






http://blog.csdn.net/drshenlei/article/details/4261909
文标题:Memory Translation and Segmentation
原文地址:http://duartes.org/gustavo/blog/
本文是Intel兼容计算机(x86)的内存与保护系列文章的第一篇,延续了启动引导系列文章的主题,进一步分析操作系统内核的工作流程。与以前一样,我将引用Linux内核的源代码,但对Windows只给出示例(抱歉,我忽略了BSD,Mac等系统,但大部分的讨论对它们一样适用)。文中如果有错误,请不吝赐教。
在支持Intel的主板芯片组上,CPU对内存的访问是通过连接着CPU和北桥芯片的前端总线来完成的。在前端总线上传输的内存地址都是物理内存地址,编号从0开始一直到可用物理内存的最高端。这些数字被北桥映射到实际的内存条上。物理地址是明确的、最终用在总线上的编号,不必转换,不必分页,也没有特权级检查。然而,在CPU内部,程序所使用的是逻辑内存地址,它必须被转换成物理地址后,才能用于实际内存访问。从概念上讲,地址转换的过程如下图所示:
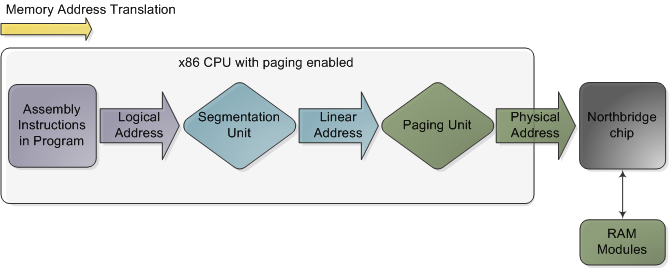
x86 CPU开启分页功能后的内存地址转换过程
此图并未指出详实的转换方式,它仅仅描述了在CPU的分页功能开启的情况下内存地址的转换过程。如果CPU关闭了分页功能,或运行于16位实模式,那么从分段单元(segmentation unit)输出的就是最终的物理地址了。当CPU要执行一条引用了内存地址的指令时,转换过程就开始了。第一步是把逻辑地址转换成线性地址。但是,为什么不跳过这一步,而让软件直接使用线性地址(或物理地址呢?)其理由与:“人类为何要长有阑尾?它的主要作用仅仅是被感染发炎而已”大致相同。这是进化过程中产生的奇特构造。要真正理解x86分段功能的设计,我们就必须回溯到1978年。
最初的8086处理器的寄存器是16位的,其指令集大多使用8位或16位的操作数。这使得代码可以控制216个字节(或64KB)的内存。然而Intel的工程师们想要让CPU可以使用更多的内存,而又不用扩展寄存器和指令的位宽。于是他们引入了段寄存器(segment register),用来告诉CPU一条程序指令将操作哪一个64K的内存区块。一个合理的解决方案是:你先加载段寄存器,相当于说“这儿!我打算操作开始于X处的内存区块”;之后,再用16位的内存地址来表示相对于那个内存区块(或段)的偏移量。总共有4个段寄存器:一个用于栈(ss),一个用于程序代码(cs),两个用于数据(ds,es)。在那个年代,大部分程序的栈、代码、数据都可以塞进对应的段中,每段64KB长,所以分段功能经常是透明的。
现今,分段功能依然存在,一直被x86处理器所使用着。每一条会访问内存的指令都隐式的使用了段寄存器。比如,一条跳转指令会用到代码段寄存器(cs),一条压栈指令(stack push instruction)会使用到堆栈段寄存器(ss)。在大部分情况下你可以使用指令明确的改写段寄存器的值。段寄存器存储了一个16位的段选择符(segment selector);它们可以经由机器指令(比如MOV)被直接加载。唯一的例外是代码段寄存器(cs),它只能被影响程序执行顺序的指令所改变,比如CALL或JMP指令。虽然分段功能一直是开启的,但其在实模式与保护模式下的运作方式并不相同的。
在实模式下,比如在引导启动的初期,段选择符是一个16位的数值,指示出一个段的开始处的物理内存地址。这个数值必须被以某种方式放大,否则它也会受限于64K当中,分段就没有意义了。比如,CPU可能会把这个段选择符当作物理内存地址的高16位(只需将之左移16位,也就是乘以216)。这个简单的规则使得:可以按64K的段为单位,一块块的将4GB的内存都寻址到。遗憾的是,Intel做了一个很诡异的设计,让段选择符仅仅乘以24(或16),一举将寻址范围限制在了1MB,还引入了过度复杂的转换过程。下述图例显示了一条跳转指令,cs的值是0x1000:
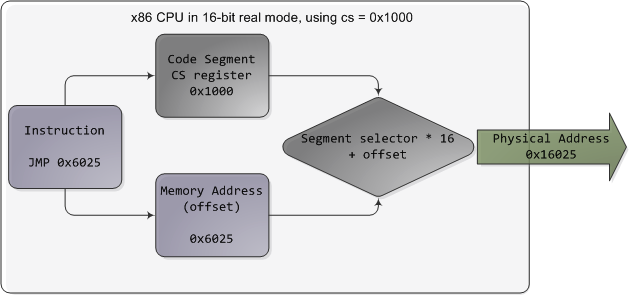
实模式分段功能
实模式的段地址以16个字节为步长,从0开始编号一直到0xFFFF0(即1MB)。你可以将一个从0到0xFFFF的16位偏移量(逻辑地址)加在段地址上。在这个规则下,对于同一个内存地址,会有多个段地址/偏移量的组合与之对应,而且物理地址可以超过1MB的边界,只要你的段地址足够高(参见臭名昭著的A20线)。同样的,在实模式的C语言代码中,一个远指针(far pointer)既包含了段选择符又包含了逻辑地址,用于寻址1MB的内存范围。真够“远”的啊。随着程序变得越来越大,超出了64K的段,分段功能以及它古怪的处理方式,使得x86平台的软件开发变得非常复杂。这种设定可能听起来有些诡异,但它却把当时的程序员推进了令人崩溃的深渊。
在32位保护模式下,段选择符不再是一个单纯的数值,取而代之的是一个索引编号,用于引用段描述符表中的表项。这个表为一个简单的数组,元素长度为8字节,每个元素描述一个段。看起来如下:

段描述符
有三种类型的段:代码,数据,系统。为了简洁明了,只有描述符的共有特征被绘制出来。基地址(base address)是一个32位的线性地址,指向段的开始;段界限(limit)指出这个段有多大。将基地址加到逻辑地址上就形成了线性地址。DPL是描述符的特权级(privilege level),其值从0(最高特权,内核模式)到3(最低特权,用户模式),用于控制对段的访问。
这些段描述符被保存在两个表中:全局描述符表(GDT)和局部描述符表(LDT)。电脑中的每一个CPU(或一个处理核心)都含有一个叫做gdtr的寄存器,用于保存GDT的首个字节所在的线性内存地址。为了选出一个段,你必须向段寄存器加载符合以下格式的段选择符:

段选择符
对GDT,TI位为0;对LDT,TI位为1;index指出想要表中哪一个段描述符(译注:原文是段选择符,应该是笔误)。对于RPL,请求特权级(Requested Privilege Level),以后我们还会详细讨论。现在,需要好好想想了。当CPU运行于32位模式时,不管怎样,寄存器和指令都可以寻址整个线性地址空间,所以根本就不需要再去使用基地址或其他什么鬼东西。那为什么不干脆将基地址设成0,好让逻辑地址与线性地址一致呢?Intel的文档将之称为“扁平模型”(flat model),而且在现代的x86系统内核中就是这么做的(特别指出,它们使用的是基本扁平模型)。基本扁平模型(basic flat model)等价于在转换地址时关闭了分段功能。如此一来多么美好啊。就让我们来看看32位保护模式下执行一个跳转指令的例子,其中的数值来自一个实际的Linux用户模式应用程序:
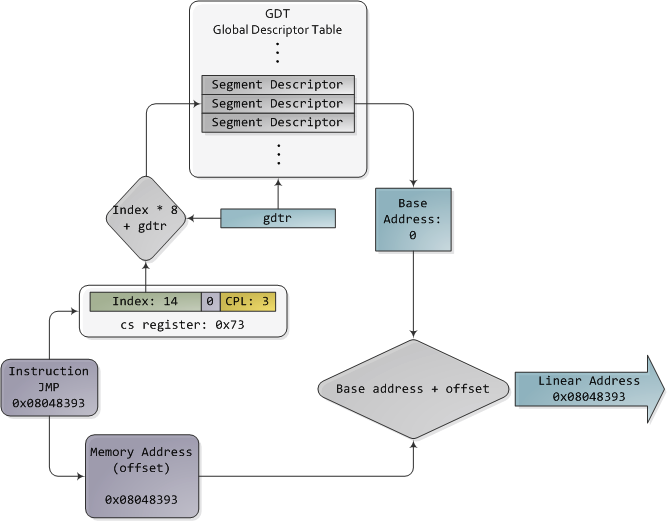
保护模式的分段
段描述符的内容一旦被访问,就会被cache(缓存),所以在随后的访问中,就不再需要去实际读取GDT了,否则会有损性能。每个段寄存器都有一个隐藏部分用于缓存段选择符所对应的那个段描述符。如果你想了解更多细节,包括关于LDT的更多信息,请参阅《Intel System Programming Guide》3A卷的第三章。2A和2B卷讲述了每一个x86指令,同时也指明了x86寻址时所使用的各种类型的操作数:16位,16位加段描述符(可被用于实现远指针),32位,等等。
在Linux上,只有3个段描述符在引导启动过程被使用。他们使用GDT_ENTRY宏来定义并存储在boot_gdt数组中。其中两个段是扁平的,可对整个32位空间寻址:一个是代码段,加载到cs中,一个是数据段,加载到其他段寄存器中。第三个段是系统段,称为任务状态段(Task State Segment)。在完成引导启动以后,每一个CPU都拥有一份属于自己的GDT。其中大部分内容是相同的,只有少数表项依赖于正在运行的进程。你可以从segment.h看到Linux GDT的布局以及其实际的样子。这里有4个主要的GDT表项:2个是扁平的,用于内核模式的代码和数据,另两个用于用户模式。在看这个Linux GDT时,请留意那些用于确保数据与CPU缓存线对齐的填充字节——目的是克服冯·诺依曼瓶颈。最后要说说,那个经典的Unix错误信息“Segmentation fault”(分段错误)并不是由x86风格的段所引起的,而是由于分页单元检测到了非法的内存地址。唉呀,下次再讨论这个话题吧。
Intel巧妙的绕过了他们原先设计的那个拼拼凑凑的分段方法,而是提供了一种富于弹性的方式来让我们选择是使用段还是使用扁平模型。由于很容易将逻辑地址与线性地址合二为一,于是这成为了标准,比如现在在64位模式中就强制使用扁平的线性地址空间了。但是即使是在扁平模型中,段对于x86的保护机制也十分重要。保护机制用于抵御用户模式进程对系统内核的非法内存访问,或各个进程之间的非法内存访问,否则系统将会进入一个狗咬狗的世界!在下一篇文章中,我们将窥视保护级别以及如何用段来实现这些保护功能。















 2629
2629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









