






select count(1) 和select count(*)都是统计某个表中或者视图的记录条数,那他们两个有什么区别呢?以下我将做下试验。
通过运行的时间和IO的统计值,执行计划来进行观察
use AdventureWorks2008R2
go
--在运行前开启时间和IO统计的设置,选中显示执行计划
--set statistics time on
--set statistics io on
select COUNT(*) from dbo.DatabaseLog
第一次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 19 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 1, read-ahead reads 8, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 78 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
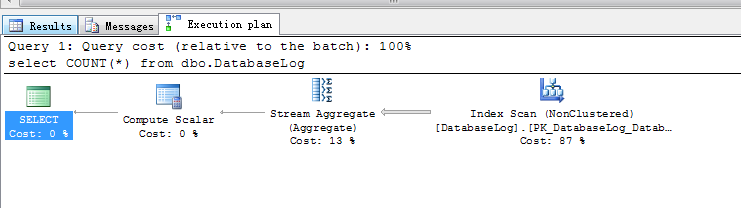
第二次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
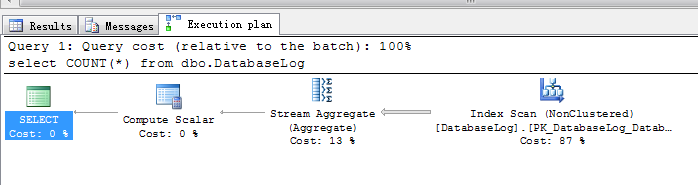
其后多次运行都跟第二次运行耗费的IO,time基本都是一样的,执行计划当然也是一样的。
在执行select count(1) 时,我们为了避免sql重用上面的执行计划,所以使用以下命令先将执行计划缓存先清除掉
use AdventureWorks2008R2
go
--dbcc freeproccache
--set statistics time on
--set statistics io on
select COUNT(1) from dbo.DatabaseLog
第一次运行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
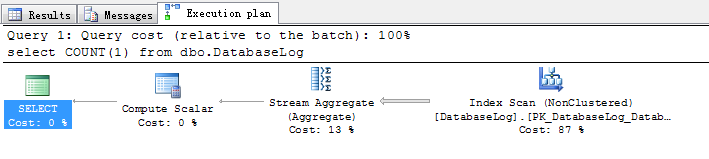
第二次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
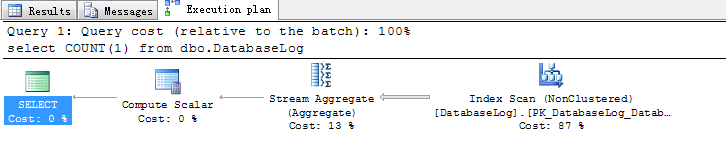
有些人开始怀疑select count (1)是不是还是重用之前select count(*)的执行计划,所以我下面又重新使用一张表,然后先运行select count(1)运行了两遍,然后再清楚执行计划缓存,再执行select count(*),然后我们观察两者的区别
use AdventureWorks2008R2
go
--set statistics time on
--set statistics io on
select COUNT(1) from Person.EmailAddress
第一次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 4, read-ahead reads 182, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 92 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
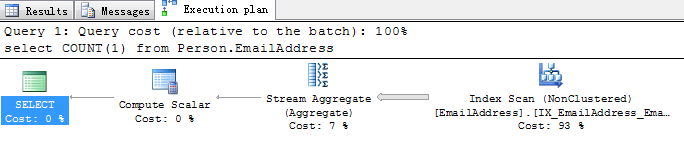
第二次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

清楚执行计划缓存
dbcc freeproccache
use AdventureWorks2008R2
go
--set statistics time on
--set statistics io on
select COUNT(1) from Person.EmailAddress
第一次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
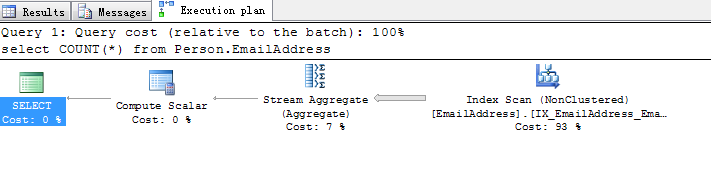
第二次执行
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

经过以上对比,我们可以看出其实select count(1)和select count(*)对于有索引的表几乎是等同的,执行计划都走的是index scan,花费的成本,时间,IO几乎都是一样的。这个实验也推翻了我们认为select count(1)要比select count(*)优的说法。
以上是对于有索引的表做的测试,下面我将做堆表(即没有索引的表)的测试:
测试一:
CREATE TABLE TEST_COUNT
(
ID INT NOT NULL,
COL1 VARCHAR(10) NULL,
COL2 VARCHAR(13) NULL,
COL3 DATETIME NULL,
COL4 DATETIME NULL
)
DECLARE @A INT
SELECT @A=0
WHILE (@A<100000)
BEGIN
INSERT INTO TEST_COUNT
SELECT @A,CAST(REPLICATE(@A,10) AS VARCHAR(10)),CAST(REPLICATE(@A,10) AS VARCHAR(10)),GETDATE(),GETDATE()
SELECT @A=@A+1
END
USE TEST
GO
--dbcc freeproccache
select COUNT(*) from dbo.TEST_COUNT
开销:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'TEST_COUNT'. Scan count 1, logical reads 715, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 20 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
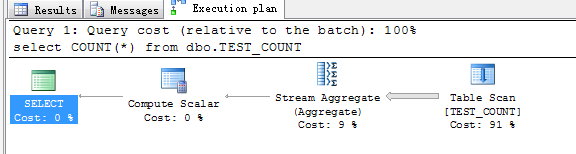
USE TEST
GO
--dbcc freeproccache
select COUNT(1) from dbo.TEST_COUNT
开销:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'TEST_COUNT'. Scan count 1, logical reads 715, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 23 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
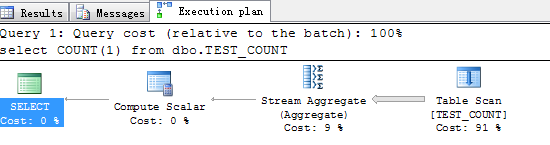
根据以上测试的结果,我们可以得出结论, select count(1)和select count(*)基本可以等效了,开销和执行计划都一样
最后我还想测一个问题,对于有多个索引的表,那我们在select count(1)或者select count(*)或者select 具体某一列,那他们的执行计划又是怎样的。
举例测试下:
CREATE TABLE DBO.TEST_COUNT
(
ID INT NOT NULL,
COL1 VARCHAR(10) NULL,
COL2 VARCHAR(13) NULL,
COL3 DATETIME NULL,
COL4 DATETIME NULL,
col5 int null,
col6 bit null
)
DECLARE @A INT
SELECT @A=0
WHILE (@A<100000)
BEGIN
INSERT INTO TEST_COUNT
SELECT @A,CAST(REPLICATE(@A,10) AS VARCHAR(10)),CAST(REPLICATE(@A,10) AS VARCHAR(10)),GETDATE(),GETDATE(),@A,null
SELECT @A=@A+1
END
alter table DBO.TEST_COUNT
add constraint PK_TEST_COUNT primary key (ID ASC)
CREATE NONCLUSTERED INDEX IX_TEST_COUNT_COL4 ON DBO.TEST_COUNT
(
COL4
)
CREATE NONCLUSTERED INDEX IX_TEST_COUNT_col55 ON DBO.TEST_COUNT
(
col5
)WHERE (COL5>100)
CREATE NONCLUSTERED INDEX IX_TEST_COUNT_col6 ON DBO.TEST_COUNT
(
col6
)
SELECT COUNT(*) FROM dbo.TEST_COUNT --count(*)
SELECT COUNT(1) FROM dbo.TEST_COUNT --count(1)
SELECT COUNT(ID) FROM dbo.TEST_COUNT --count(主键)
SELECT COUNT(COL3) FROM dbo.TEST_COUNT --count(一般列)
SELECT COUNT(COL4) FROM dbo.TEST_COUNT --count(一般非聚集索引列,列类型为int)
SELECT COUNT(col5) FROM dbo.TEST_COUNT --count(筛选索引列)
select COUNT(COL6) from dbo.TEST_COUNT --count(一般非聚集索引列)
执行计划:
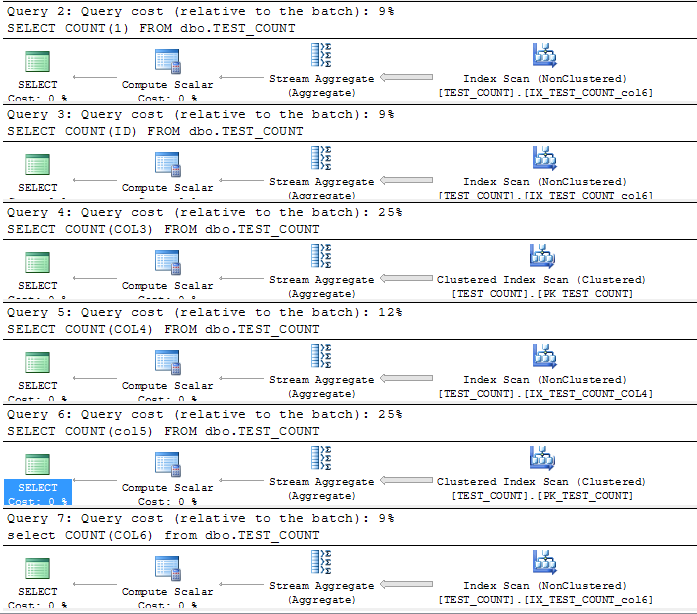
运行结果:
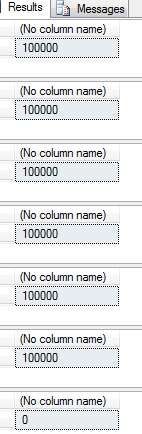
从以上的查询结果及查询计划,我们可以得出一个结论:
当具有聚集索引的表上存在多个非聚集索引时,
select count(1),count(*),count(主键),那sqlserver会选择扫描一个列最窄的一般的非聚集索引,因为这些非聚集索引上存储了我们的主键列。
select(一般索引列),sqlserver会选择扫描自己的索引.
select(筛选索引列)因为筛选索引的数据不全,而其他索引上又不包含该列信息,所以sqlserver选择扫描聚集索引。
select(一般数据列)因为没有哪个索引包含该列信息,所以sqlserver也选择扫描聚集索引
从查询结果,我又有了额外的收获,因为col6列都是null值,所以count(col6)就是0,也就是sqlserver认为null值就是该行没有值。
又临时想到一个问题,如果该表为存在多个非聚集索引的堆表,那这几个查询sqlserver的执行计划有是怎样的呢?
测试下吧,删掉主键(因为表上没有其他聚集索引,所以这里默认为主键为聚集索引)
alter table DBO.TEST_COUNT
drop constraint PK_TEST_COUNT
执行计划如下:
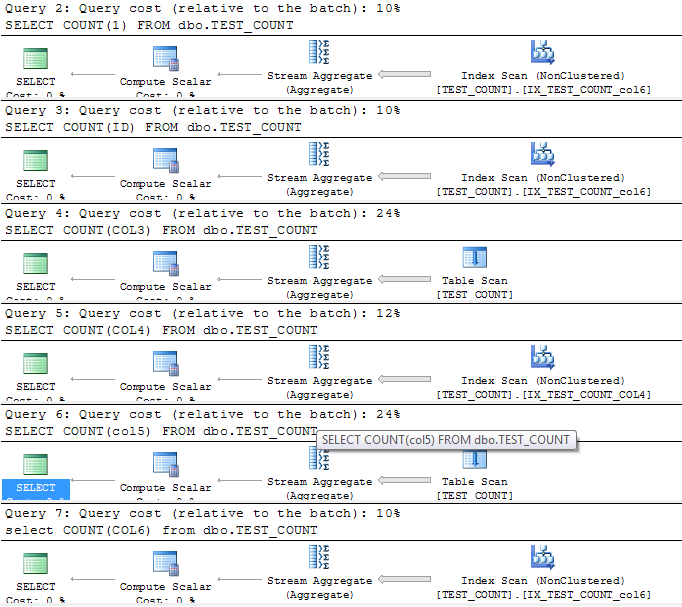
运行结果和上面一样。
根据执行计划,我们总结一下:
存在有非聚集索引的堆表上,
select count(1),count(*),count(主键),那sqlserver会选择扫描一个列最窄的一般的非聚集索引,因为这些非聚集索引上存储了我们的RID。
select(一般索引列),sqlserver会选择扫描自己的索引.
select(筛选索引列)因为筛选索引的数据不全,而其他索引上又不包含该列信息,所以sqlserver选择全表扫描。
select(一般数据列)因为没有哪个索引包含该列信息,所以sqlserver也选择全表扫描
通过运行的时间和IO的统计值,执行计划来进行观察
use AdventureWorks2008R2
go
--在运行前开启时间和IO统计的设置,选中显示执行计划
--set statistics time on
--set statistics io on
select COUNT(*) from dbo.DatabaseLog
第一次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 19 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 1, read-ahead reads 8, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 78 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
第二次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
其后多次运行都跟第二次运行耗费的IO,time基本都是一样的,执行计划当然也是一样的。
在执行select count(1) 时,我们为了避免sql重用上面的执行计划,所以使用以下命令先将执行计划缓存先清除掉
use AdventureWorks2008R2
go
--dbcc freeproccache
--set statistics time on
--set statistics io on
select COUNT(1) from dbo.DatabaseLog
第一次运行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
第二次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'DatabaseLog'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
有些人开始怀疑select count (1)是不是还是重用之前select count(*)的执行计划,所以我下面又重新使用一张表,然后先运行select count(1)运行了两遍,然后再清楚执行计划缓存,再执行select count(*),然后我们观察两者的区别
use AdventureWorks2008R2
go
--set statistics time on
--set statistics io on
select COUNT(1) from Person.EmailAddress
第一次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 4, read-ahead reads 182, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 92 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
第二次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
清楚执行计划缓存
dbcc freeproccache
use AdventureWorks2008R2
go
--set statistics time on
--set statistics io on
select COUNT(1) from Person.EmailAddress
第一次执行:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
第二次执行
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'EmailAddress'. Scan count 1, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
经过以上对比,我们可以看出其实select count(1)和select count(*)对于有索引的表几乎是等同的,执行计划都走的是index scan,花费的成本,时间,IO几乎都是一样的。这个实验也推翻了我们认为select count(1)要比select count(*)优的说法。
以上是对于有索引的表做的测试,下面我将做堆表(即没有索引的表)的测试:
测试一:
CREATE TABLE TEST_COUNT
(
ID INT NOT NULL,
COL1 VARCHAR(10) NULL,
COL2 VARCHAR(13) NULL,
COL3 DATETIME NULL,
COL4 DATETIME NULL
)
DECLARE @A INT
SELECT @A=0
WHILE (@A<100000)
BEGIN
INSERT INTO TEST_COUNT
SELECT @A,CAST(REPLICATE(@A,10) AS VARCHAR(10)),CAST(REPLICATE(@A,10) AS VARCHAR(10)),GETDATE(),GETDATE()
SELECT @A=@A+1
END
USE TEST
GO
--dbcc freeproccache
select COUNT(*) from dbo.TEST_COUNT
开销:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
Table 'TEST_COUNT'. Scan count 1, logical reads 715, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 20 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
USE TEST
GO
--dbcc freeproccache
select COUNT(1) from dbo.TEST_COUNT
开销:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
Table 'TEST_COUNT'. Scan count 1, logical reads 715, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 23 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
根据以上测试的结果,我们可以得出结论, select count(1)和select count(*)基本可以等效了,开销和执行计划都一样
最后我还想测一个问题,对于有多个索引的表,那我们在select count(1)或者select count(*)或者select 具体某一列,那他们的执行计划又是怎样的。
举例测试下:
CREATE TABLE DBO.TEST_COUNT
(
ID INT NOT NULL,
COL1 VARCHAR(10) NULL,
COL2 VARCHAR(13) NULL,
COL3 DATETIME NULL,
COL4 DATETIME NULL,
col5 int null,
col6 bit null
)
DECLARE @A INT
SELECT @A=0
WHILE (@A<100000)
BEGIN
INSERT INTO TEST_COUNT
SELECT @A,CAST(REPLICATE(@A,10) AS VARCHAR(10)),CAST(REPLICATE(@A,10) AS VARCHAR(10)),GETDATE(),GETDATE(),@A,null
SELECT @A=@A+1
END
alter table DBO.TEST_COUNT
add constraint PK_TEST_COUNT primary key (ID ASC)
CREATE NONCLUSTERED INDEX IX_TEST_COUNT_COL4 ON DBO.TEST_COUNT
(
COL4
)
CREATE NONCLUSTERED INDEX IX_TEST_COUNT_col55 ON DBO.TEST_COUNT
(
col5
)WHERE (COL5>100)
CREATE NONCLUSTERED INDEX IX_TEST_COUNT_col6 ON DBO.TEST_COUNT
(
col6
)
SELECT COUNT(*) FROM dbo.TEST_COUNT --count(*)
SELECT COUNT(1) FROM dbo.TEST_COUNT --count(1)
SELECT COUNT(ID) FROM dbo.TEST_COUNT --count(主键)
SELECT COUNT(COL3) FROM dbo.TEST_COUNT --count(一般列)
SELECT COUNT(COL4) FROM dbo.TEST_COUNT --count(一般非聚集索引列,列类型为int)
SELECT COUNT(col5) FROM dbo.TEST_COUNT --count(筛选索引列)
select COUNT(COL6) from dbo.TEST_COUNT --count(一般非聚集索引列)
执行计划:
运行结果:
从以上的查询结果及查询计划,我们可以得出一个结论:
当具有聚集索引的表上存在多个非聚集索引时,
select count(1),count(*),count(主键),那sqlserver会选择扫描一个列最窄的一般的非聚集索引,因为这些非聚集索引上存储了我们的主键列。
select(一般索引列),sqlserver会选择扫描自己的索引.
select(筛选索引列)因为筛选索引的数据不全,而其他索引上又不包含该列信息,所以sqlserver选择扫描聚集索引。
select(一般数据列)因为没有哪个索引包含该列信息,所以sqlserver也选择扫描聚集索引
从查询结果,我又有了额外的收获,因为col6列都是null值,所以count(col6)就是0,也就是sqlserver认为null值就是该行没有值。
又临时想到一个问题,如果该表为存在多个非聚集索引的堆表,那这几个查询sqlserver的执行计划有是怎样的呢?
测试下吧,删掉主键(因为表上没有其他聚集索引,所以这里默认为主键为聚集索引)
alter table DBO.TEST_COUNT
drop constraint PK_TEST_COUNT
执行计划如下:
运行结果和上面一样。
根据执行计划,我们总结一下:
存在有非聚集索引的堆表上,
select count(1),count(*),count(主键),那sqlserver会选择扫描一个列最窄的一般的非聚集索引,因为这些非聚集索引上存储了我们的RID。
select(一般索引列),sqlserver会选择扫描自己的索引.
select(筛选索引列)因为筛选索引的数据不全,而其他索引上又不包含该列信息,所以sqlserver选择全表扫描。
select(一般数据列)因为没有哪个索引包含该列信息,所以sqlserver也选择全表扫描
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/27026361/viewspace-767651/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/27026361/viewspace-767651/















 2880
2880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









