






MVCC(Multi-Version Concurrent Control),即多版本并发控制协议,广泛使用于数据库系统。
MVCC基本原理
在介绍MVCC概念之前,我们先来想一下数据库系统里的一个问题:假设有多个用户同时读写数据库里的一行记录,那么怎么保证数据的一致性呢?一个基本的解决方法是对这一行记录加上一把锁,将不同用户对同一行记录的读写操作完全串行化执行,由于同一时刻只有一个用户在操作,因此一致性不存在问题。但是,它存在明显的性能问题:读会阻塞写,写也会阻塞读,整个数据库系统的并发性能将大打折扣。
MVCC(Multi-Version Concurrent Control),即多版本并发控制协议,它的目标是在保证数据一致性的前提下,提供一种高并发的访问性能。在MVCC协议中,每个用户在连接数据库时看到的是一个具有一致性状态的镜像,每个事务在提交到数据库之前对其他用户均是不可见的。当事务需要更新数据时,不会直接覆盖以前的数据,而是生成一个新的版本的数据,因此一条数据会有多个版本存储,但是同一时刻只有最新的版本号是有效的。因此,读的时候就可以保证总是以当前时刻的版本的数据可以被读到,不论这条数据后来是否被修改或删除。
在并发读写数据库时,读操作可能会不一致的数据(脏读)。为了避免这种情况,需要实现数据库的并发访问控制,最简单的方式就是加锁访问。由于,加锁会将读写操作串行化,所以不会出现不一致的状态。但是,读操作会被写操作阻塞,大幅降低读性能。在java concurrent包中,有copyonwrite系列的类,专门用于优化读远大于写的情况。而其优化的手段就是,在进行写操作时,将数据copy一份,不会影响原有数据,然后进行修改,修改完成后原子替换掉旧的数据,而读操作只会读取原有数据。通过这种方式实现写操作不会阻塞读操作,从而优化读效率。而写操作之间是要互斥的,并且每次写操作都会有一次copy,所以只适合读大于写的情况。
MVCC的原理与copyonwrite类似,全称是Multi-Version Concurrent Control,即多版本并发控制。在MVCC协议下,每个读操作会看到一个一致性的snapshot,并且可以实现非阻塞的读。MVCC允许数据具有多个版本,这个版本可以是时间戳或者是全局递增的事务ID,在同一个时间点,不同的事务看到的数据是不同的。
实现原理:
------------------------------------------------------------------------------------------> 时间轴
|-------R(T1)-----|
|-----------U(T2)-----------|
如上图,假设有两个并发操作R(T1)和U(T2),T1和T2是事务ID,T1小于T2,系统中包含数据a = 1(T1),R和W的操作如下:
R:read a (T1)
U:a = 2 (T2)
R(读操作)的版本T1表示要读取数据的版本,而之后写操作才会更新版本,读操作不会。在时间轴上,R晚于U,而由于U在R开始之后提交,所以对于R是不可见的。所以,R只会读取T1版本的数据,即a = 1。
由于在update操作提交之前,不能影响已有数据的一致性,所以不会改变旧的数据,update操作会被拆分成insert + delete。需要标记删除旧的数据,insert新的数据。只有update提交之后,才会影响后续的读操作。而对于读操作而且,只能读到在其之前的所有的写操作,正在执行中的写操作对其是不可见的。
上面说了一堆的虚的理论,下面来点干活,看一下MySQL的innodb引擎是如何实现MVCC的。innodb会为每一行添加两个字段,分别表示该行创建的版本和删除的版本,填入的是事务的版本号,这个版本号随着事务的创建不断递增。在repeated read的隔离级别(事务的隔离级别请看这篇文章)下,具体各种数据库操作的实现:
select:满足以下两个条件innodb会返回该行数据:(1)该行的创建版本号小于等于当前版本号,用于保证在select操作之前所有的操作已经执行落地。(2)该行的删除版本号大于当前版本或者为空。删除版本号大于当前版本意味着有一个并发事务将该行删除了。
insert:将新插入的行的创建版本号设置为当前系统的版本号。
delete:将要删除的行的删除版本号设置为当前系统的版本号。
update:不执行原地update,而是转换成insert + delete。将旧行的删除版本号设置为当前版本号,并将新行insert同时设置创建版本号为当前版本号。
其中,写操作(insert、delete和update)执行时,需要将系统版本号递增。
由于旧数据并不真正的删除,所以必须对这些数据进行清理,innodb会开启一个后台线程执行清理工作,具体的规则是将删除版本号小于当前系统版本的行删除,这个过程叫做purge。
通过MVCC很好的实现了事务的隔离性,可以达到repeated read级别,要实现serializable还必须加锁。
Mysql中的MVCC
MySQL到底是怎么实现MVCC的?这个问题无数人都在问,但google中并无答案,本文尝试从Mysql源码中寻找答案。
在Mysql中MVCC是在Innodb存储引擎中得到支持的,Innodb为每行记录都实现了三个隐藏字段:
- 6字节的事务ID(DB_TRX_ID )
- 7字节的回滚指针(DB_ROLL_PTR)
- 隐藏的ID
1. Innodb的事务相关概念
- redo log
redo log就是保存执行的SQL语句到一个指定的Log文件,当Mysql执行recovery时重新执行redo log记录的SQL操作即可。当客户端执行每条SQL(更新语句)时,redo log会被首先写入log buffer;当客户端执行COMMIT命令时,log buffer中的内容会被视情况刷新到磁盘。redo log在磁盘上作为一个独立的文件存在,即Innodb的log文件。 - undo log
与redo log相反,undo log是为回滚而用,具体内容就是copy事务前的数据库内容(行)到undo buffer,在适合的时间把undo buffer中的内容刷新到磁盘。undo buffer与redo buffer一样,也是环形缓冲,但当缓冲满的时候,undo buffer中的内容会也会被刷新到磁盘;与redo log不同的是,磁盘上不存在单独的undo log文件,所有的undo log均存放在主ibd数据文件中(表空间),即使客户端设置了每表一个数据文件也是如此。 - rollback segment
回滚段这个概念来自Oracle的事物模型,在Innodb中,undo log被划分为多个段,具体某行的undo log就保存在某个段中,称为回滚段。可以认为undo log和回滚段是同一意思。 - 锁
Innodb提供了基于行的锁,如果行的数量非常大,则在高并发下锁的数量也可能会比较大,据Innodb文档说,Innodb对锁进行了空间有效优化,即使并发量高也不会导致内存耗尽。
对行的锁有分两种:排他锁、共享锁。共享锁针对对,排他锁针对写,完全等同读写锁的概念。如果某个事务在更新某行(排他锁),则其他事物无论是读还是写本行都必须等待;如果某个事物读某行(共享锁),则其他读的事物无需等待,而写事物则需等待。通过共享锁,保证了多读之间的无等待性,但是锁的应用又依赖Mysql的事务隔离级别。 - 隔离级别
隔离级别用来限制事务直接的交互程度,目前有几个工业标准:
- READ_UNCOMMITTED:脏读
- READ_COMMITTED:读提交
- REPEATABLE_READ:重复读
- SERIALIZABLE:串行化
Innodb对四种类型都支持,脏读和串行化应用场景不多,读提交、重复读用的比较广泛,后面会介绍其实现方式。
2. 行的更新过程
1. 初始数据行
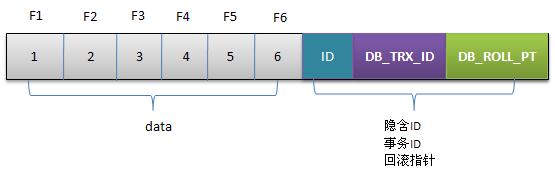
2.事务1更改该行的各字段的值
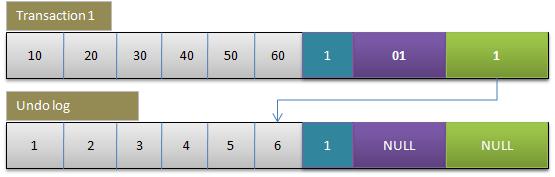
- 用排他锁锁定该行
- 记录redo log
- 把该行修改前的值Copy到undo log,即上图中下面的行
- 修改当前行的值,填写事务编号,使回滚指针指向undo log中的修改前的行
3.事务2修改该行的值
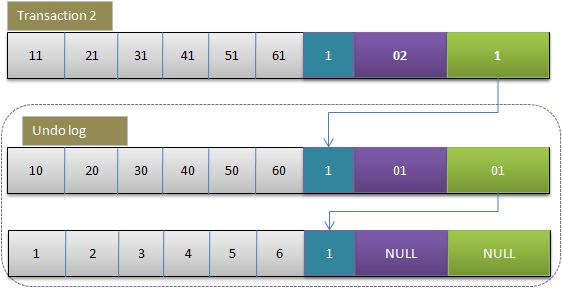
4. 事务提交
5. Insert Undo log
3. 事务级别
- READ_UNCOMMITTED
读未提交时,读事务直接读取主记录,无论更新事务是否完成 - READ_COMMITTED
读提交时,读事务每次都读取undo log中最近的版本,因此两次对同一字段的读可能读到不同的数据(幻读),但能保证每次都读到最新的数据。 - REPEATABLE_READ
每次都读取指定的版本,这样保证不会产生幻读,但可能读不到最新的数据 - SERIALIZABLE
锁表,读写相互阻塞,使用较少
4. MVCC
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本随意修改,个事务之间无干扰
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
5.总结
6. 参考资料
- Mysql官网
- http://blog.chinaunix.net/link.php?url=http://forge.mysql.com%2Fwiki%2FMySQL_Internals
- Understanding MySQL Internals
InnoDB MVCC何时创建read view
导读
InnoDB MVCC是事务一启动就创建read view,还是什么时候?
几个关于事务的基本概念
说到事务,我们不得不先说下什么是ACID、MVCC、consistent read、read view 等几个基本概念。
ACID
ACID是事务的原子性、一致性、隔离性、持久性4个单词的首字母缩写。所有的事务型数据库系统都遵循这4个特性,InnoDB亦是如此。关于ACID的具体解释请自行 google/bing。
MVCC
是multiversion concurrency control的简称,也就是多版本并发控制,是个很基本的概念。MVCC的作用是让事务在并行发生时,在一定隔离级别前提下,可以保证在某个事务中能实现一致性读,也就是该事务启动时根据某个条件读取到的数据,直到事务结束时,再次执行相同条件,还是读到同一份数据,不会发生变化(不会看到被其他并行事务修改的数据)。
有了 MVCC 就可以提高事务的并行度,因为可以利用锁机制实现资源控制而无需等待其他事务先执行。
read view
InnoDB MVCC使用的内部快照的意思。在不同的隔离级别下,事务启动时(有些情况下,可能是SQL语句开始时)看到的数据快照版本可能也不同。在RR、RC、RU(READ UNCOMMITTED)等几个隔离级别下会用到 read view。
一致性读
读请求基于某个时间点得到一份那时的数据快照,而不管同时其他事务对数据的修改。查询过程中,若其他事务修改了数据,那么就需要从 undo log中获取旧版本的数据。这么做可以有效避免因为需要加锁(来阻止其他事务同时对这些数据的修改)而导致事务并行度下降的问题。
在可重复读(REPEATABLE READ,简称RR)隔离级别下,数据快照版本是在第一个读请求发起时创建的。在读已提交(READ COMMITTED,简称RC)隔离级别下,则是在每次读请求时都会重新创建一份快照。
一致性读是InnoDB在RR和RC下处理SELECT请求的默认模式。由于一致性读不会在它请求的表上加锁,其他事务可以同时修改数据不受影响。
何时创建read view
其实,我们从上面的解释已经明白了,在RC隔离级别下,是每个SELECT都会获取最新的read view;而在RR隔离级别下,则是当事务中的第一个SELECT请求才创建read view。
我们通过几个例子来加强下。
1. RR级别
首先,确认隔离级别
yejr@imysql.com [test]>select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+
测试1:事务启动后立即发起SELECT请求
| session1 | session2 |
|---|---|
| begin; | begin; |
| select * from t1 where a=10; +----+------+---+ | a | b | c | +----+------+---+ | 10 | 8 | 1 | | select * from t1 where a=10; +----+------+---+ | 10 | 8 | 1 | 事务中第一个SELECT立即创建read view |
| update t1 set c=10 where a=10; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 | select * from t1 where a=10; +----+------+---+ | 10 | 8 | 1 | 再次读取,结果还是一样 |
| commit; 提交事务 | select * from t1 where a=10; +----+------+---+ | 10 | 8 | 1 | 再次读取,结果仍然一样 |
结论可见:RR中第一个SELECT已经创建好read view,之后不会再发生变化
测试2:另一个事物提交后才发起SELECT请求
| session1 | session2 |
|---|---|
| begin; | begin; |
| select * from t1 where a=10; +----+------+---+ | a | b | c | +----+------+---+ | 10 | 8 | 1 | | |
| update t1 set c=10 where a=10; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 | |
| commit; 提交事务 | select * from t1 where a=10; +----+------+---+ | 10 | 8 | 10 | session1提交后才发起SELECT,可以读取到最新版本 |
结论可见:RR中是发起SELECT时才创建read view,而不是事务刚启动时就创建
2. RC级别
根据上面提到的说法,RC隔离级别下,是每次发起SELECT都会创建read view,也就是每次SELECT都能读取到已经COMMIT的数据,所以才存在不可重复读、幻读 现象。
修改&确认隔离级别
yejr@imysql.com [test]>set session transaction isolation level read committed; yejr@imysql.com [test]>select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+
开始测试
| session1 | session2 |
|---|---|
| begin; | begin; |
| select * from t1 where a=10; +----+------+---+ | a | b | c | +----+------+---+ | 10 | 8 | 101 | | select * from t1 where a=10; +----+------+---+ | a | b | c | +----+------+---+ | 10 | 8 | 101 | |
| update t1 set c=102 where a=10;commit; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 0 rows affected (0.02 sec) | |
| | select * from t1 where a=10; +----+------+---+ | 10 | 8 | 102 | session1提交后再次发起SELECT,可以读取到最新版本 |
| begin;update t1 set c=103 where a=10;commit; Query OK, 0 rows affected (0.00 sec) Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 0 rows affected (0.02 sec) | |
| | select * from t1 where a=10; +----+------+---+ | 10 | 8 | 103 | 再次发起SELECT,又可以读取到最新版本 |
总结
-
RR级别下,事务中的第一个SELECT请求才开始创建read view;
-
RC级别下,事务中每次SELECT请求都会重新创建read view;
About Me
.............................................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162/abstract/1/)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版、个人简介及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● DBA宝典今日头条号地址:http://www.toutiao.com/c/user/6401772890/#mid=1564638659405826
.............................................................................................................................................
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-08-01 09:00 ~ 2017-08-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
.............................................................................................................................................
● 小麦苗的微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
● 小麦苗出版的数据库类丛书:http://blog.itpub.net/26736162/viewspace-2142121/
.............................................................................................................................................
使用微信客户端扫描下面的二维码来关注小麦苗的微信公众号(xiaomaimiaolhr)及QQ群(DBA宝典),学习最实用的数据库技术。

小麦苗的微信公众号 小麦苗的QQ群 小麦苗的微店
.............................................................................................................................................





来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2143025/,如需转载,请注明出处,否则将追究法律责任。














 9776
9776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









