






12.跨域
一、为什么会出现跨域问题
出于浏览器的同源策略限制。同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port);
二、什么是跨域
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域
需要注意的是:没写默认的端口号是80

13.主流浏览器内核私有属性css前缀:
mozilla内核 (firefox,flock等) -moz
webkit内核(safari,chrome等) -webkit
opera内核(opera浏览器) -o
trident内核(ie浏览器) -ms
14.JavaScript 是一门什么样的语言,它有哪些特点?
javaScript 一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它 的解释器被称为 JavaScript 引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在 HTML 网页上使用,用来给HTML网页增加动态功能。JavaScript兼容于ECMA标准,因此也称为ECMAScript。
基本特点 :
1.是一种解释性脚本语言(代码不进行预编译)。
2.主要用来向 HTML(标准通用标记语言下的一个应用)页面添加交互行为。
3.可以直接嵌入 HTML 页面,但写成单独的 js 文件有利于结构和行为的分离。
4.跨平台特性,在绝大多数浏览器的支持下,可以在多种平台下运行(如 Windows、Linux、Mac、 Android、iOS 等)。
15、CSS 选择符有哪些?哪些属性可以继承?优先级算法如何计算? CSS3新增伪类有哪些?
1.id选择器( # myid)
2.类选择器(.myclassname)
3.标签选择器(div, h1, p)
4.相邻选择器(h1 + p)
5.子选择器(ul > li)
6.后代选择器(li a)
7.通配符选择器( *)
8.属性选择器(a[rel = "external"])
9.伪类选择器(a: hover, li: nth - child)
**可继承的样式: **
font-size font-family color, UL LI DL DD DT;
不可继承的样式:
border padding margin width height
优先级
优先级就近原则,同权重情况下样式定义最近者为准,载入样式以最后载入的定位为准;
优先级为:
!important > id > class > tag
important 比 内联优先级高
CSS3新增伪类举例
p:first-of-type 选择属于其父元素的首个<p> 元素的每个<p>元素。
p:last-of-type 选择属于其父元素的最后 <p>元素的每个<p>元素。
p:only-of-type 选择属于其父元素唯一的<p>元素的每个<p>元素。
p:only-child 选择属于其父元素的唯一子元素的每个<p>元素。
p:nth-child(2) 选择属于其父元素的第二个子元素的每个<p>元素。
:enabled :disabled 控制表单控件的禁用状态。
:checked 单选框或复选框被选中。
16常用的HTTP方法有哪些
GET:请求指定的页面信息,返回实体主体;
HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于捕获报头;
使用HEAD方法有以下优点:
- 在不获取资源的情况下了解资源的情况(比如:判断其类型);
- 通过查看响应的状态码,看看某个对象是否存在;
- 通过查看首部,测试资源是否被修改了
POST:向指定资源提交数据进行处理请求(比如表单提交或者上传文件),。数据被包含在请求体中。
PUT:从客户端向服务端传送数据取代指定的文档的内容;
DELETE方法所做的事情就是请服务器删除请求URL所指定的资源。但客户端应用程序无法保证删除操作一定会被执行。因为HTTP规范允许服务器在不通知客户端的情况下撤销请求。
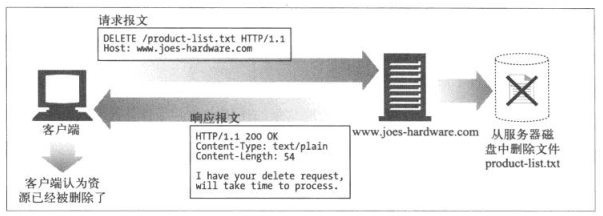
CONNNECT:HTTP1.1协议中预留给能够将连接方式改为管道方式的代理服务器;
OPTIONS:允许客户端查看服务器的性能;
TRACE:回显服务器的请求,主要用于测试或者诊断。
GET和POST 的区别
1.get是从服务器上获取数据,post是向服务器传送数据。
2.GET请求把参数包含在URL中,将请求信息放在URL后面,POST请求通过request body传递参数,将请求信息放置在报文体中。
3.get传送的数据量较小,不能大于2KB。post传送的数据量较大,一般被默认为不受限制。但理论上,IIS4中最大量为80KB,IIS5中为100KB。
4.get安全性非常低,get设计成传输数据,一般都在地址栏里面可以看到,post安全性较高,post传递数据比较隐私,所以在地址栏看不到, 如果没有加密,他们安全级别都是一样的,随便一个监听器都可以把所有的数据监听到。
5.GET请求能够被缓存,GET请求会保存在浏览器的浏览记录中,以GET请求的URL能够保存为浏览器书签,post请求不具有这些功能。
6.HTTP的底层是TCP/IP,GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。GET和POST能做的事情是一样一样的。你要给GET加上request body,给POST带上url参数,技术上是完全行的通的。
7.GET产生一个TCP数据包,对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);POST产生两个TCP数据包,对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据),并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
17utf8编码中汉字占多少字节
占2个字节的:带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码
占3个字节的:基本等同于GBK,含21000多个汉字
占4个字节的:中日韩超大字符集里面的汉字,有5万多个
一个utf8数字占1个字节
一个utf8英文字母占1个字节
少数是汉字每个占用3个字节,多数占用4个字节。
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
3.Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示Unicode。2)Unicode在很长一段时间内无法推广,直到互联网的出现。
5.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。
已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
6. Little endian和Big endian
上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字"严"为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式
参考文献:
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://blog.csdn.net/chummyhe89/article/details/7777613
原文链接:https://blog.csdn.net/Kwoky/article/details/121784243















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









