






正则表达式(Regular Expressions)
正则表达式(regex)是被用来识别一些正则字符串。即,正则表达式定义了“你给我的字符串符合规则,否则,则丢弃。”这可以用来很快的扫描大量的文本,比如:电话号码或者邮件地址。
这里用到了一个短语正则字符串(regular string)。那什么事正则字符串呢?正则字符串是满足一系列规则的字符串,比如:
1. 写字母“a”至少一次;
2. 然后,添加字母“b”五次;
3. 再然后,包含字母“c”任意偶数次;
4. 可选择的,以字母“d”结尾。
满足这些规则的字符串有“aaaabbbbccccd”,”aabbbbbcc”等等。(有无数的变种。(an infinite number of variations))。
正则表达式则是包含这些规则的缩写。比如,这些规则的正则表达式可以描述为:
aa*bbbbb(cc)*(d|)这个字符串初次看上去有一点难以理解,经过我们对其分析,就会变得很清楚:
aa* —— 写一个字母“a”,然后跟着“a*”。“a*”的意思是任意个字母“a”。通过这种方式,我们可以保证字母“a”至少写一次。
bbbbb —— 没有特殊的含义,就是写了连续五个字母“b”。
(cc)* —— 任意偶数个c的组合。
(d|) —— 在两个表达式之间添加一个”|”表示是这两个表达式之间的任意一个。
可以通过RegexPal来检测正则表达式与字符串之间是否匹配。
一个经典的正则表达式的例子是邮箱地址的识别。下面是我们设置的一个邮箱地址识别的规则:
| 规则1:邮箱地址的第一部分至少包含了以下的情况:大写字母、小写字母、数字0-9,点(.),加号(+),或者下划线(_)。 | “` [A-Za-z0-9\._+]+ “` 这个正则表达式的缩写是相当智能的。所有的字符都在中括号内,其意味着中括号内的所有的字符中的任意一次;“+”意味着括号内的内容可以出现至少一次。 |
| 规则2:邮箱地址包含了@字符。 | “`@“` 这个是相当直接的,仅有一个@。 |
| 规则3: 接下来包含了至少一个大写的字母或者小写字母。 | “`[A-Za-z]+“` 这个表示@后面的域名的第一部分。 |
| 规则4: 接下来是.。 | “`\.“` 在域名之前。 |
| 规则5:最后是com, org, edu, net(当然实际上有很多可能的顶级域名,这里只是一个例子)。 | (com|org|edu|net) 这里包含了可能的顶级域名。 |
整合这些规则,我们可以得出正则表达式:
[A-Za-z0-9\._+]+@[A-Za-z]+\.(com|org|edu|net)当你试图写一个爬虫程序的正则表达式的时候,首先最好列举出可能的步骤,这些步骤描述了你想要的字符串像什么。注意一些边缘示例。比如,你正在识别电话号码,你是否考虑到国家代码以及其它的扩展?
下表列举了一些常见的正则表达式符号,以及简单的解释和例子。这里并没有全部列举出所有的符号,正如前面所言,你可能遇到一些变化。然而,这12个符号是Python中最常见的用于正则表达式的符号,可以用来发现以及收集大多数的字符串类型。
|
|
|
|
|
| * | 匹配在其之前的字符,子表达式或者括号内的字符,**0次或者多次** | a* b* | aaaaaaaa, aaabbbb, bbbbbb |
| + | 匹配在其之前的字符,子表达式或者括号内的字符,**1次或者多次** | a+b+ | aaaaaaaab, aaabbbbb, abbbbb |
| [] | 匹配括号内的任意字符(即,匹配这些字符中的任意一个) | [A-Z]* | APPLE, CAPITALS, QWERTY |
| () | 一个组合的子表达式(与[]的不同应该是其是一个子表达式的组合,而[]是字符的组合。) | (a* b)* | aaabaab, abaaab, ababaaaab |
| {m,n} | 匹配之前的字符,子表达式,活着带有括号字符,m到n次(包括了界限) | a{2,3}b{2,3} | aabbb, aaabbb, aabb |
| [^] | 匹配不在括号内的任意单个字符 | [^A-Z]* | apple, lowercase, qwerty |
| | | 匹配被“|”分离的任意字符,字符串或者子表达式 | b(a|i|e)d | bad, bid, bed |
| . | 匹配任意单个字符(包括了符号,数字,空格等等) | b.d | bad, bad, b$d, b d |
| ^ | 表明一个字符或者子表达式出现在字符串的开头 | ^a | apple, asdf, a |
| \ | 反定义符 | \.\|\\ | .|\ |
| $ | 经常出现在正则表达式的末尾,功能是“匹配这个直到字符的结尾”。没有它,每个正则表达式有一个实际上的”.*”作为结尾,接收那些只有字符的第一个匹配的字符串。这种想法与”^”是一致的。 | [A-Z]* [a-z]*$ | ABCabc, zzzyx, Bob |
| ?! | “不要包含”。符号的奇配对,立即先于一个字符(或者表达式)发生,表明字符不应该出现在更大的字符串的特殊位置。这个应该谨慎使用;毕竟,字符可能出现在字符串的不同位置。如果试图去完全消除一个字符,可以使用^和$联合使用。 | ^((?![A-Z]).)*$ | no-caps-here, $ymb0ls a4e f!ne |
正则表达式:不要一直正则
正则表达式的标准版本是基于Perl的设定。大多数当前的编程语言都使用这个或者与之相似的标准。需要清醒的是,如果在另外一个编程语言使用的时候,可能会遇到问题。在这种情况下,就要读相应的文档了。
正则表达式与BS
现在我们来对 http://www.pythonscraping.com/pages/page3.html 进行爬虫。在这个链接中,有许多的产品图像,他们采用了以下的形式:
<img src = "../img/gifts/img3.jpg">如果我们想要获得所有的产品图像的URL,看上去我们可以直接使用 .findall("img") 来实现?
from urllib.request import urlopen
from urllib.error import HTTPError, URLError
from bs4 import BeautifulSoup
try:
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
except HTTPError as e:
print("The server couldn't could not fulfill the request.")
print(e.code)
except URLError as e:
print("Reaching a server is failed.")
print(e.reason)
else:
bsObj = BeautifulSoup(html)
imgList = bsObj.findAll("img")
for img in imgList:
print(img["src"])结果为:
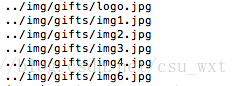
从中,我们可以发现,其中不仅包含了产品图像的URL,而且还包含了logo图像的URL。解决的方案为识别标签看上去的样子。
from urllib.request import urlopen
from urllib.error import HTTPError, URLError
from bs4 import BeautifulSoup, re
try:
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
except HTTPError as e:
print("The server couldn't could not fulfill the request.")
print(e.code)
except URLError as e:
print("Reaching a server is failed.")
print(e.reason)
else:
bsObj = BeautifulSoup(html)
images = bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts\/img.*\.jpg")})
for image in images:
print(image["src"])结果为:
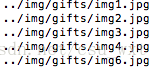
获得属性(accessing attribute)
迄今为止,我们都是在关注如何接近和过滤标签以及接近内容。然而,在网络爬虫中,你经常不是寻找标签的内容;相反,你试图寻找它的属性。这对于标签来说是非常有用的,比如<a> ,其包含一个href 属性,或者img 标签中的src 属性。
有了一个标签对象,一个Python属性列表会自动通过调用来获得:
myTag.attrs这个语句返回一个Python字典对象。对于一个图像的源位置,可以通过以下获得:
myImgTag.attrs['src']Lambda表达式
一个lambda表达式是一个函数,该函数将另外一个函数作为变量。也就是说,不是定义一个函数诸如 f(x,y) ,而是 f(g(x),y) ,甚至是 f(g(x),h(x)) 。
BS允许我们传递函数的某些类型作为参数到findAll() 函数中。唯一的要求就是这些函数必须将标签对象作为一个参数,然后返回一个布尔类型。每个BS遇到的标签对象就用这个函数作为评价,标签被评价为“True”的时候被返;否则,不会。
比如,下面检索了包含两个属性的标签:
soup.findAll(lambda tag: len(tag.attrs) == 2)会发现如下的标签:
<div class = "body" id = "content"></div>
<span style = "color:red" class = "title"></span>如果BS满足不了你的需求的时候,可以使用下面的库:
lxml —— 这个库是用来分解HTML和XML文档的,且是基于C语言的。虽然需要花时间来学习,却能很快的分解大部分的HTML文档。
HTML Parser —— 是Python自带的分解库(https://docs.python.org/3/library/html.parser.html)。由于他不需要安装,所以非常方便使用。














 2359
2359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









