









持久化
redis 的数据全部在内存中,如果突然宕机,数据就会全部丢失,因此需要持久化来保证 redis 的数据不会因为故障而丢失,redis 重启的时候可以重新加载持久化文件来恢复数据。
redis持久化有以下4种方式:
-
aof
-
rdb
-
aof rewrite
-
aof-rdb混用
从以下方面了解redis持久化:
-
aof与rdb比较
-
aof rewrite解决了aof什么问题?
-
aof-rdb混用解决aof-rdb什么问题?
-
该如何进行持久化方法的选择
redis持久化相关的配置
# redis.cnf
###### aof ######
appendonly no
appendfilename "appendonly.aof"
# appendfsync always
appendfsync everysec
# appendfsync no
# auto-aof-rewrite-percentage 为 0 则关闭 aof 复写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# yes 如果 aof 数据不完整,尽量读取最多的格式正确的数据;
# no 如果 aof 数据不完整 报错,可以通过 redis-check-aof 来修复 aof 文件;
aof-load-truncated yes
# 开启混合持久化
aof-use-rdb-preamble yes
###### rdb ######
# save ""
# save 3600 1
# save 300 100
# save 60 10000
默认配置下,只开启rdb持久化。默认rdb策略如下。
save 3600 1
save 300 100
save 60 10000
aof
append only file
aof 日志存储的是 redis 服务器的顺序指令序列,按照协议格式存储aof 日志只记录对内存修改的指令记录。
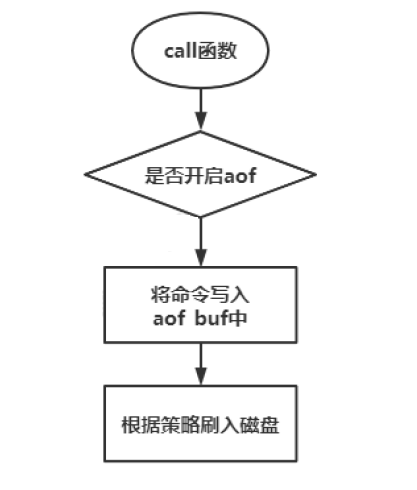
aof收到命令,在主线程中先把内容写到缓存中aof_buf。
恢复
如果redis进行了aof持久化,重启的时候,可以通过aof进行恢复,通过重放(replay)aof 日志中指令序列来进行恢复,通过重放命令,来恢复redis的内存数据。
配置
只开启aof,需要关闭aof rewrite,关闭aof-rdb混合持久化,关闭rdb。
# 开启 aof
appendonly yes
# 关闭 aof复写
auto-aof-rewrite-percentage 0
# 关闭 混合持久化
aof-use-rdb-preamble no
# 关闭 rdb
save ""
策略怎么选择?
# 1. 每条命令刷盘
# appendfsync always
# 2. 每秒刷盘
appendfsync everysec
# 3. 交由系统刷盘
# appendfsync no
持久化什么内容?
是命令的协议数据。
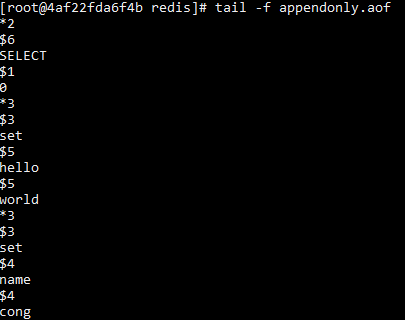
数据丢失
如果策略是appendfsync eversec,即每秒进行持久化,则最多丢失1秒钟的数据。
如果策略是appendfsync always,即每个命令都持久化,则一个命令也不会丢。为什么?
如果开启appendfsync always, read后(从client端收到命令),进行内存操作后先会进行持久化,之后才会write,将response返回给client,所以一个命令也不会丢。

优点
相对于rdb持久化,aof持久化丢失数据的可能性会更少。因为不需要fork子进程,相对于rdb来说,持久化的频率要更高一些。
缺点
- 随着时间越长,aof 日志会越来越长,如果 redis 重启,重放整个 aof 日志会非常耗时,导致 redis 长时间无法对外提供服务;
- aof占用逻辑主线程,会进行磁盘io,影响性能。
aof rewrite
aof 持久化策略会持久化所有修改命令,里面的很多命令其实可以合并或者删除。aof rewrite对aof进行了一些改进。
aof rewrite解决aof哪些问题?
- 解决aof日志越来越长的问题。
- aof占用逻辑主线程,会进行磁盘io,会影响性能。aof rewrite则通过fork进程的方式进行持久化。
aof rewrite在aof的基础上,满足一定策略则 fork 进程,根据当前内存状态,转换成一系列的 redis 命令,将命令写入一个新的 aof 日志文件中,写完后再将操作期间发生的增量 aof 日志追加到新的 aof 日志文件,追加完毕后替换旧的 aof 日志文件。以此达到对 aof 日志瘦身的目的。
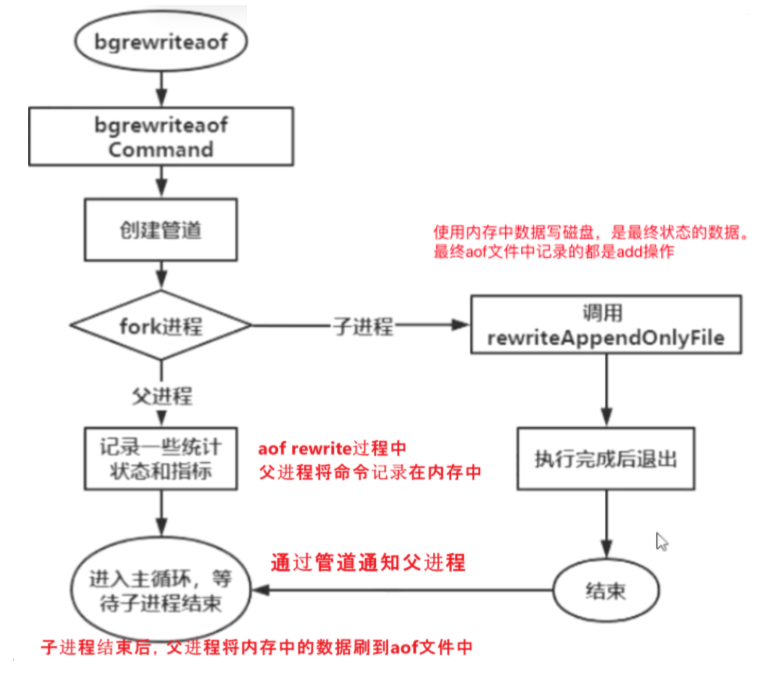
aof rewrite并不会解决aof持久化占用主线程进行磁盘io的问题, 因为还是会进行aof持久化。
策略
通过配置文件设置aof rewrite策略
# 第一次aof rewrite,是当aof文件大小为64mb,进行fork;第二次rewrite是128mb,第三次256mb......
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
也可以手动通过BGREWRITEAOF命令的方式进行aof rewrite
lpush list mark
lpush list king
lpush list darren
bgrewriteaof
# 此时会将上面三个命令进行合并成为一个命令
# 合并策略:会先检测键所包含的元素数量,如果超过 64 个会使用多个命令来记录键的值;
hset hash mark 10001
hset hash darren 10002
hset hash king 10003
hdel hash mark
bgrewriteaof
# 此时aof中不会出现mark,设置mark跟删除mark变得像从来没操作过
配置
# 开启 aof, aof rewrite的前提是开启aof
appendonly yes
# 开启 aof rewrite
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 关闭 混合持久化
aof-use-rdb-preamble no
# 关闭 rdb
save ""
优点
aof rewrite在 aof 基础上实现了瘦身,一定程度上压缩了aof持久化文件。
缺点
aof rewrite在 aof 基础上实现了瘦身,但是 aof rewrite后的aof文件的数据量仍然很大,reids重启后加载会非常慢。
rdb
aof 或 aof rewrite存在持久化文件大的缺点,rdb则是一种快照(snapshot)持久化;它通过 fork 主进程,在子进程中将内存当中的数据键值对按照存储方式持久化到 rdb 文件中;rdb 存储的是经过压缩的二进制数据;
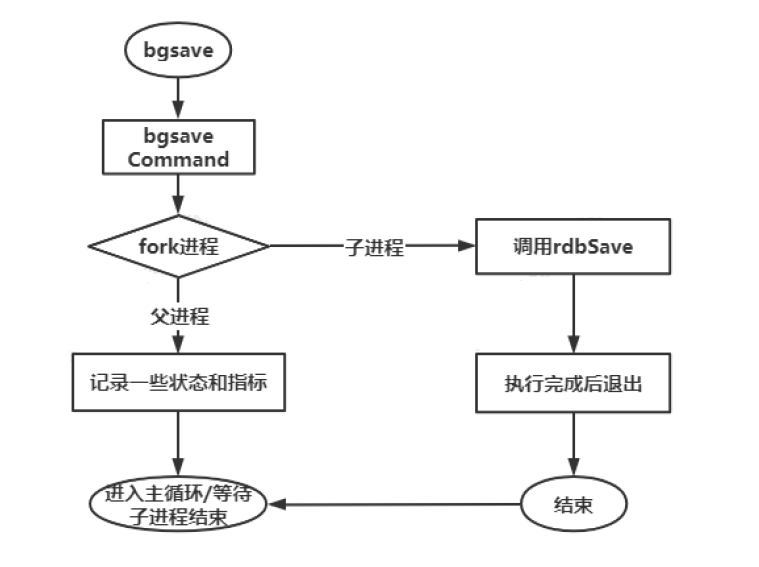
配置
# 关闭 aof 同时也关闭了 aof rewrite
appendonly no
# 关闭 aof rewrite
auto-aof-rewrite-percentage 0
# 关闭 aof-rdb混合持久化
aof-use-rdb-preamble no
# 开启 rdb 也就是注释 save ""
# save ""
# 以下3行是默认策略
# save 3600 1
# save 300 100
# save 60 10000
策略
# redis 默认策略如下:
# 注意:写了多个 save 策略,只需要满足一个则开启rdb持久化
# 3600 秒内有以1次修改
save 3600 1
# 300 秒内有100次修改
save 300 100
# 60 秒内有10000次修改
save 60 10000
优点
rdb持久化相对于aof,因为持久化文件时二进制文件,所以文件大小更小,redis重启后可以直接加载到内存,速度更快。
缺点
若采用 rdb 持久化,一旦 redis 宕机,redis 将丢失一段时间的数据;因为使用fork子进程的方法进行持久化,持久化的频率要小于aof,所以丢失数据的可能性要高于aof。
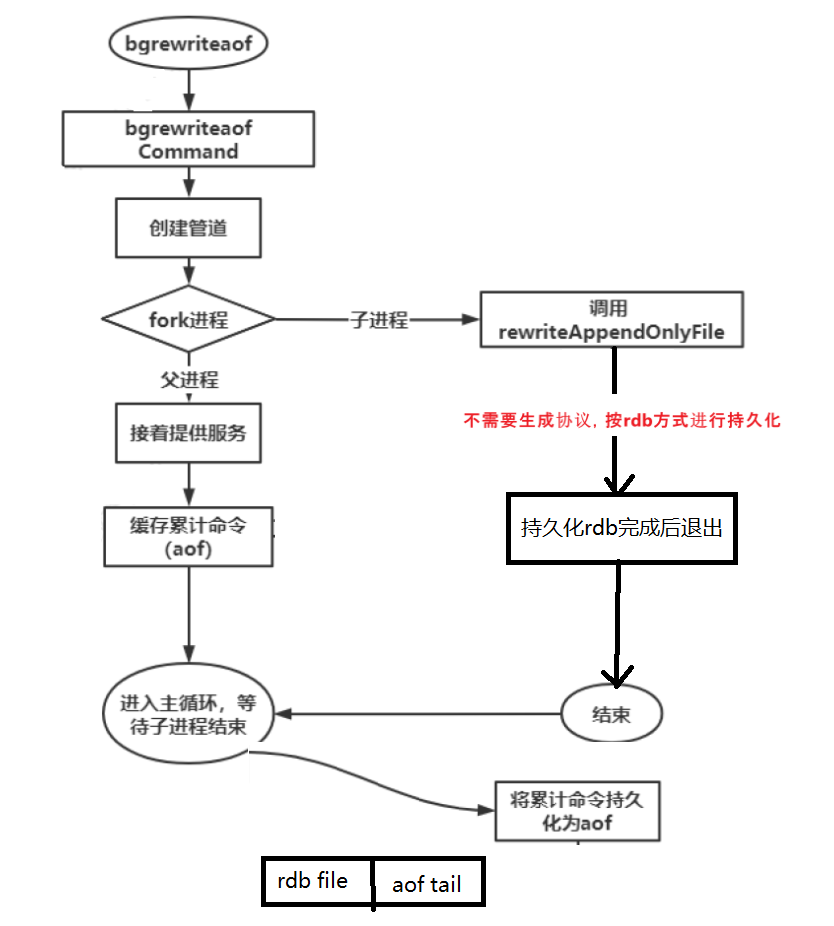
aof-rdb混合持久化
aof rewrite 和rdb持久化完成前,主进程能不能提供服务?
当然是可以的,主进程还是会正常处理命令的。
从上面知道,rdb 文件小且加载快但丢失多,aof 文件大且加载慢但丢失少;混合持久化aof-use-rdb-preamble, 是吸取rdb 和 aof 两者优点的一种持久化方案;子进程实际持久化的内容是rdb,等子进程持久化结束后,持久化期间修改的数据以 aof 的形式附加到文件的尾部。
混合持久化实际上是在 aof rewrite 基础上进行优化;所以需要先开启 aof rewrite。
配置
# 开启 aof
appendonly yes
# 开启 aof rewrite
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 开启 混合持久化
aof-use-rdb-preamble yes
# 关闭 rdb
save ""
# save 3600 1
# save 300 100
# save 60 10000
持久化应用
- MySQL 缓存方案中,redis 不开启持久化,redis 只存储热点数据,数据的依据来源于MySQL;若某些数据经常访问需要开启持久化,此时可以选择 rdb 持久化方案,也就是允许丢失一段时间数据;
- 对数据可靠性要求高,在机器性能,内存也安全 (fork 写时复制 最差的情况下 2倍内存)的情况下,可以让 redis 同时开启 aof 和 rdb,注意此时不是混合持久化;redis 重启优先从aof 加载数据,理论上 aof 包含更多最新数据;如果只开启一种,那么使用混合持久化;
如果同时开启aof和rdb,默认使用优先使用aof重启,因为aof数据最新。我们可以先 move一下aof文件,就可以从rdb重启了,rdb重启比较快。
aof文件太大;rdb总需要fork,可能会丢失数据。
- 在允许丢失数据的情况下,亦可采用主redis不持久化(充分利用内存,如96G redis可用90G),从redis进行持久化;
主从复制,主不做持久化,那通过什么进行同步的呢?正常应该是通过rdb进行同步的。
我测试了一下主从模式,即使master不开启持久化(包括aof和rdb),redis也会默认开启rdb的,所以这种主redis不持久化, 从持久化的方案并不可行。
- 伪装从库,解决2倍内存的问题;把redis数据拉到其他k-v数据库进行持久化,其他数据库不需要fork进程,而是多线程写日志。
主从复制 master-slave
主要用来实现 redis 数据的可靠性;防止主 redis 所在磁盘损坏,造成数据永久丢失;
主从之间采用异步复制的方式;
主从复制主节点是否一定要开启rdb?
测试了一下,master就算不指定开启rdb,最后也会开启rdb。
从数据库是只读的。
开启主从复制
不管通过什么方式开启主从复制,master都必须关闭protected mode
# redis.conf master
protected-mode no
之后启动主redis。
从redis可以通过命令行方式或者配置文件开启主从复制。
命令:redis-server --replicaof 127.0.0.1 7001
# redis.conf slave
replicaof 127.0.0.1 7001
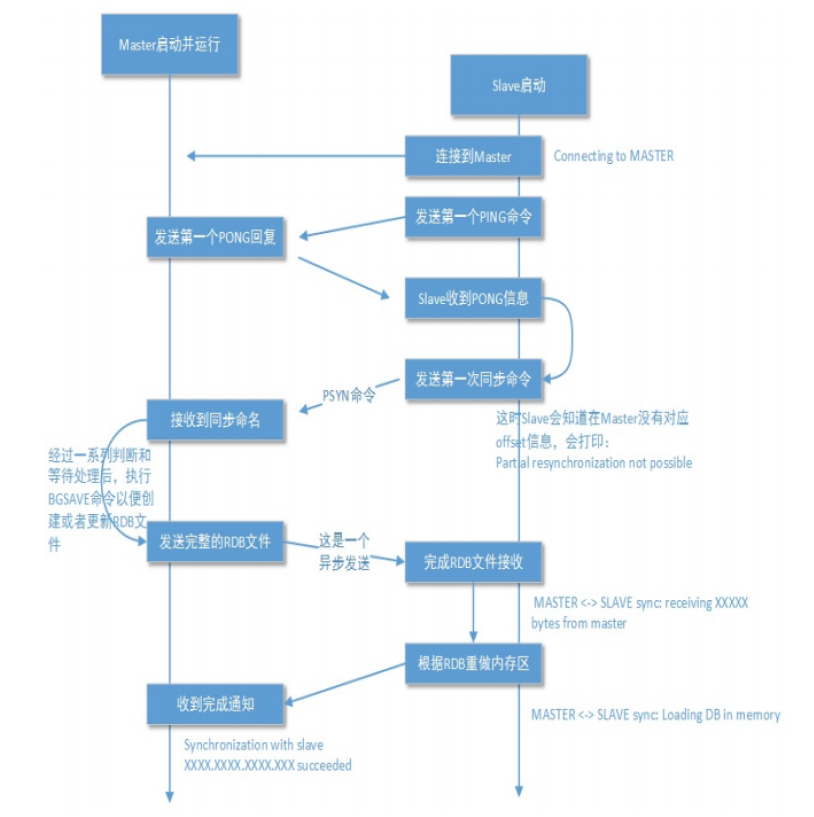
数据同步
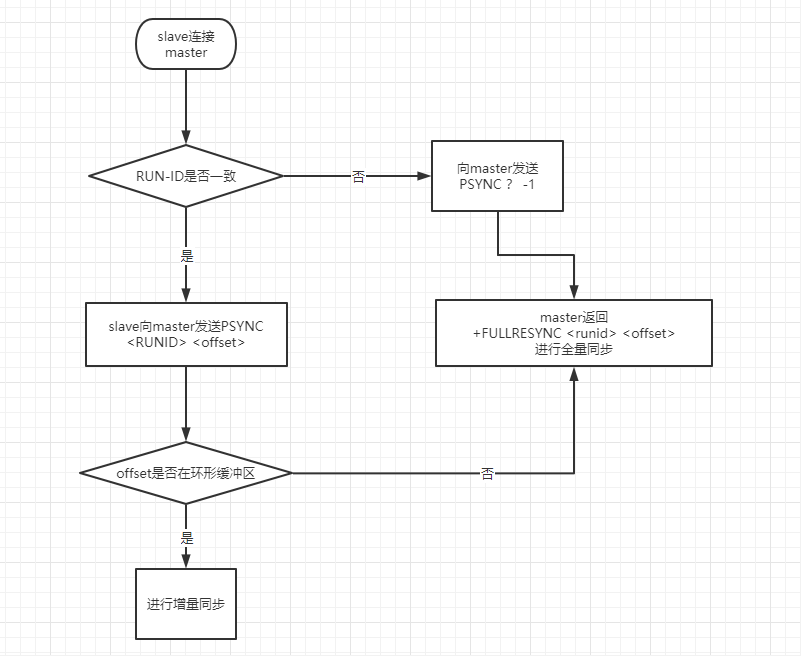
全量同步
为什么需要发送ping?连接到master不可以?
ping主要是check master是可用状态,并没有被其他命令阻塞或者死循环。
这个ping包就是一个用户层心跳包,能够探查目标进程是否能够响应。
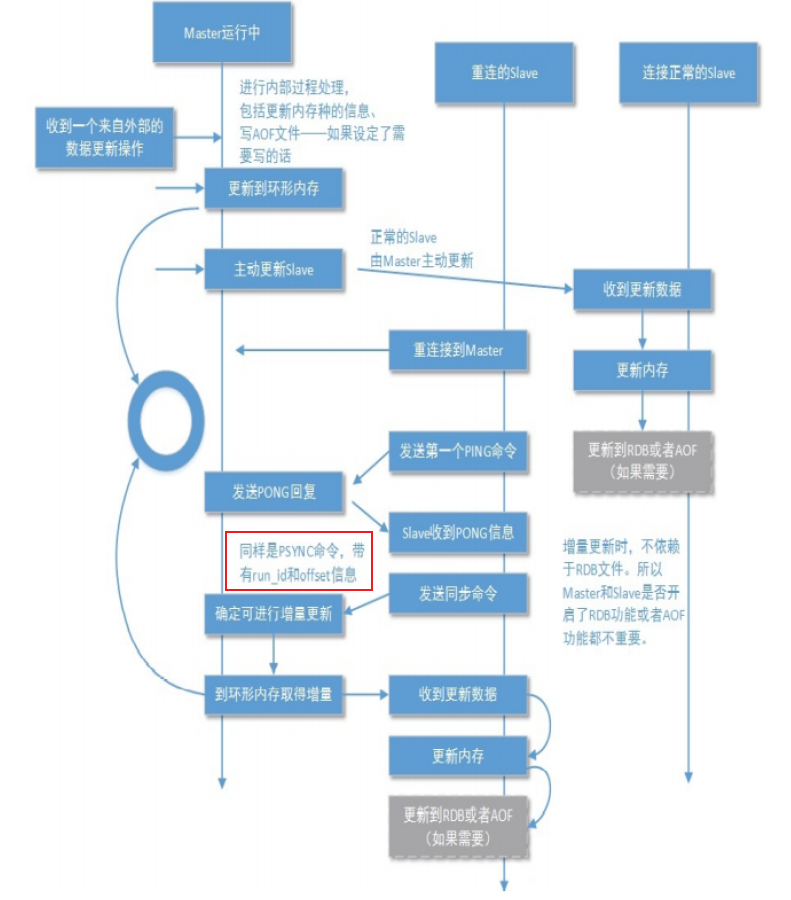
增量同步
服务器RUN ID
无论主库还是从库都有自己的 RUN ID,RUN ID 启动时自动产生,RUN ID 由40个随机的十六进制字符组成;
当从库对主库初次复制时,主库将自身的 RUN ID 传送给从库,从库会将 RUN ID 保存;
当从库断线重连主库时,从库将向主库发送之前保存的 RUN ID;
- 从库 RUN ID 和主库 RUN ID 一致,说明从库断线前复制的就是当前的主库;主库尝试执行增量同步操作;
- 若不一致,说明从库断线前复制的主库并不时当前的主库,则主库将对从库执行全量同步操作;
复制偏移量 offset
offset是一个64bit的数。
主从都会维护一个offset;
- 主库向从库发送N个字节的数据时,将自己的offset上加N;
- 从库接收到主库发送的N个字节数据时,将自己的offset加上N;
通过比较主从offset得知主从之间数据是否一致;offset相同则数据一致;offset不同则数据不一致;
环形缓冲区(复制积压缓冲区)
本质:固定长度先进先出队列;
存储内容:如下图;
当因某些原因(网络抖动或从库宕机)从库与主库断开连接,避免重新连接后开始全量同步,在主库设置了一个环形缓冲区;该缓冲区会在从库失联期间累计主库的写操作;当从库重连,会发送自身的offset到主库,主库会比较主从的offset:
- 若从库offset还在环形缓冲区中,则进行增量同步;
- 否则,主库将对从库执行全量同步;
# redis.conf
repl-backlog-size 1mb
# 如果所有从库断开连接 3600 秒后没有从库连接,则释放环形缓冲区
repl-backlog-ttl 3600

master需要根据 runnid + offset 来确定是否需要进行增量同步。
哨兵 sentinel
分布式理论
cap理论
c 一致性consistency,all nodes see the same data at the same time.
强一致性、最终一致性
mysql、redis都是最终一致性。
a 可用性availablity,reads and writes always succeed 服务一直可用。
合理时间内返回合理的值。
p 分区容错性partial tolerance,当网络分区故障时,仍然能够对外提供一致性或者可用性的服务。数据存在的节点越多,分区容错性越高。
知乎上的文章介绍的挺好https://www.zhihu.com/question/54105974
base理论
Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)
- 原子性(硬状态) -> 要求多个节点的数据副本都是一致的,这是一种"硬状态"
- 软状态(弱状态) -> 允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延迟
sentinel原理
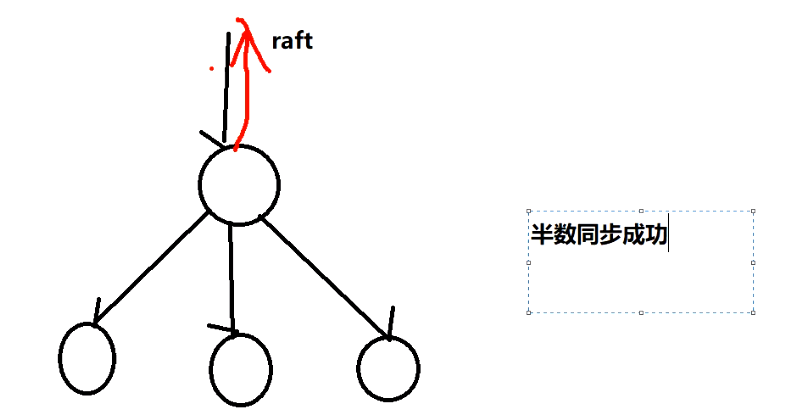
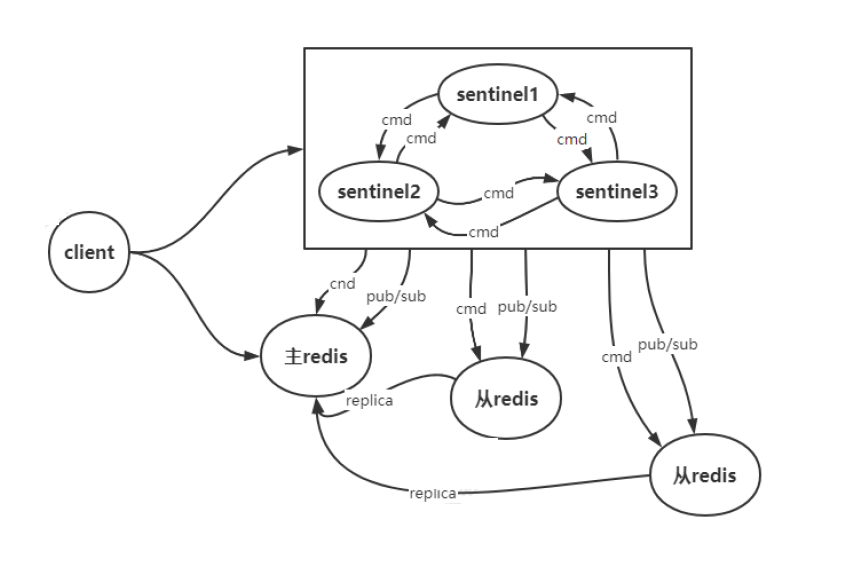
哨兵解决redis高可用的问题。每一个节点对应一个sentinel进程,sentinel进程对redis节点进行监视;当master节点down了,自动将某个slave升级为master。sentinel用来进行选举master节点,使用raft一致性算法。
客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询master的地址,然后再连接master进行数据交互。当master发生故障时,客户端会重新向 sentinel 索要mster地址,sentinel 会将最新的master地址告诉客户端。通过这样客户端无须重启即可自动完成节点切换。
一致性算法
poxos, zk使用poxos;
raft,redis sentinel,etcd使用raft。
一致性算法解决问题:
- leader选举
- 日志复制, 半数从节点同步成功,才返回给client。
sentinel原理图
如果master down了,以什么为标准选举新的主节点呢?谁的offset最大选谁。
缺点
使用的主从复制是异步复制,最终一致性,可能数据不一致,可能存在数据丢失的情况;
不支持横向扩展,redis缓存的大小最大只能使master节点的内存大小,不能扩展。
cluster
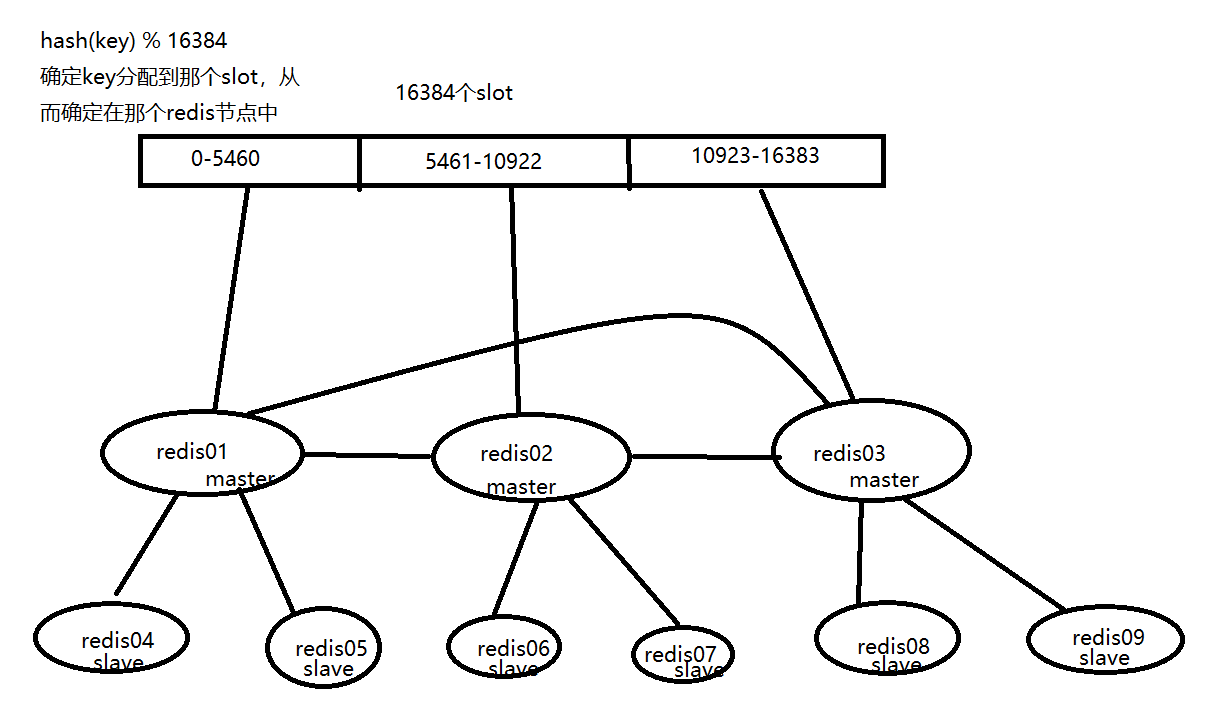
原理
redis cluster 划分 16384(2^14)个槽位(slot),每个slot就是一个虚拟节点,每个 redis 节点负责其中一部分槽位。
redis cluster,使用分布式一致性hash。
对于一个key,先使用CRC16进行hash,之后再对16384(2^14)取余,得到一个0-16384的数值,根据这个数值确定该key-value存储在redis cluster中的哪个节点中。
为什么要固定槽位?
为了确保扩容缩容不会造成数据失效。
redis会自动把cluster信息写入下面的文件,每个节点都会保存cluster信息。
# cluster-config-file nodes-6379.conf
所以客户端可以通过任意节点连接redis集群。当 redis cluster 的客户端来连接集群时,会得到一份集群的槽位配置信息。这样当客户端要查找某个 key时,可以直接定位到目标节点。
客户端为了可以直接定位(对key通过crc16进行hash, 再对2^14取余)某个具体的 key 所在节点,需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为可能会存在客户端与服务器存储槽位的信息不一致的情况,还需要纠正机制(客户端收到后需要立即纠正本地的槽位映射表)来实现槽位信息的校验调整。
可以从任意一个节点去访问集群,如果key不在该节点,则进行重定向。

如果当前节点是所访问key的slave节点,仍然需要重定向到主节点,因为redis实现的是最终一致性,slave节点认为master节点的数据更新。

扩容和缩容
redis cluster支持增加或者删除节点,通过这种方式,可以增加redis 集群的内存大小。
增加节点步骤如下:
- 启动新redis节点;
- 将新节点加入到集群中,redis-cli --cluster add-node;
- 为新节点分配槽位。
这就涉及到数据迁移, 数据迁移是以slot为单位的。可以从多个节点迁移slot给新节点,也可以从一个节点上迁移slot给新节点,可以手动指定迁移哪些slot。
需要注意的是,因为redis是单线程,迁移过程中,源节点的主线程将处于阻塞状态,知道key被删除;所以如果某个key的value内容很大,将会影响到客户端的正常访问。
怎么使key存在同一个节点?
set {mark}key value
如果不加{mark},则会以key做hash;
加上{mark}, 会以mark做hash,这类key都会分配到同一个节点。














 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









