







【CSDN 编者按】岁末年初,Linux内核2023年度盘点如约而至。继《2022 Linux内核十大技术革新功能 | 年终盘点》之后,知名Linux内核一线开发者,经典书籍《Linux 设备驱动开发详解》作者宋宝华老师又给大家带来了2023年Linux内核开发中,十个最典型的patchset,为大家呈现干货满满的硬核技术年货。
作者 | 宋宝华 责编 | 梦依丹
出品 | CSDN(ID:CSDNnews)
君不见,黄河之水天上来,奔流到海不复回。君不见,高堂明镜悲白发,朝如青丝暮成雪。公元1991年,当Linus Torvalds发布Linux内核的时候,他还只是一位21岁的少年。时间的巨轮不舍昼夜,滚滚向前。过往岁月,欢快亦或悲伤,回首时都仿佛如昨天。
2023年的Linux内核,虽然即将迈向象征码农“高龄”的35岁,仍繁花似锦,蜂蝶翩翩。它的无边活力,似一束强光,刺穿时代全部的阴霾,璀璨夺目。作为一名老码农,唯一能做的,就是用文字记录这道光芒,让它可以在记忆里存留更久,也顺道希冀留住自己这逝去的一年吧。
2023年,众多Linux内核开发者仍然在调度器、内存管理、文件系统等领域贡献着自己的idea和patch,本文从其中选取十个最典型的patchset,进行阐述,它们是:
基于eBPF的sched_ext调度类扩展
per-VMA lock
NUMA系统上kernel代码段复制
Large folios/动态大页
文件系统large block支持
基于scope的资源管理
用代理执行解决优先级反转(priority inversion)问题
延后用户空间临界区内的抢占
EEVDF调度
BPF通用迭代器
下面我们一一展开。

基于eBPF的sched_ext调度类扩展
这一patchset的开发过程,堪称神仙打架。对垒的多方,无论是发patch的还是review patch的,都是内核社区的顶流大神,甚至连看客都会北冥神功。他们之间直接的拼杀,刺刀见红,毫不留情,让凡人们见识了神仙也有性格,技术和思想的力量可以怎样无视虚伪和矫情。
sched_ext patchset由社区鼎鼎大名的Tejun Heo发出,他是Linux内核cgroup、KERNFS、PER-CPU MEMORY ALLOCATOR、WORKQUEUE等的maintainer。
这个patchset——sched: Implement BPF extensible scheduler class
链接:
https://lore.kernel.org/lkml/20231111024835.2164816-1-tj@kernel.org/
Patchset的实际贡献还包括来自Google、meta、卡内基梅隆大学等多家主流厂商和科研院校的开发者。该patchset扩展了一个调度class,与之前的CFS、realtime等并行,但是它允许调度行为被一个BPF程序来实现,并声称有如下三大好处:
1. 让探索和实验变地容易: 让新的调度策略可以快速迭代
2. 定制化调度行为:为特定应用定制调度器(这个调度器也许不适用于通用目的)
3. 调度器快速部署: 在产品环境下,非侵入式地修改调度器。
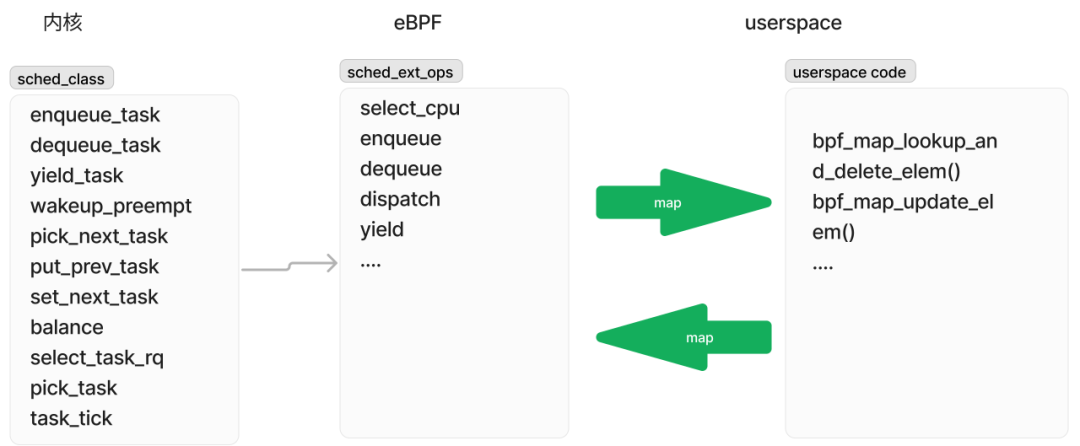
新加入的sched_ext与内核已经存在的stop_sched_class、dl_sched_class、rt_sched_class、fair_sched_class、idle_sched_class是一种并列关系,任何一个sched_class,都需要实现一系列的callback函数,比如:
enqueue_task:将task放入runqueue,在CFS中task会加入一个红黑树;
dequeue_task:将task从runqueue拿出来;
pick_next_task:调度时候选取下一个run的task,比如对于rt调度类而言就是找bitmap上第一个bit的queue里面的task;
task_tick:在调度tick发生时被调用,比如对于CFS而言,它会更新当前运行task的vruntime和sum_exec_runtime,并可能设置need_resched;
wakeup_preempt:一个task被唤醒的时候(也可能是调度策略或者优先级更改,比如从其他策略调整为CFS插入CFS的runqueue的switched_to_fair),可能抢占正在运行的task;
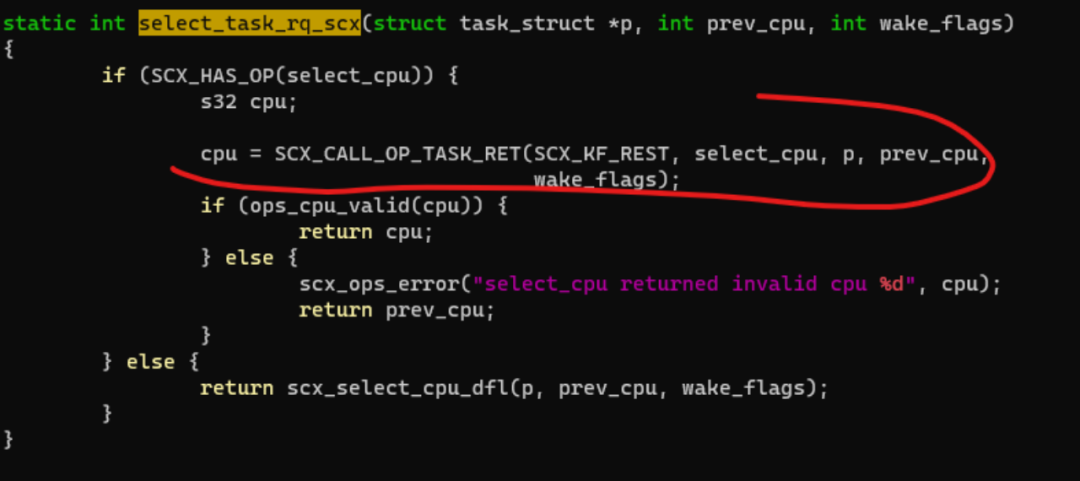
select_task_rq:比如fork一个新的task以及exec、wakeup等负载均衡场景,我们要选择把task放到哪个CPU的runqueue上面。

Patchset定义了一组可以由eBPF程序实现的callback:
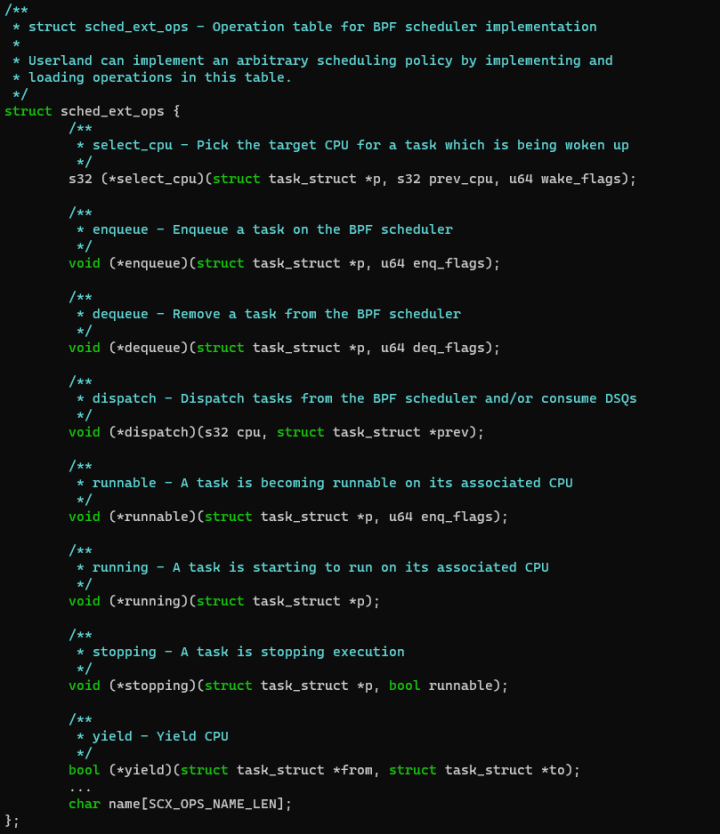
并在内核的sched_ext class的callback中,调用这一组eBPF实现的callback,比如ext sched_class的select_task_rq() callback调用eBPF的select_cpu() callback:
进一步地,由于eBPF程序可以通过maps和userspace交互,实际上,调度行为也可以在userspace实现了,这让内核sched_class、eBPF的sched_ext_ops和用户空间,实现了3位一体的联动。
比如eBPF中可以pop一个BPF_MAP_TYPE_QUEUE类型的map:
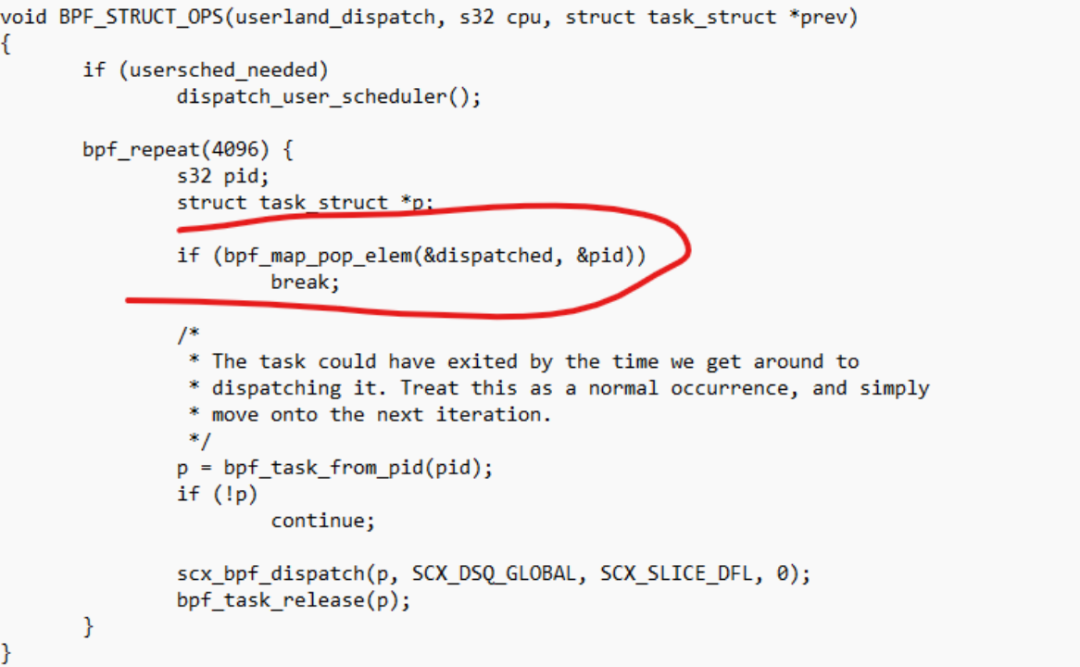
而userspace则可以update_elem相关dispatch进程的pid到这个map:
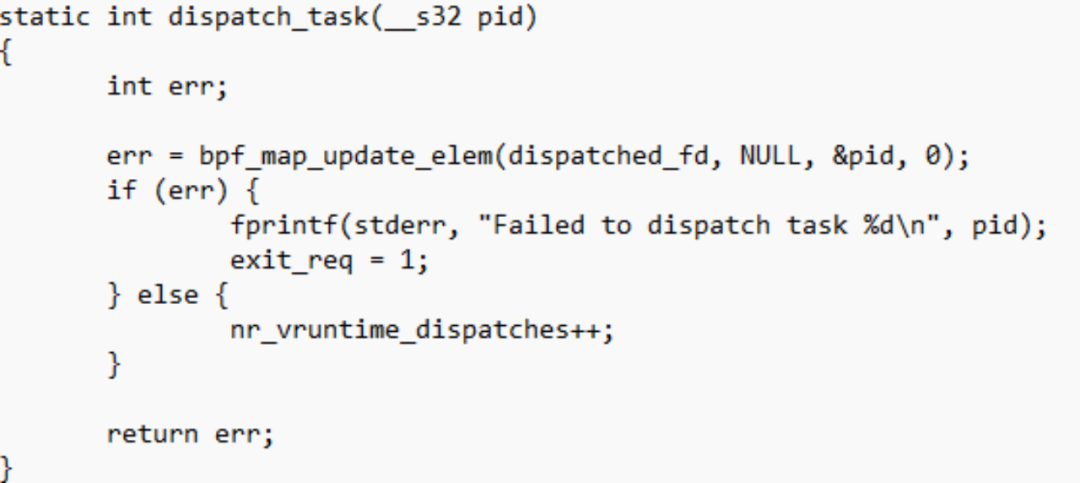
整个patchset让Linux内核调度器的维护者Peter Zijlstra(同时也是ATOMIC INFRASTRUCTURE、CPU HOTPLUG、FUTEX、LKMM、MMU GATHER AND TLB INVALIDATION、Perf等的维护者)所极度反感,在patchset中直接给出了NACK:

他NAK的无疑是一位大神,当我们回眸特洛伊之战中两位伟大英雄阿喀琉斯和赫克托耳的决斗时刻,最后命运的天平无论便向的是哪一边,剩下的都只有悲壮。

per-VMA lock
如果Linux内核里面有什么锁最臭名昭著,那么一定是mmap_sem(后改名为mmap_lock)。这个锁位于mm_struct里面,很显然它应该是一个多线程共享的进程级别概念而不应该是per-VMA的概念:
struct mm_struct {
...
struct rw_semaphore mmap_lock;
}但是之前我们在page fault中,也是要拿mmap_sem读锁的,因为我们也不知道page fault处理过程中,对应的VMA会不会变化或者甚至消失,所以要和可能写VMA的人排他。Page fault的处理逻辑实际是:
down_read(&mm->mmap_lock);
__do_page_fault(mm, vma, addr, mm_flags, vm_flags, regs);
up_read(&mm->mmap_lock);由于mmap_sem是整个进程的,而一个进程里面说不定也有成千上万的VMA,然后大量的page fault以及其他的VMA的写操作行为,相互竞争锁,就导致大量的竞争延迟。其他需要持有写锁的地方也是非常多的,比如:brk、stack expand、munmap、remap_file_pages、exit、madvise、mprotect、mremap、mlock等。
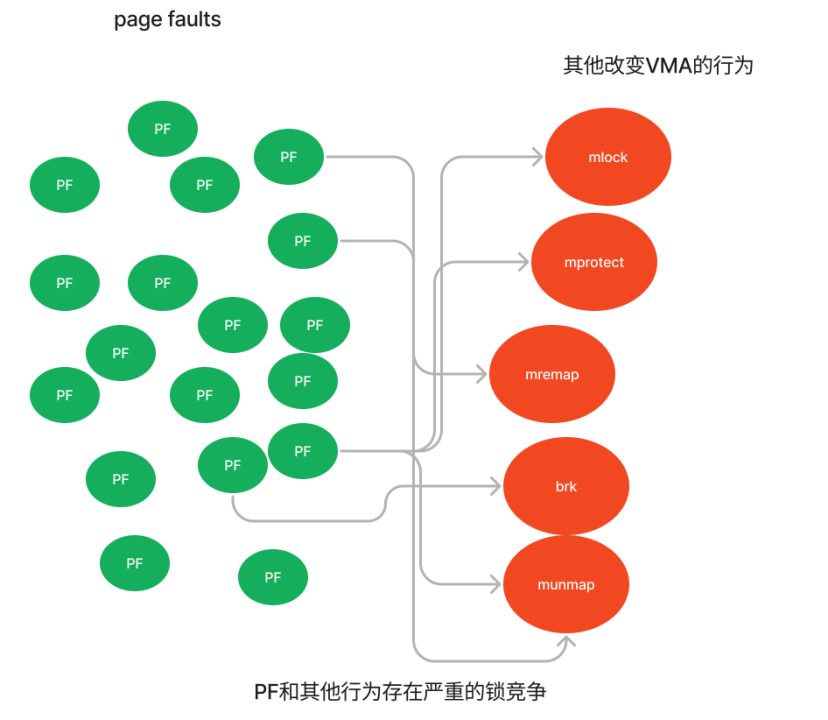
用一个大的mmap_lock把这些写和page fault的读进行保护,这固然安全,但是也实在低效。我们假设一个进程有1万个VMA,然后我们在其中的1个VMA上面进行page fault,其他的9999个VMA消失不消失,变化不变化,跟我这个page fault之间其实是没有半毛钱关系的。如果能够在PF中不去持有mmap_lock读锁,而去持有一个更细粒度的,只关心本VMA的锁,应该是一个更好的选择。
在处理page fault的时候,我们只需要通过持有VMA的lock,来保证这个VMA本身的稳定:
struct vm_area_struct *lock_vma_under_rcu(struct mm_struct *mm, unsigned long address);每个VMA里面实际增加了一个vma_lock(里面含有一个读写锁):

在page fault里面我们持有读锁,在其他要写某个VMA的场景,我们要持有写锁(前提条件是我们也必须持有了进程级的mmap_lock):

它的这个实现看起来很奇怪,因为它拿到了vma->vm_lock->lock后,并不真地会一直拿着,而是马上就放了up_write,但是它写了一个vma->vm_lock_seq,把这个vm_lock_seq写成了vma->vm_mm->mm_lock_seq的,而进程级的mm_lock_seq会在mmap_lock释放的时候自增。
但是拿读锁的page fault,则是在page fault的途中一直hold着vma->vm_lock->lock。lock_vma_under_rcu()会调用vma_start_read():
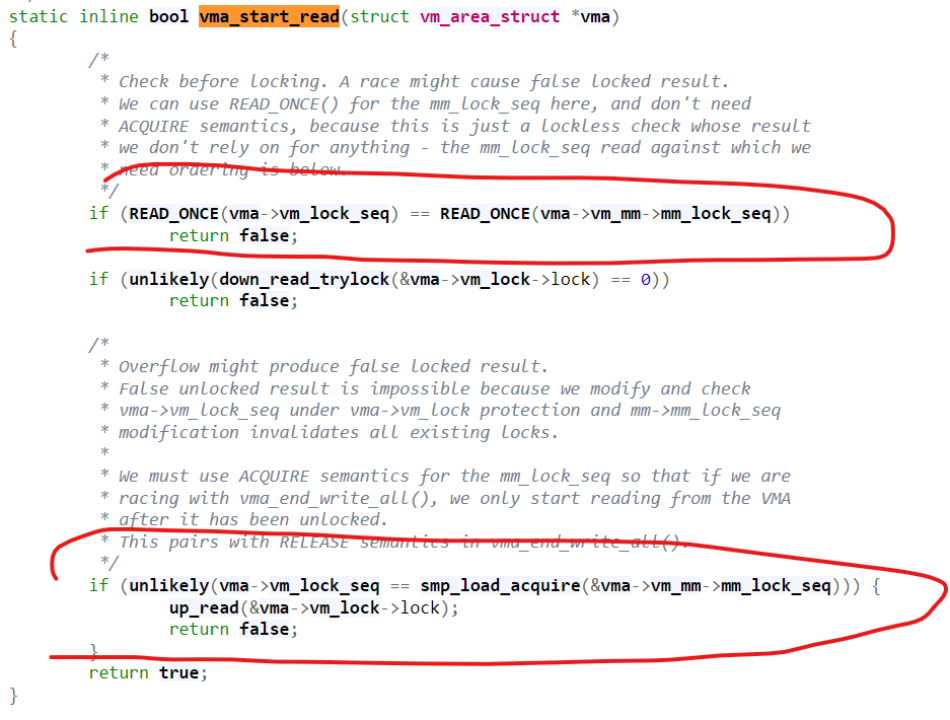
因为我们要开始VMA写的时候把vma->vm_lock_seq写成了进程级的mm_lock_seq,这样当我们拿读锁的时候,如果vma->vm_lock_seq == mm->mm_lock_seq,说明VMA还在写,我们其实也不用拿读锁了,per-VMA读锁直接失败,让page fault的代码回退到去拿原先的mmap_lock就好。
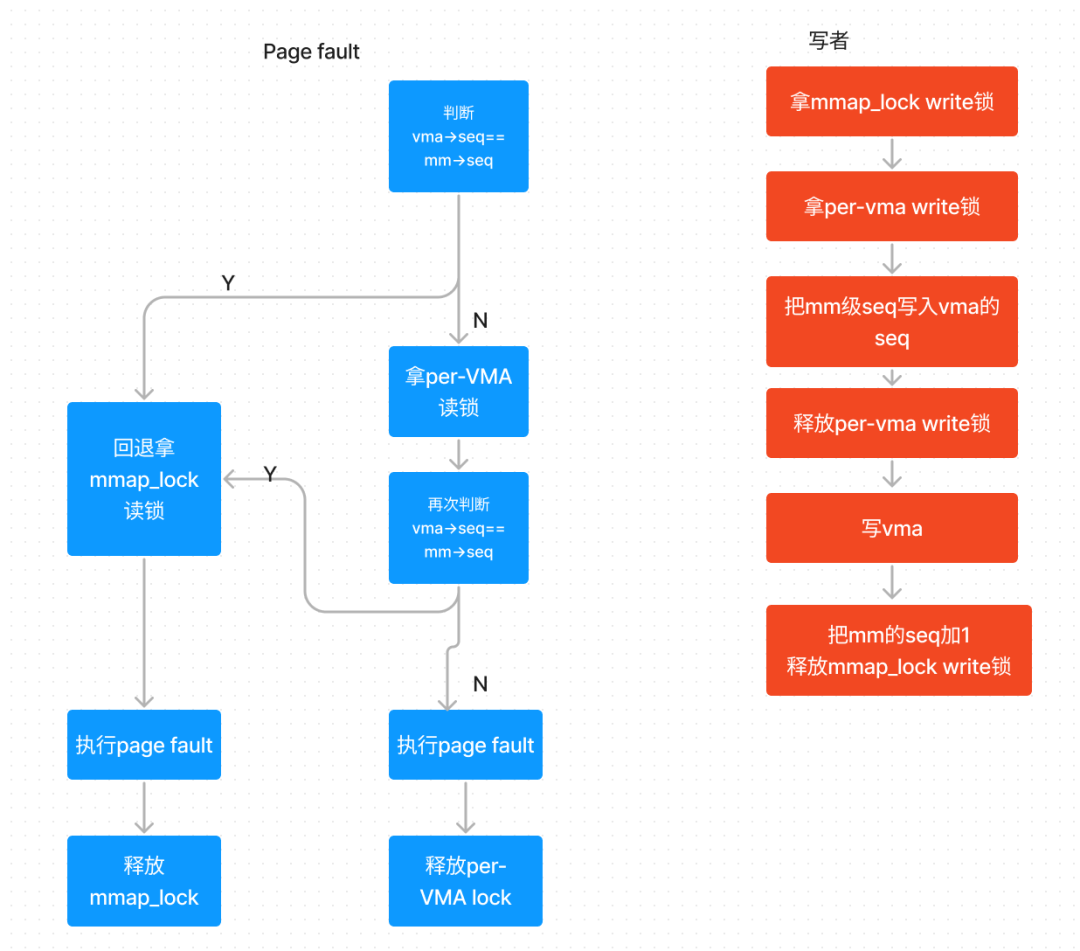
由于per-VMA拿写锁的人总是当场放写锁,我们其实就不用担心忘记up_write了。这有点自动化的类似后面将要提到的scope-based resource management。
值得一提是,在per-VMA lock准备好之前,有些Linux内核,比如Android采用了SPF(Speculative page faults)来处理page fault,SPF的实现不包含per-VMA lock,它也不拿mmap_sem,但是page fault会不拿mmap_sem投机执行,处理过程中会边走边看,如果执行过程中发现VMA被修改,page fault会拿mmap_sem来retry原先的page fault。这个机制我们在2022年终盘点中也有提及。

NUMA系统上kernel代码段复制
Russell King,在Linux ARM体系架构采用device tree之前,维护着ARM Linux社区。由于当时的arch/arm目录充斥着大量的冗余描述硬件的代码,在2011年TI OMAP的一次Pull request中,Linus终于忍无可忍,破口大骂“this whole ARM thing is a f*cking pain in the ass”。此后,Linaro和ARM强势介入,在ARM Linux引入了device tree,开启了一个崭新的时代。自己的地盘被人革了命,Russell童鞋的黯然神伤无可掩饰。但是,作为大神,Russell无疑拥有无可辩驳的技术实力,这次他给我们带来的是黯然销魂掌arm64 kernel text replication。
在一个典型的NUMA系统中,跨node访问内存的开销比访问本地node的开销大。
 于是从软件层面,我们倾向于让本node的CPU访问本node的内存,对于数据段而言,通过内存绑定、NUMA balance等方法可以可以实现这个目的。
于是从软件层面,我们倾向于让本node的CPU访问本node的内存,对于数据段而言,通过内存绑定、NUMA balance等方法可以可以实现这个目的。
但是,Russell瞄准的是内核的代码段,众所周知,内核代码段在整个内存只有一份拷贝,假设这份拷贝位于node 0 memory,那么对于node1,node 2, node3这些CPU而言,它们其实都是访问远端的内存来执行内核代码,这显然是有耗损的。
Russell的这个patchset ——arm64 kernel text replication
链接:
https://lore.kernel.org/linux-arm-kernel/ZMKNYEkM7YnrDtOt@shell.armlinux.org.uk/
让kernel的代码段(也可以包含只读的数据段)在node0, node1, node2和node3各自拥有自己的拷贝,从而实现近距离内存访问。
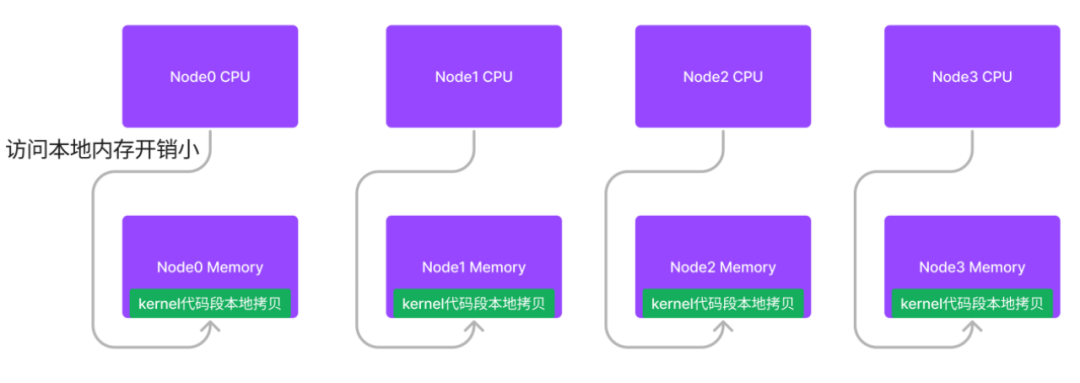
为了实现这个功能,Russell主要做了两件事:
1. 制造kernel text(包括read-only data)的per-node拷贝
2. 修正内核的page table,让每个node看到不同的页表entry,从而实现text的本地拷贝在各个node的CPU上看到的虚拟地址是一致的。
该patchset报告,这一patchset使得以数据库为中心的类似工作负载取得了6%-17%的性能提升。
Russell的工作是在ARM上面做的,我们看到2023年底,华为的Artem Kuzin随后在X86架构跟进,提交了如下的patchset ——[PATCH RFC 00/12] x86 NUMA-aware kernel replication
链接:
https://lore.kernel.org/linux-mm/20231228131056.602411-1-artem.kuzin@huawei.com/
Artem Kuzin初步性能报告聚焦在fork、mmap、kill、open、close等系统调用上,看到了明显的性能提升。

Large folios/动态大页
Large folios是社区2023的热门话题,由于一个large folio中可以包含多个page,所以采用large folio可以减小page fault的次数(比如一个page fault中映射1个包含16个page的folio,这样就减少了后面15次page fault)、降低LRU的维护成本(large folio整体加入LRU)、降低内存的回收成本(large folio整体回收)等。
匿名页方面,有以ARM公司Ryan Roberts主导的anon large folios(也称mTHP项目);文件页方面,如果文件系统声称支持large mapping,page cache那边也有尽可能申请large folios。而在产品角度,OPPO的手机甚至在支持folio之前的5.15等内核,率先将动态大页产品化,来提高手机的性能。
Ryan Roberts主要工作在匿名页的large folios领域,他的patchset集中在如下几个角度:
1. 在匿名页的page fault中申请large folios
[PATCH v9 00/10] Multi-size THP for anonymous memory
https://lore.kernel.org/linux-mm/20231207161211.2374093-1-ryan.roberts@arm.com/
2. 利用ARM的硬件特性CONT-PTE比特,比16个连续的PTE映射为CONT
[PATCH v4 00/16] Transparent Contiguous PTEs for User Mappings
https://lore.kernel.org/linux-mm/20231218105100.172635-1-ryan.roberts@arm.com/
3. Large folios swpout出去时候不split
[PATCH v3 0/4] Swap-out small-sized THP without splitting
https://lore.kernel.org/linux-mm/20231025144546.577640-1-ryan.roberts@arm.com/
原先匿名页的映射,也是支持PMD或更高级别的THP的,但是Ryan Roberts的patchset,实际扩展了THP的概念,让它可以是PTE级别的,所以也被称作multi-size THP(或mTHP)。
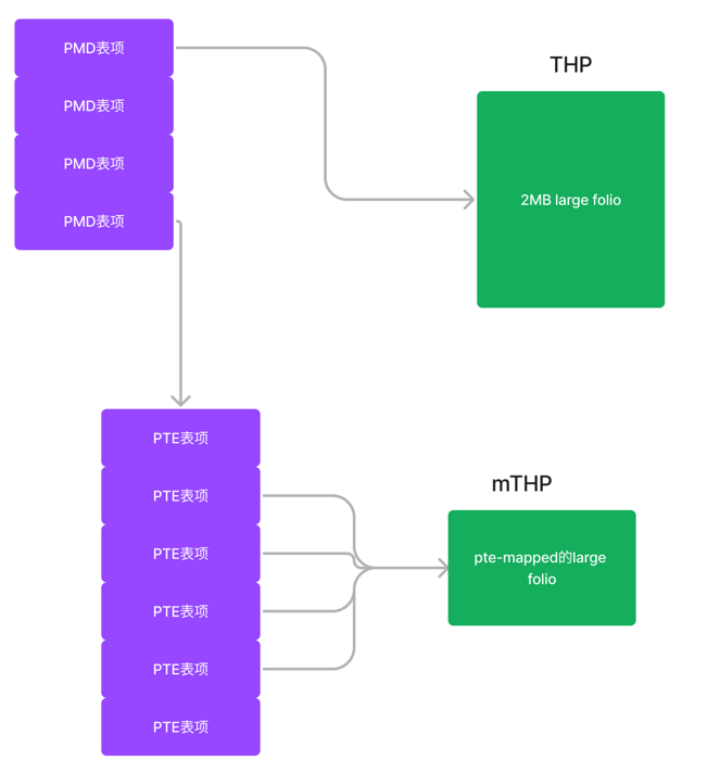
至于文件页方面,文件系统如果透过mapping_set_large_folios()申明自己支持large folios,则page cache层的读填充环节可以考虑申请large folios来填充page cache:
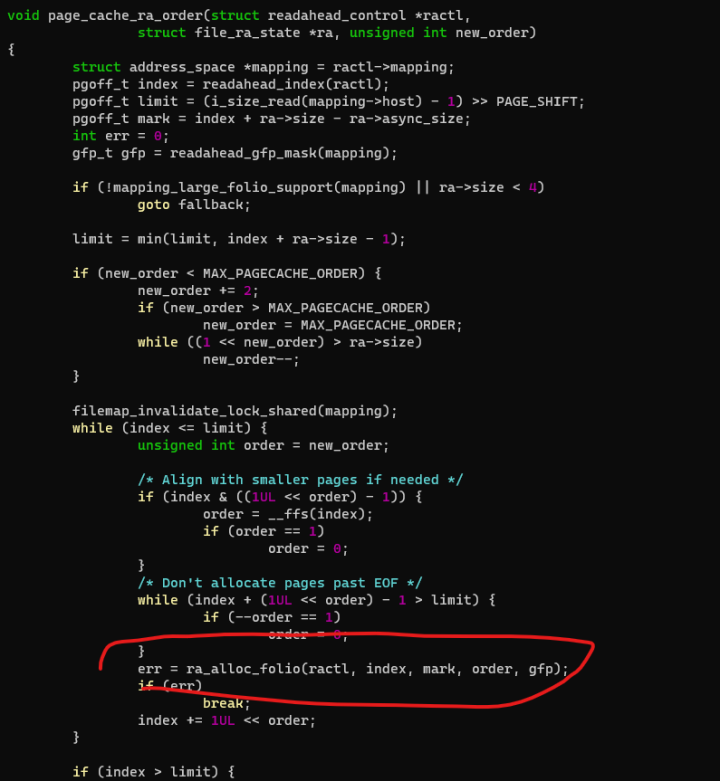
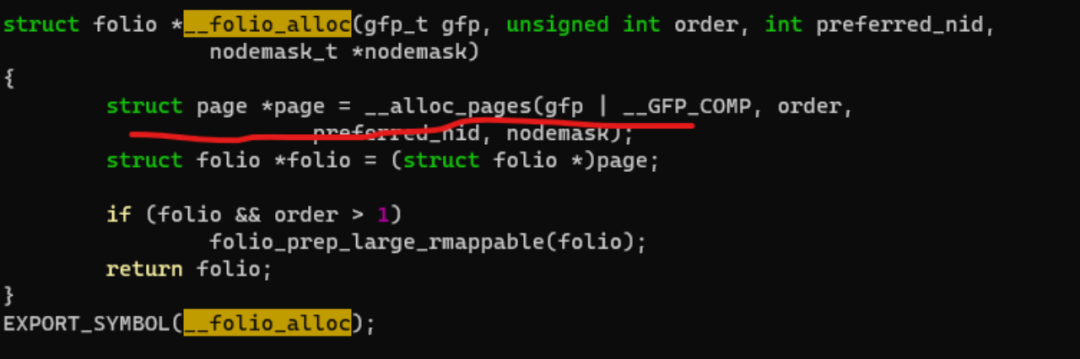
其中的ra_alloc_folio()会申请large folio,它最终调用的是__folio_alloc()从buddy获得指定order的compound pages:
Matthew Wilcox的patchset——Create large folios in iomap buffered write path支持了buffered写路径上的large folios申请
链接:
https://patchwork.kernel.org/project/linux-fsdevel/list/?series=764040&state=%2A&archive=both
它让iomap_get_folio()支持了指定len的功能:
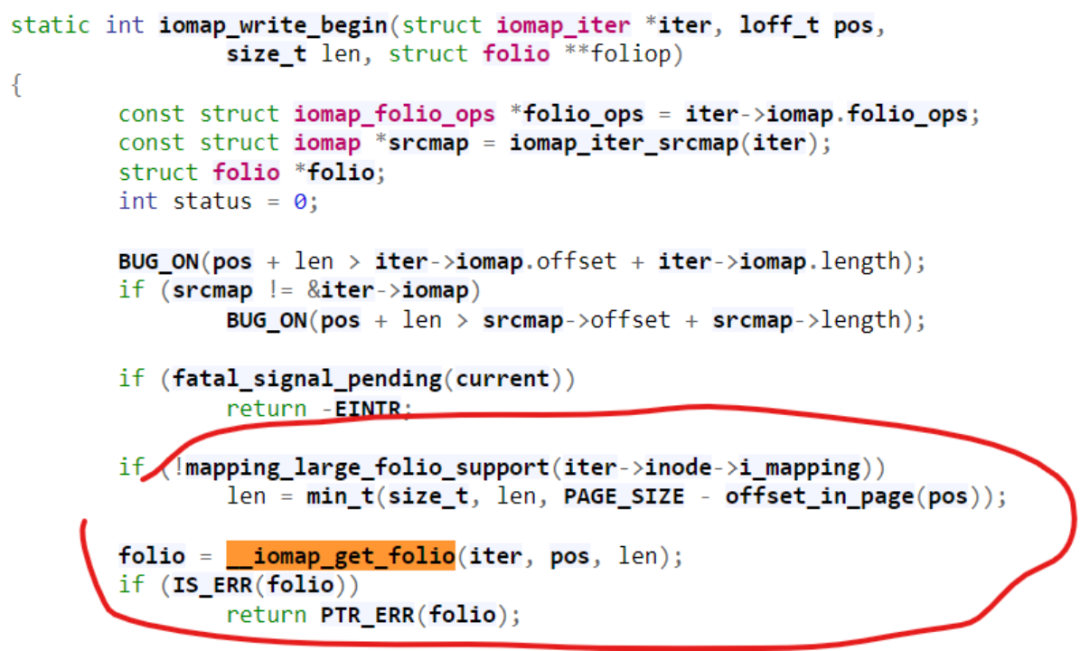
同时我们也看到还有很多的文件系统不支持iomap和large folios,相信它们向iomap/large folios支持的转移也是一种未来的趋势,比如华为的Zhang Yi就在进行如下的工作——ext4: use iomap for regular file's buffered IO path and enable large foilo
链接:
https://lwn.net/Articles/956575/
社区large folios的概念付诸于产品应该还会有很多的问题,我们预计large folios将仍然是2024年社区的开发热点之一。
值得一提的是,在中国Linux内核开发者大会CLK2023上,来自OPPO的开发者韩传华实际呈现了一个更完整的产品化设计——《动态大页:基于ARM64 contiguous PTE的64KB HugePage/Large Folios》
链接:
https://github.com/ChinaLinuxKernel/CLK2023 内存管理分论坛。

文件系统large block支持
一般意义上的文件系统的block size是4KB或者以下的(一般的PAGE_SIZE也是4KB),如果我们把它放大为16KB、64KB等,则显然会减小文件系统本身的维护开销,也同时可能提高I/O的性能(现代的存储设备可能本身硬件的block size就变大),并与前面所提到的page cache的所支持large folios更好适配。当然,副作用是它可能增大文件系统的体积(文件的大小并不总是block size的整数倍)。
早在2007年,来自SGI的Christoph Lameter的patchset [00/17] Large Blocksize Support V3
链接:
https://lore.kernel.org/lkml/20070424222105.883597089@sgi.com/
就开始寻求在4KB的PAGE_SIZE的情况下,寻求大于4KB的block size支持。2007年这个概念显得有点超前,但是在今天iomap、large folios的情况下则更加有可能变成现实。kernelnewbies.org专门建了一个wiki来跟踪这方面的进展:
https://kernelnewbies.org/KernelProjects/large-block-size
Luis Chamberlain以及来自三星的 Pankaj Raghav童鞋,提交了一个XFS支持large block(block > page)的patchset——[RFC 00/23] Enable block size > page size in XFS
链接:
https://lore.kernel.org/all/20230915183848.1018717-1-kernel@pankajraghav.com/
这个patchset让page cache的filemap, readahead和truncation代码按照文件系统inode的address_space的minimum order要求去分配和对齐folio,比如文件系统应该通过如下API进行暗示:

而filemap、readahead等page cache的处理层则尊重文件系统的暗示进行对齐和分配:
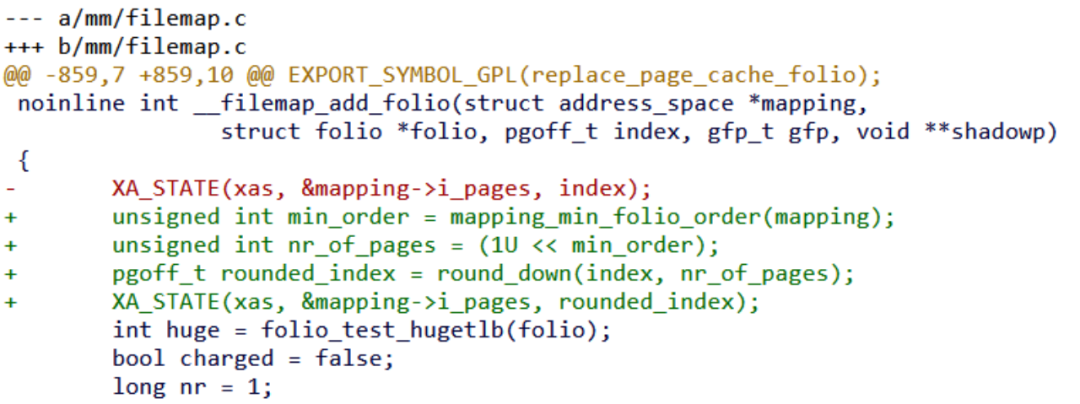
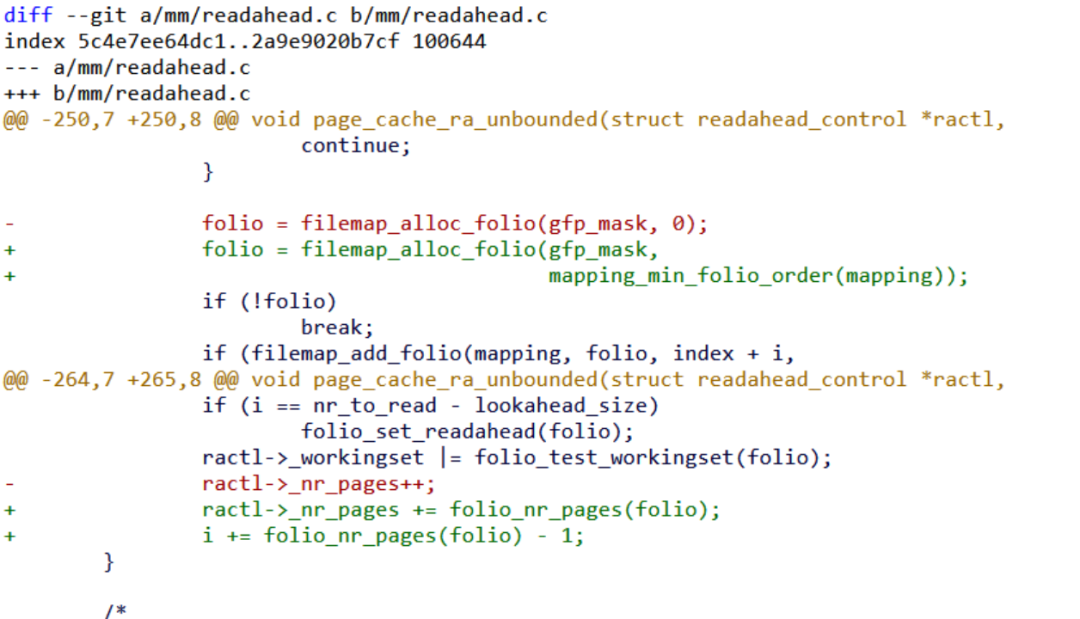
所以本质上,它的逻辑是page cache这层folio与文件系统声称的min_order对齐,而文件系统本身按照大块进行I/O。
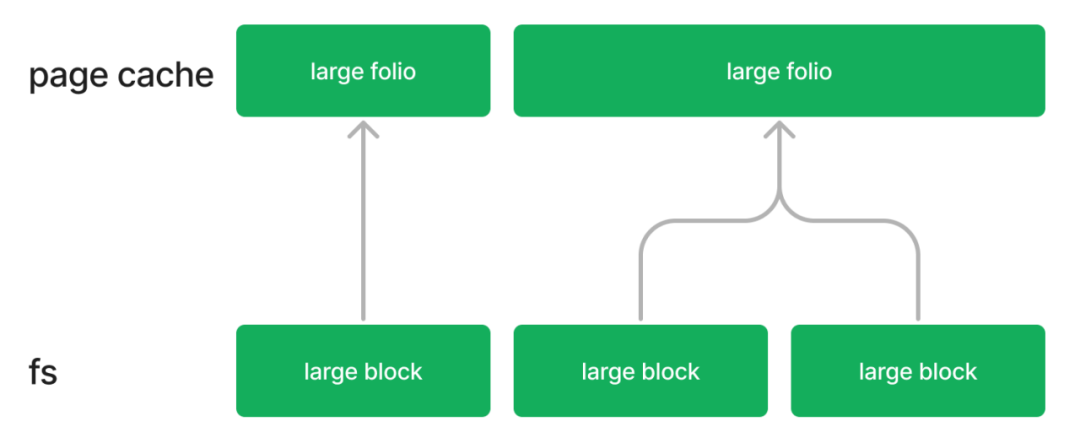
XFS设置的min_order要求如下,显然是大于或者等于block size对应的order的:
 对于ARM64而言,底层的page size可以配置为16KB,我们看到,来自google的工程师Daniel Rosenberg修正了F2FS,让它可以在16KB的block size情况下工作——
对于ARM64而言,底层的page size可以配置为16KB,我们看到,来自google的工程师Daniel Rosenberg修正了F2FS,让它可以在16KB的block size情况下工作——
f2fs: Support Block Size == Page Sizehttps://lore.kernel.org/lkml/20231002230935.169229-2-drosen@google.com/
但是,这其实和我们前面讲到的large block实际上并不同,因为large block强调是block > page。F2FS的这个case仍然是block=page,只不过page也是16KB。

基于scope的资源管理
Scope-based resource management并不是什么新鲜概念,比如C++和Rust语言都有这种概率,在scope结束的位置,完成deallocation和deconstruction。比如下面的代码:
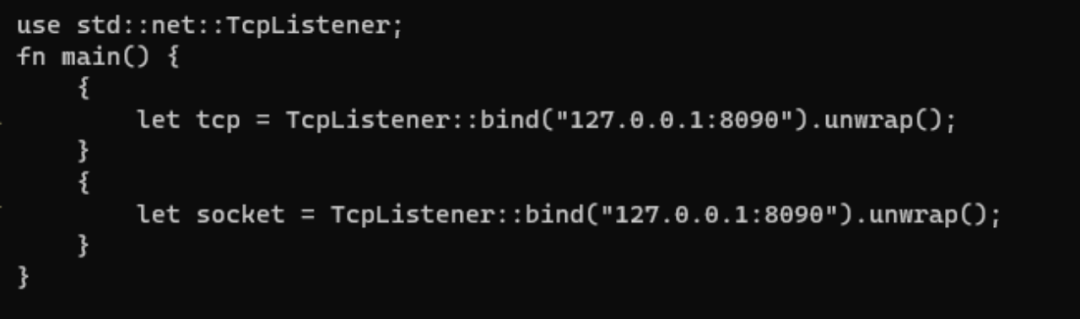
tcp在自己的作用域结束的时候,被自动释放(drop),这样我们在下一个作用域,可以建立一个完全一样的同样端口的socket。
比如一段如下的代码,我们在1处获得了mutex,我们需要在2和3两处释放mutex,这样才能保证mutex不会出乱子。
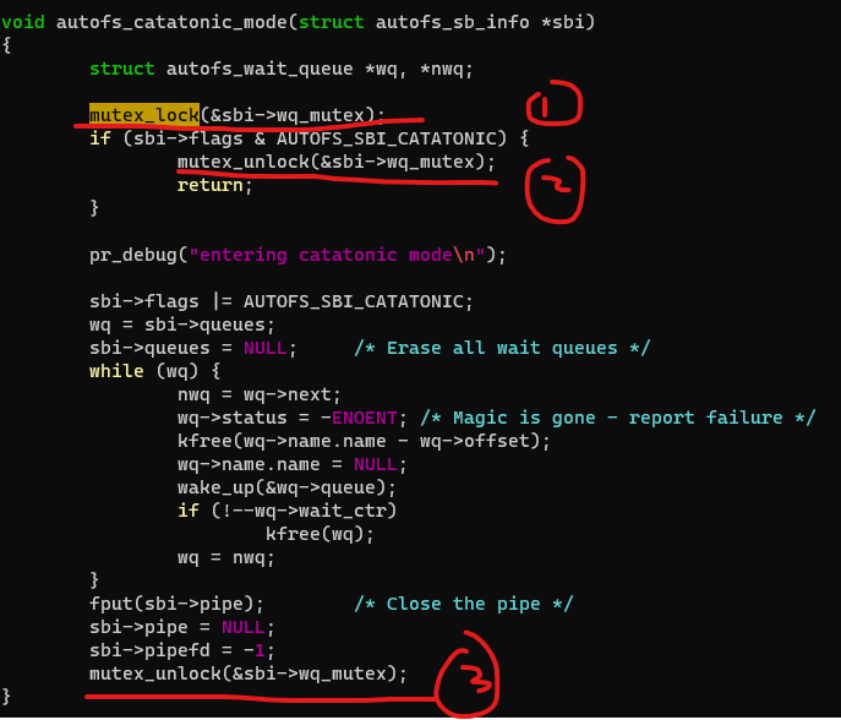 但是,假设这个mutex本身是支持Scope-based resource management的话,只要mutex的作用域scope(本例中是这个函数)结束,这个mutex就可以自动释放,这样我们不必记得位置2和位置3的释放了。这样的编程方式通常比较安全,可以避免内存泄露、资源忘记释放等潜在的bug。
但是,假设这个mutex本身是支持Scope-based resource management的话,只要mutex的作用域scope(本例中是这个函数)结束,这个mutex就可以自动释放,这样我们不必记得位置2和位置3的释放了。这样的编程方式通常比较安全,可以避免内存泄露、资源忘记释放等潜在的bug。
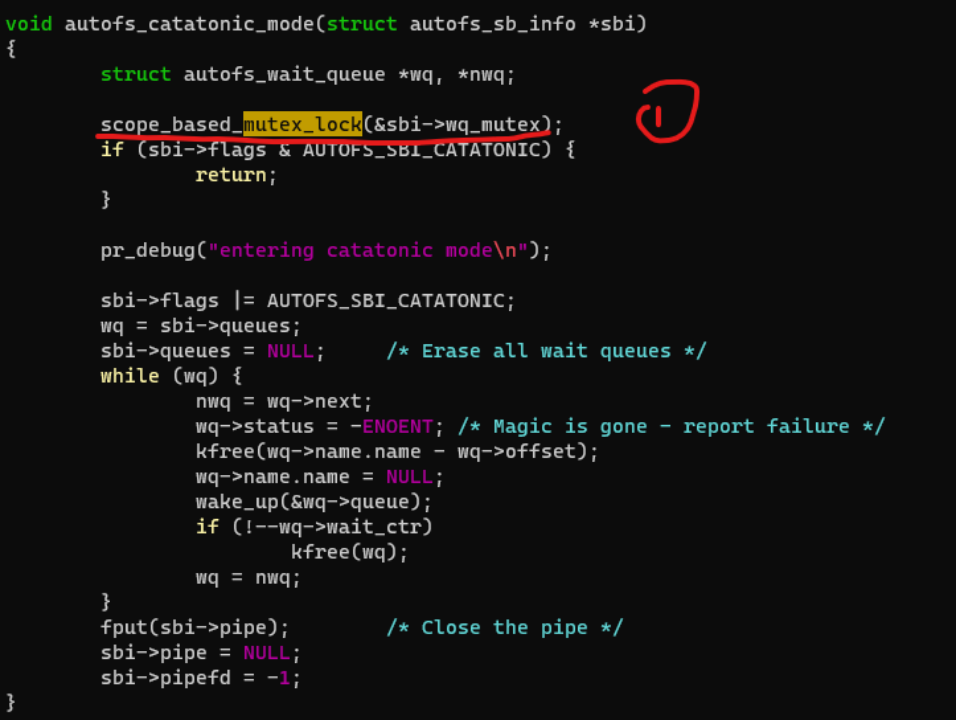
C语言本身不具备类似C++/Rust的Scope-based resource management的能力,但是我们或可以借助GCC/CLANG编译器的扩展属性进行变通实现:

上面我们对foo_ptr变量使用了__attribute__((__cleanup__(cleanup_func)))属性定义了一个cleanup函数,这个cleanup函数,可以在foo_ptr作用域结束的时候,被执行,从而kfree()来释放内存。
这样子直接用__attribute__((__cleanup__(cleanup_func)))是比较土的,大神 Peter Zijlstra的patchset——[PATCH v3 00/57] Scope-based Resource Management
链接:
https://lwn.net/ml/linux-kernel/20230612090713.652690195@infradead.org/
定义了一组helper宏,让整个过程看起来更加自然,更接近Rust和C++的样子。
比如下面的代码,原本要进行很多rcu_read_lock和rcu_read_unlock的异常处理,比如中间横线部分2处有个cpu = i,然后goto unlock后释放rcu_read_unlock,之后return cpu的过程(4处)。现在因为Peter在1处引入的guard(rcu),让这个rcu的释放具备了Scope-based Resource Management的能力,所以我们在修改后的代码的3处,直接return i就好了,rcu_read_unlock的动作,会由guard(rcu)内部封装的cleanup完成。

再比如下面的代码(取自6.6内核),我们用了scope-based的spinlock,我们就不必管释放的事情了:
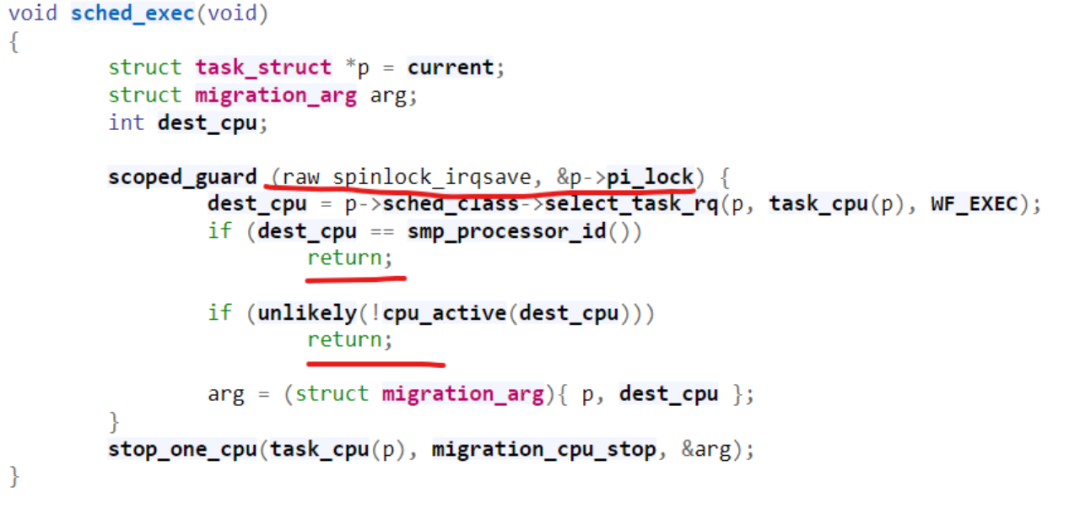
这相对于原先的代码(取自6.5内核)大为简化了:
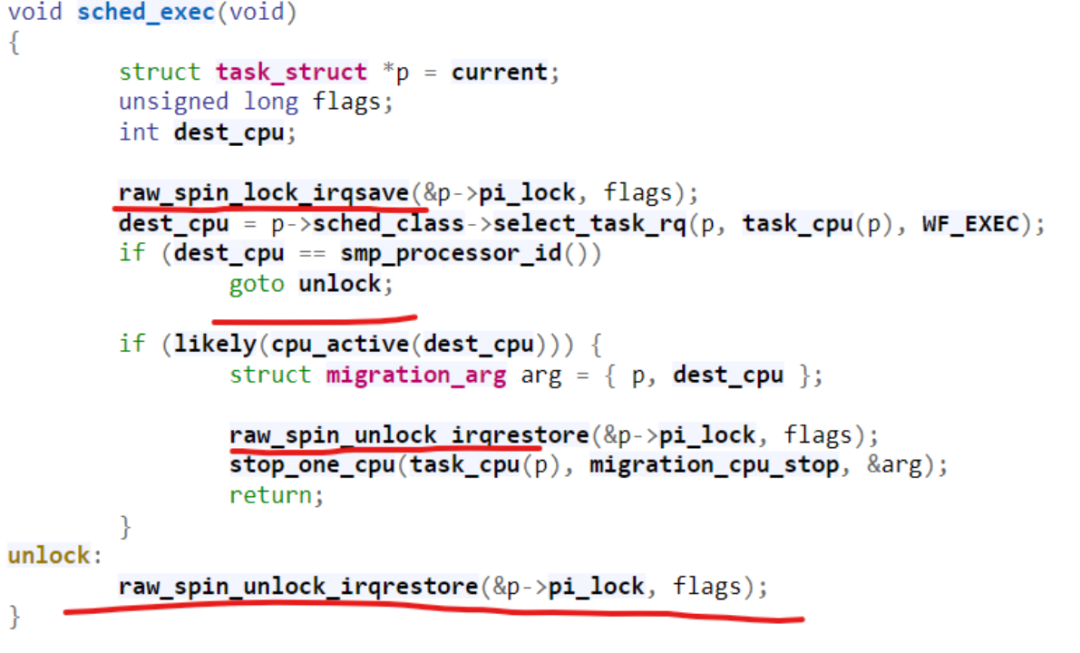

用代理执行解决优先级反转(priority inversion)问题
假设我们现在有任务p1, p2, p3,优先级顺序为p1 > p2 > p3。一个典型的优先级反转问题指的是:
假设p3先拿到了锁,p1随后想拿锁,由于它的优先级最高,于是它希望p3尽快放锁;
但是p3在执行的途中,完全可以被p2抢占,而假设p2又不需要拿锁的话,这样可能导致优先级高的p1等很久,看起来就像优先级反了p2甚至可以比p1先执行:
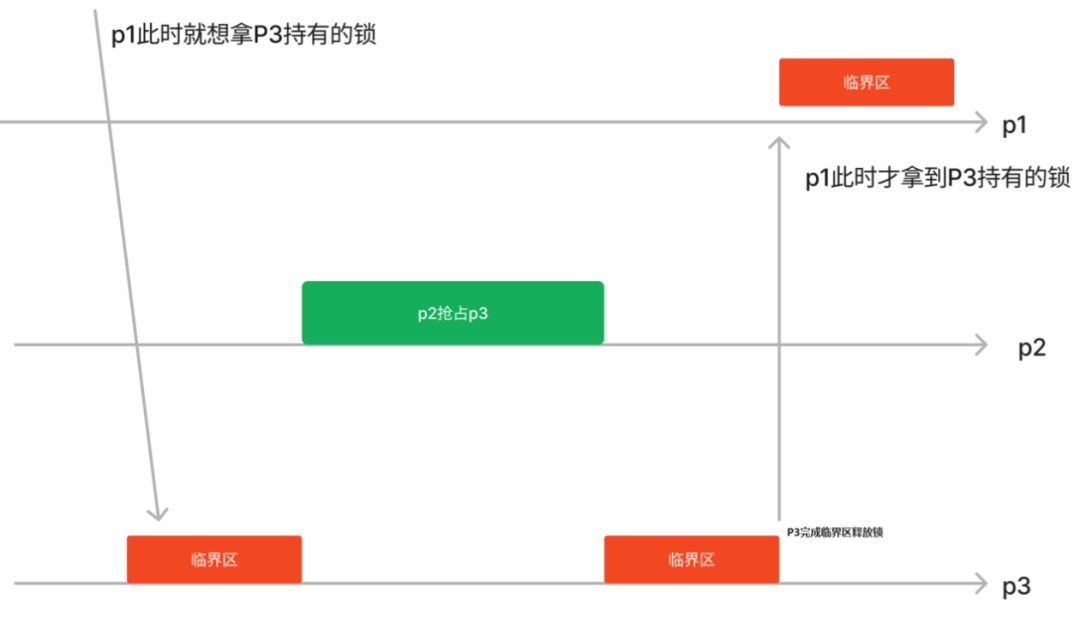
解决此类问题的最常见方法之一是优先级继承,比如在p1想拿p3持有的锁的那刻,把p3的优先级调到和p1一样,这样p2不抢占p3,p3可以加快完成临界区的执行,从而让p1尽快拿到锁。
这种经典的优先级继承方法对Linux内核的Realtime调度还算比较适用,因为Realtime调度类本身靠优先级来进行调度决策。但是对于CFS或者Deadline等调度类,调度不是一个简单由比如nice值来决定的东西,经典优先级继承方法难以适用,比如CFS里面pick_next_task()的时候考虑的是vruntime最小而不是nice值最低。Proxy execution是一种更加通用的“优先级继承”机制,如果我们把“优先级”的概念推向广义。
Proxy execution会记录P1在等什么mutex,以及这个mutex的owner是谁,比如在下图圆圈的时刻,p1想要拿p3进入临界区之前已经拿到的mutex,这一刻,按照原先的逻辑p1应该被block了应该从runqueue拿走。但是Proxy execution的选择不同,它还是死心塌地坚持“运行”p1,但是这个p1显然需要mutex运行不下去的。那么我们可以假装p1在运行,它让p3剩下的临界区借p1的壳继续运行(p3代表p1执行)。

显而易见,上述的“优先级继承”方法,并不在乎我们原先是用什么样的形式来表达p1应该优先。
正如这个patchset—— Generalized Priority Inheritance via Proxy Execution v3
链接:
https://lwn.net/ml/linux-kernel/20230601055846.2349566-1-jstultz@google.com/
的发送者来自Google的 John Stultz所述,这个工作并非他的创举,它的idea首先来自于如下的这篇paper:
https://static.lwn.net/images/conf/rtlws11/papers/proc/p38.pdf
 其后,Peter Zijlstra, Juri Lelli,Valentin Schneider和Connor O'Brien也投入了一些富有成效的工作。
其后,Peter Zijlstra, Juri Lelli,Valentin Schneider和Connor O'Brien也投入了一些富有成效的工作。

延后用户空间临界区内的抢占
在Linux内核空间,当某个CPU上的某个线程拿到spin_lock后,这个核上就不再能发生抢占调度,直到持锁的线程释放spinlock。鉴于spinlock主要针对短小的临界区,这种禁止抢占的方法,实际保证了这种短小精悍的临界区可以快速完成执行,既避免不必要的上下文切换开销,又有利于减小多任务之间spinlock的延迟等待。
但是同样的事情如果发生在用户态的spin_lock,则不会关闭抢占,也就是task A拿到spin_lock后,task B还是可以抢占A的。这在内核/用户态的不同分工角度上来看是非常合理的,如果连用户态都能随便控制抢占,那一个用户态程序就可能搞死内核调度器。用户态的spinlock不可能关抢占,比如task A拿到spinlock被task B抢占,这个时候task C想等A释放spinlock了自己再拿就要自旋很久。
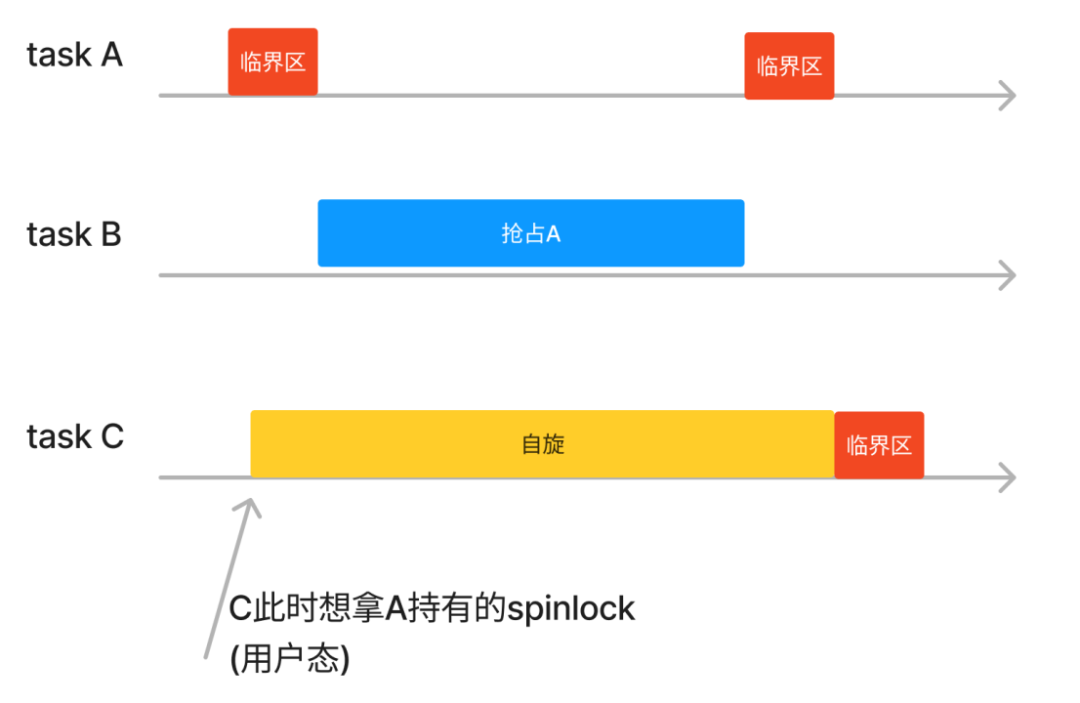
来自Google的Steven Rostedt的patchset——[POC][RFC][PATCH v2] sched: Extended Scheduler Time Slice
链接:
https://lwn.net/ml/linux-kernel/20231025235413.597287e1@gandalf.local.home/
在Steven的patch里面,仍然不可能允许用户态去关闭抢占调度,但是用户态在拿spinlock时,可以对内核进行某种暗示(比如通过在一片用户空间和内核空间共享的内存填充一个RSEQ_CR_FLAG_IN_CRITICAL_SECTION),当task B企图在A的临界区抢占的时候,内核看到这个flag,可以让抢占稍微延后一点时间允许A继续执行,这样正在spinlock临界区执行的线程A可以利用这段延后的时间,把自己的临界区执行完,这样C的自旋等待将大为缩短。

当然,这种延后抢占并不总是被执行,比如B是一个RT的任务,则完全可以无视前面的RSEQ_CR_FLAG_IN_CRITICAL_SECTION flag。

EEVDF调度
CFS更多地考虑公平性,它很难接收进程对延迟latency的表达。某些进程对延迟敏感,它可能更关心能尽早拿到CPU(否则可能影响用户体验),但是其优先级又没有达到Realtime的程度。
为了解决这个问题,Vincent Guittot、Parth Shah发了一个patchset——Add latency_nice priority
链接:
https://lwn.net/ml/linux-kernel/20220311161406.23497-1-vincent.guittot@linaro.org/
这个patchset运行进程设置一个除了调度nice值以外的latency_nice值,通过系统调用sched_setattr()来设置。
Vincent 他们在进程抢占过程中,增加了latency_nice的考量因子。当一个进程被唤醒的时候,如果它的latency_nice对应的优先级比runqueue上正在运行的进程高且没有用完它的时间片配额,则可以直接抢占正在运行的进程,而原本的CFS只看vruntime并没有考虑latency的需求因子。
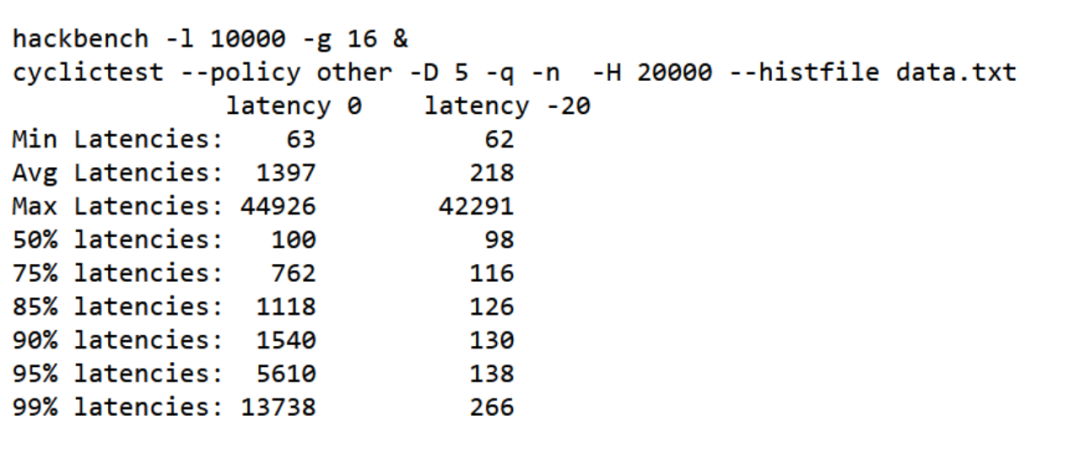
通过hackbench/cyclictest可以看出 latency优先级高的进程延迟更小:
 Latency -20的平均延迟低于latency 0的进程很多。从直方图上可以看地更准确:
Latency -20的平均延迟低于latency 0的进程很多。从直方图上可以看地更准确:
Vincent Guittot他们的patchset是有效的,但是Peter Zijlstra认为可以找到更通用的解法来利用这个latency_nice,那就是EEVDF(Earliest Eligible Virtual Deadline First)调度。EEVDF是一种基于虚拟截止时间的调度算法,它可以让进程根据它们的优先级和已经获得的CPU时间来计算它们的虚拟截止时间,然后每次选择运行虚拟截止时间最早的进程,这样就可以保证延迟敏感的进程能够及时得到CPU时间。
比如我们现在调度周期是100ms,有5个nice是0权重一样的进程,那么理论上EEVDF和CFS相似,也追求这5个进程各运行20ms(如果5个进程的nice不同,则nice会影响他们有不同的时间配额)。然后EEVDF里面增加了一个lag(滞后)值的概念,比如有人还没用完这20ms,它的lag值为正;已经用完了lag值为负。Lag值为正的人才是可以跑的,eligible的。
下图中,在时间点0,我们启动了A,B,C,D,E,最开始它们都是eligible的,在100ms的调度周期里面有配额。但是A运行了20ms后,实际它的lag没了,它不是eligible。但是这个时间轴是一直向前的,到了100ms的时间点,其实它们又都有了配额。所以它们的新的eligible_time = 100ms。

在100ms这个新的eligible时间点,到底先运行谁呢?内核的EEVDF的虚拟deadline时间
Vdeadline_time = eligible_time + time_slice它总是跑Vdeadline_time最小的那个task,所以time_slice是可以影响100ms这个eligible点运行谁的。在内核实现的EEVDF调度器中,给task分配time_slice的时候,考虑了latency_nice,如果latency的优先级高,则time_slice会分地比较小,从而让对延迟敏感的task可以优先运行。
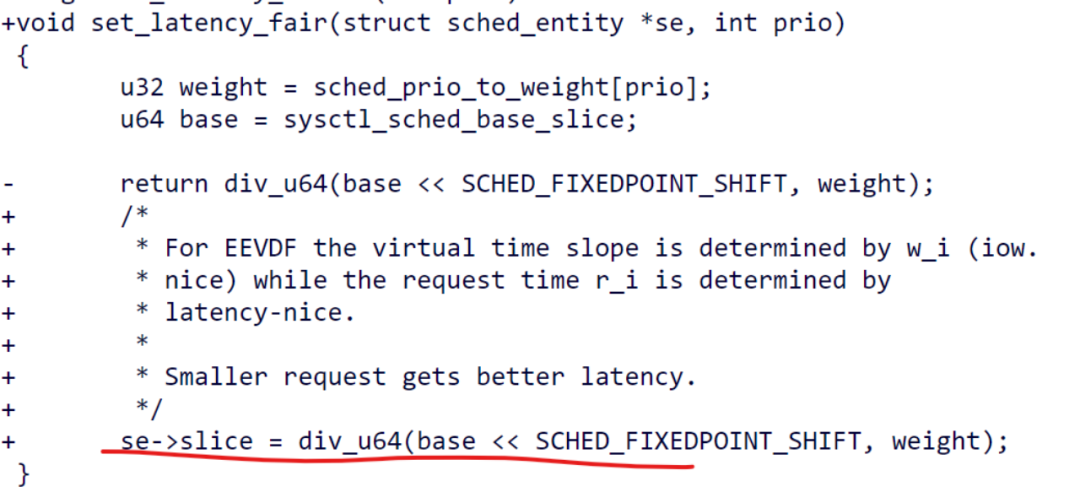
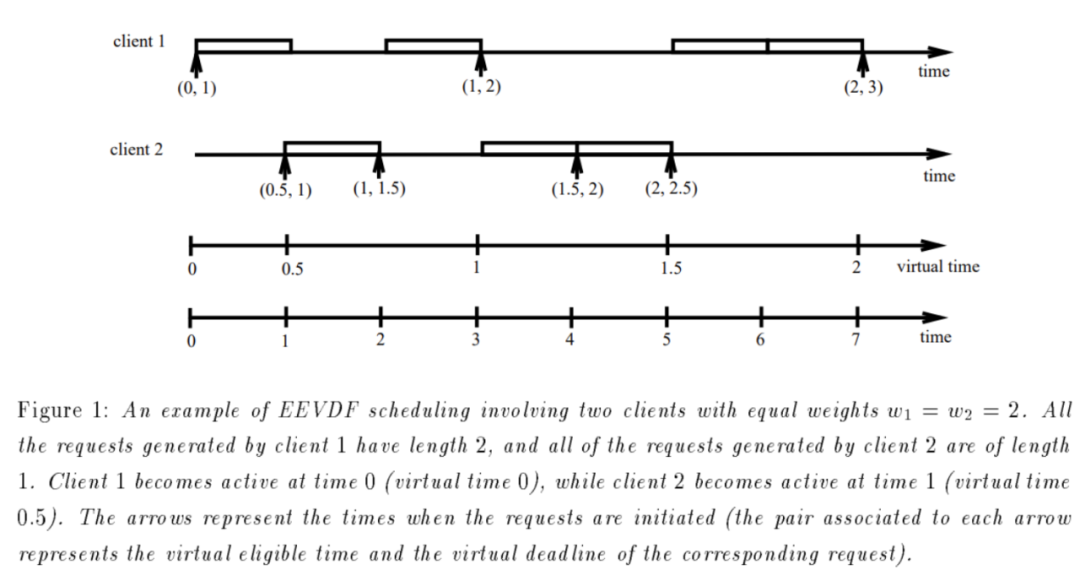
这比较符合EEVDF原生的论文,负载本身的request size是可以影响调度的(burst的小size的request应该优先):
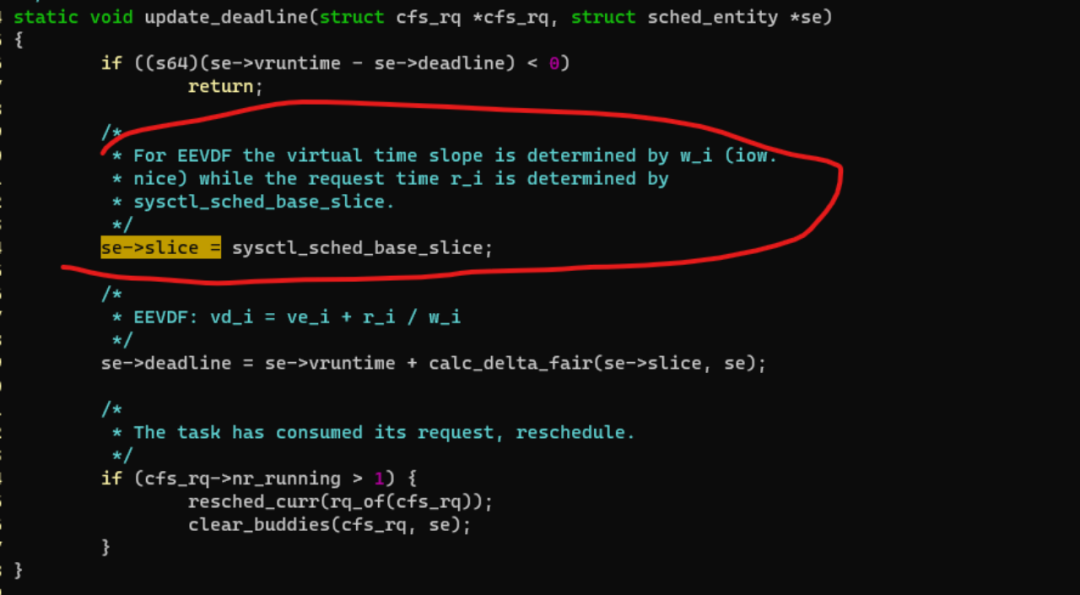
但是我们看到主线合入EEVDF的时候,latency_nice的这部分并没有合入,slice是固定的:
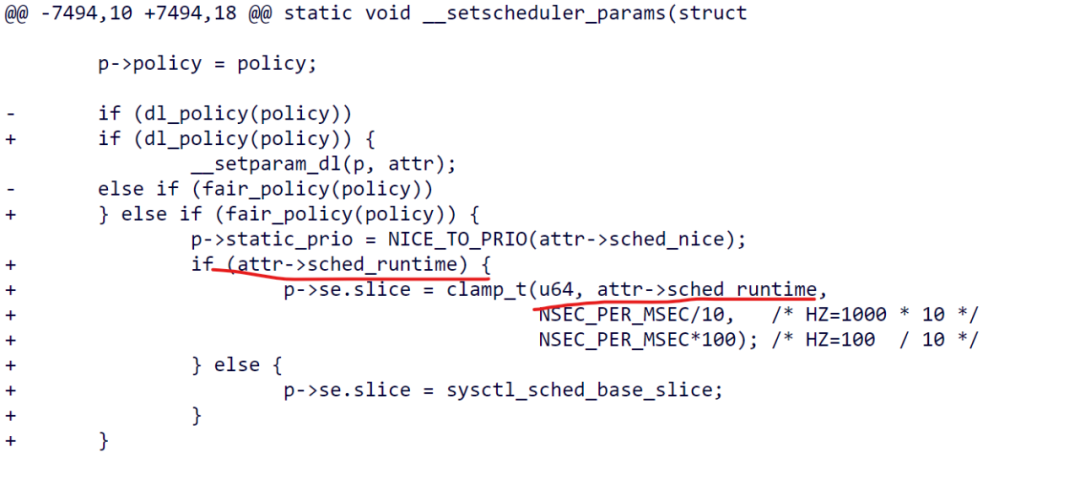
这很可能是因为latency_nice接口的暴露收到了社区较多的抱怨,Peter Zijlstra推出的一种可能变通的实现是采用
sched_attr::sched_runtime——patch [RFC][PATCH 15/15]
sched/eevdf: Use sched_attr::sched_runtime to set request/slice链接:
https://lore.kernel.org/lkml/20230531124604.615053451@infradead.org/
所以这个过程还在社区进行中。EEVDF在Linux内核代替了CFS,不过EEVDF仍然是fair.c里面实现的,属于公平类的调度算法,它跟之前CFS的相似性大于跟RT和DEADLINE调度类的相似性。

BPF通用迭代器
Andrii Nakryiko的patchset——[PATCH v3 bpf-next 0/8] BPF open-coded iterators
链接:
https://lwn.net/ml/bpf/20230307232913.576893-1-andrii@kernel.org/
实现了一个通用的BPF迭代器框架(理论上可支持cgroup, task, file等的迭代),并提供了一个简单的数字迭代器作为案例。

一个迭代器包含三个元素:
1. 构造:本例中为bpf_iter_num_new()
2. 迭代next:获得一个迭代元素
3. 析构:本例中为bpf_iter_num_destroy()
我们后续也看到Facebook的Dave Marchevsky发送了vma的open-coded迭代器——[PATCH v6 bpf-next 0/4] Open-coded task_vma iter
链接:
https://lore.kernel.org/bpf/B6AD12E1-3BFC-4AC4-87C8-9E58A586C4B4@fb.com/
它这个patchset提供的3要素如下:
1. 构造
int bpf_iter_task_vma_new(struct bpf_iter_task_vma *it,
struct task_struct *task, u64 addr);2. 迭代next:
struct vm_area_struct *bpf_iter_task_vma_next(struct bpf_iter_task_vma *it);3. 析构:
void bpf_iter_task_vma_destroy(struct bpf_iter_task_vma *it);
结语
作为全人类集体智慧的结晶,Linux内核未来还有无穷无尽的可能性等待我们去探索。最后以唐代著名Linux内核开发者李白的两句诗结束本文:祝愿童鞋们在新的一年里“大鹏一日同风起,扶摇直上九万里”。
作者简介:
宋宝华,长期的一线 Linux 内核开发者,工作于内核调度器、内存管理、ARM/ARM64 arch、设备驱动等领域,向内核提交了数百个补丁;同时也是经典书籍《Linux 设备驱动开发详解》的作者。
推荐阅读:
▶字节回应朝夕光年正与腾讯谈判出售多款游戏;苹果Vision Pro将于2月2日在美上市;Linux 6.7 发布|极客头条


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











