







Bag-of-Words词袋模型,经常用在自然语言处理和信息检索当中.在词袋模型中,一篇文本(文章)被表示成"装着词的袋子",也就是说忽略文章的词序和语法,句法;将文章看做词的组合,文中出现的每个词都是独立的,不依赖于其他词.虽然这个事实上并不成立,但是在实际工作中,效果很好.
Set-of-Words词集模型SoW:用0-1作为文章中词的数量表示.
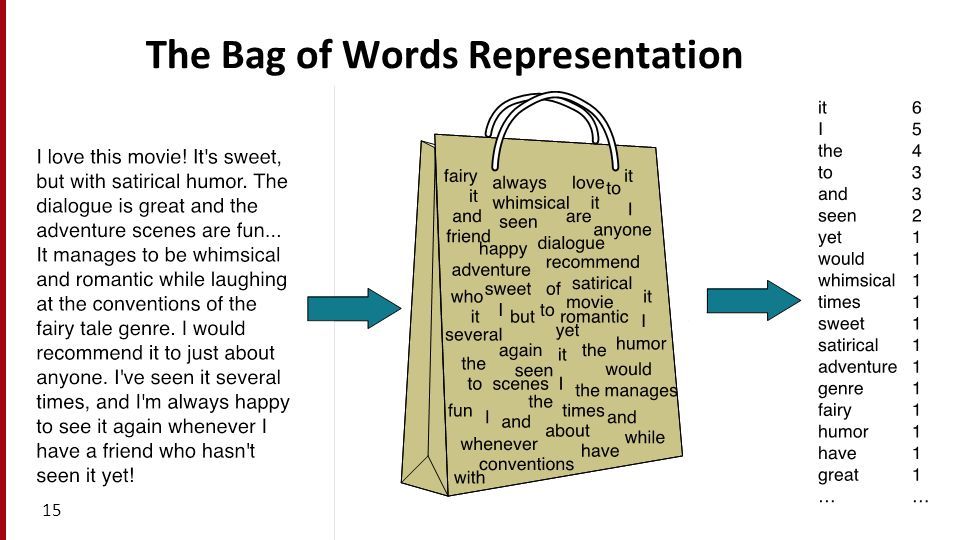
在词袋模型BoW中,每个词的数量表示有多种方法:可以表示为0-1(在这篇文章中,这个词出现了没有–词集模型),词频(在这篇文章中,这个词出现了多少次),也可以用tf-idf.
从这个角度上说,BoW模型包含SoW,两者之间的区别在于词的数量表示不同,一个用0-1,一个用词频,但本质上是相同的,将文章看做词袋,忽略文章的词序,语法和句法,仅仅将文章看做一些列词的组合. 所以,一般只说BoW词袋模型(忽略词序,语法和句法).
参考链接:
维基百科 Bag-of-words model














 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









