







- 每天不断完善和更新自己的认知是件让人很愉悦的事情!!!

50、linux下如何临时上传和下载文件
发送文件到本地:sz filename
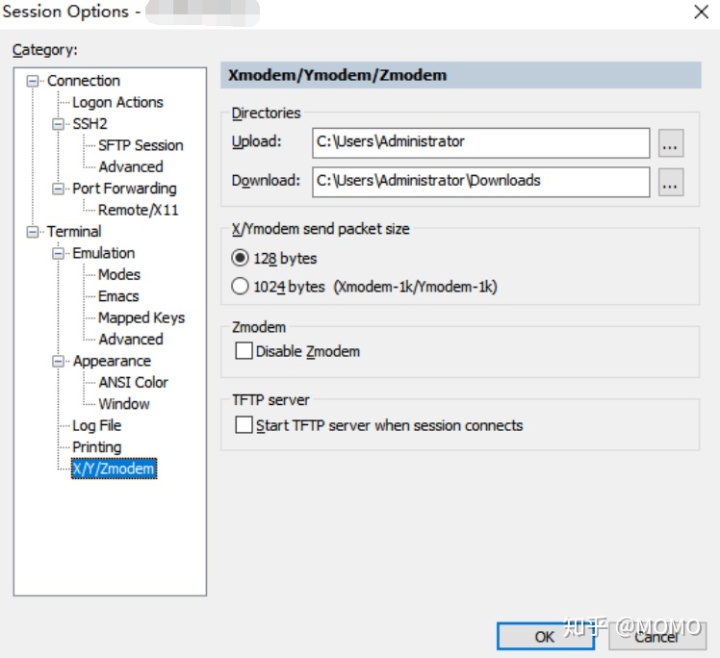
本地上传文件到服务器:rz(执行该命令后,在弹出框中选择要上传的文件即可)说明:打开SecureCRT软件 -> Options -> session options -> X/Y/Zmodem 下可以设置上传和下载的目录。
49、Linux下,软件的默认安装目录一般在/usr/local或者/opt里。
48、Linux下如何查看版本信息, 包括位数、版本信息以及CPU内核信息、CPU具体型号等
Linux查看版本当前操作系统内核信息:uname -a
Linux查看当前操作系统版本信息:cat /proc/version
Linux查看版本当前操作系统发行版信息:cat /etc/redhat-release
Linux查看cpu相关信息,包括型号、主频、内核信息等:more /proc/cpuinfo
47、history n
history n 表示列出最近的n条命令,历史命令是被保存在内存中的,当退出或登录shell时,会自动保存或读取,在内存中,历史命令仅能够存储1000条历史命令,该数量由环境变量HISTSIZE控制。查看history的缓存数量命令如下:
cat /etc/profile | grep HISTSIZE
输出:
HISTSIZE=1000
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
46、scp服务器之间免密传输文件
举例:将A服务器路径/data/下的文件trainset.csv免密传输到B服务器的路径/data/下,在A服务器下执行如下命令,其中,xx.x.xx.xxx为B服务器的内网地址。
scp /data/trainset.csv root@xx.x.xx.xxx:/data/
45、定时任务
crontab -l :表示查看当前用户的定时任务配置
crontab -e :表示进入当前用户的定时任务vim编辑模式
crontab -u 用户名 -l :表示查看指定用户的定时任务设置定时任务不执行时,可尝试命令: chmod 777

44、grep 耗时 main.log
搜索main.log中包含“耗时”的行,输出结果示例如下:


43、vi 搜索功能
vi进入编辑状态后,输入?,输入要查找的关键字,按回车即可跳到要查找关键字所在的位置,按n可跳转到下一个关键字位置,如果需要退出,则按冒号:,再按q,按回车退出。按:q!是强制退出的意思,按:wq是保存并退出的意思。
?batch_size
:wq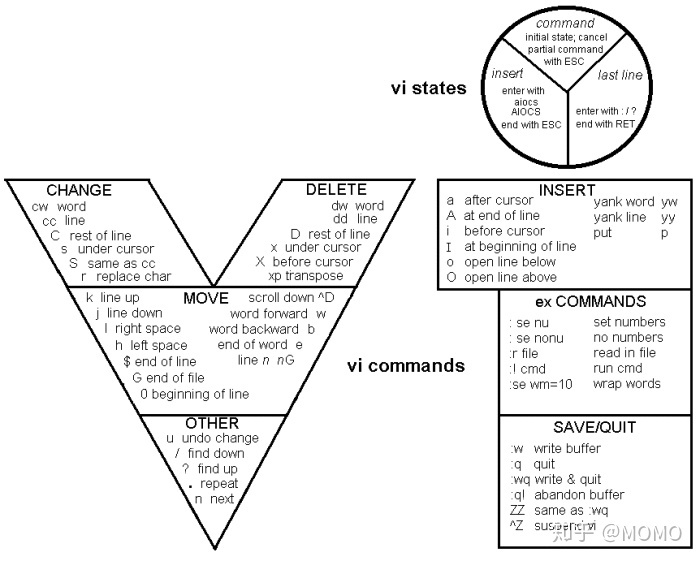
42、find . -type f -size +1024M -print0 | xargs -0 du -h
查找当前路径下大文件所在位置(超过1024M的的文件):
例如,find . -type f -size +1024M -print0 | xargs -0 du -h返回结果如下:
1.2G ./project/pengpeng/project/bert/data/20201001/test_set.csv
9.8G ./project/pengpeng/project/bert/data/20201001/train_set.csv41、find ./ -name data
查找当前路径下某个文件夹或文件所在的路径地址,包括当前路径下的子文件夹和子文件。
例如,命令find ./ -name data返回的结果如下:
./project/pengpeng/project/bert/data例如,find ./ -name train_set.py返回的结果如下:
./project/pengpeng/project/bert/data/train_set.py40、/ ./ ../
/指根目录,和Windows的我的电脑那个位置差不多。
./指当前目录。
../指前一级目录。
39、paste -s title.txt > title_str.txt
说明:将文件title中的多行数据合并为一行,并存储在title_str.txt中。
38、kill -9 45439
说明:杀掉PID为45439的进程,9表示无条件终止,强制杀死该进程(绝杀)。

37、du -sh *
说明:列出当前路径下,所有文件的大小,如果是文件夹,则显示的是文件夹里所有文件的大小总和。
36、ls -alh
说明:列出当前路径下,所有文件和文件夹,包括隐藏文件。
35、ls -l data_*|grep "^-" | wc -l
说明:查看当前路径下,data_开头的文件个数,不包括文件夹,且不包括子文件夹里data_开头的文件。
34、ls -l |grep "^d" | wc -l
说明:查看当前路径下,文件夹的个数,不包括子文件夹里的文件夹。
33、ls -l |grep "^-" | wc -l
说明:查看当前路径下,文件的个数,不包括文件夹,且不包括子文件夹里的文件。
32、find ./ -type f | wc -l 或 find -type f | wc -l 或 ls -lR |grep "^-" | wc -l
说明:查看当前路径下,文件的个数,不包括文件夹,但包括子文件夹里的文件。
31、sed -n '5001,10000p' train_set.csv > train_set_5000.csv
说明:从train_set.csv选取第5001行至第10000行的5000行数据,并存储在train_set_5000.csv中。
30、tail -5000 train_set.csv > train_set_5000.csv
说明:从train_set.csv选取末尾5000行数据,并存储在train_set_5000.csv中。
29、head -5000 train_set.csv > train_set_5000.csv
说明:从train_set.csv选取第1行至第5000行的5000行数据,并存储在train_set_5000.csv中。
28、shuf -n5000 train_set.csv > train_set_5000.csv
说明:从train_set.csv随机选取5000行数据,并存储在train_set_5000.csv中。
27、cp -r /data/20201212/trainset.csv ./20201212/
说明;将/data/20201212/路径下的文件trainset.csv复制到当前路径下的20201212
26、cp -r /data/20201212 ./20201212
说明:将/data/路径下的整个文件夹20201212复制到当前路径下,复制之前,当前路径下还没有20201212文件夹。
25、more main.log
说明:查看main.log日志部分内容.
24、 cat main.log
说明:查看main.log日志所有内容.
23、 vi main.py,然后按i键,修改,按esc键,按冒号键,按wq表示保存并退出,按q!表示不保存并强制退出。
说明:修改程序main.py中的内容.
22、 free -g
说明:查看服务器内存使用情况。
21、执行sync,然后执行echo 3 > /proc/sys/vm/drop_caches
说明:清除缓存。缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。缓存是分布式系统中的重要组件,主要解决高并发,大数据场景下,热点数据访问的性能问题。提供高性能的数据快速访问。sync(即synchronous synchronization),echo 3 > /proc/sys/vm/drop_caches(即echolocation process/system/virtual memory).
疑问:程序运行过程中,清理内存是否有影响?
20、nvidia-smi
说明:静态查看GPU使用情况。
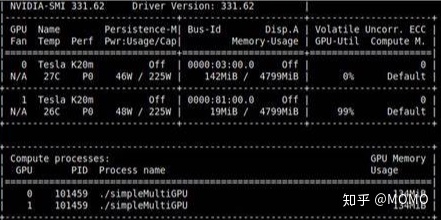
19、watch -n 1 nvidia-smi
说明:动态查看GPU使用情况。
18、nohup python -u main.py > ./main.log 2>&1 &
说明:后台挂起方式运行程序main.py,运行日志保存至main.log
最后一个&表示把该命令以后台的job的形式运行。
文件描述符0,1,2分别表示标准输入,标准输出,标准错误输出。
将标准错误输出也重定向到标准输出中,再将标准输出重定向到main.log这个文件中,这样可以将所有的输出都存储到文件中。
。最后的 & 表示在后台运行
。2 表示输出错误信息到提示符窗口
。1 表示输出信息到提示符窗口,1前面的&要注意添加,否则还会创建一个名为 1 的文件

17、split -l 100 train_set_shuf.csv ./train_set_shuf_split_
说明:将train_set_shuf.csv按100行切分成多个文件,文件名为train_set_shuf_split_aa、train_set_shuf_split_ab、train_set_shuf_split_ac、……
16、rm -rf train_set.csv
说明:强制删除文件train_set.csv
15、shuf train_set.csv -o ./train_set_shuf.csv
说明:打乱train_set.csv行的顺序,并保存为新文件train_set_shuf.csv
14、cat data__* > train_set.csv
说明:合并所有data开头的文件,并保存为新文件 train_set.csv
13、sudo gzip -d data__*
说明:解压data__开头,且后缀为.gz的压缩文件。
12、sudo chown -R pengpeng:pengpeng data
说明:chown是权限管理命令,表示change owner,把文件data的拥有者和群组都改为pengpeng,普通用户不能将自己的文件改变成其它的拥有者,其操作权限一般为管理员,所以要加sudo,-R表示处理指定目录以及其子目录下的所有文件。

11、chmod -R 777 data
说明:chmod表示change mode,把data的权限设置为777,-R表示以递归的方式对data目录下的所有文件和子目录进行权限变更。常见的权限表示形式如下。

10、ls -lh
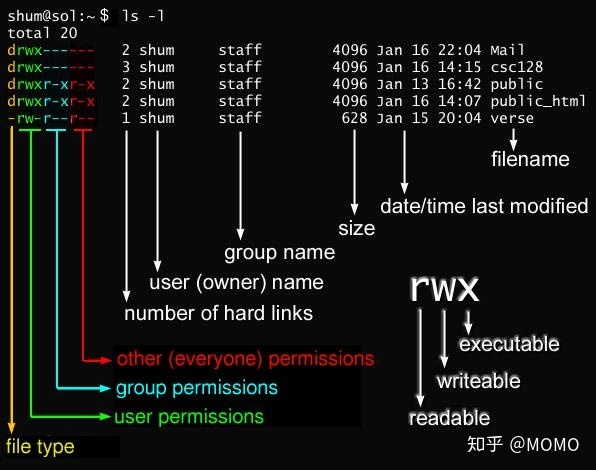
说明:以human方式罗列当前目录下的所有文件的详细信息,包括文件的属性,所属用户,所属组,文件大小,创建时间,文件名称,示例如下。
drwxr-xr-- 3 pengpeng pengpeng 4.0K Mar 14 10:16 data
文件属性:drwxr-xr-x,由10个字母组成,第1个字母代表文件的类型。字母“-”表示普通文件,字母“d”表示目录,是directory的缩写,字母“l”表示软链接文档。第2-10个字母含义如下图所示,“-”表示没有权限,r表示写读,w表示可写,x表示可执行(execute)。

只读,只写,可执行三种权限代表的权限数值分别为1,2,4,因此,上面“drwxr-xr--”表示将data文件的读、写、及运行权限赋予文件所有者(7 = 4 + 2 + 1),把读和运行的权限赋予群组用户(5 = 4 + 1),把只读的权限赋予其它用户(4 = 4),即所谓的754权限。不难得知,文件的最高权限为777.
所属用户:pengpeng
所属组:pengpeng
文件大小:4.0K
创建时间:Mar 14 10:16
文件名称:data,显示的颜色为蓝色,因为它是一个目录,不同颜色所代表的含义如下。

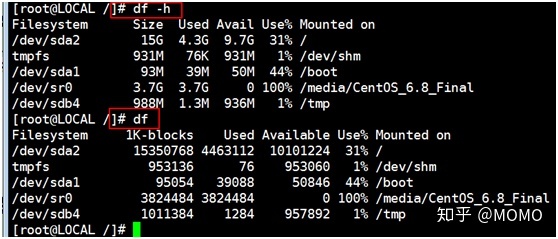
9、df -h
说明:disk file -human-readable 的缩写,表示以human方式(即以人们易读的GB、MB、KB等格式显示)查看各磁盘空间使用情况。

8、conda env remove -n tf-1-19
说明:Remove all packages in environment tf-1-19(先退出环境tf-1-19).

7、conda install tqdm 和 pip install sklearn
说明:出现报错ModuleNotFoundError: No module named 'tqdm',或出现报错ModuleNotFoundError: No module named 'sklearn',需要安装包tqdm和sklearn.
6、conda install tensorflow-gpu==1.19.0
说明:安装tensorflow-gpu版本1.19.0(先进入环境tf-1-19)
5、source activate tf-1-19 或 conda activate tf-1-19(在Anaconda Prompt上有效)
说明:To activate this environment tf-1-19,相反,退出环境,则用source deactivate。
4、conda create -n tf-1-19 python==3.7
说明:创建名称为tf-1-19为环境
3、conda env list
说明:列出所有环境
2、su 彭彭
说明:switch user 切换用户,不加用户名默认切换为root用户。

1、sudo su
说明:su不加用户名默认切换为root用户,sudo命令:superuser do 的简写,即使用超级用户来执行命令,一般是指root用户,如果不加sudo,则需要输入密码。















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









