





filestorm超级节点
GraphQL is a specification and therefore language agnostic. When it comes GraphQL development with node, there are various options available ranging from graphql-js, express-graphql to apollo-server. In this tutorial, I'll be showing you how simple it is to get a fully featured GraphQL server up and running in Node.js with Apollo Server.
GraphQL是一个规范,因此与语言无关。 当涉及到带有节点的GraphQL开发时,有各种可用选项,包括graphql-js , express-graphql到apollo-server 。 在本教程中,我将向您展示使用Apollo Server在Node.js中启动并运行功能齐全的GraphQL服务器是多么简单。
Since the lauch of Apollo Server 2, creating GraphQL server with Apollo Server has gotten a lot easier, to to mention the other features that came with it. For the purpose of demonstration, we'll be building a GraphQL server for a simple recipe app.
自从Apollo Server 2停产以来,使用Apollo Server创建GraphQL服务器变得更加容易了,更不用说它附带的其他功能了。 为了演示的目的,我们将为一个简单的配方应用程序构建一个GraphQL服务器。
先决条件 ( Prerequisites )
This tutorial assumes the following:
本教程假定以下内容:
- Node.js and NPM installed on your computer 计算机上安装了Node.js和NPM
- Basic knowledge of GraphQL GraphQL的基础知识
什么是GraphQL? ( What is GraphQL? )
GraphQL is a declarative data fetching specification and query language for APIs. It was created by Facebook. GraphQL is an effective alternative to REST, as it was created to overcome some of the shortcomings of REST like under/over fetching.
GraphQL是用于API的声明性数据获取规范和查询语言。 它是由Facebook创建的。 GraphQL是REST的有效替代方案,因为它是为了克服REST的一些缺点(如读取不足/读取过多)而创建的。
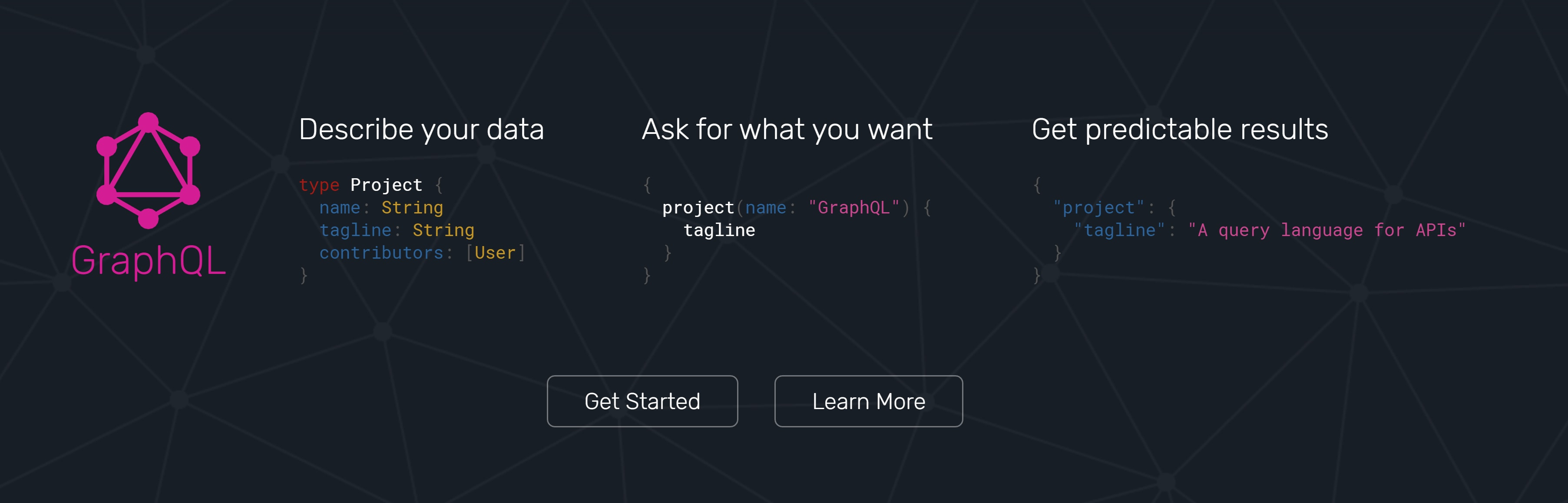
它是如何工作的? ( How does it work? )
Unlike REST, GraphQL uses one endpoint. So basically, we make one request to the endpoint and we'll get one response as JSON. This JSON response can contain as little or as much data as we want. Like REST, GraphQL can be operated over HTTP, though GraphQL is protocol agnostic.
与REST不同,GraphQL使用一个端点。 因此,基本上,我们向端点发出一个请求,并且将获得一个作为JSON的响应。 该JSON响应可以包含我们想要的尽可能少的数据。 与REST一样,尽管GraphQL与协议无关,但GraphQL可以通过HTTP操作。
A typical GraphQL server is comprised of schema and resolvers. A schema (or GraphQL schema) contains type definitions that would make up a GraphQL API. A type definition contains field(s), each with what it is expected to return. Each field is mapped to a function on the GraphQL server called a resolver. Resolvers contains the implementation logic and returns data for a field. Other words, schema contains type definition, while resolvers contains the actual implementations.
典型的GraphQL服务器由架构和解析器组成。 模式(或GraphQL模式)包含将构成GraphQL API的类型定义。 类型定义包含一个或多个字段,每个字段都包含预期返回的内容。 每个字段都映射到GraphQL服务器上称为解析器的函数。 解析器包含实现逻辑并返回字段的数据。 换句话说,模式包含类型定义,而解析器包含实际的实现。
设置数据库 ( Setting up the database )
We’ll start by setting up our database. To keep things simple and straightforward, we’ll be using SQLite for our database. Also, we’ll be using Sequelize, which is an ORM for Node.js, to interact with our database. First, let's create a new project:
我们将从建立数据库开始。 为了使事情简单明了,我们将对数据库使用SQLite。 另外,我们将使用Sequelize (它是Node.js的ORM)与我们的数据库进行交互。 首先,让我们创建一个新项目:
$mkdir graphql-recipe-server
$ cd graphql-recipe-server
$ yarn init -yNext, let's install Sequelize:
接下来,让我们安装Sequelize:
$ yarn add sequelize sequelize-cli sqlite3In addtion to install Sequelize, we are also installing sqlite3 package for Node.js. To help us scaffold our project, we’ll be using the Sequelize CLI, which we are installing as well.
除了安装Sequelize,我们还为Node.js安装sqlite3软件包。 为了帮助我们搭建项目,我们将使用同时安装的Sequelize CLI。
Let's scaffold our project with the CLI:
让我们用CLI搭建我们的项目:
$ node_modules/.bin/sequelize initThis will create following folders:
这将创建以下文件夹:
config: contains config file, which tells Sequelize how to connect with our database. models: contains all models for our project, also contains an index.js file which integrates all the models together. migrations: contains all migration files. seeders: contains all seed files.
config :包含配置文件,它告诉Sequelize如何与我们的数据库连接。 models :包含我们项目的所有模型,还包含将所有模型集成在一起的index.js文件。 migrations :包含所有迁移文件。 seeders :包含所有种子文件。
For the purpose of this tutorial, we won't be creating with any seeders. Open config/config.json and replace it content with below:
就本教程而言,我们将不使用任何播种器进行创建。 打开config/config.json并将其内容替换为以下内容:
// config/config.json{
"development": {
"dialect": "sqlite",
"storage": "./database.sqlite"
}
}We set the dialect to sqlite and set the storage to point to a SQLite database file.
我们将dialect设置为sqlite ,并将storage设置为指向SQLite数据库文件。
Next, we need to create the database file directly inside the project's root directory:
接下来,我们需要直接在项目的根目录内创建数据库文件:
$touch database.sqlite创建模型和迁移 ( Creating models and migrations )
With the database set up out of the way, we can start creating the models for our project. Our recipe app will have two models: User and Recipe. We’ll be using the Sequelize CLI for this:
随着数据库的建立,我们可以开始为我们的项目创建模型。 我们的食谱应用程序将具有两种模型: User和Recipe 。 我们将为此使用Sequelize CLI:
$ node_modules/.bin/sequelize model:create --name User --attributes name:string,email:string,password:stringThis is will create a user.js file inside the models directory and a corresponding migration file inside the migrations directory.
这将在models目录中创建一个user.js文件,并在migrations目录中创建一个相应的迁移文件。
Since we don't want any on the fields on the User model to be nullable, we need to explicitly defined that. Open migrations/XXXXXXXXXXXXXX-create-user.js and update the fields definitions as below:
由于我们不希望User模型上的字段可以为空,因此我们需要明确定义它。 打开migrations/XXXXXXXXXXXXXX-create-user.js并更新字段定义,如下所示:
// migrations/XXXXXXXXXXXXXX-create-user.js
name: {
allowNull: false,
type: Sequelize.STRING
},
email: {
allowNull: false,
type: Sequelize.STRING
},
password: {
allowNull: false,
type: Sequelize.STRING
}Then we'll do the same in the User model:
然后,我们将在User模型中执行相同的User :
// models/user.js
name: {
type: DataTypes.STRING,
allowNull: false
},
email: {
type: DataTypes.STRING,
allowNull: false
},
password: {
type: DataTypes.STRING,
allowNull: false
}Next, let's create the Recipe model:
接下来,让我们创建Recipe模型:
$ node_modules/.bin/sequelize model:create --name Recipe --attributes title:string,ingredients:text,direction:textJust as we did with the User model, we'll do the same for the Recipe model. Open migrations/XXXXXXXXXXXXXX-create-recipe.js and update the fields definitions as below:
就像使用User模型一样,我们将对Recipe模型执行相同的操作。 打开migrations/XXXXXXXXXXXXXX-create-recipe.js并更新字段定义,如下所示:
// migrations/XXXXXXXXXXXXXX-create-recipe.js
userId: {
type: Sequelize.INTEGER.UNSIGNED,
allowNull: false
},
title: {
allowNull: false,
type: Sequelize.STRING
},
ingredients: {
allowNull: false,
type: Sequelize.STRING
},
direction: {
allowNull: false,
type: Sequelize.STRING
},You'll notice we have an additional field: userId, which would hold the ID of the user that created a recipe. More on this shortly.
您会注意到我们还有一个附加字段: userId ,其中包含创建食谱的用户的ID。 不久之后会更多。
Update the Recipe model as well:
同时更新Recipe模型:
// models/recipe.js
title: {
type: DataTypes.STRING,
allowNull: false
},
ingredients: {
type: DataTypes.STRING,
allowNull: false
},
direction: {
type: DataTypes.STRING,
allowNull: false
}To wrap up with our models, let's define the relationship between them. You might have guessed with the inclusion of the userId column to the recipes table, that we want to be able to associate a recipe to a user and vice-versa. So, we want a one-to-many relationships between our models.
为了总结我们的模型,让我们定义它们之间的关系。 您可能已经猜到在recipes表中包含了userId列,我们希望能够将食谱与用户相关联,反之亦然。 因此,我们希望模型之间存在一对多关系。
Open models/user.js and update the User.associate function as below:
打开models/user.js并更新User.associate函数,如下所示:
// models/user.js
User.associate = function (models) {
User.hasMany(models.Recipe)
}We need to also define the inverse of the relationship on the Recipe model:
我们还需要在Recipe模型上定义关系的逆:
// models/recipe.js
Recipe.associate = function (models) {
Recipe.belongsTo(models.User, { foreignKey: 'userId' })
}By default, Sequelize will use a camel case name from the corresponding model name and its primary key as the foreign key. So in our case, it will expect the foreign key to be UserId. Since we named the column differently, we need to explicitly define the foreignKey on the association.
默认情况下,Sequelize将使用相应模型名称中的骆驼箱名称及其主键作为外键。 因此,在本例中,它将期望外键为UserId 。 由于我们以不同的方式命名该列,因此我们需要在关联上显式定义foreignKey 。
Now, we can run the migrations:
现在,我们可以运行迁移:
$ node_modules/.bin/sequelize db:migrate创建GraphQL服务器 ( Creating the GraphQL server )
Phew! Let's get to the GraphQL stuff. As earlier mentioned, we'll be using Apollo Server for building our GraphQL server. So, let's install it:
! 让我们看一下GraphQL的东西。 如前所述,我们将使用Apollo Server来构建GraphQL服务器。 因此,让我们安装它:
$ yarn add apollo-server graphql bcryptjsApollo Server requires graphql as a dependency, hence the need to install it as well. Also, we install bcryptjs, which we'll use to hash users passwords later on.
Apollo Server需要graphql作为依赖项,因此也需要安装它。 另外,我们安装了bcryptjs ,稍后将用它来哈希用户密码。
With those installed, create a src directory, then within it, create an index.js file and paste the code below in it:
安装后,创建一个src目录,然后在其中创建一个index.js文件,并将以下代码粘贴到其中:
// src/index.js
const { ApolloServer } = require('apollo-server')
const typeDefs = require('./schema')
const resolvers = require('./resolvers')
const models = require('../models')
const server = new ApolloServer({
typeDefs,
resolvers,
context: { models }
})
server
.listen()
.then(({ url }) => console.log('Server is running on localhost:4000'))Here, we create a new instance of Apollo Server, passing to it our schema and resolvers (both which we'll create shortly). We also pass the models as the context to the Apollo Server. This will allow us have access to the models from our resolvers.
在这里,我们创建一个新的Apollo Server实例,并将其架构和解析器(稍后将很快创建)传递给它。 我们还将模型作为上下文传递给Apollo服务器。 这将使我们能够从解析器访问模型。
Finally, we start the server.
最后,我们启动服务器。
定义GraphQL模式 ( Defining the GraphQL Schema )
GraphQL schema is used to define the functionality a GraphQL API would have. Basically, a GraphQL schema is comprised of types. A type can be for defining the structure of our domain specific entity. In addition to defining types for our domain specific entities, we can also define types for GraphQL operations, which will in turn translates to the functionality a GraphQL API will have. These operations are: queries, mutations and subscriptions. Queries are used to perform read operations (fetching of data) on a GraphQL server. Mutations on the other hand are used to perform write operations (inserting, updating or deleting data) on a GraphQL server. Subscriptions are completely different from these two, as they are used to add realtime functionality to a GraphQL server.
GraphQL模式用于定义GraphQL API所具有的功能。 基本上,一个GraphQL模式由类型组成。 类型可以用于定义我们域特定实体的结构。 除了为我们特定于域的实体定义类型外,我们还可以为GraphQL操作定义类型,这又将转换为GraphQL API将具有的功能。 这些操作是:查询,变异和订阅。 查询用于在GraphQL服务器上执行读取操作(数据获取)。 另一方面,变异用于在GraphQL服务器上执行写入操作(插入,更新或删除数据)。 订阅与这两个完全不同,因为它们用于向GraphQL服务器添加实时功能。
We'll be focusing only on queries and mutations in this tutorial.
在本教程中,我们将只关注查询和变异。
Now that we understand what GraphQL schema is, let's create the schema for our app. Within the src directory, create a schema.js file and paste the code below in it:
现在我们了解了GraphQL模式是什么,让我们为我们的应用程序创建模式。 在src目录中,创建一个schema.js文件,并将以下代码粘贴到其中:
// src/schema.js
const { gql } = require('apollo-server')
const typeDefs = gql`
type User {
id: Int!
name: String!
email: String!
recipes: [Recipe!]!
}
type Recipe {
id: Int!
title: String!
ingredients: String!
direction: String!
user: User!
}
type Query {
user(id: Int!): User
allRecipes: [Recipe!]!
recipe(id: Int!): Recipe
}
type Mutation {
createUser(name: String!, email: String!, password: String!): User!
createRecipe(
userId: Int!
title: String!
ingredients: String!
direction: String!
): Recipe!
}
`
module.exports = typeDefsFirst, we pull in the gql package from apollo-server. Then we use it to define our schema. Ideally, we'd want to our GraphQL schema to mirror our database schema as much as possible. So we define to types: User and Recipe, which corresponds to our models. On the User type, in addition to defining the fields we have on the User model, we also define a recipes fields, which will be used to retrieve the user's recipes. Same with the Recipe type, we define a user field, which will be used to get the user of a recipe.
首先,我们从apollo-server提取gql软件包。 然后我们使用它来定义我们的模式。 理想情况下,我们希望GraphQL模式尽可能地镜像我们的数据库模式。 因此,我们定义了以下类型: User和Recipe ,它们与我们的模型相对应。 在User类型上,除了定义User模型上的字段外,我们还定义一个recipes字段,这些字段将用于检索用户的配方。 与“ Recipe类型相同,我们定义一个“ user字段,该字段将用于获取食谱的用户。
Next, we define three queries; for fetching a single user, for fetching all recipes that have been created and for fetching a single recipe respectively. Both the user and recipe queries can either return a user or recipe respectively or return null if no corresponding match was found for the ID. The allRecipes query will always return a array of recipes, which might be empty if no recipe as been created yet.
接下来,我们定义三个查询; 用于获取单个用户,获取所有已创建的食谱以及分别获取单个食谱。 user和recipe查询都可以分别返回用户或配方,或者如果没有找到对应的ID匹配,则返回null 。 allRecipes查询将始终返回配方数组,如果尚未创建配方,则该数组可能为空。
Lastly, we define mutations for creating and new user as well as creating a new recipe. Both mutations return back the created user and recipe respectively.
最后,我们定义了用于创建新用户和创建新配方的变体。 这两个突变分别返回创建的用户和配方。
Tips: The ! denotes a field is required, while [] denotes the field will return an array of items.
提示:! 表示必填字段,而[]表示该字段将返回项目数组。
创建解析器 ( Creating the resolvers )
Resolvers defines how the fields in a schema is executed. In other words, our schema is useless without resolvers. Creating a resolvers.js file inside the src directory and past the following code in it:
解析程序定义模式中字段的执行方式。 换句话说,没有解析器,我们的架构将毫无用处。 在src目录中创建一个resolvers.js文件,并在其中添加以下代码:
// src/resolvers.js
const resolvers = {
Query: {
async user (root, { id }, { models }) {
return models.User.findById(id)
},
async allRecipes (root, args, { models }) {
return models.Recipe.findAll()
},
async recipe (root, { id }, { models }) {
return models.Recipe.findById(id)
}
},
}
module.exports = resolversWe start by creating the resolvers for our queries. Here, we are making use of the models to perform the necessary queries on the database and simply return the results.
我们首先为查询创建解析器。 在这里,我们利用这些模型对数据库执行必要的查询,并简单地返回结果。
Still inside src/resolvers.js, let's import bcryptjs at the top of the file:
仍然在src/resolvers.js内部,让我们在文件顶部导入bcryptjs :
// src/resolvers.js
const bcrypt = require('bcryptjs')Then add the code below immediately after the Query object:
然后在Query对象之后立即添加以下代码:
// src/resolvers.js
Mutation: {
async createUser (root, { name, email, password }, { models }) {
return models.User.create({
name,
email,
password: await bcrypt.hash(password, 10)
})
},
async createRecipe (root, { userId, title, ingredients, direction }, { models }) {
return models.Recipe.create({ userId, title, ingredients, direction })
}
},The createUser mutation accepts the name, email and password of a user, and creates a new record in the database with the supplied details. We make sure to hash the password using the bcrypt package before persisting it to the database. It returns the newly created user. The createRecipe mutation accepts the ID of the user that's creating the recipe as well as the details for the recipe itself, persists them to the database and returns the newly created recipe.
createUser突变接受用户的名称,电子邮件和密码,并使用提供的详细信息在数据库中创建新记录。 我们确保在将密码持久保存到数据库之前使用bcrypt软件包对密码进行哈希处理。 它返回新创建的用户。 createRecipe突变接受创建配方的用户的ID以及配方本身的详细信息,并将其持久化到数据库中并返回新创建的配方。
To wrap up with the resolvers, let's define how we want our custom fields (recipes on the User and user on Recipe) to be resolved. Add the code below inside src/resolvers.js just immediately the Mutation object:
为了总结解析器,让我们定义如何解析自定义字段(“ user上的Recipe和“ recipes上的User )。 将代码添加到src/resolvers.js内部,紧接在Mutation对象之后:
// src/resolvers.js
User: {
async recipes (user) {
return user.getRecipes()
}
},
Recipe: {
async user (recipe) {
return recipe.getUser()
}
}These uses the methods (getRecipes() , getUser()), which are made available on our models by Sequelize due to the relationships we defined.
这些使用方法( getRecipes() , getUser() ),由于我们定义的关系,Sequelize在我们的模型中提供了这些方法。
测试我们的GraphQL服务器 ( Testing our GraphQL server )
It's time to test our GraphQL server out. First, we need to start the server with:
现在该测试我们的GraphQL服务器了。 首先,我们需要使用以下命令启动服务器:
$ node src/index.jsThis should be running on http://localhost:4000, and we should see GraphQL Playground running if we access it. Let's try creating a new recipe:
它应该在http:// localhost:4000上运行 ,并且如果访问它,我们应该看到GraphQL Playground正在运行。 让我们尝试创建一个新配方:
# create a new recipe
mutation {
createRecipe(
userId: 3
title: "Sample 2"
ingredients: "Salt, Pepper"
direction: "Add salt, Add pepper"
) {
id
title
ingredients
direction
user {
id
name
email
}
}
}We should see a result as below:
我们应该看到如下结果:

结论 ( Conclusion )
In this tutorial, we looked at how to creating a GraphQL server in Node.js with Apollo Server. We also saw how to integrate a database with a GraphQL server using Sequelize.
在本教程中,我们研究了如何使用Apollo Server在Node.js中创建GraphQL服务器。 我们还看到了如何使用Sequelize将数据库与GraphQL服务器集成。
翻译自: https://scotch.io/tutorials/super-simple-graphql-with-node
filestorm超级节点















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









