






学习下,转自
https://www.cnblogs.com/hellcat/p/8449031.html
https://www.cnblogs.com/hellcat/p/8449801.html
https://www.cnblogs.com/hellcat/p/8453615.html
谢谢原作者的辛苦总结。
(上)
在PyTorch中计算图的特点可总结如下:
- autograd根据用户对variable的操作构建其计算图。对变量的操作抽象为
Function。 - 对于那些不是任何函数(Function)的输出,由用户创建的节点称为叶子节点,叶子节点的
grad_fn为None。叶子节点中需要求导的variable,具有AccumulateGrad标识,因其梯度是累加的。 - variable默认是不需要求导的,即
requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。 - variable的
volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。 - 多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定
retain_graph=True来保存这些缓存。 - 非叶子节点的梯度计算完之后即被清空,可以使用
autograd.grad或hook技术获取非叶子节点的值。 - variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播
- 反向传播函数
backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1 - PyTorch采用动态图设计,可以很方便地查看中间层的输出,动态的设计计算图结构。
Variable类和计算图
简单的建立一个计算图,便于理解几个相关知识点:
-
requires_grad 是否要求导数,默认False,叶节点指定True后,依赖节点都被置为True
-
.backward() 根Variable的方法会反向求解叶Variable的梯度
-
.backward()方法grad_variable参数 形状与根Variable一致,非标量Variable反向传播方向指定
-
叶节点 由用户创建的计算图Variable对象,反向传播后会保留梯度grad数值,其他Variable会清空为None
-
grad_fn 指向创建Tensor的Function,如果某一个对象由用户创建,则指向None
-
.is_leaf 是否是叶节点
-
.grad_fn.next_functions 本节点接收的上级节点的grad_fn
-
.volatile 是否处于推理模式
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
True False True True True True False False Variable containing: 1 1 1 1 1 1 1 1 1 1 1 1 [torch.FloatTensor of size 3x4] None None None
| 1 |
|
None None <AddBackward1 object at 0x000002A2F3D2EBA8> <SumBackward0 object at 0x000002A2F3D2ECC0>
模拟一个简单的反向传播:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
Variable containing: -0.3315 3.5068 -0.1079 -0.4308 -0.1202 -0.4529 -0.1873 0.6514 0.2343 0.1050 0.1223 15.9192 [torch.FloatTensor of size 3x4] Variable containing: -0.3315 3.5068 -0.1079 -0.4308 -0.1202 -0.4529 -0.1873 0.6514 0.2343 0.1050 0.1223 15.9192 [torch.FloatTensor of size 3x4]
结果一致。
.grad_fn.next_functions
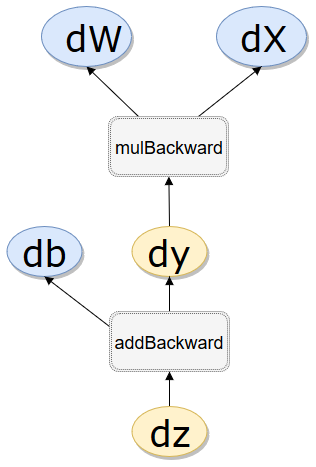
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
.is_leaf True True True False False .requires_grad False True True True True .grad_fn None None None <MulBackward1 object at 0x000002A2F57F5710> <AddBackward1 object at 0x000002A2F57F5630> .grad_fn.next_functions ((<AccumulateGrad object at 0x000002A2F57F5630>, 0), (None, 0)) ((<MulBackward1 object at 0x000002A2F57F57B8>, 0), (<AccumulateGrad object at 0x000002A2F57F57F0>, 0))z.grad_fn.next_functions[0][0]==y.grad_fn Truez.grad_fn.next_functions[0][0],y.grad_fn <MulBackward1 object at 0x000002A2F57F57F0> <MulBackward1 object at 0x000002A2F57F57F0>
.volatile
| 1 2 3 4 5 6 7 8 9 |
|
False True False True False True
附录、Variable类源码简介
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
|
(中)
查看非叶节点梯度的两种方法
在反向传播过程中非叶子节点的导数计算完之后即被清空。若想查看这些变量的梯度,有两种方法:
- 使用autograd.grad函数
- 使用hook
autograd.grad和hook方法都是很强大的工具,更详细的用法参考官方api文档,这里举例说明基础的使用。推荐使用hook方法,但是在实际使用中应尽量避免修改grad的值。
求z对y的导数
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
hook梯度输出: Variable containing: 1 1 1 [torch.FloatTensor of size 3] autograd.grad输出: (Variable containing: 1 1 1 [torch.FloatTensor of size 3] ,)
多次反向传播试验
实际就是使用retain_graph参数,
| 1 2 3 4 5 6 7 8 9 10 |
|
Variable containing: 1 1 1 [torch.FloatTensor of size 3] Variable containing: 2 2 2 [torch.FloatTensor of size 3]
如果不使用retain_graph参数,
实际上效果是一样的,AccumulateGrad object仍然会积累梯度
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
Variable containing: 1 1 1 [torch.FloatTensor of size 3] Variable containing: 2 2 2 [torch.FloatTensor of size 3]
分析:
这里的重新建立高级节点意义在这里:实际上高级节点在创建时,会缓存用于输入的低级节点的信息(值,用于梯度计算),但是这些buffer在backward之后会被清空(推测是节省内存),而这个buffer实际也体现了上面说的动态图的"动态"过程,之后的反向传播需要的数据被清空,则会报错,这样我们上面过程就分别从:保留数据不被删除&重建数据两个角度实现了多次backward过程。
实际上第二次的z.backward()已经不是第一次的z所在的图了,体现了动态图的技术,静态图初始化之后会留在内存中等待feed数据,但是动态图不会,动态图更类似我们自己实现的机器学习框架实践,相较于静态逻辑简单一点,只是PyTorch的静态图和我们的比会在反向传播后清空存下的数据:下次要么完全重建,要么反向传播之后指定不舍弃图z.backward(retain_graph=True)。
总之图上的节点是依赖buffer记录来完成反向传播,TensorFlow中会一直存留,PyTorch中就会backward后直接舍弃(默认时)。
(下)
一、封装新的PyTorch函数
继承Function类
forward:输入Variable->中间计算Tensor->输出Variable
backward:均使用Variable
线性映射
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
调用方法一
类名.apply(参数)
输出变量.backward()
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
开始前向传播 type in forward <class 'torch.FloatTensor'> 开始反向传播 type in backward <class 'torch.autograd.variable.Variable'>(None, Variable containing: 1 [torch.FloatTensor of size 1], Variable containing: 1 [torch.FloatTensor of size 1])
调用方法二
类名.apply(参数)
输出变量.grad_fn.apply()
| 1 2 3 4 5 6 7 8 9 10 |
|
开始前向传播 type in forward <class 'torch.FloatTensor'> 开始反向传播 type in backward <class 'torch.autograd.variable.Variable'>(Variable containing: 1 [torch.FloatTensor of size 1], Variable containing: 0.7655 [torch.FloatTensor of size 1], Variable containing: 1 [torch.FloatTensor of size 1])
之所以forward函数的输入是tensor,而backward函数的输入是variable,是为了实现高阶求导。backward函数的输入输出虽然是variable,但在实际使用时autograd.Function会将输入variable提取为tensor,并将计算结果的tensor封装成variable返回。在backward函数中,之所以也要对variable进行操作,是为了能够计算梯度的梯度(backward of backward)。下面举例说明,有关torch.autograd.grad的更详细使用请参照文档。
二、高阶导数
grad_x =t.autograd.grad(y, x, create_graph=True)
grad_grad_x = t.autograd.grad(grad_x[0],x)
| 1 2 3 4 5 6 7 8 |
|
(Variable containing: 10 [torch.FloatTensor of size 1],)(Variable containing: 2 [torch.FloatTensor of size 1],)
三、梯度检查
t.autograd.gradcheck(Sigmoid.apply, (test_input,), eps=1e-3)
此外在实现了自己的Function之后,还可以使用gradcheck函数来检测实现是否正确。gradcheck通过数值逼近来计算梯度,可能具有一定的误差,通过控制eps的大小可以控制容忍的误差。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
True
测试效率,
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
实际测试结果,
245 µs ± 70.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) 211 µs ± 23.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) 219 µs ± 36.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
书中说的结果,
100 loops, best of 3: 320 µs per loop 100 loops, best of 3: 588 µs per loop 100 loops, best of 3: 271 µs per loop
很奇怪,我的结果竟然是:简单堆砌<官方封装<自己封装……不过还是引用一下书中的结论吧:
显然
f_sigmoid要比单纯利用autograd加减和乘方操作实现的函数快不少,因为f_sigmoid的backward优化了反向传播的过程。另外可以看出系统实现的buildin接口(t.sigmoid)更快。















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









