







为什么需要将 Mysql 数据同步到 Elasticsearch
Mysql 作为传统的关系型数据库,主要面向 OLTP,性能优异,支持事务,但是在一些全文检索,复杂查询上面并不快。Elasticsearch 底层基于 Lucense 实现,天然分布式,采用倒排索引存储数据,全文检索效率很高,使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。
kafka 连接器同步方案
Debezium 是捕获数据实时动态变化(change data capture,CDC)的开源的分布式同步平台。能实时捕获到数据源(Mysql、Mongo、PostgreSql)的:新增(inserts)、更新(updates)、删除(deletes)操作,实时同步到Kafka,稳定性强且速度非常快。Debezium 是基于 kafka Connect 的开源项目。
Elasticsearch-Connector 使用主题+分区+偏移量作为事件的唯一标识符,然后在 Elasticsearch 中转换为唯一的文档。它支持使用 Kafka 消息中的键值作为 Elasticsearch 中的文档 Id,并且确保更新按顺序写入 Elasticsearch。
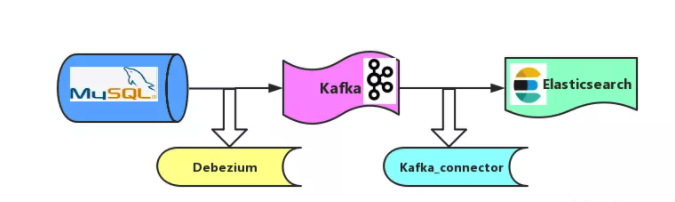
如图,Mysql 到 ES 的同步策略,采取“曲线救国”机制。
- 步骤1: 基 Debezium 的binlog 机制,将 Mysql 数据同步到Kafka。
- 步骤2: 基于 Kafka_connector 机制,将 Kafka 数据同步到 Elasticsearch。
MySQL 配置
开启 binlog
Debezium 使用 MySQL 的 binlog 机制实现数据动态变化监测,所以需要 Mysql 提前配置 binlog。
编辑 /etc/my.cnf 的 mysqld 下添加如下配置:
server-id = 7777
log_bin = mysql-bin
binlog_format = row
binlog_row_image = full
expire_logs_days = 10
然后,重启一下 Mysql 以使得 binlog 生效。
systemctl restart mysqld.service
检查 binlog 是否开启:
[root@mysql-5 ~]# mysqladmin variables -uroot@123456 | grep log_bin
| log_bin | ON
创建用户
创建用户 debezium,密码 dbz,并授予相关权限:
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium' IDENTIFIED BY 'dbz';
创建表并插入数据
mysql> create database school;
mysql> use school;
mysql> create table student (name varchar(20),age int);
mysql> insert into student values('tom',18),('jack',19),('lisa',18);
使用 Debezium 同步 MySQL 数据到 Kafka
安装 Debezium
下载 Debezium 压缩包:
https://www.confluent.io/hub/debezium/debezium-connector-mysql
将压缩包解压到自定义的目录,只要 libs 目录中的 jar 包即可:
[root@kafka1 connect]# ls -l /usr/local/kafka/connect/debezium-connector-mysql
total 9412
-rw-r--r--. 1 root root 337904 Apr 3 22:54 antlr4-runtime-4.7.2.jar
-rw-r--r--. 1 root root 20270 Apr 3 22:54 debezium-api-1.4.0.Final.jar
-rw-r--r--. 1 root root 264910 Apr 3 22:54 debezium-connector-mysql-1.4.0.Final.jar
-rw-r--r--. 1 root root 823056 Apr 3 22:54 debezium-core-1.4.0.Final.jar
-rw-r--r--. 1 root root 2733898 Apr 3 22:54 debezium-ddl-parser-1.4.0.Final.jar
-rw-r--r--. 1 root root 4617 Apr 3 22:54 failureaccess-1.0.1.jar
-rw-r--r--. 1 root root 2858426 Apr 3 22:54 guava-30.0-jre.jar
-rw-r--r--. 1 root root 182602 Apr 3 22:54 mysql-binlog-connector-java-0.23.1.jar
-rw-r--r--. 1 root root 2397321 Apr 3 22:54 mysql-connector-java-8.0.21.jar
修改 Kafka 的 config/connect-distributed.properties 文件,在最后添加如下内容,这里注意 plugin.path 只写到放 jar 包的上一层目录:
plugin.path=/usr/local/kafka/connect
启动 Kafka 连接器
bin/connect-distributed.sh config/connect-distributed.properties
启动完成后,可以查看刚刚安装的 debezium 插件:
[root@kafka1 connect]# curl http://kafka1:8083/connector-plugins -s | jq
[
{
"class": "io.debezium.connector.mysql.MySqlConnector",
"type": "source",
"version": "1.4.0.Final"
}
]
新增 connector 连接器实例
为了方便起见,先编辑一个文件 mysql-connector.json:
{
"name": "mysql-connector", #自定义连接器实例名
"config":
{
"connector.class": "io.debezium.connector.mysql.MySqlConnector", #连接器类库
"database.hostname": "192.168.1.14", #mysql地址
"database.port": "3306", #mysql端口号
"database.user": "debezium", #用户名
"database.password": "dbz", #密码
"database.server.id": "7777", #对应mysql中的server-id的配置。
"database.server.name": "cr7-demo", #逻辑名称,每个connector确保唯一,作为写入数据的kafka topic的前缀名称
"database.history.kafka.bootstrap.servers": "kafka1:9092,kafka2:9092,kafka3:9092", #kafka集群地址
"database.history.kafka.topic": "cr7-schema-changes-inventory", #存储数据库的Shcema的记录信息,而非写入数据的topic
"include.schema.changes": "true",
"database.whitelist": "school", #待同步的mysql数据库名
"table.whitlelist": "student" #待同步的mysq表名
}
}
通过 Http Post 请求新增 connector 连接器实例:
curl -X POST -H "Content-Type:application/json" --data @mysql-connector.json http://kafka1:8083/connectors
查看新增的连接器实例:
[root@kafka1 connect]# curl http://kafka1:8083/connectors -s | jq
[
"mysql-connector"
]
查看连接器实例运行状态:
[root@kafka1 connect]# curl http://kafka1:8083/connectors/mysql-connector/status -s | jq
{
"name": "mysql-connector",
"connector": {
"state": "RUNNING",
"worker_id": "192.168.1.87:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "192.168.1.87:8083"
}
],
"type": "source"
}
查看 Kafka 数据
使用下面命令可以消费到 Debezium 根据 binlog 更新写入到 Kafka Topic 中的数据:
- topic 的名字为前面定义的前缀.数据库名.表名。
--from-beginning表示从头开始消费,如果不加该参数,就只能消费到新增的消息。
kafka-console-consumer.sh \
--bootstrap-server kafka1:9092 \
--topic cr7-demo.school.student \
--from-beginning
Kafka 数据同步到 Elasticsearch
安装 elasticsearch-connector
下载 elasticsearch-connector 压缩包:
https://www.confluent.io/hub/confluentinc/kafka-connect-elasticsearch
下载完成后解压到自定义目录,只要 libs 目录下的 jar 包即可,然后重启 Kafka 连接器:
[root@kafka1 kafka]# ls -l /usr/local/kafka/connect/elasticsearch-connector
total 27048
-rw-r--r--. 1 root root 59860 Apr 3 20:18 aggs-matrix-stats-client-7.0.1.jar
-rw-r--r--. 1 root root 353793 Apr 3 20:18 commons-codec-1.15.jar
-rw-r--r--. 1 root root 61829 Apr 3 20:18 commons-logging-1.2.jar
-rw-r--r--. 1 root root 17265 Apr 3 20:18 common-utils-6.0.1.jar
-rw-r--r--. 1 root root 99939 Apr 3 20:18 compiler-0.9.3.jar
-rw-r--r--. 1 root root 10997301 Apr 3 20:18 elasticsearch-7.0.1.jar
-rw-r--r--. 1 root root 16058 Apr 3 20:18 elasticsearch-cli-7.0.1.jar
-rw-r--r--. 1 root root 38776 Apr 3 20:18 elasticsearch-core-7.0.1.jar
-rw-r--r--. 1 root root 31303 Apr 3 20:18 elasticsearch-geo-7.0.1.jar
-rw-r--r--. 1 root root 62091 Apr 3 20:18 elasticsearch-rest-client-7.0.1.jar
-rw-r--r--. 1 root root 989767 Apr 3 20:18 elasticsearch-rest-high-level-client-7.0.1.jar
-rw-r--r--. 1 root root 10876 Apr 3 20:18 elasticsearch-secure-sm-7.0.1.jar
-rw-r--r--. 1 root root 117634 Apr 3 20:18 elasticsearch-x-content-7.0.1.jar
......
查看安装的 elasticsearch-connector 插件:
[root@kafka1 connect]# curl http://kafka1:8083/connector-plugins -s | jq
[
{
"class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type": "sink",
"version": "11.0.3"
},
{
"class": "io.debezium.connector.mysql.MySqlConnector",
"type": "source",
"version": "1.4.0.Final"
}
]
为了方便起见,先编辑一个文件 elasticsearch-connector.json:
{
"name": "elasticsearch-connector", #自定义连接器实例名
"config":
{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector", #连接器类库
"connection.url": "http://192.168.1.171:9200", #Elasticsearch地址
"key.ignore": "true", #Kafka 消息没有指定 key,因此要指定该参数,否则无法消费到 Elasticsearch
"topics": "cr7-demo.school.student" #kafka topic名字
}
}
通过 Http Post 请求新增 connector 连接器实例:
curl -X POST -H "Content-Type:application/json" --data @elasticsearch-connector.json http://kafka1:8083/connectors
查看创建的连接器实例:
[root@kafka1 connect]# curl http://kafka1:8083/connectors -s | jq
[
"mysql-connector",
"elasticsearch-connector"
]
查看 Elasticsearch 数据
在 Elasticsearch 上查询 cr7-demo.school.student 索引可以看到数据,索引名字和 Kafka Topic 名字一样:
GET cr7-demo.school.student/_search
#返回结果:
{
"took" : 190,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "cr7-demo.school.student",
"_type" : "_doc",
"_id" : "cr7-demo.school.student+2+0",
"_score" : 1.0,
"_source" : {
"before" : null,
"after" : {
"name" : "tom", #字段内容
"age" : 18
},
"source" : {
"name" : "cr7-demo",
"server_id" : 0,
"ts_sec" : 0,
"gtid" : null,
"file" : "mysql-bin.000001", #binlog文件
"pos" : 995,
"row" : 0,
"snapshot" : true,
"thread" : null,
"db" : "school", #数据库名
"table" : "student" #表名
},
"op" : "c",
"ts_ms" : 1617450734795
}
},
}
......
}
参考链接
- https://www.confluent.io/blog/kafka-elasticsearch-connector-tutorial/
- https://mp.weixin.qq.com/s/XTvWpTq2YsFBzT2gojNoHA
- https://rmoff.net/2018/03/24/streaming-data-from-mysql-into-kafka-with-kafka-connect-and-debezium/
欢迎关注















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









