






java IO
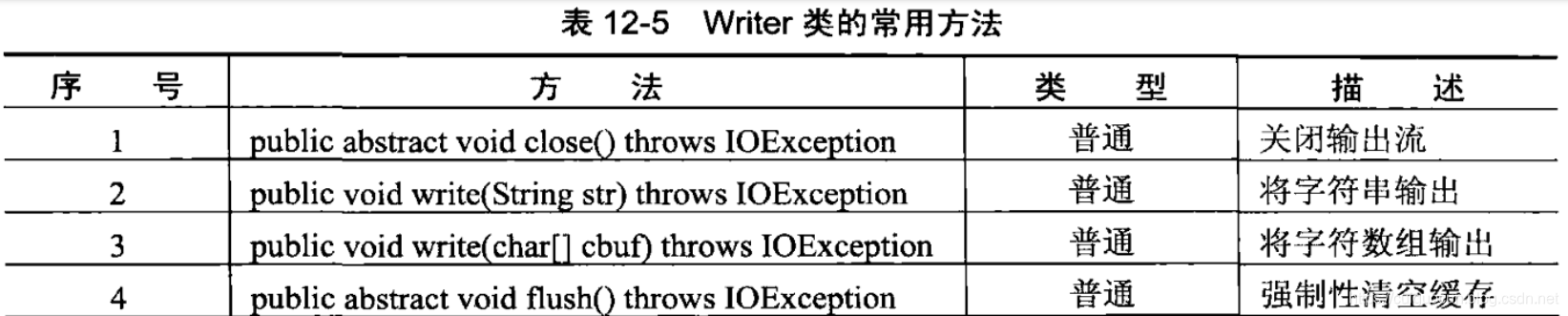
java IO操作主要是指使用java进行输入、输出操作,java中的所有操作类都存在java.io包中。
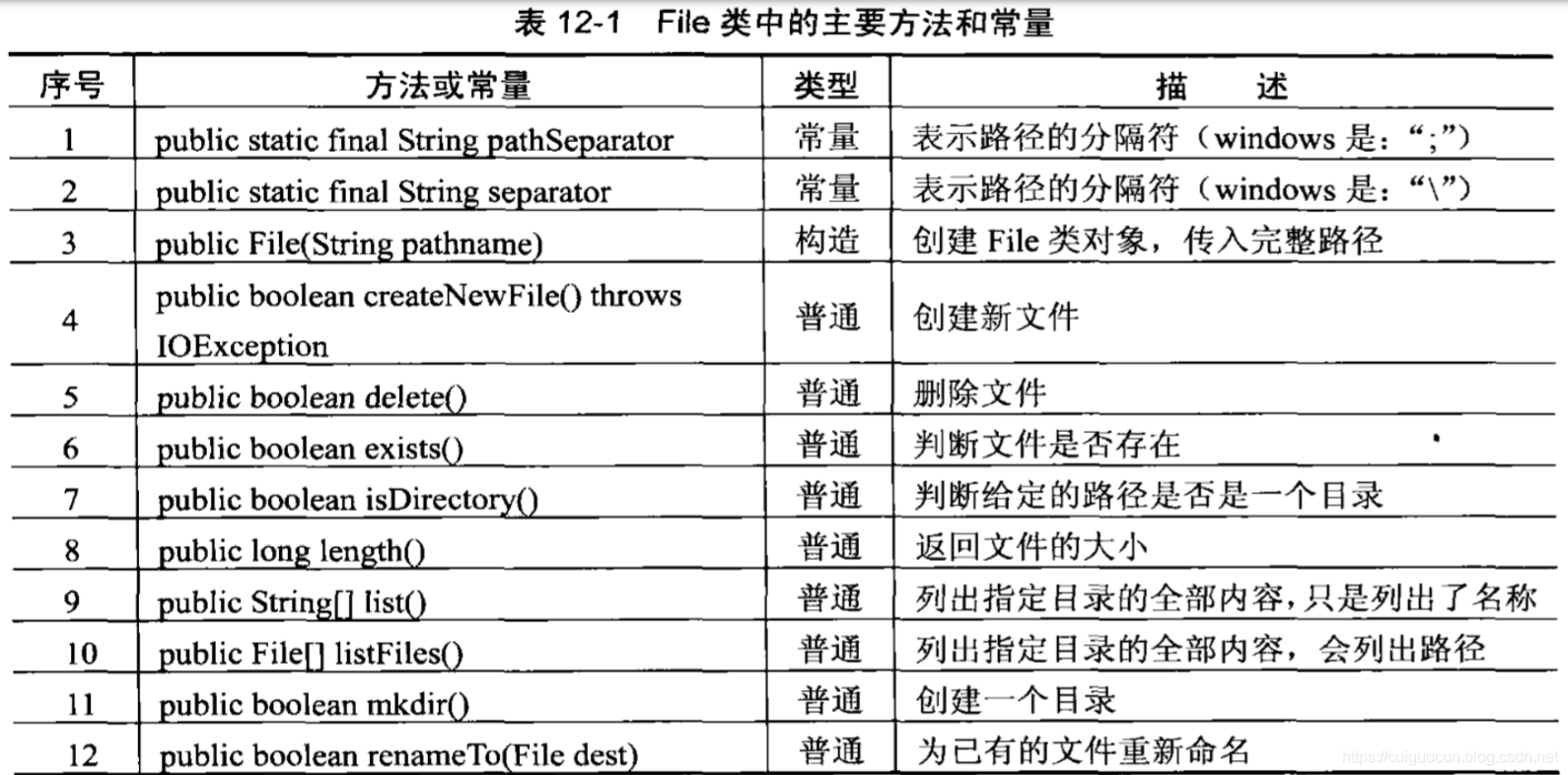
在整个java包中最重要的就是5个类和1个接口,5个类是指FIle、InputStream、OutputStream、Reader、Writer;一个接口指的是Serializable。
操作文件的类–File
在整个io包中,唯一与文件本身有关的类就是File类,使用File类可以创建或者删除文件等常用操作,要使用File类则首先观察File类的构造方法:
public File(String pathname) 实例化File类必须设置好路径
可以发现,如果要使用一个File类,则必须向File类的构造方法中传递一个文件路径。
例如:D盘下的test.txt文件。路径必须写成"d:\test.txt",其中\表示一个
windows使用反斜杠表示目录的分隔符“\”
Linux使用正斜杠表示目录的分隔符 “/”
实例操作;创建一个新文件
File类对象实例化完成之后,就可以使用creatNewFile创建一个新文件,但是此方法使用了throws关键字,
所以在使用时必须使用try....catch进行异常处理(在D盘创建一个test.txt文件)
public class Test3{
public static void main(String[] args) {
File file=new File("d:\\test.txt");
try {
file.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
结果是在D盘已经创建好了文件。
那么java程序本身具有可移植性的特点,则在编写路径时,最好可以根据程序所在的操作系统自动使用符合
本地操作系统要求的分隔符,这样才能达到可移植性的目的。
要使用本地分隔符就要用到FIle类的两个常量:pathSeparator,separator。
public class Test3{
public static void main(String[] args) {
System.out.println(File.pathSeparator);
System.out.println(File.separator);
}
}
结果:
;
\
最好的做法是使用常量来表示路径:
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"test.txt";
File file=new File(path);
try {
file.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(File.pathSeparator);
System.out.println(File.separator);
}
}
在开发的时候一定要使用FIle.separator分隔符,这样Windows开发,Linux部署才不会出现问题。
实例二,删除一个指定的文件
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"test.txt";
File file=new File(path);
file.delete();
}
}
文件被删除了,但是这种做法存在一个问题,就是应该先判断文件存在不存在,在进行删除操作。
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"test.txt";
File file=new File(path);
boolean b=file.exists();
if(b) {
file.delete();
System.out.println("文件存在,并已经被删除。");
}else {
System.out.println("无法找到您要删除的文件。");
}
}
}
结果:
文件存在,并已经被删除。
实例:创建一个文件夹
可以使用File类指定一个文件夹,直接使用mkdir()方法就可以完成。
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"testDir";
File file=new File(path);
file.mkdir();
}
}
结果:文件夹已创建
实例:列出指定目录的全部文件
如果现在给出一个目录,可以直接列出目录中的内容,有两个方法:
public String[] list() 列出全部名称,返回一个字符串数组
public File[] listFiles() 列出一个完整路径,返回File对象数组。
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"testDir";
File file=new File(path);
String arr[]=file.list();
File f[]=file.listFiles();
System.out.println(Arrays.toString(arr));
for(int i=0;i<f.length;i++) {
System.out.println(f[i]);
}
}
}
结果:
[cui.txt, dir, sheng.txt, xian.txt]
d:\testDir\cui.txt
d:\testDir\dir
d:\testDir\sheng.txt
d:\testDir\xian.txt
实例:判断一个给定的路径是否是目录
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"testDir";
File file=new File(path);
System.out.println(file.isDirectory());
}
}
结果:
true
实例:列出指定目录和子目录的全部文件
public class Test3{
public static void main(String[] args) {
String path="d:"+File.separator+"testDir";
File file=new File(path);
print(file);
}
public static void print(File file) {
if(file != null) {
if(file.isDirectory()) {
File f[]=file.listFiles();
if(f != null) {
for(int i=0;i<f.length;i++) {
print(f[i]);
}
}
}else{
System.out.println(file);
}
}
}
}
结果:
d:\testDir\cui.txt
d:\testDir\dir\cui1.txt
d:\testDir\sheng.txt
d:\testDir\xian.txt
RandomAccessFile类
File类只是针对文件本身进行操作,而如果要对文件内容进行操作,则可以使用RandomAccessFile类,此类属于随机读取类,可以随机的读取一个文件中指定位置的数据。
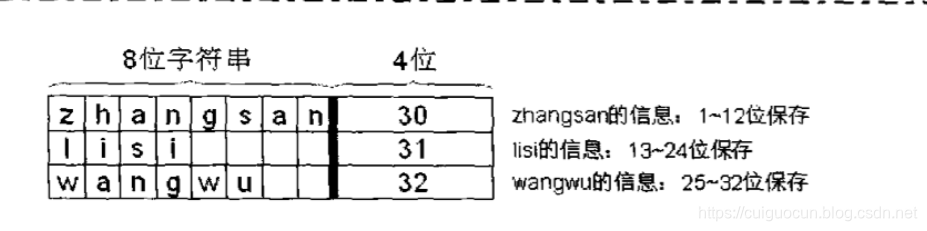
假如有数据:
zhangsan,30。
lisi,31。
王五,32。
那如果要使用RandomAccessFile类读取信息时,就可以将zhangsan的信息跳过,相当于在文件设置了一个指针,根据指针的位置读取,但是如果想实现这样的功能,则每个数据的长度应该保持一致。所以在设置姓名时应该设置8位,设置年龄时应该设置4位。
需要注意的是:如果使用rw方式声明RandomAccessFile对象时,要写入的文件不存在系统将自动创建。

使用RandomAccessFile类写入文件
为了保证进行随机读取,所以写入的名字都是8个字节,写入的数字是固定的4个字节
public class Test3{
public static void main(String[] args) throws Exception {
String path="d:"+File.separator+"testDir"+File.separator+"xian.txt";
File file=new File(path);
RandomAccessFile raf=null; //声明一个RandomAccessFile对象
raf=new RandomAccessFile(file, "rw"); //以读写的方式打开文件,自动创建新文件
String name=null;
int age=0;
name="zhangsan";
age=30;
raf.writeBytes(name);
raf.writeInt(age);
name="lisi ";
age=31;
raf.writeBytes(name);
raf.writeInt(age);
name="wangwu ";
age=33;
raf.writeBytes(name);
raf.writeInt(age);
raf.close();
}
}
public class Test2{
public static void main(String[] args) throws Exception{
String path="d:"+File.separator+"testDir"+File.separator+"xian.txt";
File file=new File(path);
RandomAccessFile raf=null;
raf=new RandomAccessFile(file, "r");
String name=null;
int age=0;
byte[] b2=new byte[8]; //准备空间读取姓名
raf.skipBytes(12);
for(int i=0;i<b2.length;i++) {//循环读取前八个内容
b2[i]=raf.readByte();
}
name=new String(b2);
age=raf.readInt();
System.out.println("第二个人信息"+name+"---"+age);
raf.seek(0); //指针回到文件头
byte[] b1=new byte[8]; //准备空间读取姓名
for(int j=0;j<b1.length;j++) {//循环读取前八个内容
b1[j]=raf.readByte();
}
name=new String(b1);
age=raf.readInt();
System.out.println("第1个人信息"+name+"---"+age);
raf.skipBytes(12);
byte[] b3=new byte[8]; //准备空间读取姓名
for(int z=0;z<b3.length;z++) {//循环读取前八个内容
b3[z]=raf.readByte();
}
name=new String(b3);
age=raf.readInt();
System.out.println("第3个人信息"+name+"---"+age);
raf.close();
}
}
结果:
第二个人信息lisi ---31
第1个人信息zhangsan---30
第3个人信息wangwu ---33
可以发现,程序中随机跳过12位读取信息,也可以回到开始点冲洗读取,随机读写流可以实现对文件内容的操作。
但一般情况下,操作文件内容往往会使用字节流或字符流。
字节流与字符流基本操作
在程序中,所有的数据都是以流的方式进行传输或者保存的,程序需要数据时要使用输入流读取数据,而当程序要将一些数据保存起来时,就要使用输出流。
在java.io包中流的操作主要有字节流、字符流两大类,两类都有输入和输出操作。在字节流输出数据主要使用OutputStream类完成,输入使用的是InputStream类。字符流依靠Writer输出,reader类输入。
1.字节流
字节流的主要操作byte类型数据,以byte数组为准。
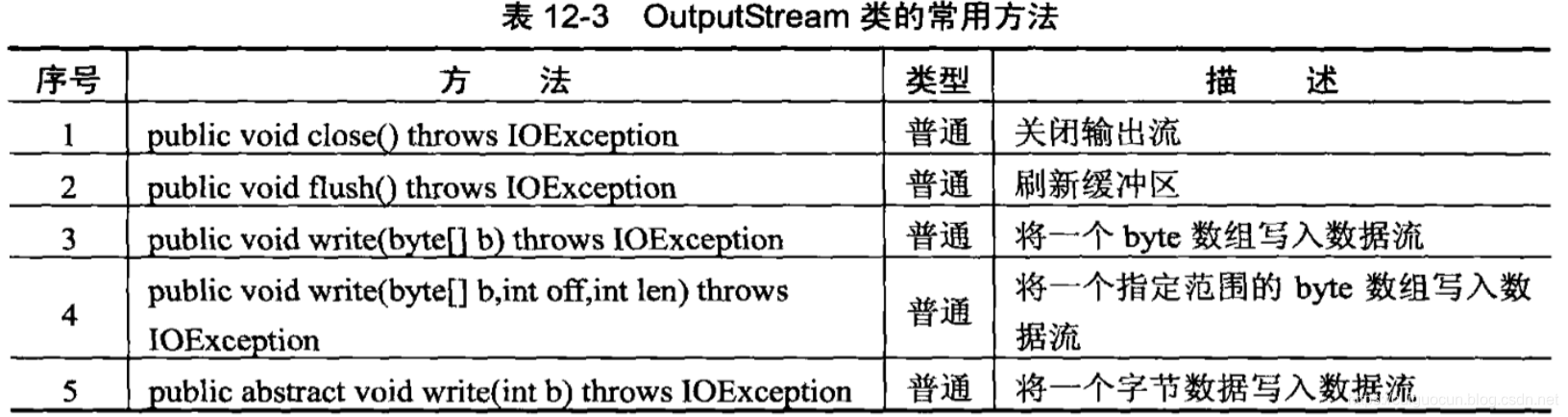
字节输出流:OutputStream
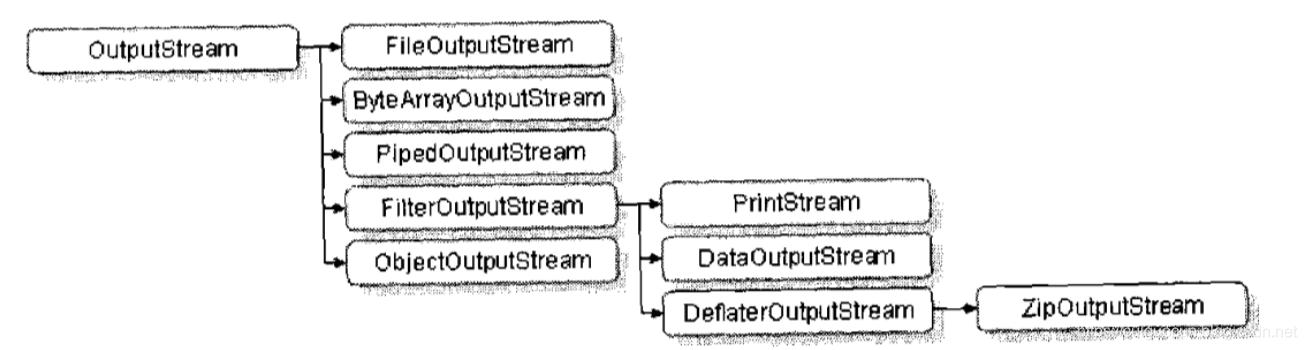
OutputStream是整个io包中字节输出流最大的父类,定义如下:
public abstract class OuputStream extends Object implements Closeable,Flushable
从以上定义可以发现,OutputStream类是一个抽象类,如果要使用此类,则首先必须通过子类实例化对象。
如果现在要操作的是一个文件,则可以使用FileOutputStream类,通过向上转型后,可以为OutputStream
实例化。
此时使用FileOutputStream子类来进行实例化OutputStream
public FileOutputStream(FIle file) throws FileNotFoundException
操作时必须接收File类的实例,指明要输出的文件路径
例子:向文件中写入字符串
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
OutputStream out=null;
out=new FileOutputStream(file);
//第三步 进行写操作
//准备一个字符串
String s="Hello China!!!";
//只能输出byte数组,所以将字符串变成byte数组
byte b[]=s.getBytes();
out.write(b);
out.close();
}
}
结果:
文件中存在字符串 Hello China!!!
***追加新内容
如果重新执行上面的程序,肯定会覆盖文件中已有的内容,那么可以使用FileOutputStream向文件中
追加内容,FileOutputStream另一个构造方法如下:
public FileOutputStream(File file,boolean append) throws FileNotFoundException
在构造方法中,如果将append的值设为true,则表示在文件的末尾追加内容。
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
OutputStream out=null;
out=new FileOutputStream(file,true);
//第三步 进行写操作
//准备一个字符串
String s="Hello China!!!";
//只能输出byte数组,所以将字符串变成byte数组
byte b[]=s.getBytes();
out.write(b);
out.close();
}
}
结果:
文件中出现两遍 Hello China!!!Hello China!!! 代表追加成功
如何增加换行呢,只需要在想要换行的地方加上"\r\n",就可以实现换行的功能了
关于Closeable和Flushable两个接口说明:
在OutputStream类中实现了这两个接口
Closebale接口定义:
public interface Closeable{
void close() throws IOException
}
Flushable接口定义:
public interface Closeable{
void flush() throws IOException
}
这两个接口的作用从其定义的方法中可以发现,Closeable表示可关闭,Flushable表示可刷新。而且在OutputStream中已经有两个这样方法的实现。而用户一般不关心这两个接口,直接调用OutputStream类就可以。
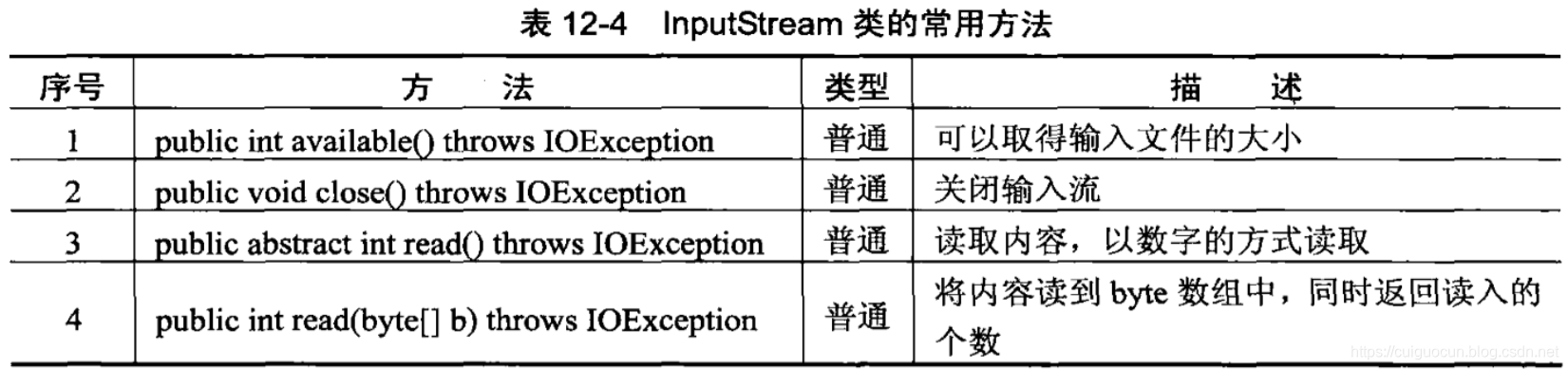
2.字节输入流InputStream
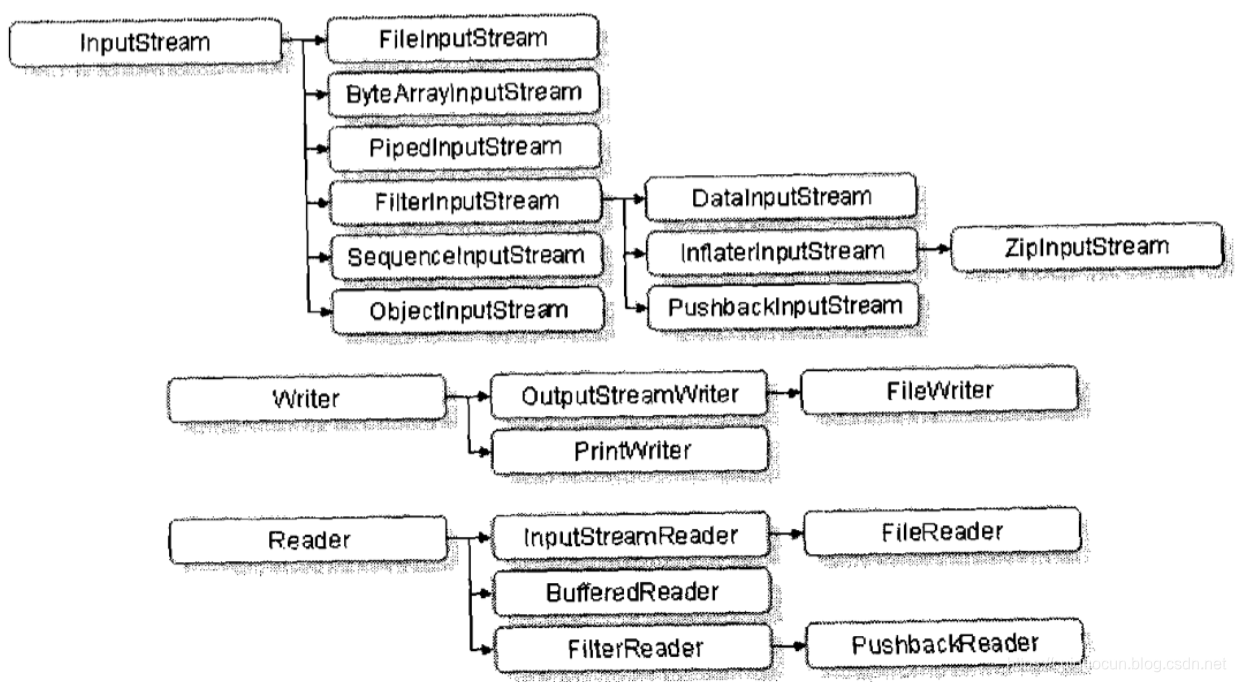
既然程序可以向文件中写内容,则可以通过InputStream把文件中的内容读取出来。InputStream定义如下:
public abstract class InputStream extends Object implements Closeable
与OutputStream类一样,InputStream类也是一个抽象类,如果要从文件中读取内容,实现的子类肯定是FileInputStream。
例子:从文件中读取内容
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
InputStream in=null;
in=new FileInputStream(file);
byte b[]=new byte[1024];
in.read(b);
in.close();
System.out.println(new String(b));
}
}
结果:
Hello China!!!Hello China!!!(后面带了很多空格) 和上面我们写入文件的结果一样
内容已经被读出来了,但是发现后面有许多空格,这是因为开辟的byte数组大小为1024,而实际内容并没有那么多。
也就是存在许多空白的空间,在将byte数组变为字符串时,也将这剩余的空间转为字符串,这样的操作肯定是
不合理的,要解决就要看read方法,这个read方法有一个返回值,此返回值表示数组中写入了多少数据
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
InputStream in=null;
in=new FileInputStream(file);
byte b[]=new byte[1024];
int len =in.read(b);
in.close();
System.out.println(new String(b,0,len));
}
}
这样结果就没有多余的空格了。
以上程序虽然最后输出没有多余的空格了,但是内容完全没有占用足够的byte数组,但是程序依然开辟了很多
空间,但是这样肯定造成了资源浪费,要根据文件的数量开辟内存空间,就要使用File类中length方法,
这个方法可以取得文件的大小。
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
InputStream in=null;
int l=(int) file.length();
in=new FileInputStream(file);
byte b[]=new byte[l];
in.read(b);
in.close();
System.out.println(new String(b));
}
}
这样结果就没有多余的空格占位了。
(也可以使用for循环进行循环数组一个一个读取)
另一种读取方式:临时变量读取:
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
InputStream in=null;
int l=(int) file.length();
in=new FileInputStream(file);
byte b[]=new byte[l];
int temp=0;
int len=0;
while((temp=in.read())!=-1) {
b[len]=(byte) temp;
len++;
}
in.close();
System.out.println(new String(b,0,len));
}
}
结果和之前一样,成功读取Hello China!!!Hello China!!!
这里注意read()方法,一个一个读了,不是一次性读取到数组中了读的。
以上程序要判断temp接收到内容是否是-1,正常情况下,不会返回-1,只有当输入流的内容已经读到底部
末尾,才会返回这个数字,通过此数字可以判断输入流中是否还有其他内容。
3.字符输出流Writer
在程序中一个字符等于两个字节,java提供了两个专门操作字符的类--Writer和Reader
Writer字符输出流定义:
public abstract class Wrtirer extends Object implements Appendable,
Closeable,Flushable
此类本身也是一个抽象类,如果要使用此类,则肯定要使用其子类进行实例化,如果是向文件中写入内容
应该使用FileWriter的子类。
Appendable接口表示内容可以被追加, 接收的参数是CharSequence,实际上String类就实现了此接口,
所以可以直接通过此接口的方法向输出流中追加内容。
FileWriter类构造方法
public FileWriter(File file) throws IOEception
范例:向文件中写入数据
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"sheng.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
Writer writer=null;
writer=new FileWriter(file);
String str="This is book!";
writer.write(str);
writer.close();
}
}
结果:
This is book!
整个程序与OutputStream的操作流没有什么太大的差异,唯一的好处就是可以直接输出字符串,而不用将
字符串变成byte数组再输出。
范例:追加文件
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"sheng.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
Writer writer=null;
writer=new FileWriter(file,true);
String str="\r\n do you want to by it? ";
writer.write(str);
writer.close();
}
}
结果:
This is book!
do you want to by it?
4.字符输入流Reader
Reader是使用字符的方式从文件中取出数据
public abstract class Reader extends Object implements Readable,Closeable
Reader本身也是抽象类,如果现在要从文件中读取内容,则可以直接使用FileReader子类。

FileReader的构造方法如下:
public FileReader(File file) throws FileNotFoundException
实例:从文件中读取内容
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname="d:"+File.separator+"testDir"+File.separator+"sheng.txt";
File file=new File(pathname);
//第二步 通过子类实例化父类
Reader read=null;
read=new FileReader(file);
char c[]=new char[(int) file.length()];
int len=0;
int temp=0;
while((temp=read.read())!=-1) {
c[len]= (char) temp;
len++;
}
read.close();
System.out.println(new String(c));
}
}
结果:
This is book!
do you want to by it?
字节流与字符流的区别
字节流和字符流使用上非常相似,两者除了操作代码的不同之外,另一个重要的不同就是:
字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时,使用了缓冲区
那么主要体现是哪里呢?
就是当我们使用输出流时不关闭它(OutputStream和Writer),这时候会发现,字节流的直接内容输出到文件中,而字符流则没有被输出到文件中。
证明字节流是操作文件本身
字符流使用了缓冲区,而在关闭字符流时,会强制性的将缓冲区的内容进行输出,但如果程序没有关闭,则缓冲区的内容无法输出。
如果在不关闭也想将字符流的内容全部输出,可以使用flush()方法,清理缓冲区。
缓冲区
缓冲区是什么?缓冲区可以简单的理解是一段内存区域
某些情况下,如果一个程序频繁的操作一个资源(文件或者数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读到内存的一块区域中,以后直接从此区域读取数据即可,这样可以提高性能。
使用字节流好还是使用字符流好?
首先所有的文件在硬盘或者在传输时,都是以字节的方式进行的。,包括图片都是按照字节的方式存储的,而字符只有在内存中才会形成,所以在开发中字节流使用广泛。
实例:文件边读边写(文件复制功能)
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname1="d:"+File.separator+"testDir"+File.separator+"sheng.txt";
String pathname2="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file1=new File(pathname1);
File file2=new File(pathname2);
if(!file1.exists()) {
System.out.println("源文件不存在");
}
InputStream in=null;
OutputStream out=null;
in=new FileInputStream(file1);
out=new FileOutputStream(file2);
int temp=0;
if(in!=null && out!=null) {
while((temp=in.read())!=-1) {
out.write(temp);
}
}
in.close();
out.close();
}
}
结果:
成功将文件内容复制到另一个文件中。
转换流
转换流OutputStreamWriter类与InputStreamReader类
整个IO包实际上分为字节流和字符流,但是除了这两个流之外,还存在一组字节流-字符流的转换类。
OutputStreamWriter:是一个Writer的子类,将输出的字符流变为字节流,即将一个字符流的输出对象变为
字节流输出对象。
InputStreamReader:是Reader的子类,将输入的字节流变为字符流,即将一个字节流的输入对象变为
字符流的输入对象。
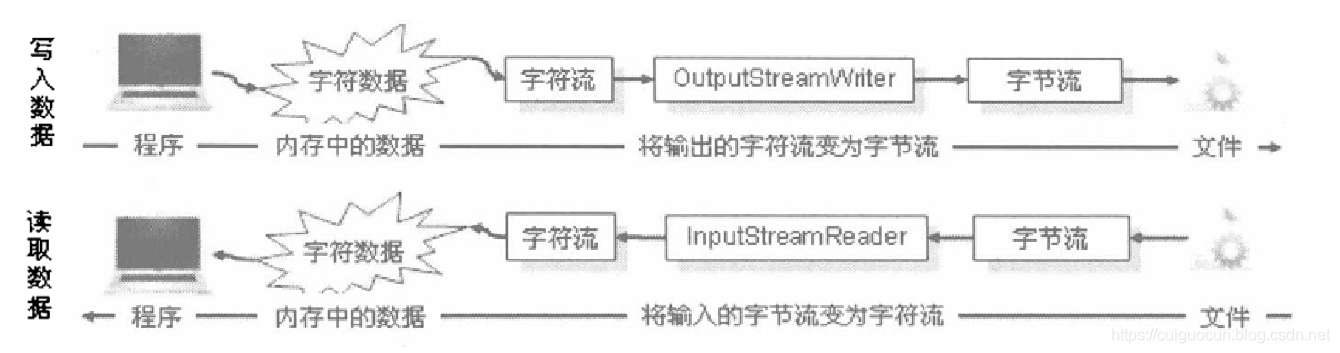
从上图可以清楚的发现,不管如何操作,最终全部是以字节的形式保存在文件中。
OutputStreamWriter的构造方法如下:
public OutputStreamWriter(OutputStream out)
正常我们往文件中写入内容,通过OutputStream写入对吧,但是这种形式只能通过byte字节的形式,
现在我们要通过字符的形式写入,这是就可以通过OutputStreamWriter类了。
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname1="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file1=new File(pathname1);
if(!file1.exists()) {
System.out.println("源文件不存在");
}
Writer out=null;
out=new OutputStreamWriter(new FileOutputStream(file1));
out.write("who are you?");
out.close();
}
}
结果:文件成功存储了who are you?这句话。
同时,我们也可以把这句话读出来,之前我们都是通过InputStream把文件中的数据读到byte字节流数组中,
但是现在我们可以通过InputStreamWriter把字节流转换成字符流读取到字符流char的数组中。
public class Test3{
public static void main(String[] args) throws Exception{
//第一步 使用File类找到一个文件
String pathname1="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file1=new File(pathname1);
if(!file1.exists()) {
System.out.println("源文件不存在");
}
Reader in=null;
in=new InputStreamReader(new FileInputStream(file1));
char c[]=new char[(int) file1.length()];
in.read(c);
in.close();
System.out.println(new String(c));
}
}
结果:
who are you? 已经成功读取出来了。
特殊说明:FileWriter和FileReader分别是InputStreamReader和OutputStreamWriter的直接子类。
内存操作流
前面讲解的程序中都是输出和输入都是从文件中来的,当然也可以将输出的位置设置在内存上,
此时就要使用ByteArrayInputStream、ByteArrayOutputStream来完成输入和输出的功能。
ByteArrayInputStream是将数据读取到内存中
ByteArrayOutputStream是把内存中的数据读取出来


实例:字母大小写转换
public class Test3{
public static void main(String[] args) throws Exception{
String str="ABCDEFG";
ByteArrayInputStream bis=null;
bis=new ByteArrayInputStream(str.getBytes());
ByteArrayOutputStream bos=null;
bos=new ByteArrayOutputStream();
int temp=0;
while((temp=bis.read())!=-1) {
char c=(char) temp;
bos.write(Character.toLowerCase(c));
}
String newStr=bos.toString();
bis.close();
bos.close();
System.out.println(newStr);
}
}
结果:abcdefg
内存操作流一般在生成一些临时的信息才会使用,而这些临时的信息如果要保存在文件中,则代码执行完毕肯定
还要删除这些临时文件,那么此时使用内存操作流是最合适的。
管道流
管道流主要的作用是可以进行两个线程之间,分为管道输出流(PipedOutputStream)和管道输入流(PipedInputStram)。如果要进行管道输出,则必须把输出流连到输入流上。
在PipedOutputStream类上有如下方法进行连接:
public void connect(PipedInputStream snk) throws IOException
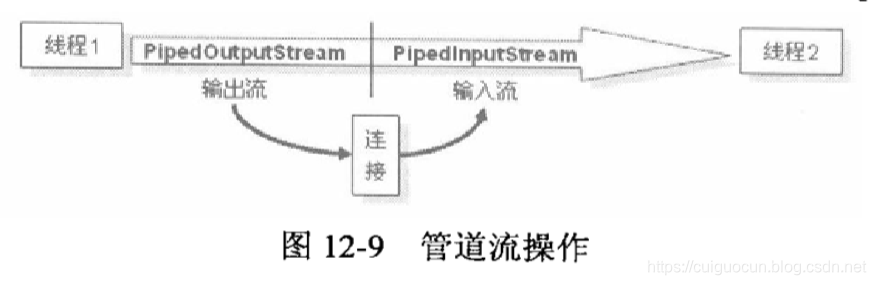
线程之间管道流通信
输出流管道
class Outer implements Runnable{
private PipedOutputStream pos=null;
public Outer() {
this.pos=new PipedOutputStream();
}
@Override
public void run() {
String str="I am String";
try {
this.pos.write(str.getBytes());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
this.pos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public PipedOutputStream getPos() {
return pos;
}
}
输入流管道
class Inter implements Runnable{
private PipedInputStream pis=null;
public Inter() {
pis=new PipedInputStream();
}
@Override
public void run() {
byte b[]=new byte[1024];
int len=0;
try {
len=this.pis.read(b);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
this.pis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(new String(b,0,len));
}
public PipedInputStream getPis() {
return pis;
}
}
执行线程
public class MyTask{
public static void main(String[] args){
Outer out=new Outer();
Inter in=new Inter();
try {
out.getPos().connect(in.getPis());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
new Thread(out).start();
new Thread(in).start();
}
}
结果:
I am String 成功打印
关于输出流
你构建输出流对象时是文件,就会内容输出到指定文件
File file2=new File(pathname2);
out=new FileOutputStream(file2);
while((temp=in.read())!=-1) {
out.write(temp);
}
如果你没构建具体的文件输出对象,而是其他输出对象,那就存储在其他输出对象中
String str=“ABCDEFG”;
ByteArrayInputStream bis=null;
bis=new ByteArrayInputStream(str.getBytes());
ByteArrayOutputStream bos=null;
bos=new ByteArrayOutputStream();
int temp=0;
while((temp=bis.read())!=-1) {
char c=(char) temp;
bos.write(Character.toLowerCase©);
}
String newStr=bos.toString();
bis.close();
bos.close();
System.out.println(newStr);
这时内容就在bos这个对象中(即ByteArrayOutputStream中)
打印流
在整个IO包中,打印流是输入信息最方便的类,主要包含字节打印流(PrintStream)和字符打印流(PrintWriter)。打印流提供了非常方便的打印功能,可以打印任何数据类型,如小数、整数、字符串等。PrintStream是OutputStream的子类。
在PrintStream类中定义的构造方法可以清楚的发现,有一个构造方法可以直接接受OutputStream类的实例。这是因为与OutputStream类相比,PrintStream类更加方便的输出数据,这就好像将OutputStream类重新包装一下,使之输出更加方便。
打印流把输出流重新装饰一下,就像送给别人礼物,需要把礼物包装一下,才会更加好看,所以这样的设计称为装饰设计模式。
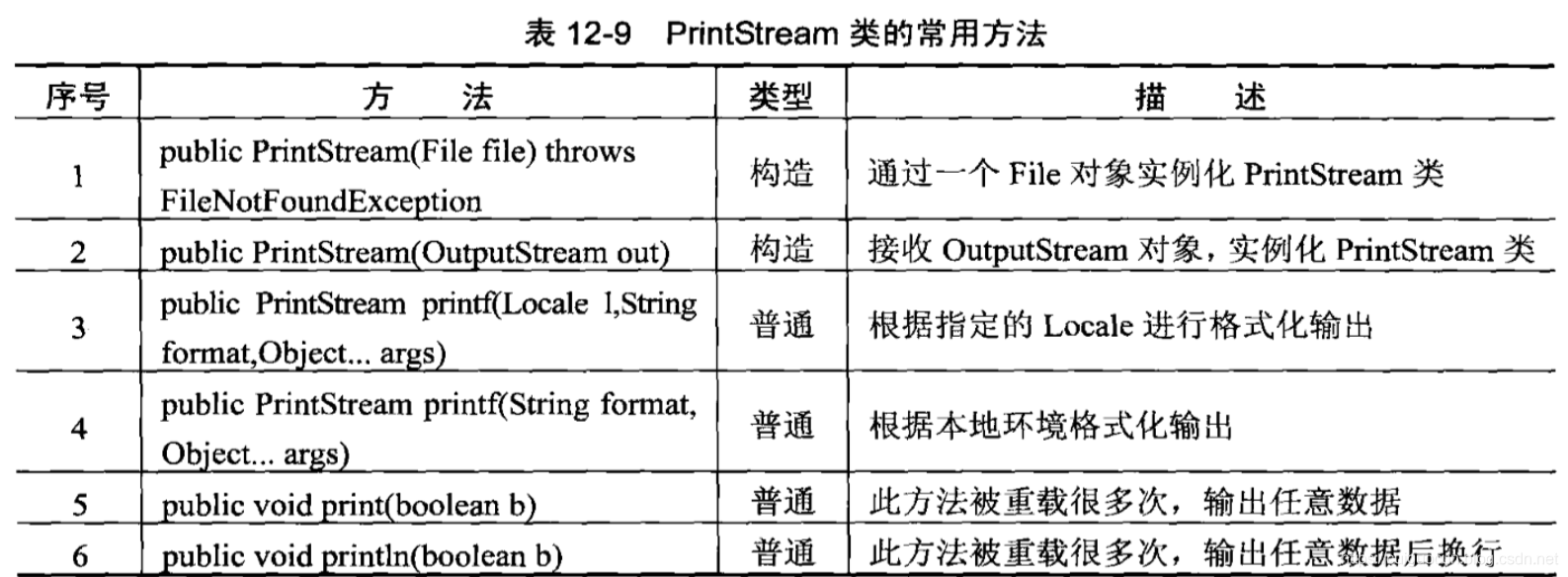
实例:使用PrintStream打印流输出
public class Test3{
public static void main(String[] args) throws FileNotFoundException{
String path="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(path);
PrintStream ps=null;
ps=new PrintStream(new FileOutputStream(file));
ps.print("I ");
ps.print("am ");
ps.print("PrintStream");
ps.close();
}
}
结果:
I am PrintStream 文件中已成功打印出这个字符串
使用打印流进行格式化输出

格式化打印
public class Test3{
public static void main(String[] args) throws FileNotFoundException{
String path="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(path);
PrintStream ps=null;
ps=new PrintStream(new FileOutputStream(file));
String name="CuiXianSheng";
int age=10;
float score=99.99f;
char sex='M';
ps.printf("姓名:%s; 年龄:%d; 成绩:%f; 性别:%c",name,age,score,sex);
ps.close();
}
}
结果:
姓名:CuiXianSheng; 年龄:10; 成绩:99.989998; 性别:M
成功打印到文件中(注意使用printf方法格式化打印,还有%在左边。)
System类对IO的支持
System类有三个主要的方法
System.out
System.err
System.in
System.out和System.err都是PrintStream的实例化对象,两者都是输出错误信息,而System.out是将信息显示给用户看,是正常的显示信息。而System.err的信息恰好相反,是不希望用户看到的,会直接在后台打印,是专门显示错误的。
System.in实际上是一个键盘输入流,可以从键盘上读取数据。
System为这三个提供了重定向的方法
就是可以改变输出的位置或者改变输入的位置
具体使用如下:
注意的是不要随便修改System.err重定向的位置,因为它表示输出的数据不希望用户看到。

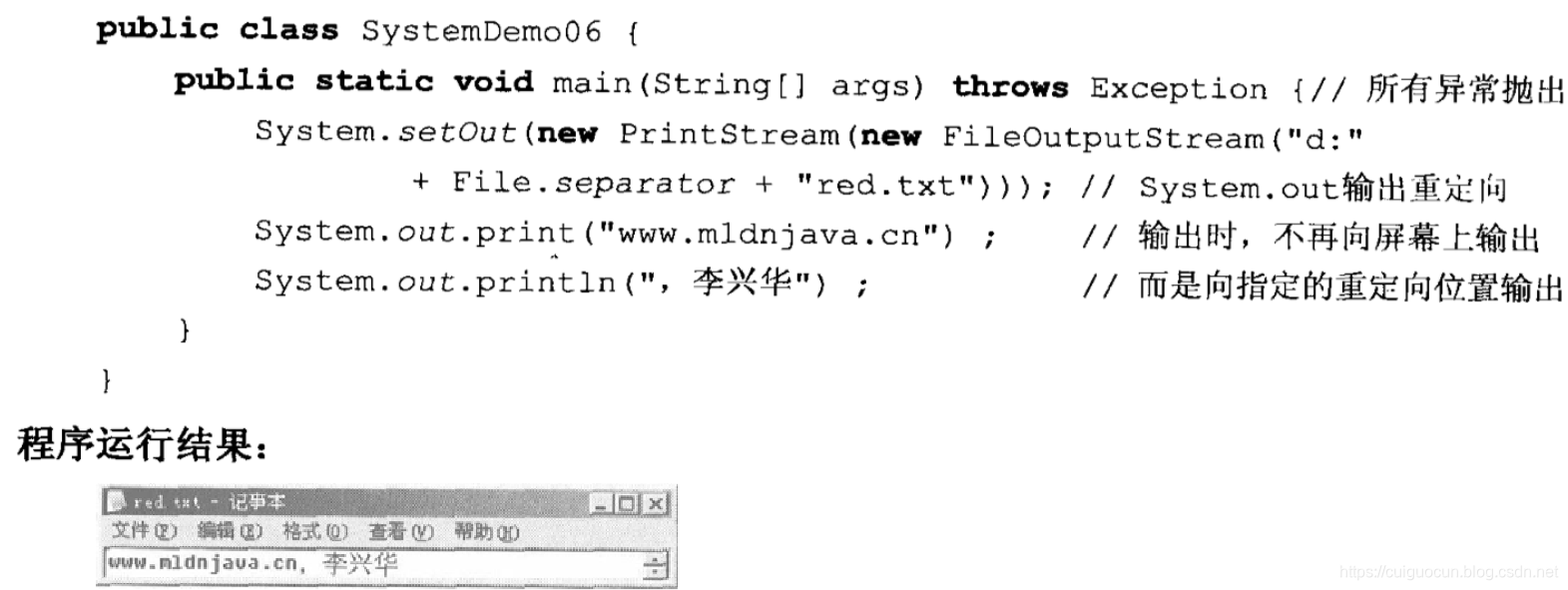
BufferedReader类
BufferedReader类用于从缓冲区中读取内容,所有的输入字节数据都将放到缓冲区中
从以上定义可以看出来,构造方法中只能接收字符输入流的实例,所以必须使用字符输入流Reader和字节输入流的转换类InputStreamReader,将字节输入流System.in变为字符流。

public class Test3{
public static void main(String[] args){
BufferedReader br=null;
br=new BufferedReader(new InputStreamReader(System.in));
String str=null;
System.out.println("请输入你想输入的内容:");
try {
str=br.readLine();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("您输入的内容是:"+str);
}
}
结果:
请输入你想输入的内容:
随便输入的 哈哈哈
您输入的内容是:随便输入的 哈哈哈
可以发现程序没有长度限制,也可以正常接收中文。
数据操作流
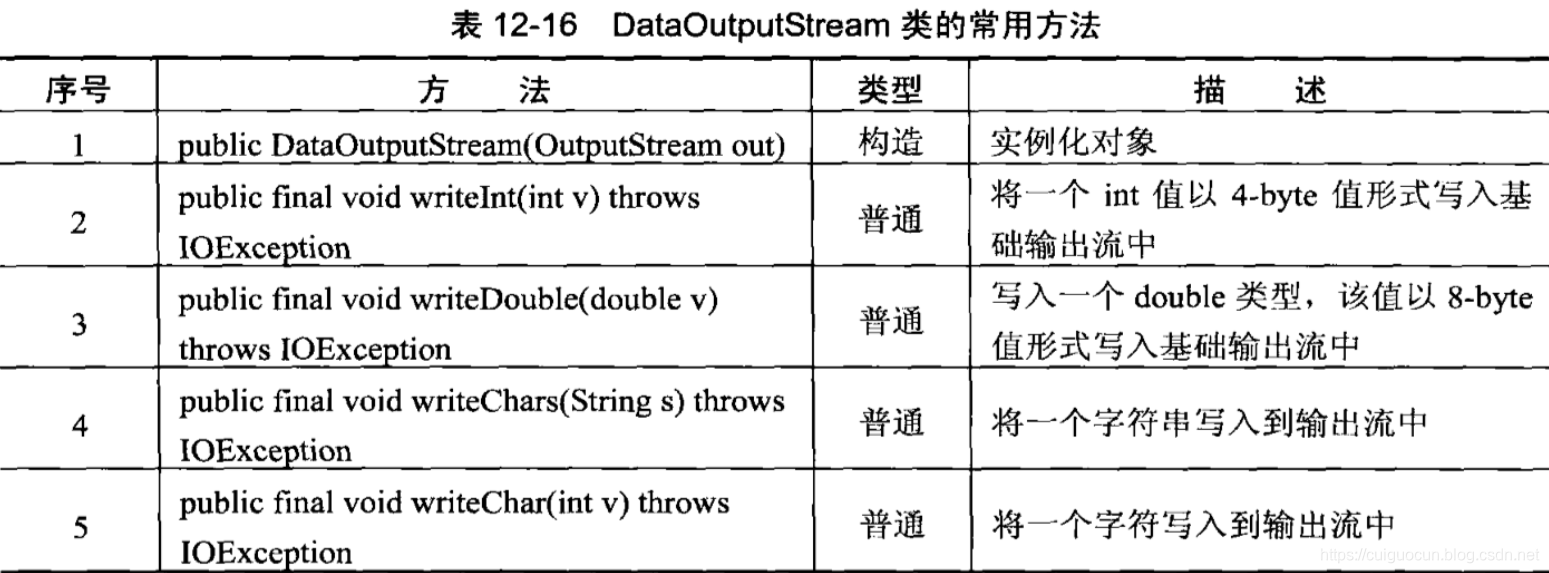
在IO包中,提供了两个与平台无关的数据操作流,分别是数据输出流DataOutputStream和数据输入流DataInputStream,通常数据输出流会按照一定的格式将数据输出,在通过数据输入流按照一定的格式将数据读入,这样可以方便对数据进行处理。
DataOutputStream是OutputStream的子类
public class DataOutputStream extends FilterOutputStream implements DataOutput
DataOutput是数据的输出接口,其中定义了各种数据的输出操作方法。例如在DataOutputStream类中的
各种WriterXxx()方法就是此接口的定义,但在数据输出时,一般都会直接使用DataOutputStream,只有在
对象序列化时才有可能直接操作DataOutput接口。

使用DataOutputStream输出这个订单到指定文件
public class Test3{
public static void main(String[] args) throws Exception{
String path="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(path);
DataOutputStream dos=null;
dos=new DataOutputStream(new FileOutputStream(file));
String names[]= {"衬衣","手套","围巾"};
float price[]= {98.3f,30.3f,50.5f};
int nums[]= {3,2,1};
for(int i=0;i<names.length;i++) {
dos.writeChars(names[i]);
dos.writeChar('\t');
dos.writeFloat(price[i]);
dos.writeChar('\t');
dos.writeInt(nums[i]);
dos.writeChar('\n');
}
dos.close();
}
}
DataOutputStream提供了将Java各种类型数据的输出方法,但是其将各种数据类型以二进制形式输出,
用户无法方便的进行查看。使用PrintWriter类的print()和PrintLn()方法可以轻松地实现将
Java的各种数据类型转换为字符串类型输出。
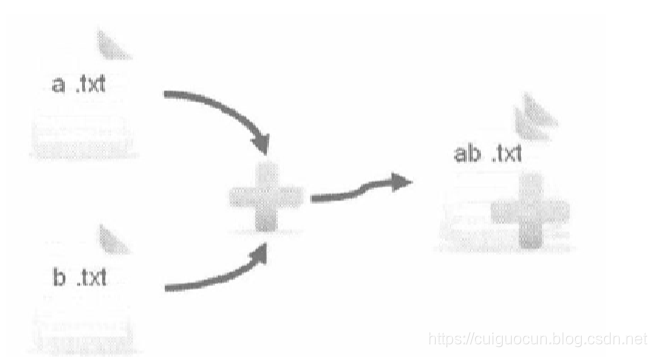
合并流SequenceInputStream
合并流的主要功能是将两个文件的内容合并成一个文件

public class Test3{
public static void main(String[] args) throws Exception{
String path1="d:"+File.separator+"testDir"+File.separator+"cui.txt";
String path2="d:"+File.separator+"testDir"+File.separator+"xian.txt";
String path3="d:"+File.separator+"testDir"+File.separator+"sheng.txt";
File file1=new File(path1);
File file2=new File(path2);
File file3=new File(path3);
InputStream in1=null;
InputStream in2=null;
SequenceInputStream in3=null;
OutputStream out=null;
in1=new FileInputStream(file1);
in2=new FileInputStream(file2);
in3=new SequenceInputStream(in1,in2);
out=new FileOutputStream(file3);
int temp=0;
while((temp=in3.read())!=-1) {
out.write(temp);
}
in3.close();
in1.close();
in2.close();
out.close();
}
}
结果:
I am firstI am second 成功cui.txt和xian.txt的内容写入到sheng.txt中
压缩流
在javaIO中,不仅可以实现ZIP压缩格式的输入、输出,也可以实现JAR以及GZIP文件的格式压缩
JAR的压缩支持类保存在java.util.jar包中,常用类有如下几个:
JAR压缩输出流:JarOutputStream
JAR压缩输入流:JarInputStream
JAR文件:JARFile
JAR实体:JAREntry
ZIP的压缩支持类保存在java.util.zip包中,常用类有如下几个:
ZIP压缩输出流:ZipOutputStream
ZIP压缩输入流:ZipInputStream
ZIP文件:ZIPFile
ZIP实体:ZIPEntry
GZIP是用于UNIX系统的文件压缩,在Linux经常会使用到*.gz文件,就是GZIP文件的格式。
GZIP压缩输出流:GZIPOutputStream
GZIP压缩输入流:GZIPInputStream
在每个压缩文件中都会存在多个子文件,那么每个子文件在java中就使用ZIPEntry表示。
要完成一个文件或者文件夹的压缩,则要使用ZipOutputStream。ZipOutputStream是OutputStream的子类。


把cui.txt压缩成cui.zip
public class Test3{
public static void main(String[] args) throws Exception{
String path1="d:"+File.separator+"testDir"+File.separator+"cui.txt";
String path2="d:"+File.separator+"testDir"+File.separator+"cui.zip";
File file=new File(path1);
File fileZip=new File(path2);
InputStream in=null;
in=new FileInputStream(file);
ZipOutputStream zos=null;
//实例化压缩输出流对象,并指定压缩文件输出路径
zos=new ZipOutputStream(new FileOutputStream(fileZip));
//每一个被压缩的文件都用ZipEntry表示,需要为每一个压缩后的文件设置名称
zos.putNextEntry(new ZipEntry(file.getName()));
zos.setComment("I am Comment!");
int temp=0;
while((temp=in.read())!=-1) {
zos.write(temp);
}
zos.close();
in.close();
}
}
结果:已成功压缩到指定目录,并压缩成cui.zip文件
压缩一个文件夹:
应该列出文件夹的全部文件,把每一个文件内容设置成ZipEntry对象,保存在压缩文件中。
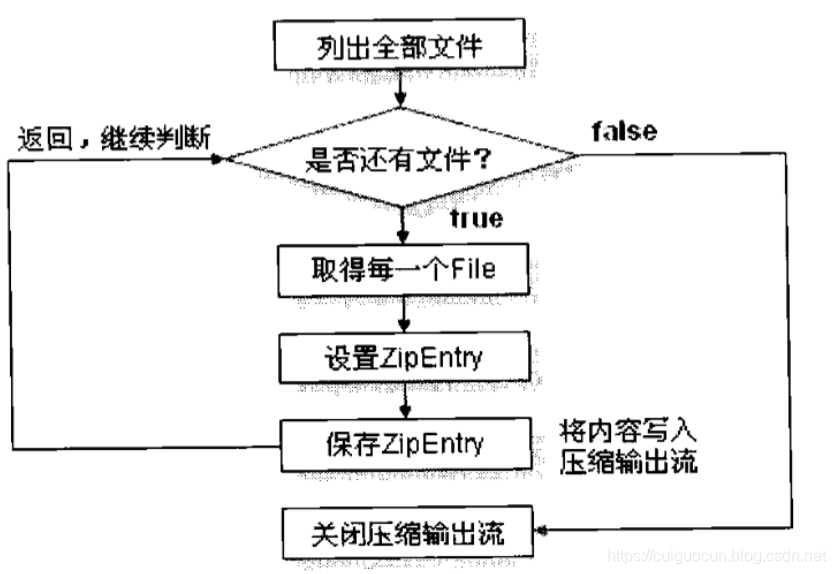
压缩一个文件夹
public class Test3{
public static void main(String[] args) throws Exception{
String path1="d:"+File.separator+"testDir"+File.separator+"dir";
String path2="d:"+File.separator+"testDir"+File.separator+"dir.zip";
File file=new File(path1);
File fileZip=new File(path2);
InputStream in=null;
ZipOutputStream zos=null;
//实例化压缩输出流对象,并指定压缩文件输出路径
zos=new ZipOutputStream(new FileOutputStream(fileZip));
if(file.isDirectory()) {
File files[]=file.listFiles();
for(int i=0;i<files.length;i++) {
in=new FileInputStream(files[i]);
zos.putNextEntry(new ZipEntry(files[i].getName()));
int temp=0;
while((temp=in.read())!=-1) {
zos.write(temp);
}
in.close();
}
}
zos.close();
}
}
ZipFile
在java中每一个压缩文件都可以用ZipFile表示,还可以使用ZipFile根据压缩后的文件名称找到每一个压缩文件中的ZipEntry,并将其进行解压缩的操作。
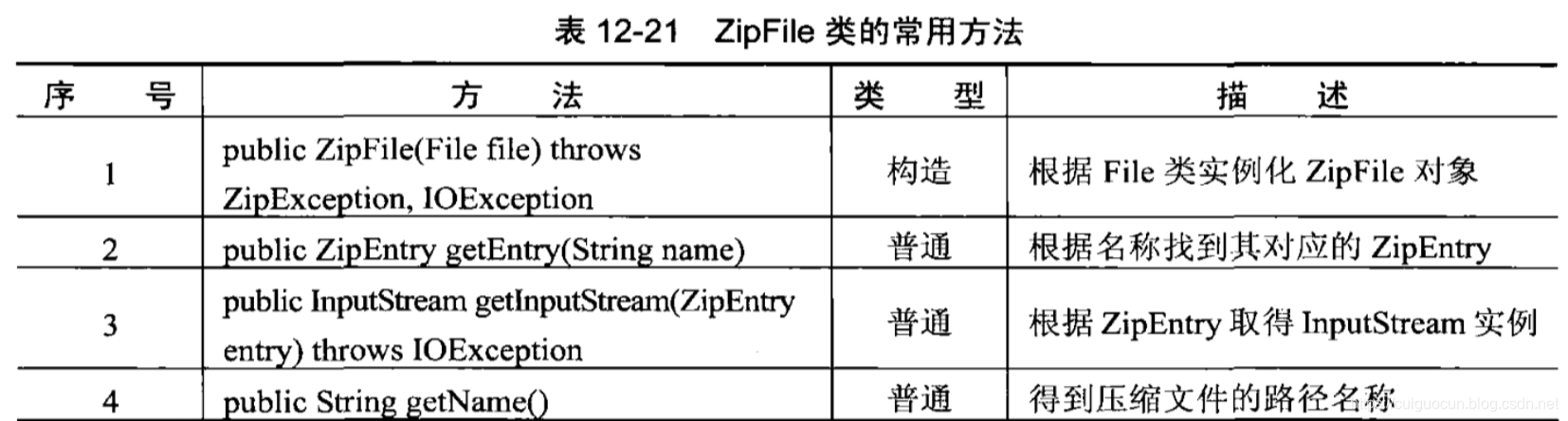
基本使用:
public class Test3{
public static void main(String[] args) throws Exception{
String path1="d:"+File.separator+"testDir"+File.separator+"cui.zip";
File file=new File(path1);
ZipFile zf=new ZipFile(file);
System.out.print("压缩文件的名称为:"+zf.getName());
}
}
结果:
压缩文件的名称为:d:\testDir\cui.zip
单文件解压缩:
public class Test3{
public static void main(String[] args) throws Exception{
String path1="d:"+File.separator+"testDir"+File.separator+"cui.zip";
String path2="d:"+File.separator+"testDir"+File.separator+"cuiUNzip.txt";
File file=new File(path1);
//定义解压缩文件名称
File fileUnzip=new File(path2);
ZipFile zf=new ZipFile(file);
ZipEntry ze=zf.getEntry("cui.txt");
InputStream in=zf.getInputStream(ze);
OutputStream out=new FileOutputStream(fileUnzip);
int temp=0;
while((temp=in.read())!=-1) {
out.write(temp);
}
in.close();
out.close();
}
}
结果:文件已成功解压到cuiUNzip.txt文本文件中。
多文件解压缩:
通过ZipInputStream类中的getNextEntry()方法可以依次取得每一个ZipEntry,那么将此类与ZipFile
结合就可以对压缩文件夹进行解压缩操作。应该先根据ZIP对应的文件名对应的文件夹在硬盘上创建好,
然后才能把文件解压缩进去。而且在操作时对于每一个解压缩的文件都必须先创建(File类的createNewFile
方法可以创建新文件)后再将内容输出。
public class Test3{
public static void main(String[] args) throws Exception{
String path1="d:"+File.separator+"testDir"+File.separator+"dir.zip";
File file=new File(path1);
//定义输出文件对象
File fileUnzip=null;
ZipFile zf=new ZipFile(file);//实例化ZupFile对象
//实例化Zip输入流
ZipInputStream zis=new ZipInputStream(new FileInputStream(file));
ZipEntry ze=null;//定义ZipEntry对象,用来接收压缩文件中的每一个实体
InputStream in=null;//定义输入流,用于读取每一个ZipEntry
OutputStream out=null;//定义输出流,用于输出每一个实体内容。
//得到每一个ZipEntry
while((ze=zis.getNextEntry())!=null) {
System.out.println("解压缩"+ze.getName()+"文件");
fileUnzip=new File("d:"+File.separator+"testDir"+File.separator+"dir"
+File.separator+ze.getName());
if(!fileUnzip.getParentFile().exists()) {
fileUnzip.getParentFile().mkdir();
}
if(!fileUnzip.exists()) {
fileUnzip.createNewFile();
}
in=zf.getInputStream(ze);
out=new FileOutputStream(fileUnzip);
int temp=0;
while((temp=in.read())!=-1) {
out.write(temp);
}
in.close();
out.close();
}
}
}
结果:
解压缩cui1.txt文件
解压缩sheng1.txt文件
解压缩xian1.txt文件
都已经成功解压到指定目录下。
回退流
在java的IO中所有的数据都是采用顺序的读取方式,即对于一个输入流来说,都是采用从头到尾的顺序读取,如果在输入流中的某个不需要的内容被读取进来,则只能通过程序将这些不需要的内容处理掉。为了解决这样的读取问题,在java中提供了一种回退输入流(PushbackInputStream,PushbackReader),可以把读取进来的某些数据重新退回到输入流的缓冲区中。
对于不需要的数据可以使用unread()方法,将内容重新发送到输入的缓冲区中。
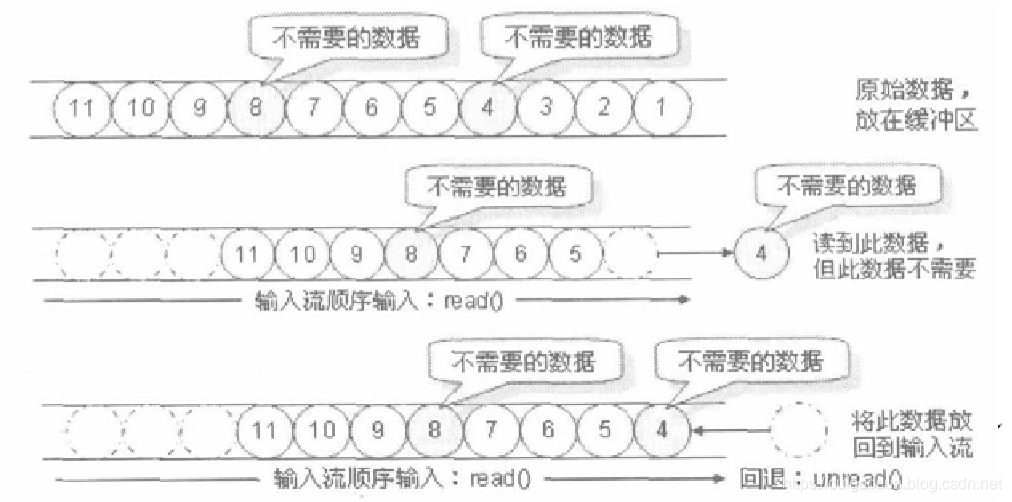
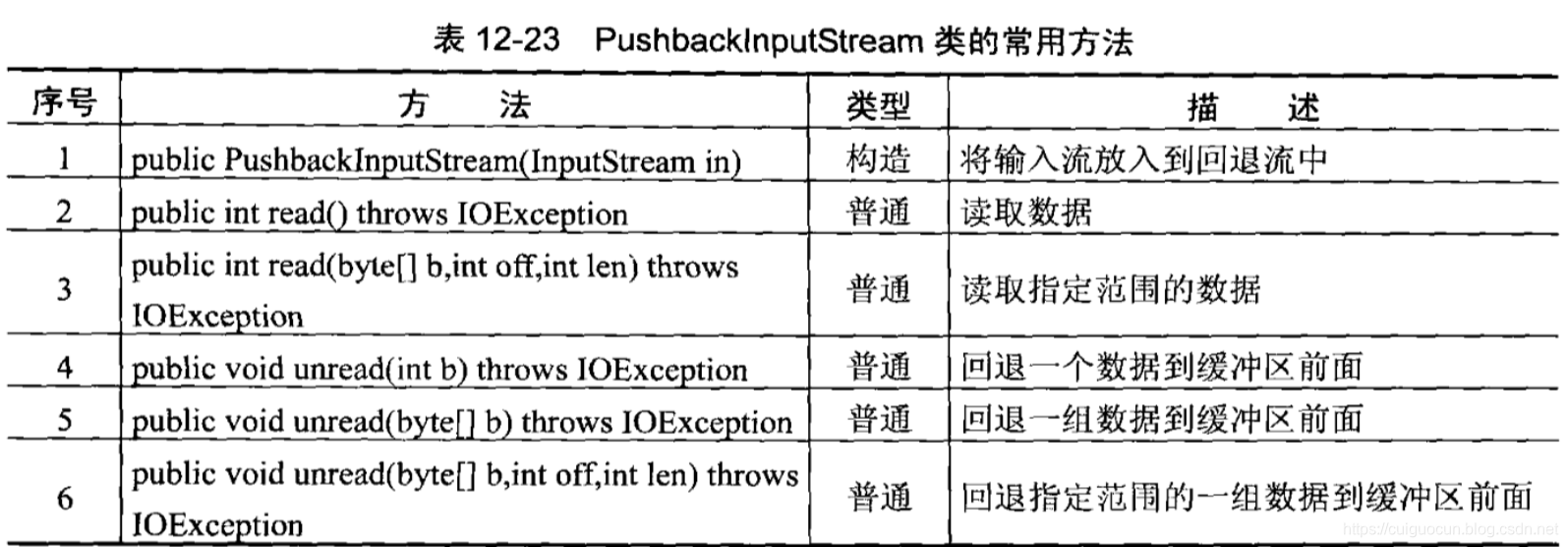

示例:
public class Test3{
public static void main(String[] args) throws Exception{
String str="www.baidu.com!!!";
PushbackInputStream pis=null;
ByteArrayInputStream bis=null;
bis=new ByteArrayInputStream(str.getBytes());
pis=new PushbackInputStream(bis);
System.out.println("开始读取数据");
int temp=0;
while((temp=pis.read())!=-1) {
if(temp=='.') {
pis.unread(temp);
temp=pis.read();
System.out.print("*");
}else {
System.out.print((char)temp);
}
}
}
}
结果:
开始读取数据
www*baidu*com!!!
System.out.print((char)temp);这里不加char转换成字符会以ASCII显示字符
结果会是119119119*9897105100117*99111109333333
而119对应的ascii表就是W
字符编码
java常见编码简介:
在计算机世界里,任何的文字都是以指定文字编码的方式存在的,在java程序开发中最常见的是:
ISO8859-1,GBK/GB2312,unicode,UTF编码
ISO8859-1:属于单字节编码,最多只能表示0~255字符的范围,主要在英文上使用
GBK/GB2312:中文的国标编码,专门用来表示汉字,是双字节编码,如果在此编码出现中文,则使用GBK编码或者GB2312。GBK可以表示简体中文和繁体中文,GB2312只能表示简体中文。GBK兼容GB2312
unicode:java中使用此编码方式,是最标准的一种编码,使用十六进制表示编码。但此编码不兼容ISO8859-1编码
UTF:由于unicode不支持ISO8859-1编码,而且容易占用更多空间,而且对于英文字母也需要使用两个字节编码,这样使用unicode不便于传输和存储。因此产生了UTF编码。UTF编码兼容了ISO8859-1编码,同时也可以用来表示所有的语音字符,不过UTF编码是不定长编码,每一个字符长度为1~6个字符不等,一般在中文网页使用此编码,可以节省空间。
得到本机的编码显示:
public class Test3{
public static void main(String[] args) throws Exception{
System.out.print(System.getProperty("file.encoding"));
}
}
结果:UTF-8
对象序列化
对象序列化就是把一个对象变为二进制数据流的一种方法,通过对象序列化可以方便的实现对象的传输和存储。
如果一个类的对象想被序列化,则对象所在类必须java.io.Serializable接口。
public interface Serializable{}
可以发现此接口没有定义任何方法,所以此接口是一个标识接口,标识一个类具备了被序列化的能力。
public class Person {
private String name;
private int age;
public Person(String name,int age) {
this.name=name;
this.age=age;
}
public String toString() {
return "姓名:"+this.name+";"+"年龄:"+this.age;
}
}
以上Person类已经实现了序列化接口,所以此类的对象是可以经过二进制数据流 进行传输的。而如果要完成对
象的输入或者输出,还要依靠对象的输出流(ObjectOuputStream)和对象的输入流(ObjectInputStream)
使用ObjectOutputStream对象输出流称为序列化,使用ObjectInputStream对象输入流称为反序列化
对象的序列化和反序列化兼容问题:
在对象进行序列化和反序列化操作时,要考虑JDK版本问题,如果序列化的JDK版本和反序列化的JDK版本不统一则就有可能造成异常,所以在序列化操作中引入一个serialVersionUID的常量,可以通过此常量来验证版本的一致性。
在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应的实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。当实现java.io.Serializable接口的实体类没有显式的定义一个名为serialVersionUID、类型为long的变量时,java序列化机制在编译时会自动生成一个此版本的serialVersionUID。当然,如果不希望通过编译生成,也可以直接显式的定义一个名为serialVersionUID类型为long的变量,只要不修改这个变量值的序列化实体,都可以互相进行串行化和反串行化。
public static final long serialVersionUID=1L;
*****ObjectOutputStream***** 对象输出流
实例:将对象数据保存到文件
public class Test3{
public static void main(String[] args) throws Exception{
String path="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(path);
ObjectOutputStream oos=null;
OutputStream out=new FileOutputStream(file);
oos=new ObjectOutputStream(out);
oos.writeObject(new Person("cui", 18));
oos.close();
}
}
结果:
sr
myTest.Person I ageL namet Ljava/lang/String;xp t cui
文件里面是乱的。因为这里保存的都是二进制数据,所以我们不能随意修改会破坏保存格式。
序列化都那些进行了序列化?
在面向对象上,每个对象都具备相同的方法,但是每个对象的属性不一定相同,也就是说对象保存的只有属性信息,那么在序列化操作时,也同样是这个道理,只有属性被序列化。
*****ObjectInputStream***** 对象输入流
实例:读出保存在文件中的对象信息。
public class Test3{
public static void main(String[] args) throws Exception{
String path="d:"+File.separator+"testDir"+File.separator+"cui.txt";
File file=new File(path);
ObjectInputStream ois=null;
InputStream in=null;
in=new FileInputStream(file);
ois=new ObjectInputStream(in);
Object objec=ois.readObject();
ois.close();
System.out.print(objec);
}
}
结果:
姓名:cui;年龄:18
另一种实例化对象方法,是部分实例化,Serializable是全部实例化。
Externalizable是部分实例化。
实现过程和Serializable一样,只不过多了两个覆写的方法(前面也是实体类实现Externalizable接口,之后在实体类中指定实例化的具体参数)
public class Person implements Externalizable{
public static final long serialVersionUID=1L;
private String name;
private int age;
public Person(String name,int age) {
this.name=name;
this.age=age;
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(this.name);//保存姓名属性
out.writeObject(this.age);//保存年龄属性
}
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
this.name=(String) in.readObject();//读取姓名属性
this.age=in.readInt();//读取年龄属性
}
public String toString() {
return "姓名:"+this.name+";"+"年龄:"+this.age;
}
}
使用使用依然使用对象的输入输出流(ObjectInputStream和ObjectOutputStream),使用方法不变。
只是实体类有变化,变化如上所示。

从实际情况来看,因为Serializable接口使用方便,所以出现较多。
transient关键字
Serializable接口实际上是将对象中的全部属性进行序列化。但是使用transient关键字就可以指定某个属性不被序列化。
private transient String name;
这样name这个属性就不会被序列化。放入文件中,取值会是空值。因为根本没有实例化到文件里面。
本章要点
2.在java中使用File类表示文件本身,可以直接使用此类完成文件的各种操作,如创建删除等。
3.RandomAccessFile类可以从指定的位置开始读取信息,但是要求文件中的各个数据的保存长度必须固定。
4.输入输出流主要分为字节流和字符流两种,但在传输过程中字节流操作较多,字符流在操作时使用了缓冲区,而字节流没有使用缓冲区。
5.字节流和字符流都是以抽象类的形式定义的,根据其使用的子类不同输入或输出的位置也不同。
6.在IO包中可以使用OutputStreamWriter和InputStreamReader完成字符流与字节流之间的转换操作。
7.使用ByteArrayInputStream和ByteOutputStream类可以对内存进行输入输出操作。
8.在线程之间进行输入输出通信,主要使用PipedInputStream和PipedOutputStream
9.在IO输出时最好使用打印流(PrintStream,PrintWriter),这样可以方便的输出各种类型数据
10.BuffereReader可以直接从缓冲去读取数据。
11.数据操作流(DataOuputStream/DataInputStream),提供了与平台无关的数据操作。
12.使用合并流(SequenceIputStream),可以将两个文件内容进行合并。
13.如果数据量过大,则可以使用压缩流压缩数据,在java中支持ZIP、JAR、GZIP共3中压缩格式。
14.使用回退流可以将不需要的数据回退到数据缓冲区中以待重新读取。
15.造成字符乱码的根本原因就是在于程序编码与本地编码不一致。
16.对象序列化可以将内存中的数据转化为二进制数据,但对象所在的类必须事先Serializable接口,一个类的属性如果使用transient关键字声明,则此属性内容将不会被序列化。
17.对象的输入输出主要使用ObjectInputStream和ObjectOutputStream两个类完成。














 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









