






1.2重做日志缓冲区(Redo Log Buffer)
当运行Oracle服务器的时候,如果突然断电或系统瘫痪,会不会造成数据的丢失?Oracle提供了一套复杂的机制来维护数据完整性,并最终确保数据不会丢失。这就是重做日志文件的作用。
重做日志缓冲区用来记录对数据缓冲区数据进行的修改,可以循环使用。当用户运行DML(INSERT、UPDATE、DELETE)以及DDL(CREATE、ALTER、DROP)语句时,会改变数据高速缓存中的相应缓冲区。但是在修改这些缓冲区之前,Oracle会自动生成重做项,首先要将这些缓冲区的变化记载到“重做日志缓冲区”中。重做日志缓冲区由一条一条的重做项构成,每条重做项记载了修改的时间、被修改的块、修改位置以及新数据。缓冲区被循环使用,当重做日志缓冲区填满时,数据库系统将重做日志缓冲区的内容写入日志文件。在系统发生故障时,可以通过重做项重新执行对数据库的修改,实现对实例的恢复。
重做日志缓冲区的大小由LOG_BUFFER初始化参数来决定。
1.3共享池(Shared Pool)
SGA 的共享池(Shared Pool)内包含了库缓存(Library Cache),数据字典缓冲区(Dictionary Cache),并行执行消息缓冲区(Buffers for parallel execution messages),以及用于系统控制的各种内存结构。
共享存储区的大小由SHARED_POOL_SIZE初始化参数来决定。同数据高速缓冲区一样,它的大小可以动态的修改。
如图1-5所示,共享池由库高速缓存和数据字典缓冲区组成。
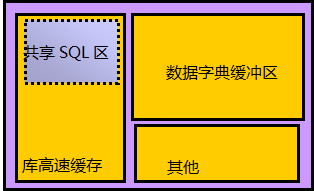 |
图 2-3 数据库高速缓冲区示意图
<!--[if !supportLists]-->1) <!--[endif]-->数据字典缓冲区
数据字典是一系列保存了数据库参考信息(例如数据库结构,数据库用户等)的表和视图。Oracle 需要频繁地使用经过解析的 SQL 语句访问数据字典。数据字典信息对 Oracle 能否正常运行至关重要。
数据字典是用来描述数据库数据的组织方式的,由表和视图组成。
数据字典由脚本$oracle_home/rdbms/admin/catalog.sql创建。
视图有三种实例:user_*(当前用户所拥有对象的有关信息),all_*(当前用户可访问对象的信息),dba_*(数据库中所有对象的信息)。
在Oracle数据库中,数据库的一些信息,包括账户、数据文件、表的描述、用户权限等信息,存储在数据字典表中,数据字典表被存放在SYSTEM表空间的数据文件中。
因为执行任何SQL语句都需要访问数据字典,所以为了提高数据字典的访问性能,Oracle在共享池中专门为存放数据字典信息分配了内存空间,这些内存空间被称为数据字典高速缓冲区。用来缓存来自于数据字典的定义。
例如,当用户执行"SELECT * FROM emp WHERE empno=7788"语句时,Oracle需要查询数据字典dba_tables确定表emp是否存在;如果该表已经存在,还需要查询数据字典dba_tab_columns确定列empno在表emp中是否存在,然后才能生成执行语句的过程(执行计划)。这些定义在首次查询时存入数据字典高速缓冲区,在后续过程中用到就可以直接使用,而不必重新查询数据字典。
<!--[if !supportLists]-->1) <!--[endif]-->库高速缓存
库高速缓冲区又可分为共享SQL区和共享PL/SQL区。
共享SQL区用来存放最近执行的SQL语句信息,包括语句文本、解析树及执行计划。执行计划就是Oracle为执行特定的SQL语句,产生的优化的执行步骤。
库高速缓冲区由许多上下文区(Context Area)组成,SQL语句和执行计划存放在相应上下文区中,并且不同SQL语句分别对应于不同的上下文区。当客户端运行SQL语句时,服务器进程首先检查是否存在对应于该SQL语句的上下文区,若存在,则按照其执行计划直接执行该SQL语句;否则生成SQL语句执行计划,并将执行计划、SQL语句存放到相应上下文区中,然后执行该SQL语句。
在开发应用程序时,必须要注意使用标准格式来编写SQL语句,使得SQL语句尽可能共享上下文区,以降低SQL语句解析次数,进而提高应用性能。
在解析SQL语句时,认为完全相同的SQL语句有以下特点:
<!--[if !supportLists]-->● <!--[endif]-->语句文本相同。
<!--[if !supportLists]-->● <!--[endif]-->大小写相同。
<!--[if !supportLists]-->● <!--[endif]-->赋值变量相同。
共享PL/SQL区用来存放最近执行的PL/SQL语句,解析和编译过的程序单元和过程(函数、包和触发器)也存放在此区域。
类似于数据高速缓冲区,Oracle也是使用LRU算法来管理库高速缓存的。通过库高速缓存,可以最小化SQL语句解析次数,进而提高应用程序的性能。
1.3大池(Large Pool)
数据库管理员可以配置一个称为大型池(Large Pool)的可选内存区域,供一次性大量的内存分配使用,例如:
<!--[if !supportLists]-->● <!--[endif]-->共享服务器(shared server)及 Oracle XA 接口(当一个事务与多个数据库交互时使用的接口)使用的会话内存(session memory)
<!--[if !supportLists]-->● <!--[endif]-->I/O 服务进程
<!--[if !supportLists]-->● <!--[endif]-->Oracle 备份与恢复操作
如果从大型池内为共享服务器,Oracle XA,或并行查询缓冲区(parallel query buffer)分配会话内存,共享池(shared pool)就能够专注于为共享 SQL 区(shared SQL area)提供内存,从而避免了共享池可用空间减小而带来的系统性能开销。
此外,Oracle 备份与恢复操作,I/O 服务进程,及并行执行缓存所需的存储空间通常为数百 KB。与共享池相比,大型池能够更好地满足此类大量内存分配的要求。
注:大型池不使用 LRU 列表管理其中内存的分配与回收。
1.4 JAVA池(Java Pool)和流池(Stream Pool)
SGA内的Java 池(Java Pool)是供各会话内运行的 Java 代码及 JVM 内的数据使用的。Java池是SGA的可选区域,用来为Java命令解析提供内存。只有在安装和使用JAVA时才需要JAVA池。
Java池的大小由JAVA_POOL_SIZE初始化参数来决定。
在数据库中,管理员可以在 SGA 内配置一个被称为数据流池(Streams Pool)的内存池供 Oracle 数据流(Stream)分配内存。管理员需要使用 STREAMS_POOL_SIZE 初始化参数设定数据流池的容量(单位为字节)。如果 Oracle 数据流第一次使用时系统中没有定义数据流池,Oracle 将自动地创建一个。
注:Java编程和Oracle数据流的详细讨论超出了本课程的范围。
<!--[if !supportLists]-->1.<!--[endif]-->查询SGA的大小
1> 显示SGA大小
SQL> SHOW SGA
SQL> SELECT * FROM v$sga;
SQL> SHOW PARAMETER sga_target
2> 显示SGA最大值
SQL> SHOW PARAMETER sga_max_size
<!--EndFragment-->来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29781254/viewspace-1744938/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/29781254/viewspace-1744938/















 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









