






 文章讲述了考研过程中“水旱区”和压分院校对考生分数的影响,建议考生在择校时要注意不同地区的评分标准和院校的压分情况。通过查看拟录取名单、代码和历年复试线来判断院校是否压分,强调扎实复习和选择合适的院校对考研成功至关重要。
文章讲述了考研过程中“水旱区”和压分院校对考生分数的影响,建议考生在择校时要注意不同地区的评分标准和院校的压分情况。通过查看拟录取名单、代码和历年复试线来判断院校是否压分,强调扎实复习和选择合适的院校对考研成功至关重要。

对咱们考研人来说,取得一个理想的分数就是最大的期许。但“水旱区”以及院校压分的存在,是高分路上小小的“绊脚石”。因此,大家在择校时尽量避开一点~
1
考研“水旱区”
水旱区是大家在历届考研里,对不同地方阅卷宽严程度的大致描述。有些地区批卷严一些被称为“旱区”,而有些地区相对宽松一些则被称为“水区”。
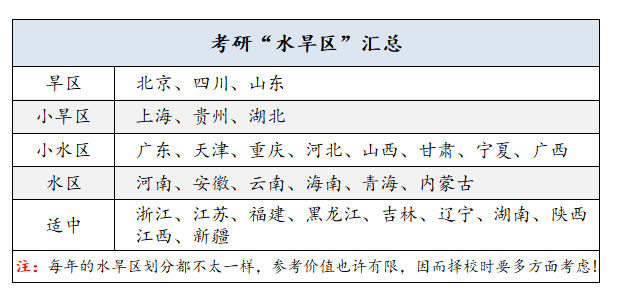
“水旱区”的划分对考研分数有影响,但不大:
①“水旱区”阅卷标准的不同主要体现在统考科目的主观题上。很多人都把考研“水旱区”想象得魔幻,以为水区分数给的都很高、旱区给的都很低,但实际上水旱区的公共课分数的差距不会那么大。
②自命题专业课的阅卷标准受水旱区的影响相对较小。毕竟每个院校会有自己的标准,很多水区院校阅卷也存在压分、给分低现象。
③不过对于需要调剂的同学来说,可能不太友好。毕竟院校收调剂都喜欢高分的,如果一志愿报考旱区院校想要调剂在水区院校,就会有点吃亏,公共课可能比竞争者少几分。
所以,想成功上岸还是要扎实复习,只要分数高,“水旱区”对咱的影响可以忽略不计!但这些会压分的院校,还是建议要慎重选择!
2
上岸密码:避开压分院校
(1) 慎选压分院校
所谓“压分”,就是指判卷标准格外高,给分很低,导致总分低。比如一道10分的题目,你的答案可以给7分,但是它只给你4分。究其原因,可能是院校想要招收更多优质生源,但也有可能是单纯题太难了...

(2) 如何判断院校是否压分
①查看拟录取名单:查看目标院校的拟录取名单,对比一志愿以及调剂上岸人数。如果调剂录取的考生特别多,就要格外注意了。
②查代码:如果录取名单中前5个数字清一色的一致,那么该院校大概率录取的都是一志愿学生。如果代码不统一,那要么是一志愿真的没招满,要么就是故意淘汰一志愿,捡漏高分调剂生!
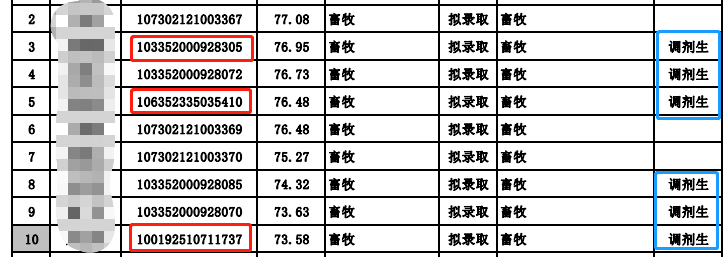
②查看一志愿考生成绩:如果普遍分数很高,说明阅卷还是比较宽松的;如果分数较低,甚至刚超过复试线,那就要特别小心了。毕竟备考了那么久,一般是不会出现学生水平无一例外都低的情况。
③对比院校近年复试线:一般来讲没有特殊原因,每年的复试线都会保持在一个相似水平,如果有哪年复试线突然大幅度降低,那就不外乎试卷变难、压分和报考人数激增这几个原因了。
总之大家在选择院校时要综合考虑很多因素,不光是院校实力、所处地域、资源条件等,关于是否压分这点也要特别注意,学校选不好,直接努力白费!
来源于网络





您还可以在以下平台找到我们




你点的每个在看,我都认真当成了喜欢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









