







Cluster the following data set of ten objects into two clusters i.e. k = 2.
把下面10个数据对象分成2个簇
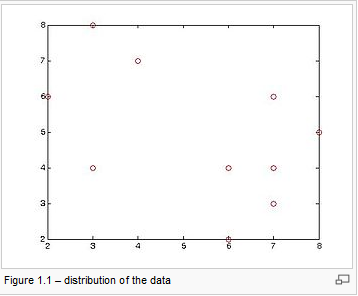
Consider a data set of ten objects as follows:

第一步:
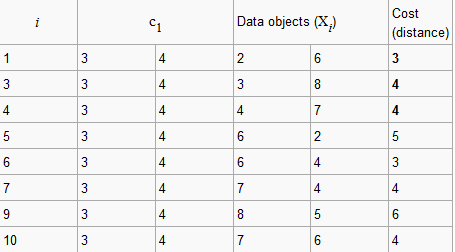
我们假设c1=(3,4)和c2=(7,4)是两个中心。
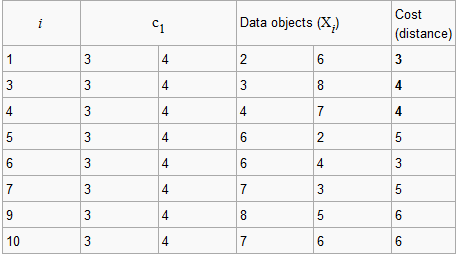

(2,6)到c1(3,4)的距离是3,(7,4)到c2(2,6)的距离是7,因此(2,6)和c1是一个簇。
按照同样的方法。得到:
Cluster1 = {(3,4)(2,6)(3,8)(4,7)}
Cluster2 = {(7,4)(6,2)(6,4)(7,3)(8,5)(7,6)}

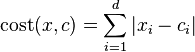
Cost((3,4),(2,6))=|3-2|+|6-4|=3
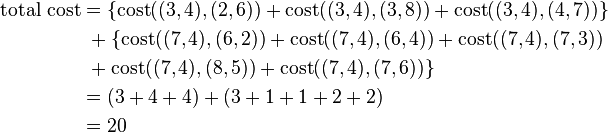
第二步:
选择一个非中心点o’,我们假设o’=(7,3)
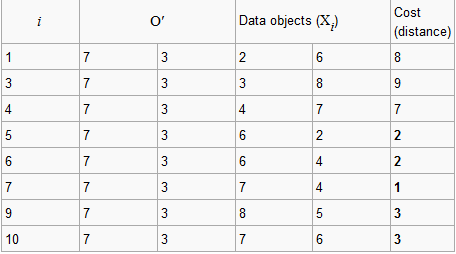
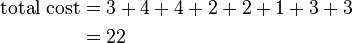
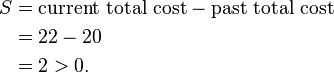
用同样的方法划分出两个簇:
然后再计算它总共的开销:
因此前面的那个选择更好。因此我们尝试了一些其他的非中心的点,发现我们的第一个选择是最好的。因此不会重新分配,算法停止。















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









