 关注
关注
 分享
分享
Reinforcement learning
coolsunxu
仅仅记录下自己的成长,不喜勿喷
展开
-
XGNN: Towards Model-Level Explanations of Graph Neural Networks
XGNN: Towards Model-Level Explanations of Graph Neural Networks原创 2020-06-09 10:23:58 · 742 阅读 · 5 评论 -
Reinforcement Learning An Introduction~The 10-armed Testbed
2.3 10臂测试台 为了粗略的评估贪婪算法和ε-greedy 方法的相对有效性,我们通过一系列测试问题进行数值上的比较。这是一个2000次的随机产生的10个臂的赌博问题。对于每个赌博机问题,就像图2.1所示: ...翻译 2018-12-21 10:01:51 · 591 阅读 · 0 评论 -
Reinforcement Learning An Introduction~Action-value Methods
2.2 行为值方法 我们开始考察一些简单的用于估计行为值并且以此来进行行为选择的方法,叫做行为值方法。回想一下行为的真值表示当行为被选择时获得的平均回报。一个自然的想法是通过行为被选择后获得的平均值来估计行为值: 其中 表示如果predicate为真,那么l ,如果predicate...翻译 2018-12-06 10:38:14 · 244 阅读 · 0 评论 -
Reinforcement Learning An Introduction~A k-armed Bandit Problem
Chapter 2 多臂赌博机 区分强化学习与其他类型学习的最重要特征是它使用训练信息来评估所采取的行动而不是通过给出正确的行动来指导。这就是积极探索创造需求,以明确寻找较好的动作。纯粹的评价反馈表明所采取的动作有多好,但不表明它是最好还是最坏的动作。另一方面,纯粹的指导性反馈表明采取的动作是正确的,但与实际采取的行动无关。这种反馈是监督学习的基础,包括模式分类,人工神经...翻译 2018-12-05 14:57:29 · 332 阅读 · 0 评论 -
Reinforcement Learning An Introduction~Summary and History
1.6 总结 强化学习是一种理解和自动化目标导向学习和决策的计算方法。 它与其他计算方法的区别在于它强调代理人通过与环境的直接交互来学习,而不依赖于模范监督或完整的环境模型。 我们认为,强化学习是第一个认真解决,从与环境互动中学习以实现长期目标时,出现的计算问题的领域。 强化学习使用马尔可夫决策过程的正式框架来定义学习代理与其环境之间在状态,动作和奖励方面的交互。该框...翻译 2018-11-29 15:06:11 · 139 阅读 · 0 评论 -
Reinforcement Learning An Introduction~An Extended Example: Tic-Tac-Toe
1.5 扩展示例:三连棋游戏 为了说明强化学习的一般概念并将其与其他方法进行对比,我们接下来将更详细地考虑一个单一的例子。 考虑一下我们比较熟悉的孩子们的三连棋游戏。两名玩家轮流在一个三乘三的棋盘上比赛。一个玩家画X符号和另一个玩家画O符号,直到一个玩家通过在水平,垂直或对角线上连续放置三个标记来获胜,作为X玩家,他获胜的局面如下图所示。 如果棋盘填...翻译 2018-11-29 11:26:22 · 473 阅读 · 2 评论 -
Reinforcement Learning An Introduction~Elements of Reinforcement Learning
1.3 强化学习的要素 除了智能体和环境之外,我们还可以识别强化学习系统的四个主要子元素:策略,奖励信号,价值函数,以及可选的环境模型。 策略定义为可以学习的智能体在给定时间的行为方式。粗略地说,策略是从感知的环境状态到在这些状态下要采取的动作的映射。它对应于心理学中所谓的一组刺激响应或关联规则。在某些情况下,策略可以是简单的函数或查找表,而在其他情况下,它可能涉及...翻译 2018-11-17 15:43:19 · 301 阅读 · 0 评论 -
Reinforcement Learning An Introduction~Examples
1.2 例子理解强化学习的一个好方法是考虑一些指导其发展的示例和可能的应用。大师级国际象棋选手采取行动。通过考虑可能的落子和反击这种计划来做出选择,以及对特定位置和落子的可取性采取果断的直接的判断。 自适应控制器实时调整炼油厂操作的参数。控制器在此基础上优化产量/成本/质量权衡指定的边际成本,而不是严格遵守最初工程师建议的设定点。 一只瞪羚小牛出生后几分钟就挣扎着。 半小时后呢?它以每...翻译 2018-11-16 10:30:46 · 313 阅读 · 0 评论 -
Reinforcement Learning An Introduction~Summary of Notation
1、鉴于编辑需要LaTex公式,比较麻烦,所以这里贴出图片形式2、读者也可以在下面网址找到笔者上传的Doc文档https://download.csdn.net/download/coolsunxu/107855063、使用第三方翻译软件(不打广告),结合自己理解翻译,请多见谅 ...翻译 2018-11-15 00:34:33 · 196 阅读 · 0 评论 -
Reinforcement Learning An Introduction~Limitations and Scope
1.4 限制和范围 强化学习在很大程度上依赖于这种称为状态的概念,它是作为政策和价值函数的输入,以及作为模型的输入和输出。非正式地,我们可以将状态视为向智能体传达,在特定时间某种“环境如何”的信号。我们在此处使用的状态的正式定义,由第3章的马尔可夫决策过程的框架给出。然而,更一般地说,我们鼓励读者遵循非正式的含义,并将状态视为是智能体对其环境来说,可获得的任何信息。实际上,我们假设...翻译 2018-11-18 18:51:11 · 183 阅读 · 0 评论 -
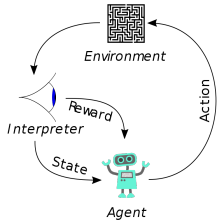
Reinforcement Learning An Introduction~Reinforcement Learning
第一章 介绍 当我们考虑学习的本质时,我们首先想到的可能是通过与环境互动学习。当一个婴儿玩耍,挥动手臂或环顾四周时,它没有明确的老师,但它确实与其环境有直接的感觉运动联系。通过这种联系可以产生大量关于因果关系的信息,关于动作的后果,以及为实现目标应该做些什么。在我们的生活中,这种互动无疑是关于我们的环境和我们自己的主要知识来源。无论我们是学习驾驶汽车还是进行对话,我们都敏锐地意识到...翻译 2018-11-15 16:16:35 · 485 阅读 · 0 评论 -
Ubuntu16.04配置Gym、Torcs、Mujoco环境
参考网址:1、https://blog.csdn.net/will_ye/article/details/810874632、https://blog.csdn.net/xulingjie_online/article/details/791790823、https://www.jianshu.com/p/a3432c0e1ef24、https://www.jianshu.com/...原创 2018-11-11 22:49:10 · 1978 阅读 · 3 评论