





背景 (Background)
Running totals have long been the core of most financial systems, be statements or even balance calculations at a given point in time. Now it’s not the hardest thing to do in SQL Server but it is definitely not the fastest thing in the world either as each record has to be evaluated separately. Prior to SQL Server 2012, you have to manually define the window/subset in which you want to calculate you running total, normally we would define a row number with a window on a specific order or a customer depending on the requirements at hand.
长期以来,运行总计一直是大多数财务系统的核心,无论是报表还是在给定时间点的余额计算。 现在,这并不是SQL Server中最难的事情,但绝对不是世界上最快的事情,因为每个记录都必须分别进行评估。 在SQL Server 2012之前,您必须手动定义要在其中计算总运行额的窗口/子集,通常,我们会根据手头的要求定义一个行号,该窗口中包含特定订单或客户的窗口。
讨论区 (Discussion)
I was tasked with rewriting a piece of old C# code that we have in our system in SQL as it was no longer performing optimally. The data requirements grew too fast for the system to be able to keep up. The piece of code was responsible for generating transactional statements that would go out to customers every night on request. One of the requirements, in the statement, was to build a running total in the statement to make it easier for customers to reconcile their transactions in question at any given time. So I started looking at my options and found there are a couple of ways for us to create running totals in SQL Server, so I started testing all the methods I can think off and find online. With performance in mind, I tried to make sure I got the best/fastest solution to my problem. I know from previous experiences that using windowed functions to help with these calculations is usually the fastest, but I had 2 big issues as the first part of the statement would run on SQL Server 2008R2 and the second objective I had in mind is to run this of our APS (You can read more on what an APS is and how it works here).
我的任务是用SQL重写系统中已有的旧C#代码,因为它不再具有最佳性能。 数据需求增长得太快了,系统无法跟上。 该代码段负责生成事务处理语句,该语句将根据要求每晚发送给客户。 报表中的一项要求是在报表中建立一个总计,以使客户在任何给定时间更容易调和有关交易。 因此,我开始研究自己的选择,发现有两种方法可以在SQL Server中创建运行总计,因此我开始测试所有可以考虑并在线找到的方法。 考虑到性能,我试图确保获得针对问题的最佳/最快解决方案。 我从以前的经验中知道,使用窗口函数来帮助进行这些计算通常是最快的,但是我遇到了两个大问题,因为该语句的第一部分将在SQL Server 2008R2上运行,而我想到的第二个目标是运行该语句我们的APS的(你可以阅读更多关于什么的APS以及它是如何工作的在这里 )。
注意事项 (Considerations)
Prior to SQL Server 2012 running totals a not a pretty thing to do in SQL, it is not hard but slow. Always test everything a DEV or UAT if you are lucky enough to have proper testing environments.
在SQL Server 2012上运行之前,在SQL中总不是一件好事,但这并不难,但很慢。 如果您幸运地拥有适当的测试环境,请始终对DEV或UAT进行所有测试。
先决条件 (Prerequisites)
- SQL Server 2008+ or SQL Server 2012+ (If you want to use the windowed method) SQL Server 2008+或SQL Server 2012+(如果要使用窗口方法)
- AdventureWorks Sample Database (If you want to follow the examples in the article) AdventureWorks示例数据库(如果您想遵循本文中的示例)
目的 (Objective)
We will be using the AdventureWorks sample database to go through a few methods of creating running totals in SQL Server and by doing this looking at what the best option for our environment would be.
我们将使用AdventureWorks示例数据库来研究几种在SQL Server中创建运行总计的方法,并通过这样做来寻找对我们的环境而言最佳的选择。
解 (Solution)
My first thought was to us a subquery to create my running total as this would make sense to calculate the value of the running total at execution time.
我的第一个想法是为我们创建运行总计的子查询,因为在执行时计算运行总计的值很有意义。
--SubQuery
SELECT SalesOrderID ,
SalesOrderDetailID ,
LineTotal ,
( SELECT SUM(y.LineTotal)
FROM Sales.SalesOrderDetail y
WHERE y.SalesOrderID = x.SalesOrderID
AND y.SalesOrderDetailID <= x.SalesOrderDetailID
) AS RunningTotal
FROM Sales.SalesOrderDetail x
ORDER BY 1 ,2 ,3;
Now as we can see from the above screenshot of the result set this work perfectly, but I cannot just look at one option as I need to make sure it is as optimised as possible to ensure business continuity. So what if we did a self-join and join the table to itself with an offset and then used this as a way to get a running total working and would this be faster as I can control the indexing better to ensure the performance is better than the subquery method.
现在,从上面的结果集屏幕快照中我们可以看到,此功能可以完美地工作,但是我不能只看一个选项,因为我需要确保它尽可能优化以确保业务连续性。 因此,如果我们进行自联接并使用偏移量将表连接到自身,然后将其用作获得运行总工作量的方法,那会更快些,因为我可以更好地控制索引以确保性能优于子查询方法。
So let’s see how to this will work and will it be more effective.
因此,让我们看看这将如何工作并且会更有效。
--Self Join
SELECT x.SalesOrderID ,
x.SalesOrderDetailID ,
x.LineTotal ,
SUM(y.LineTotal) AS RunningTotal
FROM Sales.SalesOrderDetail x
JOIN Sales.SalesOrderDetail y ON y.SalesOrderID = x.SalesOrderID
AND y.SalesOrderDetailID <= x.SalesOrderDetailID
GROUP BY x.SalesOrderID ,
x.SalesOrderDetailID ,
x.LineTotal
ORDER BY 1, 2, 3;
And what do you know, it works and the results set is the exact same as we would have hoped. The big question now is, is it really better than the subquery method? So let’s pull out the execution plan and compare the two together.
您知道吗,它可以工作,结果集与我们希望的完全相同。 现在最大的问题是,它真的比子查询方法好吗? 因此,让我们提出执行计划,并将两者进行比较。
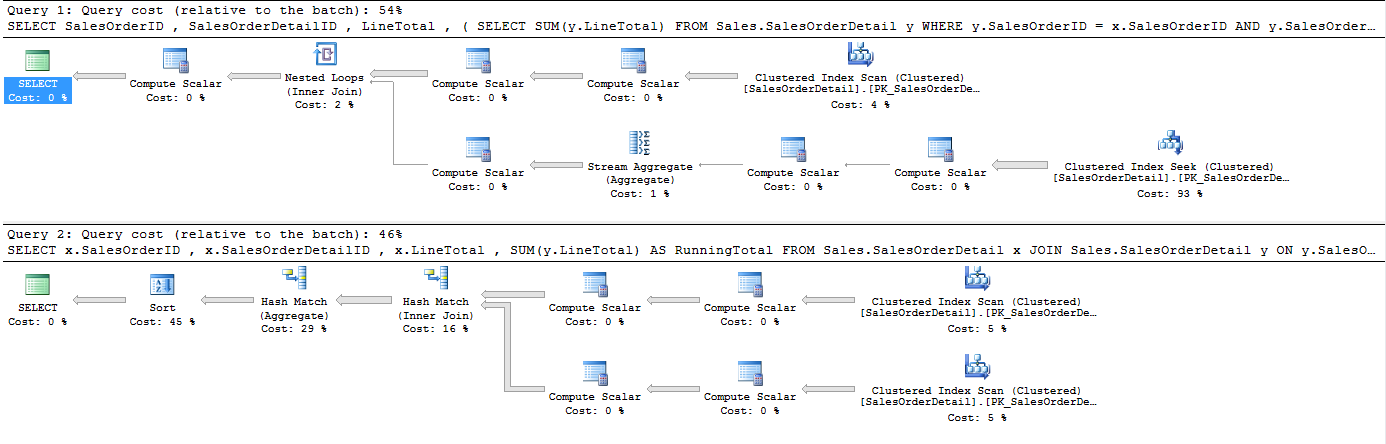
By looking only at the relative to batch percentages we can immediately see that the subquery method used 54% of the batch resources and the self-join only 46%. So now let’s see if we can improve on this even further.
通过仅查看相对于批次的百分比,我们可以立即看到子查询方法使用了54%的批次资源,而自联接仅使用了46%。 现在,让我们看看我们是否可以进一步改善这一点。
I was thinking of how I could use the recursive nature of a CTE to create a running total. So the below code will be using a recursive CTE to add the “LineTotal” to itself the whole time.
我在考虑如何使用CTE的递归性质来创建运行总计。 因此,以下代码将始终使用递归CTE将“ LineTotal”添加到自身。
WITH CTE
AS ( SELECT SalesOrderID ,
SalesOrderDetailID ,
LineTotal ,
RunningTotal = LineTotal
FROM Sales.SalesOrderDetail
WHERE SalesOrderDetailID IN ( SELECT MIN(SalesOrderDetailID)
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID )
UNION ALL
SELECT y.SalesOrderID ,
y.SalesOrderDetailID ,
y.LineTotal ,
RunningTotal = x.RunningTotal + y.LineTotal
FROM CTE x
JOIN Sales.SalesOrderDetail y ON y.SalesOrderID = x.SalesOrderID
AND y.SalesOrderDetailID = x.SalesOrderDetailID + 1
)
SELECT *
FROM CTE
ORDER BY 1 ,
2 ,
3
OPTION ( MAXRECURSION 10000 );
And again we get the same results, but only this time if we have a look at the execution plan for all three of the methods we have tested we see something very interesting.
再次,我们得到相同的结果,但是只有这次,如果我们看看测试过的所有三个方法的执行计划,我们都会看到一些非常有趣的东西。
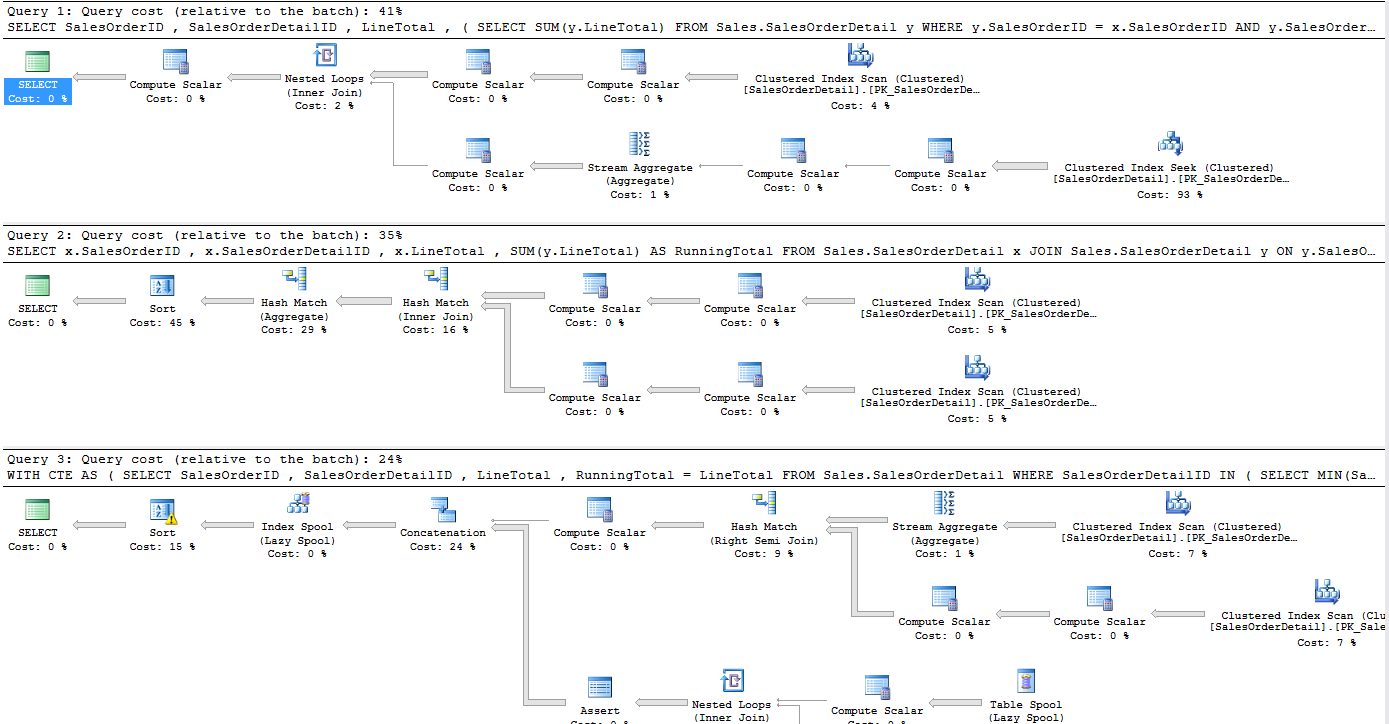
Now we can see that the recursive CTE is way faster than the other two methods so clearly we have a winner. Or do we? Firstly to allow the CTE to be used in this way we have to increase the MAXRECURSION option for this query, and the max we are allowed to set it to is 32767. In my use case, I would not ever come close to this number ever as no statement ever have this many records in, but if you are running this on big data sets you would not be able to go with this method. And secondly, when I tested it on our APS, it yells at me for even thinking I can do a recursive CTE on it. So then in my production environment on SQL Server 2008R2 I can use this method, but in our data warehousing environment, I need to use one of the other two methods.
现在我们可以看到递归CTE比其他两种方法快得多,因此很明显我们有赢家。 还是我们? 首先,为了允许以这种方式使用CTE,我们必须为此查询增加MAXRECURSION选项,并且允许将其设置为max(最大值)为32767。在我的用例中,我永远都不会接近这个数字因为没有语句包含这么多的记录,但是如果您在大数据集上运行此记录,则将无法使用此方法。 其次,当我在APS上对其进行测试时,它甚至对我认为可以对其进行递归CTE都大吼大叫。 因此,在SQL Server 2008R2的生产环境中,我可以使用此方法,但是在数据仓库环境中,我需要使用其他两种方法之一。
Now if you are lucky enough to run SQL Server 2012+ (as most of us should be doing), Microsoft improved on the Windowed functions and thus we have a far superior method that we can use. Using windowed functions in this is faster and easier to read when you have to hand down your code to someone else to support or change.
现在,如果您有幸可以运行SQL Server 2012+(就像我们大多数人一样),Microsoft改进了Windowed函数,因此我们可以使用一种非常优越的方法。 当您必须将代码交给其他人来支持或更改时,在其中使用窗口函数可以更快,更容易阅读。
--SQL2012+
SELECT SalesOrderID ,
SalesOrderDetailID ,
LineTotal ,
SUM(LineTotal) OVER ( PARTITION BY SalesOrderID ORDER BY SalesOrderDetailID ) AS RunningTotal
FROM Sales.SalesOrderDetail
ORDER BY 1 ,
2 ,
3;
If we have a look at the execution plan now, only comparing the recursive CTE to the Windowed function method, we can clearly see that the recursive CTE is no match for the Windowed function.
如果现在看一下执行计划,仅将递归CTE与Windowed函数方法进行比较,就可以清楚地看到递归CTE与Windowed函数不匹配。
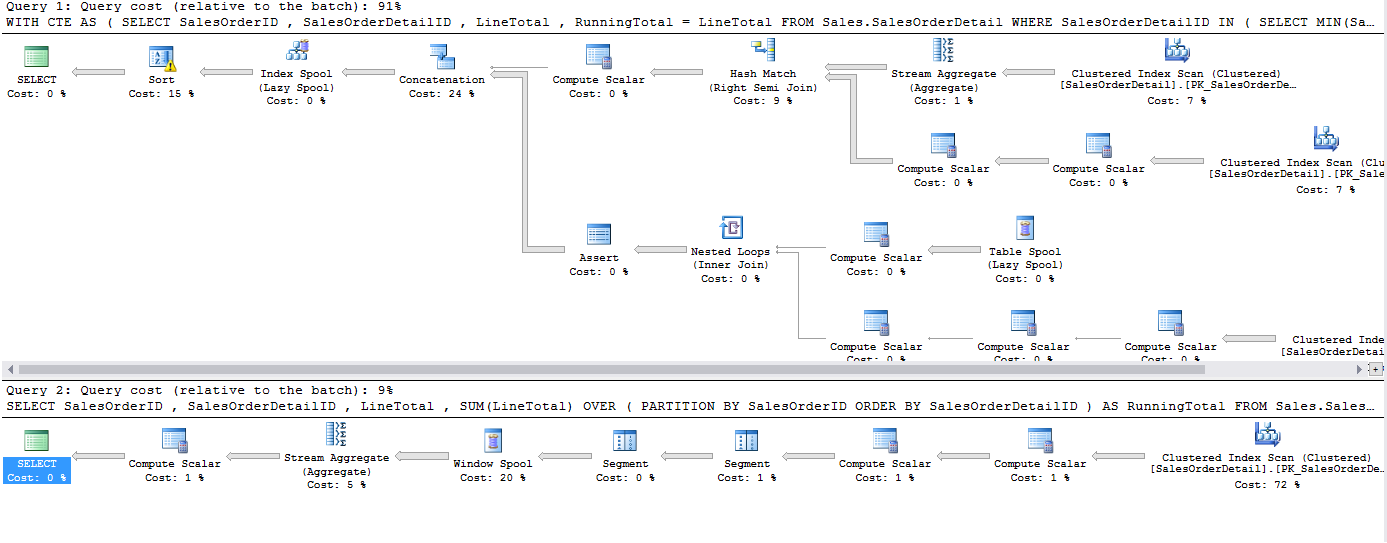
Looking at the relative to batch again we can see that the recursive CTE now use 91% compared to the windowed function method of 9%.
再次查看相对于批处理的关系,我们可以看到递归CTE现在使用91%,而窗口函数方法为9%。
最后的想法 (Final thoughts)
If you know your data and the requirement well, I would use the recursive CTE method in environments pre-SQL Server 2012 and the Windowed functions in SQL Server 2012 and later. I also think that a CLR might be useful in this scenario, but my C# skills is a bit rusty at the moment. Maybe with the help of the community, I can test this idea.
如果您很了解您的数据和要求,我将在SQL Server 2012之前的环境中使用递归CTE方法,在SQL Server 2012及更高版本中使用Windowed函数。 我还认为在这种情况下CLR可能会有用,但是我的C#技能目前有点生锈。 也许在社区的帮助下,我可以测试这个想法。
参考资料 (References)
翻译自: https://www.sqlshack.com/running-running-totals-sql-server/















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









