






c# 爬网教程
In this tutorial, we are going to talk about web scraping using python.
在本教程中,我们将讨论使用python进行网络抓取。
Firstly, we have to discuss about what is web scraping technique? Whenever we need the data (it can be text, images, links and videos) from web to our database. Lets discuss where we should need the web scraping in real world.
首先,我们必须讨论什么是网络抓取技术? 每当我们需要从Web到我们数据库的数据(可以是文本,图像,链接和视频)时。 让我们讨论一下在现实世界中我们应该在哪里需要网络抓取。
- Nowadays, we have so many competitors in each and every field for surpassing them we need their data from the website or Blogs to know about products, customers and their facilities. 如今,我们在各个领域都拥有众多竞争对手,要想超越这些竞争对手,我们需要从网站或博客中获取他们的数据,以了解产品,客户及其设施。
- And Some Admin of Particular website, blogs and youtube channel want the reviews of their customers in database and want to update with this In, this condition they use web scraping 某些网站,博客和YouTube频道的某些管理员希望他们的客户在数据库中的评论,并希望对此进行更新,在这种情况下,他们使用网络抓取
There are many other areas where we need web scraping, we discussed two points for precise this article for readers.
在许多其他领域,我们需要进行网络抓取,为使读者能够准确了解本文,我们讨论了两点。
Do you want to become certified Python Programmer? Then Intellipaat Python Certification course is for you.
您想成为认证的Python程序员吗? 然后Intellipaat Python认证课程适合您。
Prerequisites:
先决条件:
You just have basic knowledge of python nothing else so, get ready for learning web scraping.
您只具备python的基本知识,因此准备学习网络抓取。
Which technology we should use to achieve web scraping?
我们应该使用哪种技术来实现网页抓取?
We can do this with JavaScript and python but according to me and most of the peoples, we can do it with python easily just you should know the basic knowledge of python nothing else rest of the things we will learn in this article.
我们可以使用JavaScript和python来做到这一点,但是据我和大多数人所说,我们可以轻松地使用python来做到这一点,只是您应该了解python的基本知识,除此之外我们将在本文中学习其他内容。
Python Web爬网教程 (Python Web Scraping Tutorial)
1.通过网页抓取从网站和Youtube频道检索链接和文本 (1. Retrieving Links and Text from Website and Youtube Channel through Web Scraping)
- In this first point, we will learn how to get the text and the links of any webpage with some methods and classes. 在这一点上,我们将学习如何使用一些方法和类来获取任何网页的文本和链接。
We are going to do this beautiful soup method.
我们将要做这种漂亮的汤法。
1. Install BS4 and Install lxml parser
1.安装BS4并安装lxml解析器
To install BS4 in windows open your command prompt or windows shell and type: pip install bs4
要在Windows中安装BS4,请打开命令提示符或Windows Shell,然后键入: pip install bs4
To install lxml in windows open your command prompt or windows shell and type: pip install lxml
要在Windows中安装lxml,请打开命令提示符或Windows Shell,然后键入: pip install lxml
Note: “pip is not recognized” if this error occurs, take help from any reference.
注意:如果发生此错误,则“无法识别点”,请寻求任何参考。
To install BS4 in ubuntu open your terminal:
要在ubuntu中安装BS4,请打开您的终端:
If you are using python version 2 type: pip install bs4
如果您使用的是python版本2,请输入: pip install bs4
If you are using python version 3 type: pip3 install bs4
如果您使用的是python版本3,请输入: pip3 install bs4
To install lxml in ubuntu open your terminal
要在ubuntu中安装lxml,请打开您的终端
If you are using python version 2 type: pip install lxml
如果您使用的是python版本2,请输入: pip install lxml
If you are using python version 3 type: pip3 install lxml
如果您使用的是python版本3,请输入: pip3 install lxml
2. Open Pycharm and Import Modules
2.打开Pycharm和导入模块
Import useful modules:
导入有用的模块:
import bs4
导入bs4
import requests
汇入要求

Then take url of particular website for example www.thecrazyprogrammer.com
然后以特定网站的网址为例,例如www.thecrazyprogrammer.com
url= "https://www.thecrazyprogrammer.com/"
data=requests.get(url)
soup=bs4.BeautifulSoup(data.text,'htm.parser')
print(soup.prettify())And now you will get the html script with the help of these lines of code of particular link you provided to the program. This is the same data which is in the page source of the website webpage you can check it also.
现在,您将在提供给程序的特定链接的这些代码行的帮助下获得html脚本。 这与网站页面的页面源中的数据相同,您也可以检查它。

Now we talk about find function() with the help of find function we can get the text, links and many more things from our webpage. We can achieve this thing through the python code which is written below of this line:
现在,我们在find函数的帮助下讨论find function() ,我们可以从我们的网页上获取文本,链接和更多内容。 我们可以通过以下代码编写的python代码来实现此目的:
We just take one loop in our program and comment the previous line.
我们只需要在程序中执行一个循环并注释上一行。
for para in soup.find('p')
print(para)
And we will get the first para of our webpage, you can see the output in the below image. See, this is the original website view and see the output of python code in the below image.
我们将获得网页的第一段,您可以在下图中看到输出。 请参阅,这是原始网站视图,并在下图中查看python代码的输出。

Pycharm Output
pycharm输出

Now, if you want all the paragraph of this webpage you just need to do some changes in this code i.e.
现在,如果您想要此网页的所有段落,则只需在此代码中进行一些更改,即
Here, we should use find_all function() instead find function. Let’s do it practically
在这里,我们应该使用find_all function()代替find函数。 让我们实践一下

You will get all paragraphs of web page.
您将获得网页的所有段落。
Now, one problem will occur that is the “<p>” tag will print with the text data for removing the <p> tag we have to again do changes in the code like this:
现在,将出现一个问题,即“ <p>”标记将与文本数据一起打印以删除<p>标记,我们必须再次对代码进行如下更改:

We just add “.text” in the print function with para. This will give us only text without any tags. Now see the output there <p> tag has removed with this code.
我们只需在带有para的打印功能中添加“ .text”即可 。 这将只给我们提供没有任何标签的文本。 现在,该代码已删除<p>标记的输出。
With the last line we have completed our first point i.e. how we can get the data (text) and the html script of our webpage. In the second point we will learn how we get the hyperlinks from webpage.
在最后一行中,我们完成了第一点,即如何获取数据(文本)和网页的html脚本。 第二点,我们将学习如何从网页获得超链接。
2.如何通过网页爬取获取网页的所有链接 (2. How to Get All the Links Of Webpage Through Web Scraping)
Introduction:
介绍:
In this, we will learn how we can get the links of the webpage and the youtube channels also or any other web page you want.
在此,我们将学习如何获取网页和youtube频道或您想要的任何其他网页的链接。
All the import modules will be same some changes are there only that changes are:
所有导入模块都是相同的,只有部分更改是:
Take one for loop with the condition of anchor tag ‘a’ and get all the links using href tag and assign them to the object (you can see in the below image) which taken under the for loop and then print the object. Now, you will get all the links of webpage. Practical work:
使用锚标记“ a”的条件进行一个for循环,并使用href标记获取所有链接,并将它们分配给在for循环下获取的对象(如下图所示),然后打印该对象。 现在,您将获得网页的所有链接。 实际工作:

You will get all the links with the extra stuff (like “../” and “#” in the starting of the link)
您将获得带有多余内容的所有链接(例如,链接开头的“ ../”和“#”)
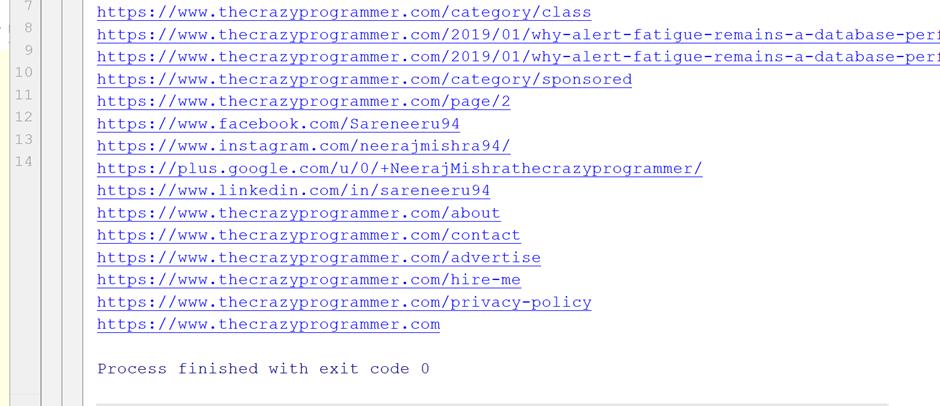
- There is only some valid links in this console screen rest of them are also link but because of some extra stuff are not treating like links for removing this bug we have to do change in our python code. 在此控制台屏幕上只有一些有效的链接,其余的也都是链接,但是由于某些多余的东西没有像删除该bug的链接那样对待,因此我们必须在python代码中进行更改。
We need if and else condition and we will do slicing using python also, “../” if we replace it with our url (you can see the url above images) i.e. https://www.thecrazyprogrammer.com/, we will get the valid links of the page in output console let see practically in below image.
我们需要if和else条件,我们也将使用python进行切片 ,如果将其替换为我们的网址(您可以在图片上方看到网址),即https://www.thecrazyprogrammer.com/ ,我们也会使用“ ../”进行切片在输出控制台中获取页面的有效链接,实际上请参见下图。

In the above image we take the if condition where the link or you can say that the string start with the “../” start with 3 position of the string using slice method and the extra stuff like “#” which is unuseful for us that’s why we don’t include it in our output and we used the len() function also for printing the string to the last and with the prefix of our webpage url are also adding for producing the link.
在上面的图片中,我们采用if条件,其中链接或您可以说使用切片方法以字符串的“ ../”开头并以字符串的3个位置开头,而多余的内容(如“#”)对我们来说是无用的这就是为什么我们不将其包含在输出中的原因,我们还使用len()函数还将字符串打印到最后,并且还添加了带有网页网址前缀的字符串以生成链接。
In your case you can use your own condition according to your output.
根据您的情况,可以根据您的输出使用自己的条件。
Now you can see we get more than one link using if condition. We get so many links but there is also one problem that is we are not getting the links which are starting with “/” for getting these links also we have to do more changes in our code lets see what should we do.
现在,您可以看到我们使用if条件获得了多个链接。 我们有很多链接,但是还有一个问题,就是我们没有得到以“ /”开头的链接来获取这些链接,我们还必须对代码做更多的更改,看看应该怎么做。
So, we have to add the condition elif also with the condition of “/” and here also we should give “#” condition also otherwise we will get extra stuff again in below image we have done this.
因此,我们还必须在条件elif上加上条件“ /”,在这里还应该给“#”条件,否则我们将在下面的图像中再次得到多余的东西。

After putting this if and elif condition in our program to finding all the links in our particular webpage We have got the links without any error you can see in below image how we increased our links numbers since the program without the if and elif condition.
在我们的程序中放置了if和elif条件以查找特定网页中的所有链接之后,我们得到了没有任何错误的链接,您可以在下图中看到,自从没有if和elif条件的程序以来,我们如何增加链接数。

In this way we can get all the links the text of our particular page or website you can find the links in same manner of youtube channel also.
这样,我们可以获得所有链接的特定页面或网站的文本,您也可以以与YouTube频道相同的方式找到这些链接。
Note: If you have any problem to getting the links change the conditions in program as I have done with my problem you can use as your requirement.
注意:如果您对获取链接有任何疑问,请像我对问题所做的那样更改程序中的条件,您可以将其用作您的要求。
So we have done how we can get the links of any webpage or youtube channel page.
因此,我们已经完成了如何获取任何网页或YouTube频道页面的链接的工作。
3.通过网页搜刮登录Facebook (3. Log In Facebook Through Web Scraping)
Introduction
介绍
In this method we can login any account of facebook using Scraping.
在这种方法中,我们可以使用Scraping登录任何Facebook帐户。
Conditions: How we can use this scarping into facebook because the security of Facebook we are unable to do it directly.
条件:由于Facebook的安全性,我们无法直接做到这一点,因此我们如何使用这种疤痕进入Facebook。
So, we can’t login facebook directly we should do change in url of facebook like we should use m.facebook.com or mbasic.facebook.com url instead of www.facebook.com because facebook has high security level we can’t scrap data directly.
因此,我们无法直接登录facebook,我们应该更改facebook的URL,就像我们应该使用m.facebook.com或mbasic.facebook.com的 url而不是www.facebook.com一样,因为facebook的安全级别很高,我们不能直接剪贴数据。
Let’s start scrapping.
让我们开始报废。
This Is Webpage Of m.facebook.com URL
这是m.facebook.com URL的网页
Let’s start with python. So first import all these modules:
让我们从python开始。 因此,首先导入所有这些模块:
import http.cookiejar
导入http.cookiejar
import urllib.request
导入urllib.request
import requests
汇入要求
import bs4
导入bs4
Then create one object and use cookiejar method which provides you the cookie into your python browser.
然后创建一个对象,并使用cookiejar方法将cookie提供给您的python浏览器。
Create another object known as opener and assign the request method to it.
创建另一个称为打开器的对象,并将请求方法分配给它。
Note: do all the things on your risk don’t hack someone id or else.
注意:请您冒险冒险做所有事情,不要破坏他人ID。
Cj=http.cookiejar.Cookiejar()
Opener=urllib.request.build_opener(urllib.request.HTTPcookieProcessor)
Urllib.request.install_opener(opener)
Authentication_url=""
After this code, you have to find the link of particular login id through inspecting the page of m.facebook.com and then put the link into under commas and remove all the text after the login word and add “.php” with login word now type further code.
在此代码之后,您必须通过检查m.facebook.com的页面来找到特定登录ID的链接,然后将该链接放入逗号下并删除登录词后的所有文本,并在登录词后添加“ .php”现在输入更多代码。

payload= {
'email':"[email protected]",
'pass':"(enter the password of id)"
}After this use get function give one cookie to it.
使用完get函数后,给它一个cookie。
Data=urllib.parse.urlencode(payload).encode('utf-8')
Req=urllib.request.Request(authentication_url,data)
Resp=urllib.request.urlopen(req)
Contents=resp.read()
Print(contents)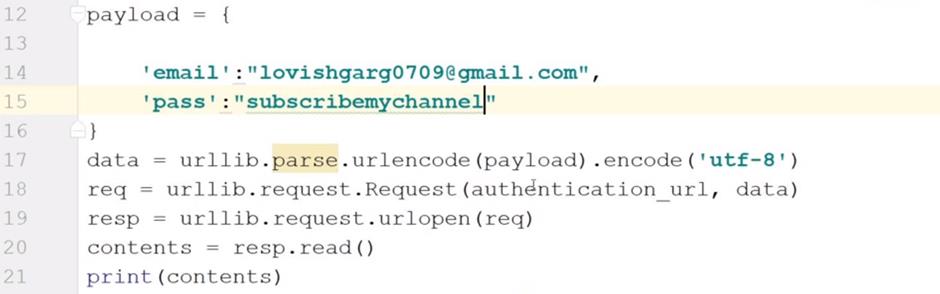
With this code we will login into facebook and the important thing I have written above also do it all things on your risk and don’t hack someone.
通过此代码,我们将登录到Facebook,而我上面编写的重要内容也将由您自担风险,并且不要黑客他人。
We can’t learn full concept of web scraping through this article only but still I hope you learned the basics of python web scrapping.
我们仅通过本文不能了解Web刮取的完整概念,但我仍然希望您学习了python Web刮取的基础知识。
翻译自: https://www.thecrazyprogrammer.com/2019/03/python-web-scraping-tutorial.html
c# 爬网教程














 1554
1554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









