







人人都要学一点深度学习(1)- 为什么我们需要它
版权声明
本文由@leftnoteasy发布于 http://leftnoteasy.cnblogs.com, 如需全文转载或有其他问题请联系wheeleast (at) gmail.com。
1.开篇
1.1 为什么我开始写这个系列博客
说五年前我还在某A云公司的时候,身在一个机器学习算法组,对机器学习怀有浓厚的兴趣。花了好多的时间来试图搞清楚各种流行的机器学习算法,经常周末也跟同事探讨公式的推倒和背后的意义。写博客的主要动力是让自己能够更好的理解机器学习。
后来坚持了没有太久的时间就换到大数据方向了,最主要的原因是觉得自己数学天赋太差,尤其是数学。当初学习的时候主要参考的PRML,Andrew Moore的PPT,Andrew Ng的公开课,plukids博客,另外加上淘宝斌强哥的各种悉心指导。但是学了好久,公式能大概看懂是怎么回事,不过自己徒手推出来实在是太艰难了。PRML的习题,甚至是具体数学的习题,都很难做得出来。
后面的发生的事情就理所当然了,既然很难在这个领域做到核心(我的理解是具有及其好的数学天赋作为后盾才能做到机器学习的核心),那么为什么不换一个更适合自己的方向呢?恩好吧,基础数据架构(Infra)看起来是个不错的方向,不需要理解太多的数学(除了真的需要去实现Paxos)。做Infra如果有架构设计的基础,另外加上勤奋,多多少少还是能做出一些东西的。
为什么我又要重新开始写机器学习相关的文章了?最主要的原因是现在的机器学习和五年前、十年前区别很大。最大的不同是,自从深度学习成为了机器学习舞台上最重要的一个角色起,机器学习变得更加真实了,利用深度学习可以做出很多很有意思的真实世界的应用,而这些东西在几年前的门槛要高得多。我在本文之后会更详细的展开此点。
此外这几年的工具发展神速,利用TensorFlow、MXNet或者其他类似的工具可以很容易的开始自己的pet project,也不用理解太多背后的细节。而在几年前能用的现成工具寥寥无几,而且十分的碎片化,比如说如果想要做分类器吧,需要用libsvm,需要搞跨语言调用。如果要换个算法的话,那可是要命的事情了。当然这些东西对于大公司来说都不是事儿,但是对于个人学习者来说需要投入的经历太多了,远不是业余时间可以承担的。
1.2 What to expect?
差不多关注了几个月的深度学习,虽然没有花太多时间来写代码,但是各种各样的博客、视频、公开课还是看了一些。这个系列和几个我看过的主要内容的差异:
- 首先这个不是一个科普杂文,现在已经有很多旁征博引丰富多彩老少皆宜的杂文,比如说王川的深度学习到底有多深系列,我准备少些一些历史和背景花絮,多写一些技术。
- 其次这个不是一个系统的深度学习教程,现在已经有非常多非常好的相关公开课,比如说Stanford的CS231N\CS224D,Hilton的,Udacity的等等。我不准备写得面面俱到。
- 另外我会尽量少的涉及数学,因为我不可能把数学推导过程写得比Ian Goodfellow的Deep Learning书写得更清楚。但是我会尽量把最重要的部分写出来。
所以我希望写出的是,当看过网上的博客、公开课和书后,什么地方是最难理解的。
2. 深度学习为什么是革命性的
啰里啰嗦了这么多,开始正文了。此篇博客严重参考了来自[1]第一章Introduction的内容,包括图片和内容。
2.1 前深度学习的世界
深度学习不是一个新概念,它已经存在好几十年了,具体可以参考[1]/[2],这里所说的深度学习世界大抵是在最近几年深度学习刷新各个机器学习领域之后了。
前深度学习世界的特征就是:在人类强的地方很弱,在人类弱的地方可能很强。人类强的地方比如说图像识别(猫还是狗);图片语义分割(参考[3])比如看出一个图片中哪部分是树、哪部分是房子。人类弱的地方比如说下棋、语法标记(一个句子里面哪些是助词哪些是动词)。
这个最主要的原因是,那种对于人类来说简单的东西(在万千世界中识别出一只猫)没办法用一个正式的数学公式去描述[1]。
比如说你无法用数学公式去定义一个猫的形状。因为不同的角度、颜色、距离、光线的组合让这个基本上没有办法做到。
所以在这个基础上谈智能实在是镜中月水中花:你连一个猫都不认识,怎么能够取代人类?因为人类的世界远远比围棋要复杂得多。
[1] 里面还有一个有趣的例子,关于1989年时候著名的专家系统Cyc:
Its inference engine detected an inconsistency in the story: it knew that people do not have electrical parts, but because Fred was holding an electric razor, it believed the entity “FredWhileShaving” contained electrical parts. It therefore asked whether Fred was still a person while he was shaving.
... 它的推论引擎发现了一个前后矛盾的地方:它知道人是没有电驱动的模块,但是因为Fred拿起了一个电动剃须刀,所以这个引擎认为"一个正在剃胡子的Fred"有了一个电驱动的模块。然后这个系统就问起这个Fred到底还是不是一个人啊。
此外,前机器学习时代一个重要的特征是要设计特征,比如说如果要做一个淘宝的商品自动分类器,特征可能有商品的题目、描述、图片等等;特征还需要进行严格的预处理,比如说要过滤掉描述里面亲包邮啊这种无意义的话,而且对正文里面的描述也要进行重点抽取才能够符合训练的标准。等到特征选择、清理好了之后才能够运行出有意义的结果。而且如果需要重新选择特征,或者更改特征,那就需要重新重头来过。
曾经有些公司甚至有"特征抽取工程师"这样的职位,以前阿里同事做分类器的时候,就要特别注意不要把成人玩具分到儿童玩具的类目里面,万一被抓到把柄了那可就要丢工作了。
2.2 深度学习带来了什么
深度学习最重要的东西就是自带了特征学习(representation learning,有时候也被翻译为表征学习),简单来说就是,不需要进行特别的特征抽取。从这个来说,深度学习相对传统机器学习来说就有了太多的优势,因为一个设计好的系统能够被相对容易地移植到新的任务上去。
参考最近DeepMind发布的一个深度增强学习的无监督系统玩复杂任务游戏游戏的例子[4]。系统从游戏的屏幕像素开始自我学习,到学会玩一个复杂游戏并超过人类的专业玩家,并没有进行特别的人工特征抽取,这个在传统的机器学习方式上看起来是很难想象的。
此外深度学习另外的一个优势是,可以表述相对与浅度学习更复杂的东西,这里不准备展开描述,不然就要提到XOR,维度诅咒(The Curse of Dimensionality)等等相对枯燥而且很难说清楚的理论知识了。简单来说,提升维度当然是一个很厉害人人都想的东西,参考三体中的降维打击。但是与此同时也带来了很多计算上的挑战,得益于这几年神经科学,算法研究和硬件(特别是GPU)提升,我们可以尝试越来越深的模型。
3. 现在(2016)的深度学习究竟在什么位置
同样,主要参考了[1]的综述部分:
首先衡量深度网络的复杂程度主要有两个方面:1. 网络中一共有多少个神经元,2. 每个神经元平均与多少个其他的神经元连接。
首先是连接的数量:
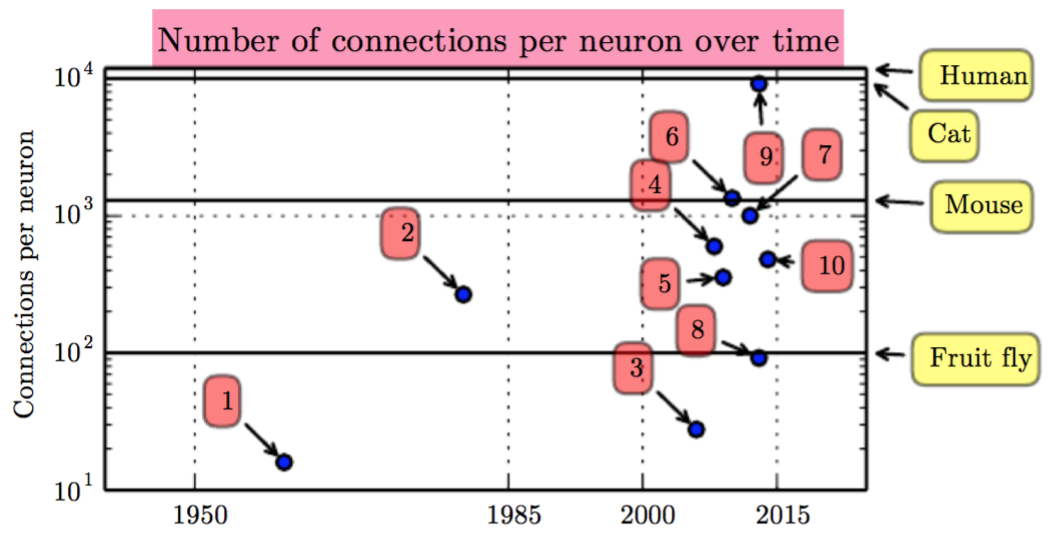
每个蓝色的小点表示一些里程碑级别的系统公布的结果,比如说10. 就是GoogLeNet (Szegedy et al., 2014a)
从这点看来,似乎还是挺乐观的,比如说10. 已经很接近人类了,但是看看下面。。。
神经元的数量:
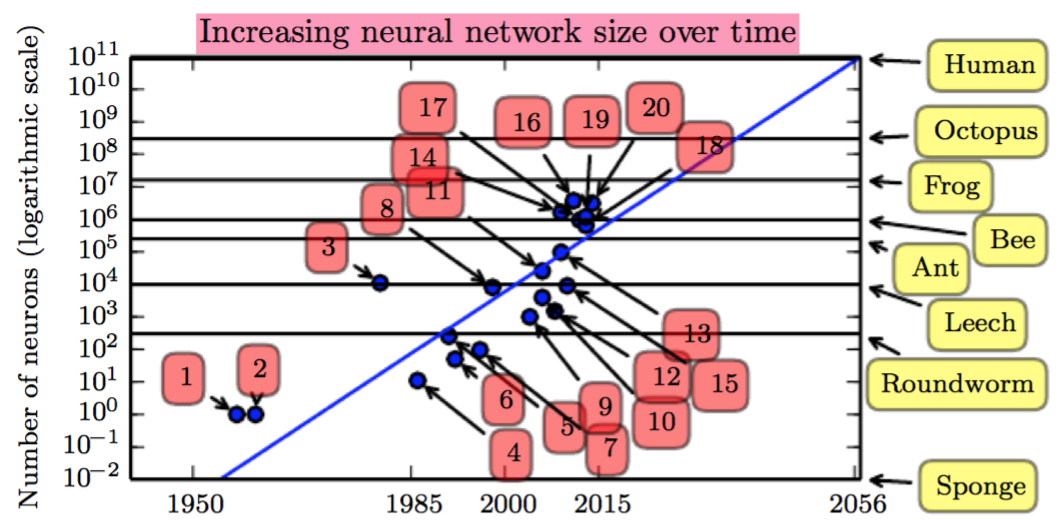
可以看到,目前最先进的系统所模拟的神经元的数量处于蜜蜂和青蛙之间。蓝色的线表示预估的增长曲线,如果在没有革命性的进步前,系统差不多可以到2050年的时候模拟人类同样的神经元的数目,所以革命之路还很漫长。
但是从另一方面来说,神经元的数目也不是唯一的衡量标准,就像是玩星际一样,APM 150的意识派也可以完虐500的抽经流选手。我们可以教一个神经元如此少的系统玩复杂的电子游戏,但是我们没有办法教一个青蛙玩这种游戏。所以也不用悲观,也许西部世界似的人工智能会到来得比想象中更早。
引用
[1] Deep Learning: Ian Goodfellow, Yoshua Bengio, Aaron Courville
[2] [王川的深度学习到底有多深系列](http://wangchuan.blog.caixin.com/archives/142598)
[3] [http://stackoverflow.com/questions/33947823/what-is-semantic-segmentation-compared-to-segmentation-and-scene-labeling](http://stackoverflow.com/questions/33947823/what-is-semantic-segmentation-compared-to-segmentation-and-scene-labeling)
[4] [https://deepmind.com/blog/reinforcement-learning-unsupervised-auxiliary-tasks/](https://deepmind.com/blog/reinforcement-learning-unsupervised-auxiliary-tasks/)














 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









