






大数据时代,随着数据量的爆炸式增长,对于数据的处理速度要求也越来越高,以往基于MySQL的数据处理方案已无法满足大吞吐、低延迟的写入和高速查询的场景;百分点总结出了一套完整的解决方案,本文就带你一同了解VoltDB在流数据交互查询的应用实践。\
流式数据交互查询场景
\在百分点,每天有10亿条记录产生,针对这些大量实时产生的数据,不仅要做到实时写入,类似推荐调优、数据验证等查询要在秒级响应。有简单的单条验证,也有几个小时或一天的聚合计算,也有基于几千万/几亿数据表间的联合聚合查询。例如如下SQL查询:\

对于前期的MySQL方案,虽然已经根据一定规则做了人工的分库,但是对于上面SQL中的表Event落在单机上的数据量达到几千万,Result表也近千万,在这样的大表之间进行复杂的联合聚合查询,MySQL查下来要花费30分钟左右,甚至更长,或是没响应了。\
因此在针对同时要求大吞吐、低延迟的写入和高速查询的场景下,基于MySQL的现存方案完全无法实现。在不放弃SQL语句的便利基础上,经历过多种选型和方案调研,最终选择了VoltDB来解决此类问题。\
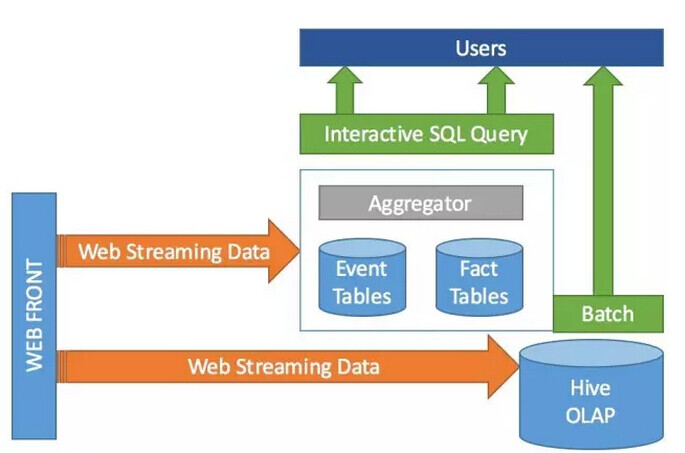
如上图,线上的全量流量,通过Streaming总线同时到达VoltDB和离线Hive表。不同的是,数据写入VoltDB使用实时方式,写入Hive使用批量方式。新的数据要求在极短的延迟内马上写入VoltDB待查询;批量写入Hive的数据也可以做到小时级以内刷写到对应分区。\
VoltDB简介
\VoltDB是一种开源的极速的内存关系型数据库,由Ingres和Postgres联合创始人Mike Stonebraker带领开发的NewSQL,提供社区版本和商业版本。VoltDB采用shard-nothing架构,既获得了NoSQL的良好可扩展性以及高吞吐量数据处理,又没有放弃传统关系型数据库的事务支持---ACID。\
一般VoltDB数据库集群由大量的站点(分区)组成,分散在多台机器上,数据的存储与处理都是分布在各个站点的,架构图如下所示:\
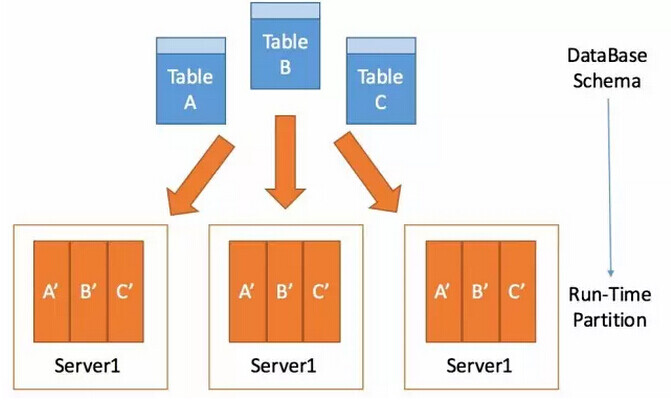
如上图,集群有3个节点、每个节点1个站点构成。因此图中的表都只分成3个区,当然也可以分成更多的区,那么一张表在单个节点上则存在多个分区。\
具体在使用上涉及以下几个概念:\
- \
客户端可以连接集群中任意一个节点,集群中所有节点是对等的,采用的也是水平分区的方式;
\ - \
每张表指定一个字段作为分区键,VoltDB使用该键采用哈希算法方式分布表数据到各个分区。事实上VoltDB中存在两种类型的表,一种是分区表,还有一种叫做”Replicated table”。”Replicated表”在每个节点存储的不是某张表的部分数据,而是全部数据,适用于小数据量的表。\
这里我们主要看重分区表,分区表的分区字段的选择很重要,应该尽量选择使数据分散均匀的字段。
VoltDB支持的客户端语言或接口:\
- \
C++
\ - \
C#
\ - \
Erlang
\ - \
Go
\ - \
Java
\ - \
Python
\ - \
Node.js
\ - \
JDBC 驱动接口
HTTPJSON 接口 (这意味着所有能实现http请求语言,都能编写VoltDB的客户端程序,且非常直观)\
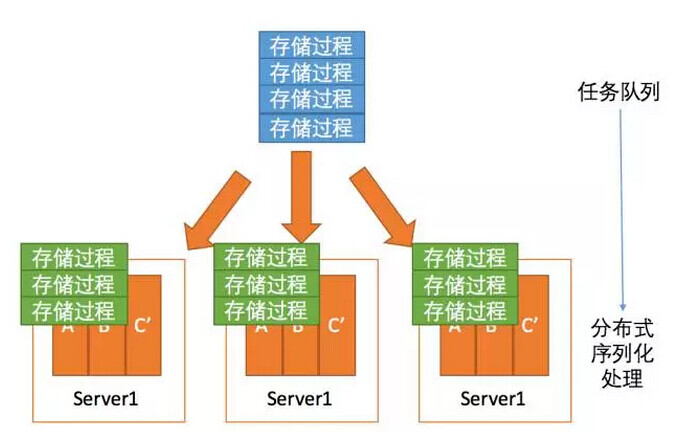
VoltDB的思想是,所有的事务都是由java实现的预编译存储过程完成,且所有的存储过程在任意站点上都是序列化执行的,这样使VoltDB达到了最高的隔离级别,且消除了锁的使用,很好地提高了处理速度。在官方的测试结果中,VoltDB可以轻松的扩展到39台服务器(300核),120个分区,每秒处理160万复杂事务。\
百分点的实践
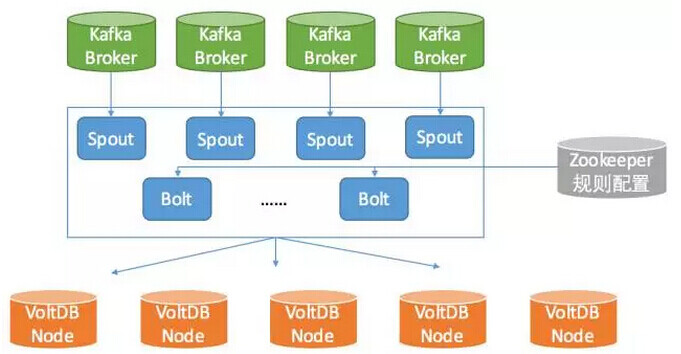
\VoltDB在百分点的使用如下图结构所示:\
- \
数据从Kafka接入,补充下我们使用的是社区版本,社区版是没有持久化到磁盘功能的。因此使用Kafka非常适合,一旦出现故障,可以迅速从Kafka中恢复数据。
\ - \
使用Storm分布式实时计算框架,作为VoltDB的客户端,同时也是Kafka的消费者,充分利用Storm框架的高可用性和低延时特性。从数据产生,到进入VoltDB,逐条写入延时在16ms内,如果优化成汇聚小batch写入,可以提升吞吐但降低写入延迟。
图中的Zookeeper保存数据写入VoltDB的规则配置,Storm拓扑通过监听配置决定写入VoltDB的数据。由于需要根据业务场景,创建合理的Schema、数据存储策略以及索引的应用。\
例如,在不同表之间的关联查询,关联条件是变化的,可能用户在两表间需要根据商品进行关联查询,也可能会要求根据用户信息进行关联查询,但对于VoltDB来讲,在分区表间进行Join查询时还要求同时符合VoltDB分区规则;由于数据量大,数据结构也存在一定的差异,而Storm拓扑内存资源总是有限的。\
于是我们采用了Zookeeper来做实时的动态配置,可以控制那些变化的数据进入VoltDB,也可以控制数据进入不同的Schema(本来是同一张表,但却使用了不同的分区策略而分成多个表)。\
另外,VoltDB目前还没有TTL的功能,我们构建自动剔除过期数据的程序,每隔10分钟删除一次最老的数据。这样一来,每天10亿条记录进出VoltDB,时刻保持着24小时数据的VoltDB应用平台就构建起来了。如下是在测试环境上进行的写入测试:\
CPU cores: 24\
Machines: 4\
Client threads: 64\
经过在测试环境中运行,在64线程时压测达到了100,000/s 的TPS,机器的平均CPU使用率在17%左右,而且VoltDB的处理能力基本上随着机器数增加呈线性增长。在高吞吐写入过程中,执行日常查询工作可以达到10秒内。\
上线后,部署5台机器,每台384G内存,同样24 cpu cores。写入的峰值接近70,000/s,相比原来同样的数据分布在13台MySQL机器上,在一台机器上(也就是部分数据上)花费30分钟的查询甚至使MySQL失去响应的复杂查询,到了VoltDB集群里基本上减少到十几秒,或者二十几秒,实现流式数据的交互查询。\

总结
\VoltDB 是一种性能极好的OLTP分布式内存SQL数据库,也存在一些缺陷,需要看使用场景,如其采用哈希的数据分布策略,进行范围查询可能不能体现出很大的优势。还有动态SQL,不支持动态表指定等等。\
数据库在大数据领域是核心组件,目前数据库产品非常多,可谓百花齐放,各有各的优势/不足,作为数据库的设计,关键还是要了解自己的需求,需要数据库来完成什么工作,再去理解每个数据库的功能和使用场景,这样才能根据需求选择合适的产品,设计出合理的Schema。\\\
感谢杜小芳对本文的审校。
\\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。














 3916
3916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









