






最近没有研究什么,先整理整理以前的故障分析报告吧!
主要是关于一个latch: ges resource hash list和library cache: mutex X并发的故障。
1. 分析主机负载情况
根据监控所看当时故障期间主要是 CPU 耗尽,因此查询当时 CPU 相关日志:
| VMSTAT: zzz ***Mon Mar 5 08:36:18 CST 2018 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 149 3 124 9812752 1198728 35568716 0 0 1298 589 44966 29616 88 12 0 0 0 135 4 124 9798624 1198728 35568716 0 0 1281 251 40886 27238 88 11 0 0 0 zzz ***Mon Mar 5 08:37:07 CST 2018 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 189 2 124 9781452 1198728 35569696 0 0 1185 215 38132 25382 86 14 0 0 0 176 5 124 9779200 1198728 35569696 0 0 1363 314 40060 29394 87 13 0 0 0 zzz ***Mon Mar 5 08:37:57 CST 2018 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 149 4 124 9793104 1198728 35570700 0 0 1417 58 40571 26809 87 13 0 0 0 176 8 124 9808340 1198728 35570928 0 0 1161 620 41007 27465 89 11 0 0 0 |
| MPSTAT: zzz ***Mon Mar 5 08:39:39 CST 2018 Linux 2.6.32-573.el6.x86_64 (yyxxdb04) 03/05/18 _x86_64_ (16 CPU)
08:39:40 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 《《《idle 0 08:39:41 all 90.26 0.00 7.93 0.00 0.00 1.81 0.00 0.00 0.00 08:39:41 0 95.00 0.00 5.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 1 89.11 0.00 7.92 0.00 0.00 2.97 0.00 0.00 0.00 08:39:41 2 94.95 0.00 5.05 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 3 81.82 0.00 4.04 0.00 0.00 14.14 0.00 0.00 0.00 08:39:41 4 86.00 0.00 6.00 0.00 0.00 8.00 0.00 0.00 0.00 08:39:41 5 90.00 0.00 7.00 0.00 0.00 3.00 0.00 0.00 0.00 08:39:41 6 95.00 0.00 5.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 7 95.00 0.00 5.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 8 91.00 0.00 8.00 0.00 0.00 1.00 0.00 0.00 0.00 08:39:41 9 81.00 0.00 19.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 10 93.00 0.00 7.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 11 92.08 0.00 7.92 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 12 93.00 0.00 7.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 13 86.87 0.00 13.13 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 14 93.00 0.00 7.00 0.00 0.00 0.00 0.00 0.00 0.00 08:39:41 15 91.00 0.00 9.00 0.00 0.00 0.00 0.00 0.00 0.00 |
| TOP: top - 08:36:31 up 174 days, 7:56, 0 users, load average: 150.94, 137.53, 87.6 Tasks: 853 total, 137 running, 716 sleeping, 0 stopped, 0 zombie < <<< 总共853任务,137在运行 Cpu(s): 88.0%us, 9.9%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 2.1%si, 0.0%st 平时20个左右 Mem: 132100752k total, 122298040k used, 9802712k free, 1198728k buffers Swap: 16777212k total, 124k used, 16777088k free, 35569088k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 31954 oracle -2 0 73.6g 117m 17m S 30.3 0.1 12178:43 oracle 》》》主要是数据库的进程 12929 root RT -5 887m 157m 63m S 28.2 0.1 2105:54 ologgerd 31958 oracle -2 0 73.6g 116m 17m S 22.3 0.1 11724:28 oracle 27695 root 20 0 3680m 301m 8368 S 13.5 0.2 1284:44 java 12531 root RT 0 836m 105m 57m S 11.4 0.1 4949:42 osysmond.bin 》》》》 资源监控 ,11g新特性 8329 oracle 20 0 73.5g 26m 21m R 10.1 0.0 0:15.21 oracle 10577 oracle 20 0 73.5g 26m 21m R 9.3 0.0 0:08.15 oracle 9140 oracle 20 0 73.5g 26m 21m R 8.8 0.0 0:15.62 oracle |
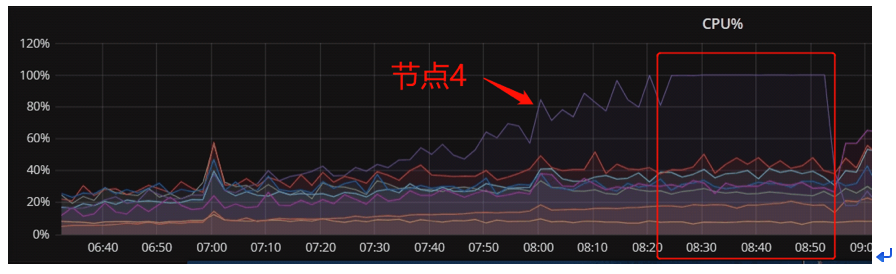
从以上可以看出,从7:00节点4 CPU使用率开始上升,这是正常业务量增多引起,而从8:20之后CPU使用率开始达到100%,说明此时故障已经出现或者恶化。故障期间主机RunQ非常高(正常情况下是在20以下),而当时主机所有CPU idle 都为0 ,所有CPU都被耗尽,其中iowait并不高,内存使用率稳定,说明当时主机主要是CPU非常繁忙。
2. 分析节点 4 数据库等待情况
查看 8 点 -9 点 AWR 报告情况如下:

可以看到,在8点-9点期间,数据库主要等待事件是latch: ges resource hash list和library cache: mutex X,并且DB CPU 排在第三位,说明数据库对CPU的请求量非常高。
以下查看具体时间的ASH情况:
| SAMPLE_ID SAMPLE_TIME INST_ID EVENT COUNT ---------- ----------------------- ----- ------------------------------- ------------------ 45357646 05-MAR-18 08.09.49.998 AM 4 12 45357656 05-MAR-18 08.10.00.118 AM 4 latch: ges resource hash list 1 45357656 05-MAR-18 08.10.00.118 AM 4 enq: IV - contention 1 45357656 05-MAR-18 08.10.00.118 AM 4 os thread startup 1 45357656 05-MAR-18 08.10.00.118 AM 4 db file sequential read 2 45357656 05-MAR-18 08.10.00.118 AM 4 library cache: mutex X 2 <<<<<< 45357656 05-MAR-18 08.10.00.118 AM 4 14 45357666 05-MAR-18 08.10.11.048 AM 4 gc current block 2-way 1 45357666 05-MAR-18 08.10.11.048 AM 4 cursor: pin S 1 45357666 05-MAR-18 08.10.11.048 AM 4 log file sync 1 45357666 05-MAR-18 08.10.11.048 AM 4 DFS lock handle 2 45357666 05-MAR-18 08.10.11.048 AM 4 db file sequential read 3 45357666 05-MAR-18 08.10.11.048 AM 4 rdbms ipc reply 6 45357666 05-MAR-18 08.10.11.048 AM 4 library cache: mutex X 12 <<<<<< library cache: mutex X 45357666 05-MAR-18 08.10.11.048 AM 4 38 开始明显增多 ……… 45358726 05-MAR-18 08.29.37.812 AM 4 latch free 3 45358726 05-MAR-18 08.29.37.812 AM 4 cursor: pin S 6 45358726 05-MAR-18 08.29.37.812 AM 4 db file sequential read 9 45358726 05-MAR-18 08.29.37.812 AM 4 library cache: mutex X 22 <<<<< < 持续增多 45358726 05-MAR-18 08.29.37.812 AM 4 52 45358736 05-MAR-18 08.29.48.846 AM 4 gc cr grant 2-way 1 45358736 05-MAR-18 08.29.48.846 AM 4 cursor: pin S 1 45358736 05-MAR-18 08.29.48.846 AM 4 latch: gc element 1 45358736 05-MAR-18 08.29.48.846 AM 4 latch free 1 45358736 05-MAR-18 08.29.48.846 AM 4 db file sequential read 3 45358736 05-MAR-18 08.29.48.846 AM 4 library cache: mutex X 14 45358736 05-MAR-18 08.29.48.846 AM 4 latch: ges resource hash list 30 <<<< latch: ges resource hash list 45358736 05-MAR-18 08.29.48.846 AM 4 70 明显增多,此时cpu idle 0 |
从以上可以看出,从8点10分开始出现library cache: mutex X 增多情况,在8点30分之后CPU 耗尽期间是数据库堆积比较严重。之后latch: ges resource hash list也逐渐增多,对照以上主机资源分析,此时CPU已经耗尽。
关于 latch: ges resource hash list 和 library cache: mutex X 解析:
首先解释library cache: mutex X , Library cache 是 shared pool 中的一块内存区域,主要作用就是缓存执行过的 SQL 语句所对应的执行计划信息等信息。
当同样的 SQL 再次执行时候可以直接利用已经缓存的相关对象不需要再从头进行解析, 所有已经编译过的library cache object会被组织在一个hash结构中,进行搜索时, Oracle会对SQL语句进行hash计算,根据结果找到相应的hash bucket,然后再搜索链接在这个bucket上的所有handle如果这个handle 正好是要找的SQL,则会向内搜索这个handle包含的child,寻找可用的cursor。
如果有完全符合条件的可用child则重用,完成软解析,如果没有,则创建一个新的child,完成一次硬解析。
在这个过程中oracle 设置了锁来防止重复添加handle或child。library cache: mutex X 是11G以后用来保护每个bucket和每个handle的小粒度的latch锁,SQL在解析时,library cache会产生mutex的争用。
Library cache: mutex 等待事件产生常见原因:
l os 资源不足 (cpu 、内存 )
l sga 设置不合理, shared_pool 不足,或动态调整导致 hard parse
l 热对象,通常伴随着高 CPU
l hard parse
l sql high version count 由于子游标太多,扫描时会形成锁
l library cache object 失效导致重编译
l bug
进而解释latch: ges resource hash list ,这个等待是RAC中的一个latch,GES 是全局队列服务的意思,在一个RAC数据库中,GES 是对实例间资源协调负责的,GES 负责所有的非 cache fusion 实例间资源操作,包括控制数据库中所有的 library cache锁和dictionary cache锁。这些资源在单实例数据库中是本地性的,但是到了RAC群集中变成了全局资源。全局锁也被用来保护数据的结构,进行事务的管理。 ges resource hash list’ 是 这 些 资 源的 hash list , 访问创 建全局 锁 (global enqueue) 资源,都需要先访问这个 hash list 。
本次故障中伴随出现大量latch: ges resource hash list也是与library cahce 有关全局队列等待,其归根结底与library cache: mutex X相关,另据oracle 官方博客《关于RunQ过高引起的latch等待问题》( https://blogs.oracle.com/database4cn/runqlatch ) 也描述了在高CPU 负载情况下极易触发该等待事件。本次故障发生时,正是当随着CPU逐渐升高时便产生了该等待事件。
从以上可以看出,在出现故障期间主要出现了大量latch: ges resource hash list和library cache: mutex X,这两种等待同时出现说明了主要是对library cahce 争用造成的阻塞。而这两个等待事件产生的过程是一个锁等待的过程,其都会加剧CPU的消耗。
3. 分析产生异常等待的原因

在以上top event中,可以看到library cache: mutex X等待的次数在一个小时内高达270多万次,而引起大部分等待的语句则是这两个语句,同时load profile中,hard parses的解析比率比较低,这说明数据库发生软解析或软软解析的比率较高,并且每秒钟的解析达到了8039次已是非常之高了,这意味大量的语句解析会对以上两条sql相关在library cache中进行大量争用。

查看引起异常等待的语句情况:(以下采集故障期间 15 分钟 ASH 报告)

从以上可以看出,故障期间引起异常等待的语句主要是a777pyn1fm84h和adunc6tas5ghr两个语句,这两个语句同时大量的等待latch: ges resource hash list和library cache: mutex X,这两个分别是执行调用存储过程的语句。
于是,以下统计这两条语句的历史执行情况(以下统计的是执行成功):


从以上可以看出,节点4数据库中该两条语句的执行频率较高,特别是在早上开始上涨,8点-9点期间正是处于一天中最高峰的时间段,其执行次数分别每小时可高达160万及250万次以上,在这个高并发执行且快速上涨的过程中,数据库及主机的负载会非常大,极易触发异常。
以下查看等待 library cache : mutex X 等待事件中 p1 值,来确定对 library cache 中哪些对象的争用, p1 为 SQL 中对象在 library cache 中的 hash 值,代表 SQL 在执行解析时所争用的对象,这个对象可以是一条语句或一个表。
|
查询library cache: mutex X争用的主要的p1值: EVENT P1 COUNT(*) -------------------------- ---------------- ---------- library cache: mutex X 2342788848 142 library cache: mutex X 421399181 156 library cache: mutex X 1862331593 160 library cache: mutex X 3937440508 167 library cache: mutex X 432630328 244 library cache: mutex X 886671581 315 library cache: mutex X 1987431835 316 library cache: mutex X 1366374364 349 library cache: mutex X 2843724998 418
查询p1对应的对象: CURSOR ADDRESS NAME HASH_VALUE TYPE ---------- ---------------- ------------------------- ---------- -------------------- Parent 000000128EC09DD0 STANDARD 421399181 PACKAGE Parent 000000128EBDF2C8 STANDARD 1862331593 PACKAGE BODY Parent 000000127E15E320 _PKG_GETGETPARAM 2843724998 PACKAGE Parent 000000129A5D3390 XXM_PKG_GETGETPARAM 432630328 PACKAGE BODY Parent 000000129A5E55A0 XXM_PKG_UTIL 1366374364 PACKAGE Parent 000000128E972548 XXM_PKG_UTIL 886671581 PACKAGE BODY Parent 000000129A4EC368 XXM_PROC_GETCALLERIN 3937440508 PROCEDURE Parent 000000129A5E58D0 XXM_PROC_GETIVRINFO 2342788848 PROCEDURE Parent 000000126ABAB798 XXM_PROC_GETPHONEINF 1987431835 PROCEDURE |
从以上可以看出,大部分library cahce 所争用的对象都来自于a777pyn1fm84h和adunc6tas5ghr等于句所调用的包和存储过程。
针对这种高频率的同一语句执行解析对library cache中热对象争用的情况,Oracle 可以使用 DBMS_SHARED_POOL.MARKHOT,来把对象、cursor之类的标记为热点对象,oracle根据cpu 个数,来决定创建多少个object 复制,这样就可以有效的缓解对同一个对象或者cursor的争用。
配置语句示例:
exec dbms_shared_pool.markhot('XXX','XXM_PKG_GETGETPARAM',1);
小结:
通过以上分析,故障期间大部分的异常等待都是由于a777pyn1fm84h和adunc6tas5ghr两个语句引起,同时大量的业务的语句执行导致CPU逐渐上升,可以判断,引起library cache: mutex X的原因是高并发执行同一语句引起的热对象争用,并且当时主机CPU负载本身非常高,这也是其中因素之一。而当主机CPU负载增高时也会latch: ges resource hash list等待堆积。
分析总结
综上分析,可以初步判断数据库问题是由于高频率的存储过程语句执行及解析,消耗了大量的 CPU, 在此过程中不断的对 library cache 中锁争用, CPU 负载增高而处理不及时便引发大批量的 latch: ges resource hash list 和library cache: mutex X等待堆积,同时该等待堆积又消耗大量CPU,从而加剧了主机资源耗尽。
对此,我们建议如下:
1. a777pyn1fm84h 和adunc6tas5ghr等语句执行频率过高,建议分开节点执行,减少同一个数据库实例中对library cache 争用。
2. 对library cache: mutex X 中热对象可使用MARKHOT语句来标记热对象,缓解library cache 争用。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29863023/viewspace-2286875/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/29863023/viewspace-2286875/














 2545
2545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









