






大家好,在我们使用 scrapy 进行网站数据采集的时,会遇到多个 spider 同时运行或者单个 spider 运行的情况,一般采取的是 shell 命令去运行,在分析 scrapy 的源码实现时,发现可以定制化启动,本篇文章我将分享启动代码和依靠启动代码分析部分 scrapy 的启动流程,希望能给读者朋友们带来帮助。
特别声明:本公众号文章只作为学术研究,不作为其他不法用途;如有侵权请联系作者删除。
立即加星标

每月看好文
目录
一、前言介绍
二、启动代码实现
三、scrapy启动分析
四、crawl源码分析
五、ExecutionEngine分析
六、downloader源码分析

一、前言介绍
本篇文章阅读完后,读者可以知晓使用 scrapy 时优雅的启动 spider 和了解 scrapy 的启动流程,让采集者在工作中更加的游刃有余,接下来我们进入正文吧。
二、启动代码实现
编写启动代码如下:
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from scrapy.spiderloader import SpiderLoader
import argparse
def run_spiders(spidername):
if spidername == "all":
spider_loader = SpiderLoader.from_settings(get_project_settings())
print(spider_loader.list())
current_setting = get_project_settings()
process = CrawlerProcess(current_setting, True)
for spidername in spider_loader.list():
process.crawl(spidername)
process.start()
else:
process = CrawlerProcess(get_project_settings())
process.crawl(spidername)
process.start()
if __name__ == '__main__':
'''
增加命令行传参可以启动单个爬虫
'''
my_arg = argparse.ArgumentParser("Scrapy-start")
my_arg.add_argument('--name', '-n', default='all', type=str, help='spider_name')
args = my_arg.parse_args()
run_spiders(args.name)思路:传参,可以传 all 或者传 spider 的名字,从而启动爬虫。
使用:可以把这个代码放到对应的位置,名字可以自定义。
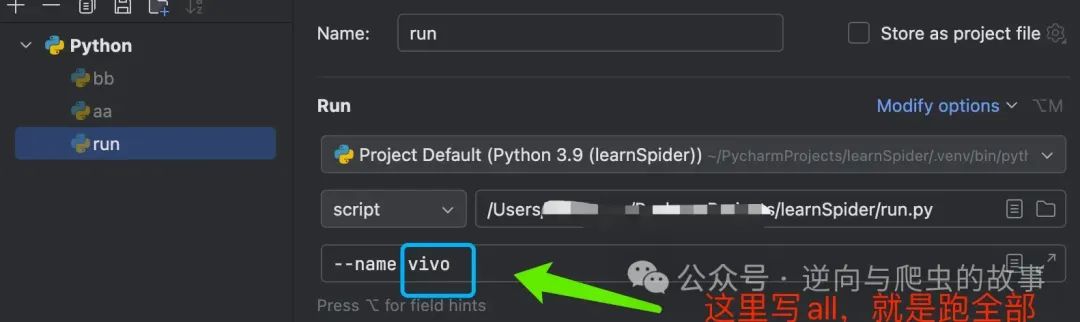
这个 name 对应 spider 中的 spider name。
三、scrapy 启动分析
上面的 class 作用:这个类用于在一个进程中运行多个爬虫。
从源码技术角度解读,主要做了如下功能:
启动 reactor 事件监听(start函数)
当接收到关闭信号时时停止 reactor(signal_shutdown 和 signal_kill)从父类 CrawlerRunner
首先初始化方法主要创建了 self._crawlers ,是个 set,里面可以存放多个 Crawler,self._active 也是个 set,里面是正在运行的 crawler。
立刻停止所有的在运行的 Crawler(stop 方法)
等待所有的 Crawler 运行完后再停止(join)
传入一个 spider 的实例类,然后使用 create_crawler 创建一个 crawler,然后调用 _crawl 方法并将加入 self.crawlers,然后调用创建的crawler的crawl进行爬取 (这里不会立即爬,会等到 reactor事件循环开始后)(crawl)
然后分析 crawl,等事件循环开启后,crawl 就开始爬取,那么爬取前做了什么?
总结:Craler 其实算我们的主角了,因为像一些关于爬虫内部相关的的东西都要在这里初始化并创建,他的存在是如果有一个 spider 要被创建那么就会有一个 crawler 去对应。例如初始化时会初始化下方的一些东西:
# 初始化其他可能用到的组件
# 用于管理和处理Scrapy扩展
self.extensions: Optional[ExtensionManager] = None
# 用于收集和报告爬虫运行期间的统计数据
self.stats: Optional[StatsCollector] = None
# 用于格式化日志消息
self.logformatter: Optional[LogFormatter] = None
# 用于生成请求的唯一标识符(指纹)
self.request_fingerprinter: Optional[RequestFingerprinter] = None
# 定义爬虫的行为和逻辑
self.spider: Optional[Spider] = None
# 管理和协调爬虫的执行
self.engine: Optional[ExecutionEngine] = None四、crawl 源码分析
首先会进行 spider 的创建;把自己设置的 setting 和 scrapy 本身的 setting 进行合并(合并的时候自己设置的为优先级高,如果同时拥有重复的,那么自己设置的会将scrapy 默认的进行覆盖);创建 engine,调用引擎的 open_spider 方法;并且调用了 engine的start 方法,这两个要重点观看,代码如下:
def crawl(self, *args: Any, **kwargs: Any) -> Generator[Deferred, Any, None]:
if self.crawling:
raise RuntimeError("Crawling already taking place")
if self._started:
warnings.warn(
"Running Crawler.crawl() more than once is deprecated.",
ScrapyDeprecationWarning,
stacklevel=2,
)
self.crawling = self._started = True
try:
self.spider = self._create_spider(*args, **kwargs)
self._apply_settings()
self._update_root_log_handler()
self.engine = self._create_engine()
start_requests = iter(self.spider.start_requests())
yield self.engine.open_spider(self.spider, start_requests)
yield maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
if self.engine is not None:
yield self.engine.close()
raise总结: 这个类里面还有一些其他方法,获取spider中间件(get_spider_middleware),获得pipline(get_iteme_pipline),获 得扩展 (get_extension),停止 spider(stop),接下来重头戏跑到了引擎里面。
五、ExecutionEngine 分析
分析的过程会具体以爬虫的运行为导向,会牵扯其实一些初始化的代码或者辅助的代码为辅。初始化方法里面会重点的创建 调度器;下载器;Scraper; 源码分析如下:
def __init__(self, crawler: "Crawler", spider_closed_callback: Callable) -> None:
self.crawler: "Crawler" = crawler # 爬虫实例
self.settings: Settings = crawler.settings # 爬虫设置
self.signals: SignalManager = crawler.signals # 信号管理器
assert crawler.logformatter # 确保logformatter存在
self.logformatter: LogFormatter = crawler.logformatter # 日志格式化器
self.slot: Optional[Slot] = None # 初始化时没有分配的槽位
self.spider: Optional[Spider] = None # 初始化时没有分配的spider
self.running: bool = False # 引擎是否在运行
self.paused: bool = False # 引擎是否暂停
self.scheduler_cls: Type["BaseScheduler"] = self._get_scheduler_class(crawler.settings) # 调度器类
downloader_cls: Type[Downloader] = load_object(self.settings["DOWNLOADER"]) # 下载器类
self.downloader: Downloader = downloader_cls(crawler) # 下载器实例
self.scraper = Scraper(crawler) # Scraper实例
self._spider_closed_callback: Callable = spider_closed_callback # Spider关闭回调函数
self.start_time: Optional[float] = None # 引擎启动时间然后我们分析 open_spider:
做了以下工作,主要对 itempipline 需要进行 open_spider 进行了处理(这里也说明了链接数据库啥的前置性,如果在 itempipline 写的情况下会被引擎主动调用),对 start_requests 进行了调度;统计状态;发送 spider_opened 的信号。源码解读如下:
def open_spider(
self, spider: Spider, start_requests: Iterable = (), close_if_idle: bool = True
) -> Generator[Deferred, Any, None]:
if self.slot is not None:
raise RuntimeError(f"No free spider slot when opening {spider.name!r}")
logger.info("Spider opened", extra={"spider": spider})
nextcall = CallLaterOnce(self._next_request)
# 创建调度器
scheduler = build_from_crawler(self.scheduler_cls, self.crawler)
# 处理请求,使用spider中间件的process_start_requests进行处理
start_requests = yield self.scraper.spidermw.process_start_requests(
start_requests, spider
)
self.slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.spider = spider
if hasattr(scheduler, "open"):
if d := scheduler.open(spider):
yield d
# 因为itempipline在我们实际的爬虫项目中需要例如先链接数据库等的操作,所以这里会主动调用
yield self.scraper.open_spider(spider)
assert self.crawler.stats
# 统计状态
self.crawler.stats.open_spider(spider)
# 异步的发送spider_opened信号
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
self.slot.nextcall.schedule()
self.slot.heartbeat.start(5)重点看如何实现的定时在事件循环中调度,通过这个方法可以每五秒主动调用一次,下面的四行代码形成了个逻辑去不间断的调用self._next_request以便达到处理请求的目的。源码解读如下:
nextcall = CallLaterOnce(self._next_request)
self.slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot.nextcall.schedule()
self.slot.heartbeat.start(5)
class CallLaterOnce(Generic[_T]):
"""Schedule a function to be called in the next reactor loop, but only if
it hasn't been already scheduled since the last time it ran.
调度一个函数在下一个事件循环中执行,但确保该函数自上次运行以来未被重复调度
举个例子
scheduler = CallLaterOnce(my_task, "hello", "world")
scheduler.schedule()
scheduler.schedule() # 第二次调用不会重复调度
reactor.callLater(1, scheduler.schedule) # 1秒后,可以再次调度
"""
def __init__(self, func: Callable[_P, _T], *a: _P.args, **kw: _P.kwargs):
self._func: Callable[_P, _T] = func
self._a: Tuple[Any, ...] = a
self._kw: Dict[str, Any] = kw
self._call: Optional[DelayedCall] = None
def schedule(self, delay: float = 0) -> None:
from twisted.internet import reactor
if self._call is None:
self._call = reactor.callLater(delay, self)
def cancel(self) -> None:
if self._call:
self._call.cancel()
def __call__(self) -> _T:
self._call = None
return self._func(*self._a, **self._kw)
class Slot:
def __init__(
self,
start_requests: Iterable[Request], # 接收一个可迭代对象 start_requests 作为参数,包含初始请求
close_if_idle: bool, # 是否在空闲时关闭的标志
nextcall: CallLaterOnce, # 下一个调用实例
scheduler: "BaseScheduler", # 调度器实例
) -> None:
self.closing: Optional[Deferred] = None # 初始化关闭的 Deferred 对象,可选类型
self.inprogress: Set[Request] = set() # 初始化进行中的 Request 集合
self.start_requests: Optional[Iterator[Request]] = iter(start_requests) # 将初始请求转化为可选类型的迭代器
self.close_if_idle: bool = close_if_idle # 设置是否空闲时关闭的标志
self.nextcall: CallLaterOnce = nextcall # 下一个调用实例
self.scheduler: "BaseScheduler" = scheduler # 调度器实例
self.heartbeat: LoopingCall = LoopingCall(nextcall.schedule) # 初始化心跳循环调用实例
def add_request(self, request: Request) -> None:
"""将请求添加到进行中的集合中"""
self.inprogress.add(request)
def remove_request(self, request: Request) -> None:
"""将请求从进行中的集合中移除,并检查是否触发关闭操作"""
self.inprogress.remove(request) # 从进行中的请求集合中移除指定请求
self._maybe_fire_closing() # 检查是否触发关闭操作
def close(self) -> Deferred:
"""启动关闭操作,并返回一个 Deferred 对象"""
self.closing = Deferred() # 创建一个新的 Deferred 对象,表示关闭操作
self._maybe_fire_closing() # 检查是否触发关闭操作
return self.closing # 返回关闭的 Deferred 对象
def _maybe_fire_closing(self) -> None:
"""如果没有进行中的请求且关闭操作已启动,则执行关闭操作"""
if self.closing is not None and not self.inprogress: # 如果关闭操作已启动且没有进行中的请求
if self.nextcall:
self.nextcall.cancel() # 取消下一个调用
if self.heartbeat.running:
self.heartbeat.stop() # 停止心跳循环
self.closing.callback(None) # 调用关闭的回调函数,表示关闭操作完成通过上面的代码,调用的函数是 _next_request:从 spider 一开始,那么调度器中的 request 肯定为空,那么会从 start_requests 进行取请求,如果调度器中存在 requests,那么会一直使用 _next_request_from_scheduler(),处理请求,如果说这 5s 的是主动去request,那么这 self._next_request_from_scheduler() 调用就是被动去 request。源码如下:
def _next_request(self) -> None:
"""
每次从start_requests中获取请求,然后调用self.crawl(),
"""
# slot是管理和调度的对象,如果为空直接返回
if self.slot is None:
return
# spider实例肯定不为空
assert self.spider is not None # 防止类型错误
# 如果爬虫已暂停,则返回 None。这意味着在暂停状态下,爬虫不会继续获取新的请求。
if self.paused:
return None
# 从调度器中获取下一个请求,直到需要退出或者没有更多的请求
while (
not self._needs_backout()
and self._next_request_from_scheduler() is not None
):
pass
# 从 start_requests 中获取请求并爬取
if self.slot.start_requests is not None and not self._needs_backout():
try:
request = next(self.slot.start_requests)
except StopIteration:
self.slot.start_requests = None # 没有初始请求
except Exception:
self.slot.start_requests = None # 处理初始请求时出错
logger.error(
"Error while obtaining start requests",
exc_info=True,
extra={"spider": self.spider},
)
else:
self.crawl(request) # 爬取请求
# 如果爬虫空闲且需要关闭,则处理空闲状态
if self.spider_is_idle() and self.slot.close_if_idle:
self._spider_idle() # 处理spider空闲接下来看下 _next_request_from_scheduler,从调度器中获取下一个请求,下载请求并处理下载结果,同时确保在不同阶段(处理下载结果、移除请求、调度下一个调用)记录任何错误,源码解读如下:
def _next_request_from_scheduler(self) -> Optional[Deferred]:
assert self.slot is not None # 防止类型错误
assert self.spider is not None # 防止类型错误
request = self.slot.scheduler.next_request() # 从调度器获取下一个请求
if request is None:
return None
d = self._download(request) # 下载请求
d.addBoth(self._handle_downloader_output, request) # 处理下载器输出
d.addErrback(
lambda f: logger.info(
"Error while handling downloader output",
exc_info=failure_to_exc_info(f),
extra={"spider": self.spider},
)
)
def _remove_request(_: Any) -> None:
assert self.slot
self.slot.remove_request(request) # 从槽位移除请求
d.addBoth(_remove_request)
d.addErrback(
lambda f: logger.info(
"Error while removing request from slot",
exc_info=failure_to_exc_info(f),
extra={"spider": self.spider},
)
)
slot = self.slot
d.addBoth(lambda _: slot.nextcall.schedule()) # 调度下一个调用
d.addErrback(
lambda f: logger.info(
"Error while scheduling new request",
exc_info=failure_to_exc_info(f),
extra={"spider": self.spider},
)
)
return d总结:拿到请求后,我们接下来分析请求是如何下载和解析的。
六、downloader源码分析
首先会将请求加入 slot 后,使用 downloader.fetch 进行处理 request,如果处理完成后返回的结果是 response,会发送 response_received 信号,然后调用 _on_complete 继续下一个调度,源码解读如下:
def _download(self, request: Request) -> Deferred:
assert self.slot is not None # 防止类型错误
self.slot.add_request(request) # 将请求加入槽位
def _on_success(result: Union[Response, Request]) -> Union[Response, Request]:
if not isinstance(result, (Response, Request)):
raise TypeError(
f"Incorrect type: expected Response or Request, got {type(result)}: {result!r}"
)
if isinstance(result, Response):
if result.request is None:
result.request = request
assert self.spider is not None
logkws = self.logformatter.crawled(result.request, result, self.spider)
if logkws is not None:
logger.log(
*logformatter_adapter(logkws), extra={"spider": self.spider}
)
self.signals.send_catch_log(
signal=signals.response_received,
response=result,
request=result.request,
spider=self.spider,
)
return result
def _on_complete(_: Any) -> Any:
assert self.slot is not None # 防止类型错误
self.slot.nextcall.schedule() # 调度下一个调用
return _
assert self.spider is not None
dwld = self.downloader.fetch(request, self.spider) # 执行下载器获取操作
dwld.addCallback(_on_success) # 下载成功回调
dwld.addBoth(_on_complete) # 下载完成后调度下一个调用
return dwld接下来我们看download.fetch如何处理的:首先调用中间件处理请求self.middleware.download,然后无论是否成功,都要从activate中移除这个请求,源码如下:
def fetch(self, request: Request, spider: Spider) -> Deferred:
# 将请求添加到活动集合中
def _deactivate(response: Response) -> Response:
self.active.remove(request)
return response
self.active.add(request)
# 通过中间件处理下载请求
dfd = self.middleware.download(self._enqueue_request, request, spider)
# 无论成功或失败,最终都要移除活动请求
return dfd.addBoth(_deactivate)这个 download 函数,会首先调用所有请求中间件的 process_requests 方法,如果 process_requests 返回一个 request 或者返回为空那么接着会进行执行下一个中间件的 process_requests 方法, 如果 process_requests 方法返回一个 response,那么下载器直接就返回 response 了,不会进行请求;如果不返回 response 的情况下,调用 download_dunc 函数进行下载;源码解读如下:
def download(
self, download_func: Callable, request: Request, spider: Spider
) -> Deferred:
# 定义一个嵌套的生成器函数用于处理请求
@inlineCallbacks
def process_request(request: Request) -> Generator[Deferred, Any, Any]:
for method in self.methods["process_request"]:
method = cast(Callable, method)
# 调用每个中间件的process_request方法
# 将python的协程转化为一个deferred对象
response = yield deferred_from_coro(
method(request=request, spider=spider)
)
# 检查返回值类型
if response is not None and not isinstance(
response, (Response, Request)
):
raise _InvalidOutput(
f"Middleware {method.__qualname__} must return None, Response or "
f"Request, got {response.__class__.__name__}"
)
## 如果中间件返回了 Response 或 Request,直接返回该结果
if response:
return response
# 如果所有中间件都未返回 Response 或 Request,调用下载函数
return (yield download_func(request=request, spider=spider))
# 定义一个嵌套的生成器函数用于处理响应
@inlineCallbacks
def process_response(
response: Union[Response, Request]
) -> Generator[Deferred, Any, Union[Response, Request]]:
if response is None:
raise TypeError("Received None in process_response")
elif isinstance(response, Request): # 这里判断如果process_request返回的是request就直接返回原始的request
return response
# 这里是yield download_func(request=request, spider=spider) 下载的内容,然后对其使用process_response
for method in self.methods["process_response"]:
method = cast(Callable, method)
# 调用每个中间件的 process_response 方法
response = yield deferred_from_coro(
method(request=request, response=response, spider=spider)
)
# 检查返回值类型是否为 Response 或 Request
if not isinstance(response, (Response, Request)):
raise _InvalidOutput(
f"Middleware {method.__qualname__} must return Response or Request, "
f"got {type(response)}"
)
# 如果中间件返回了 Request,直接返回该结果
if isinstance(response, Request):
return response
return response
@inlineCallbacks
def process_exception(
failure: Failure,
) -> Generator[Deferred, Any, Union[Failure, Response, Request]]:
exception = failure.value
for method in self.methods["process_exception"]:
method = cast(Callable, method)
# 调用每个中间件的 process_exception 方法
response = yield deferred_from_coro(
method(request=request, exception=exception, spider=spider)
)
# 检查返回值类型是否为 None、Response 或 Request
if response is not None and not isinstance(
response, (Response, Request)
):
raise _InvalidOutput(
f"Middleware {method.__qualname__} must return None, Response or "
f"Request, got {type(response)}"
)
if response:
return response
return failure
# 将 process_request 方法包装成 Deferred 对象
deferred = mustbe_deferred(process_request, request)
# 添加处理异常的回调
deferred.addErrback(process_exception)
# 添加处理响应的回调
deferred.addCallback(process_response)
# deferred最后的值,会是错误或者响应的回调产生的
return deferred通过分析可以查看到下载函数如下:
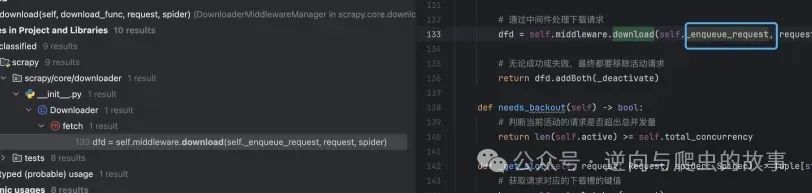
接下来分析图片中函数,代码解读如下:
def _enqueue_request(self, request: Request, spider: Spider) -> Deferred:
# 获取请求对应的下载槽
key, slot = self._get_slot(request, spider)
request.meta[self.DOWNLOAD_SLOT] = key
# 将请求添加到槽的活动请求集合中
def _deactivate(response: Response) -> Response:
slot.active.remove(request)
return response
slot.active.add(request)
self.signals.send_catch_log(
signal=signals.request_reached_downloader, request=request, spider=spider
)
# 创建一个新的Deferred对象,并将其添加到队列中
deferred: Deferred = Deferred().addBoth(_deactivate)
slot.queue.append((request, deferred))
# 处理队列中的请求
self._process_queue(spider, slot)
return deferred
接下来分析process_queue
def _process_queue(self, spider: Spider, slot: Slot) -> None:
from twisted.internet import reactor
# 如果存在活动的延迟调用,直接返回
if slot.latercall and slot.latercall.active():
return
# 处理请求队列,如果配置了下载延迟,则延迟处理
now = time()
delay = slot.download_delay()
if delay:
penalty = delay - now + slot.lastseen
if penalty > 0:
slot.latercall = reactor.callLater(
penalty, self._process_queue, spider, slot
)
return
# 处理队列中的请求,前提是有可用的传输槽
while slot.queue and slot.free_transfer_slots() > 0:
slot.lastseen = now
request, deferred = slot.queue.popleft()
dfd = self._download(slot, request, spider)
dfd.chainDeferred(deferred)
# 如果配置了请求间隔,避免突发请求
if delay:
self._process_queue(spider, slot)
break
接下来再分析
def _download(self, slot: Slot, request: Request, spider: Spider) -> Deferred:
# 创建下载deferred对象
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
# 下载完成后发送响应下载信号
def _downloaded(response: Response) -> Response:
self.signals.send_catch_log(
signal=signals.response_downloaded,
response=response,
request=request,
spider=spider,
)
return response
dfd.addCallback(_downloaded)
# 将请求添加到传输集合中,并在完成后移除
slot.transferring.add(request)
def finish_transferring(_: Any) -> Any:
slot.transferring.remove(request)
self._process_queue(spider, slot)
self.signals.send_catch_log(
signal=signals.request_left_downloader, request=request, spider=spider
)
return _
return dfd.addBoth(finish_transferring)下载完成后,我们回到 _next_request_from_scheduler的d.addBoth(self._handle_downloader_output, request) 处理下载器的结果,我们在上方代码 def download(self, download_func: Callable, request: Request, spider: Spider) 的 process_request 里面已经知道,如果直接返回一个 requqest 或 response 对象,那么会直接返回到现在处理的结果上, 所以处理这个结果的时候,会有两种可能如果是 Request 类型的那么继续抓取,是 response 直接进行解析;代码解读如下:
def _handle_downloader_output(
self, result: Union[Request, Response, Failure], request: Request
) -> Optional[Deferred]:
"""
从这里处理从process_request何process_response得内容,进行解析发给item
"""
assert self.spider is not None # 防止类型错误
if not isinstance(result, (Request, Response, Failure)):
raise TypeError(
f"Incorrect type: expected Request, Response or Failure, got {type(result)}: {result!r}"
)
# 下载器中间件可以返回请求(例如,重定向)
if isinstance(result, Request):
self.crawl(result)
return None
# 其实这个scraper,就是处理响应的。。。。
d = self.scraper.enqueue_scrape(result, request, self.spider) # 将结果加入scraper队列
d.addErrback(
lambda f: logger.error(
"Error while enqueuing downloader output",
exc_info=failure_to_exc_info(f),
extra={"spider": self.spider},
)
)
return d接下来我们看看 scrapy 是如何处理响应的,代码解读如下:
def enqueue_scrape(
self, result: Union[Response, Failure], request: Request, spider: Spider
) -> Deferred:
"""
处理response后(如果parse有requests处理requests,不然处理item,如果啥也没有直接不处理)。
参数:
- result: Union[Response, Failure] - 要处理的结果(响应或失败)
- request: Request - 相应的请求对象
- spider: Spider - 爬虫对象
返回值:
- Deferred - 处理结果的 Deferred 对象
"""
if self.slot is None:
raise RuntimeError("Scraper slot not assigned") # 如果未分配 Scraper slot,则引发运行时错误
dfd = self.slot.add_response_request(result, request) # 将结果与请求添加到处理队列中
def finish_scraping(_: Any) -> Any:
assert self.slot is not None
self.slot.finish_response(result, request) # 完成处理后,结束响应的处理
self._check_if_closing(spider) # 检查是否需要关闭爬虫
self._scrape_next(spider) # 进行下一步的抓取操作
return _
dfd.addBoth(finish_scraping) # 添加完成处理的回调函数
dfd.addErrback(
lambda f: logger.error(
"Scraper bug processing %(request)s",
{"request": request},
exc_info=failure_to_exc_info(f),
extra={"spider": spider},
)
) # 添加错误处理的回调函数,记录日志
self._scrape_next(spider) # 执行下一步的抓取操作
return dfd # 返回处理结果的 Deferred 对象
def _scrape_next(self, spider: Spider) -> None:
"""
从爬虫的请求队列中获取下一个待处理的响应和请求,处理后将结果与回调Deferred对象关联起来。
"""
assert self.slot is not None # 断言验证对象存在
while self.slot.queue:
# 从队列中获取下一个要处理的响应、请求和对应的回调Deferred对象
response, request, deferred = self.slot.next_response_request_deferred()
# 调用 _scrape 方法处理响应和请求,并将结果的Deferred对象与传入的回调Deferred对象关联起来
self._scrape(response, request, spider).chainDeferred(deferred)
def _scrape(
self, result: Union[Response, Failure], request: Request, spider: Spider
) -> Deferred:
"""
处理下载的成功响应或失败的响应,通过爬虫的回调函数/错误回调函数进行处理
"""
if not isinstance(result, (Response, Failure)):
raise TypeError(
f"Incorrect type: expected Response or Failure, got {type(result)}: {result!r}"
) # 如果result不是Response或Failure类型,则抛出类型错误异常
dfd = self._scrape2(
result, request, spider
) # 返回爬虫处理后的输出结果
dfd.addErrback(self.handle_spider_error, request, result, spider) # 添加错误回调函数
dfd.addCallback(
self.handle_spider_output, request, cast(Response, result), spider
) # 添加成功回调函数,处理爬虫的输出结果
return dfd # 返回处理结果的Deferred对象
def handle_spider_output(
self,
result: Union[Iterable, AsyncIterable],
request: Request,
response: Response,
spider: Spider,
) -> Deferred:
"""处理爬虫输出的结果,这个是处理parse的1输出的"""
if not result:
return defer_succeed(None) # 如果结果为空,直接返回一个成功的Deferred对象
it: Union[Iterable, AsyncIterable]
if isinstance(result, AsyncIterable):
it = aiter_errback(
result, self.handle_spider_error, request, response, spider
) # 处理异步可迭代对象
dfd = parallel_async(
it,
self.concurrent_items,
self._process_spidermw_output,
request,
response,
spider,
) # 并发处理异步可迭代对象中的输出
else:
it = iter_errback(
result, self.handle_spider_error, request, response, spider
) # 处理可迭代对象
dfd = parallel(
it,
self.concurrent_items,
self._process_spidermw_output,
request,
response,
spider,
) # 并发处理可迭代对象中的输出
return dfd # 返回处理结果的Deferred对象
def _process_spidermw_output(
self, output: Any, request: Request, response: Response, spider: Spider
) -> Optional[Deferred]:
"""Process each Request/Item (given in the output parameter) returned
from the given spider
如果parse方法yield的是一个请求,那么交给crawl继续去爬取
如果是一个item,那么调用pipeline的process_item去处理,
在这里也印证了为什么我们使用parse来yield requets或者item
"""
assert self.slot is not None # typing
if isinstance(output, Request):
assert self.crawler.engine is not None # typing
self.crawler.engine.crawl(request=output)
elif is_item(output):
self.slot.itemproc_size += 1
dfd = self.itemproc.process_item(output, spider)
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error(
"Spider must return request, item, or None, got %(typename)r in %(request)s",
{"request": request, "typename": typename},
extra={"spider": spider},
)
return None上面就是其完整流程了,其实还有一个问题?spider 的解析方法 是哪调用的?
答:其实是 scrape2,通过调用 spider 中 spider 中间件,然后通过 call_spider,调用的回调方法,代码解读如下:
def _scrape2(
self, result: Union[Response, Failure], request: Request, spider: Spider
) -> Deferred:
"""
Handle the different cases of request's result been a Response or a Failure
"""
if isinstance(result, Response):
# 在这里会调用spider的parse方法,或者requests拥有回调函数的情况下
return self.spidermw.scrape_response(
self.call_spider, result, request, spider
)
# else result is a Failure
dfd = self.call_spider(result, request, spider)
return dfd.addErrback(self._log_download_errors, result, request, spider)
def scrape_response(
self,
scrape_func: ScrapeFunc,
response: Response,
request: Request,
spider: Spider,
) -> Deferred:
async def process_callback_output(
result: Union[Iterable, AsyncIterable]
) -> Union[MutableChain, MutableAsyncChain]:
return await self._process_callback_output(response, spider, result)
def process_spider_exception(_failure: Failure) -> Union[Failure, MutableChain]:
return self._process_spider_exception(response, spider, _failure)
dfd = mustbe_deferred(
self._process_spider_input, scrape_func, response, request, spider
)
dfd.addCallback(deferred_f_from_coro_f(process_callback_output))
dfd.addErrback(process_spider_exception)
return dfd
def _process_spider_input(
self,
scrape_func: ScrapeFunc,
response: Response,
request: Request,
spider: Spider,
) -> Any:
for method in self.methods["process_spider_input"]:
method = cast(Callable, method)
try:
result = method(response=response, spider=spider)
if result is not None:
msg = (
f"{method.__qualname__} must return None "
f"or raise an exception, got {type(result)}"
)
raise _InvalidOutput(msg)
except _InvalidOutput:
raise
except Exception:
return scrape_func(Failure(), request, spider)
# 这个scrape_func在有时就可能是call_spider
return scrape_func(response, request, spider)
def call_spider(
self, result: Union[Response, Failure], request: Request, spider: Spider
) -> Deferred:
"""
这里会处理request的parse,缠上item或者request请求
"""
if isinstance(result, Response):
if getattr(result, "request", None) is None:
result.request = request
assert result.request
callback = result.request.callback or spider._parse
warn_on_generator_with_return_value(spider, callback)
dfd = defer_succeed(result)
dfd.addCallbacks(
callback=callback, callbackKeywords=result.request.cb_kwargs
)
else: # result is a Failure
# TODO: properly type adding this attribute to a Failure
result.request = request # type: ignore[attr-defined]
dfd = defer_fail(result)
if request.errback:
warn_on_generator_with_return_value(spider, request.errback)
dfd.addErrback(request.errback)
return dfd.addCallback(iterate_spider_output)本篇分享到这里就结束了,感谢大家的阅读和支持。如果你对爬虫逆向分析、验证码破解及其他技术话题感兴趣,记得关注我的公众号,不错过下一期的更新。我们将继续深入探讨各种技术细节和实用技巧,一起探索数字世界的奥秘。期待与你在下期文章中再见,一起学习,一起进步!☀️☀️
好文和朋友一起看~















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









