





HDFS数据并不总是均匀存储在datanode中的,如新增加一个datanode节点到集群中。当有新的数据要存储时,namenode会考虑多种因数后再选择datanode来存储数据。
因数如下:
1 把一个副本存放到client所在的节点中。
2 不能把所有副本放在同一个机架上,这样可以避免机架崩溃导致所有副本丢失。
3 把其中一个副本存到同一个机架中的节点中,这样可以减少跨机架网络I/O。
4 HDFS数据要均匀分布到集群中的 datanode节点中。
考虑到上述因素,HDFS提供了一个分析数据块的存放和datanode数据再平衡的工具rebalancer。
rebalance工作原理如下:
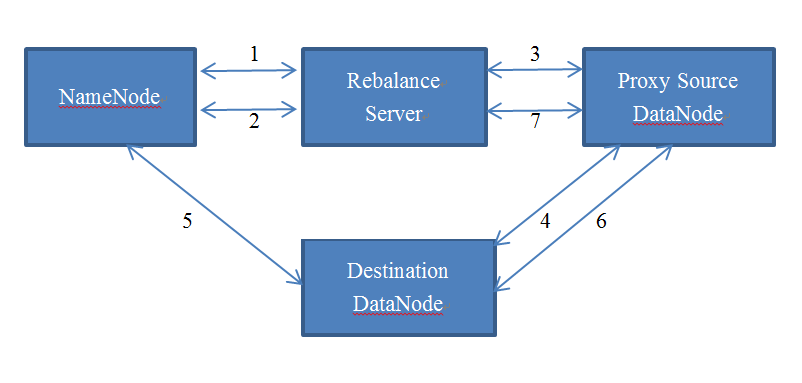
Step1: rebalance 向namenode请求datanode report。
Step2: rebalance分析报告后选择所有的proxy source 和 destination datanode,向namenode请求每个proxy source的文件块映射。
Step3: rebalance 向proxy source 发送复制文件块destination datanode的命令。
Step4: proxy source 向destination 请求重新放置proxy source中的数据块。
Step5: destination复制完数据块后,通知namenode删除proxy source中的数据块。
Step6: namenode选择一个副本删除文件块。Destination 向proxy source 通知文件块状态。
Step7: proxy source 向reblance 通知操作状态。















 2165
2165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









