





sql server序列
In this article, we will be discussing Microsoft Sequence Clustering in SQL Server. This is the ninth article of our SQL Server Data mining techniques series. Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network are the other techniques that we discussed until this article.
在本文中,我们将讨论SQL Server中的Microsoft序列群集。 这是我们SQL Server数据挖掘技术系列的第9条。 朴素贝叶斯 , 决策树 , 时间序列 , 关联规则 , 聚类 , 线性回归 , 神经网络是我们在本文之前讨论的其他技术。
什么是序列聚类 (What is Sequence Clustering)
The Microsoft Sequence Clustering algorithm is a combination of sequence analysis and clustering. This technique identifies natural groups (clusters) of similarly ordered events in a sequence.
Microsoft序列聚类算法是序列分析和聚类的组合。 此技术可识别序列中顺序相似的事件的自然组(簇)。
In Sequence Clustering, we will be looking at the events which have occurred in sequence. Then the clustering is applied to that data set. The clusters can be used to predict the likely ordering of events in a sequence based on known characteristics.
在序列聚类中,我们将研究按顺序发生的事件。 然后将聚类应用于该数据集。 聚类可用于基于已知特征预测序列中事件的可能顺序。
In this technique, the Hidden Markov model will be used to generate the sequences while K-Means and Expectation-Maximization (EM) clustering techniques will be used for clustering. Since we have discussed clustering techniques in the Clustering article, let us discuss the Hidden Markov Process in short.
在这种技术中,隐马尔可夫模型将用于生成序列,而K均值和期望最大化(EM)聚类技术将用于聚类。 由于我们在“聚类”一文中讨论了聚类技术,因此让我们简短地讨论“隐马尔可夫过程”。
隐马尔可夫过程 (Hidden Markov Process)
If you wondering how Google ranks its pages, it is by using an algorithm called a PageRank. Page rank uses Markov Process. This technique was introduced by the mathematician named, Andrey Markov (1856 – 1922) in 1906. In Hidden Markov Process, we are looking at exploring the sequence of events.
如果您想知道Google如何对其网页进行排名,可以使用称为PageRank的算法。 页面排名使用马尔可夫过程。 这项技术是由名叫安德烈·马尔科夫(Andrey Markov,1856 – 1922)的数学家在1906年引入的。在“隐马尔可夫过程”中,我们正在研究事件的顺序。
实作 (Implementation)
Let us see how we can implement, Microsoft Sequence Clustering in SQL Server. Like we did for all the other techniques, we need to create a SSAS project in this technique too. Similar to other projects, we need to create a data source to the AdventureWorksDW database.
让我们看看如何在SQL Server中实现Microsoft Sequence Clustering。 就像我们对所有其他技术所做的一样,我们也需要在该技术中创建一个SSAS项目。 与其他项目类似,我们需要为AdventureWorksDW数据库创建一个数据源。
In this technique, we have to use two views for the data source views similar to what we did in the Association Rule technique. Those two views are vAssocSeqOrders and vAssocSeqLineItems added to the data source views as shown below.
在此技术中,我们必须对数据源视图使用两个视图,类似于在关联规则技术中所做的操作。 这两个视图是添加到数据源视图中的vAssocSeqOrders和vAssocSeqLineItems ,如下所示。
By default, there won’t be any relationships between these two views since there are no relationships built at the database level. Therefore, that relationship has to be built as shown in the above screenshot.
默认情况下,这两个视图之间没有任何关系,因为在数据库级别没有建立任何关系。 因此,必须如上面的屏幕快照所示建立这种关系。
Next is to select the technique for the mining model. As shown in the below screenshot, we will be selecting the Microsoft Sequence Clustering from the available list.
接下来是选择挖掘模型的技术。 如下面的屏幕快照所示,我们将从可用列表中选择Microsoft Sequence Clustering。
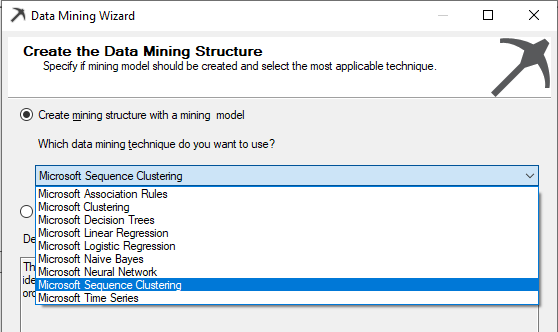
After choosing the database source view, next is to choose the Case and Nested tables. Unlike most of the other techniques, there are two tables in this technique.
选择数据库源视图之后,接下来是选择Case和Nested表。 与大多数其他技术不同,此技术有两个表。
In this vAssocSeqOrders should be selected as the Case table where the vAssocSeqLineItems should be selected as the Nested as shown in the below screenshot.
在此情况下,应将vAssocSeqOrders选择为Case表,在其中将vAssocSeqLineItems选择为Nested,如以下屏幕截图所示。
Let us see what our objectives in this sample data are. If you recall what we did for the association rule, is that we are looking at what are the similar items selling together. In that example, we looked at only Order Number and the Model as inputs.
让我们看看此样本数据中的目标是什么。 如果您还记得我们为关联规则所做的操作,那就是我们正在查看一起出售的类似物品。 在该示例中,我们仅查看订单号和模型作为输入。
In the case of sequence clustering, we are looking at the sequences. Therefore, we will include the Line Number as the sequence parameter. Though this may not be a correct business case, however from the existing sample data, this is the only dataset that has a sequence attribute.
在序列聚类的情况下,我们正在查看序列。 因此,我们将把“行号”作为序列参数。 尽管这可能不是正确的业务案例,但是从现有的样本数据来看,这是唯一具有序列属性的数据集。
Therefore, we have selected Key, Input and Predict as shown in the following screenshot.
因此,我们选择了键,输入和预测,如以下屏幕快照所示。
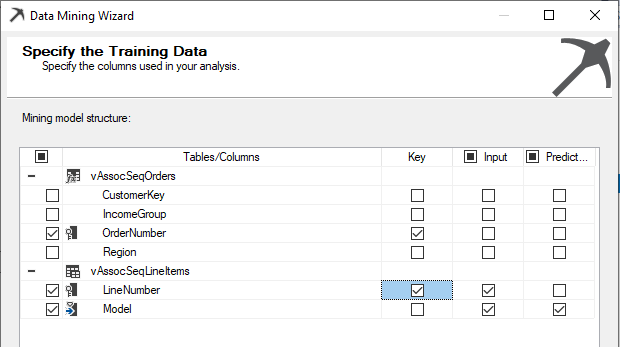
Ideally, we can choose CustomerKey as the key, but in this example, we do not have adequate data for the above case.
理想情况下,我们可以选择CustomerKey作为键,但是在此示例中,对于上述情况,我们没有足够的数据。
In the next couple of screens, default values are accepted.
在接下来的两个屏幕中,将接受默认值。
From the algorithm, it is identified that the Line Number is the Key Sequence as shown in the above screenshot.
根据算法,可以确定行号是键序列,如上面的屏幕截图所示。
After the project is created, then the mining model has to be processed. After the model is processed successfully, the next is to view the results.
创建项目后,必须处理挖掘模型。 成功处理模型后,下一步是查看结果。
挖掘模型查看器 (Mining Model Viewer)
In the Microsoft Sequence Clustering, there is an additional view called State Transition than to the Microsoft Clustering Model viewers. Let us look at each viewer.
在Microsoft序列群集中,除了Microsoft群集模型查看器外,还有一个称为状态转换的视图。 让我们看看每个观众。
集群图 (Cluster Diagram)
Since we have not limited the number of clusters, 15 clusters were defined. Clusters are named with default values that can be modified by looking at the cluster properties.
由于我们没有限制群集的数量,因此定义了15个群集。 群集以默认值命名,可以通过查看群集属性对其进行修改。
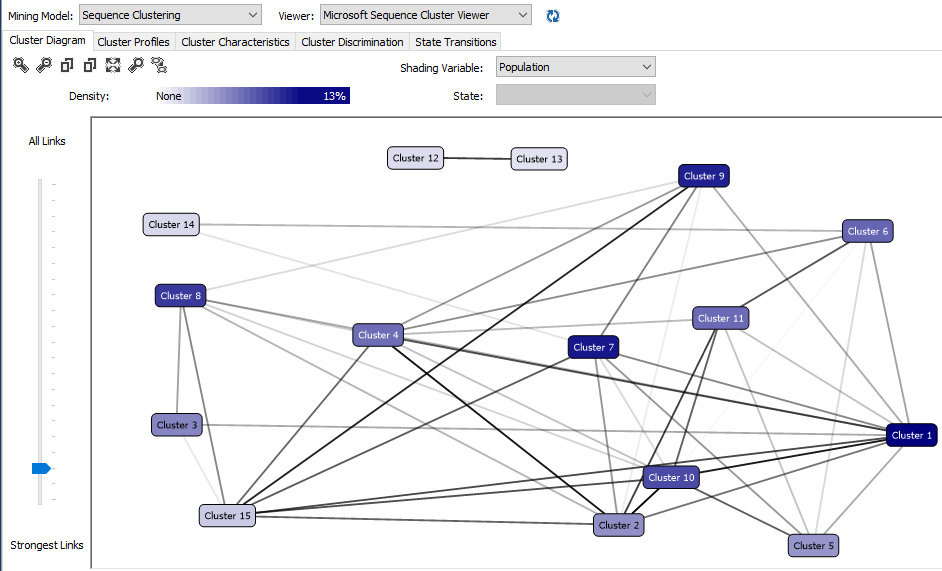
After renaming the clustering to more understandable names, the cluster diagram is visualized like follows.
将聚类重命名为更易理解的名称后,聚类图如下所示。
集群配置文件 (Cluster Profiles)
In the cluster profile view, you can view all the cluster state and the transition in one view as shown below.
在集群配置文件视图中,您可以在一个视图中查看所有集群状态和转换,如下所示。
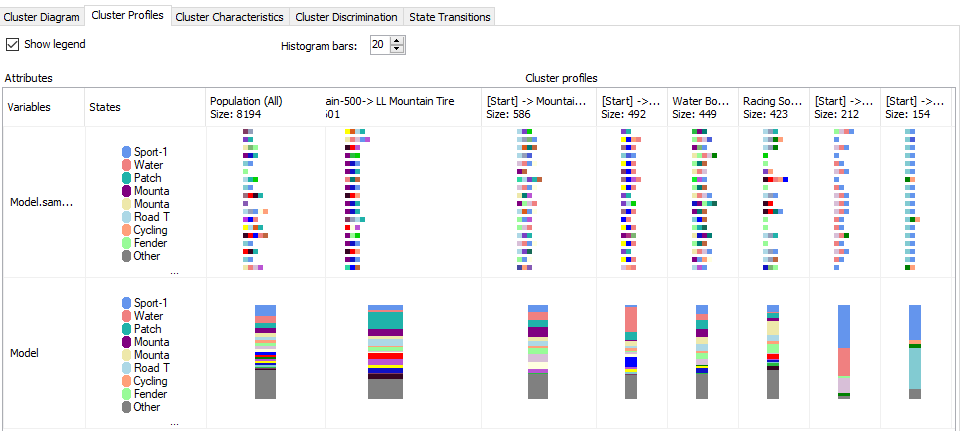
Since we have renamed the cluster names, those names are reflected in this view as well as in other views.
由于我们已经重命名了集群名称,因此这些名称将反映在该视图以及其他视图中。
集群特征 (Cluster Characteristics)
Cluster profiles view gives you a whole view of the clusters whereas the cluster characteristics view gives you details about each cluster. In the Cluster Characteristics view, you can view the details of the entire population as well as the selected cluster.
群集配置文件视图为您提供了群集的整体视图,而群集特征视图为您提供了有关每个群集的详细信息。 在“群集特征”视图中,您可以查看整个种群以及所选群集的详细信息。
The following screenshot shows the cluster characteristics for a selected cluster.
以下屏幕快照显示了所选集群的集群特征。
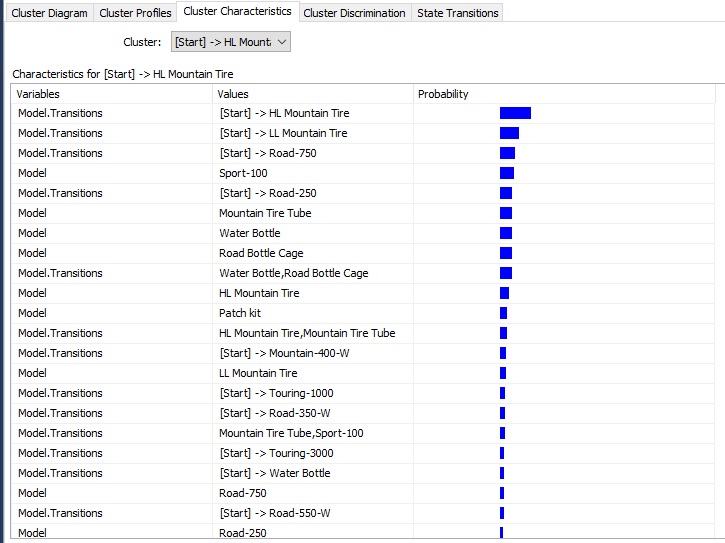
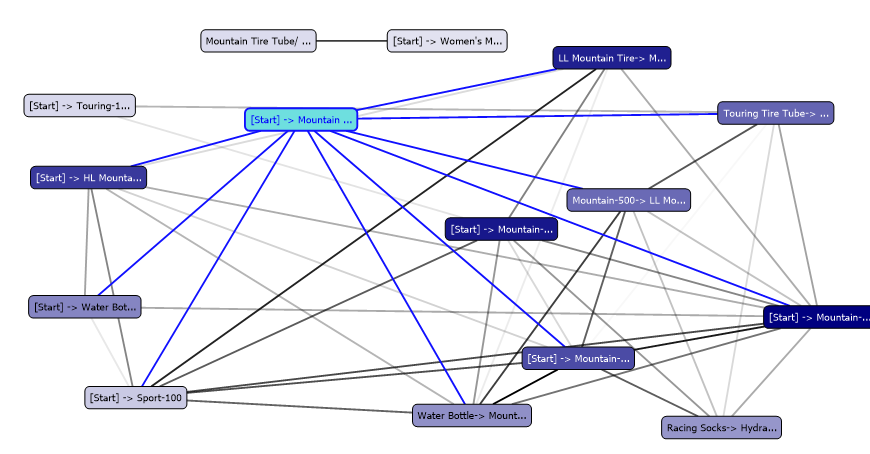
In this cluster, HL Mountain Tire, LL Mountain Tire and Road-750 model are at the start of the sequence. Further, this cluster has a Sport-100 model predominantly.
在该集群中,HL Mountain Tire,LL Mountain Tire和Road-750模型处于序列的开始。 此外,该集群主要具有Sport-100模型。
集群歧视 (Cluster Discrimination)
As always we need to compare between clusters to find out what are differences between the clusters. In the Cluster Discrimination, you can either view differences between two clusters or you can verify the differences between a cluster to all the other rest of the data.
与往常一样,我们需要在集群之间进行比较,以找出集群之间的差异。 在“群集区分”中,您可以查看两个群集之间的差异,也可以验证一个群集与所有其他数据的差异。
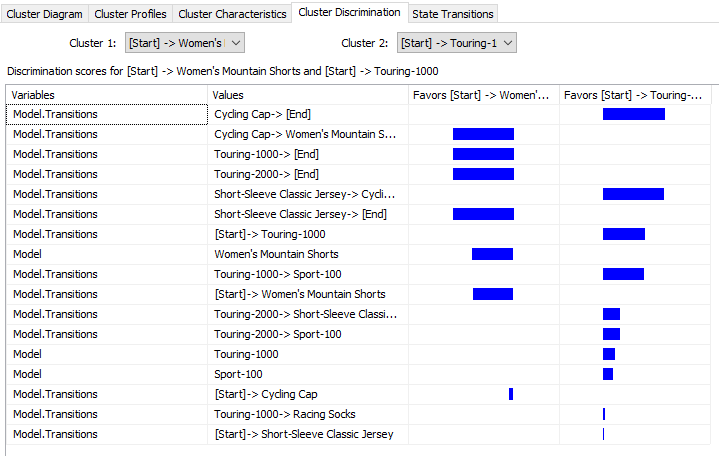
The above screenshot shows that in the first cluster more favors towards the Cycling Cap -> Women’s Mountains Shorts while the second cluster favors ending the sequence with Cycling Cap.
上面的屏幕快照显示,在第一个类别中,更喜欢Cycling Cap-> Women's Mountains Shorts,而在第二个类别中,更喜欢以Cycling Cap结束序列。
状态转换 (State Transitions)
State Transactions view is the only view that is new to the Microsoft Sequence Clustering technique. This view is created by using the Hidden Markov Model.
状态事务视图是Microsoft Sequence Clustering技术中唯一的新视图。 此视图是使用“隐马尔可夫模型”创建的。
Let us analyze a few cases of state transactions from different clusters.
让我们分析来自不同集群的状态交易的几种情况。
In the following state transition diagram, it indicates that the customer buys a water bottle, not as the first choice.
在下面的状态转换图中,它指示客户购买水瓶,而不是首选。
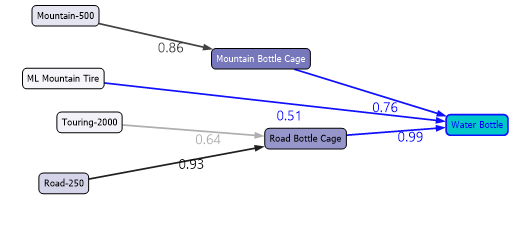
Above screenshot shows that people who buy Road Bottle Cage, there is 0.99 probability of buying a Water Bottle. Similarly, if you are buying Road-250 that there is a probability of 0.93 that buying Road Bottle Cage.
上面的屏幕截图显示,购买“道路水壶架”的人购买水瓶的可能性为0.99。 同样,如果您要购买Road-250,则有0.93的可能性购买Road Bottle Cage。
The following screenshot shows another case. In this case, people who are buying Sport-100, there is a chance that they will buy the same item again to a probability of 0.90.
以下屏幕截图显示了另一种情况。 在这种情况下,购买Sport-100的人可能会再次以0.90的概率购买相同的商品。
The following screenshot has a few more scenarios.
以下屏幕截图还有其他几种情况。
In this cluster, it is evident that customers are buying the same item again. Further, if your client is buying a Touring Tire Tube, there is a 100% probability that he will buy a Touring Tire.
在这个集群中,很明显,顾客正在再次购买同一物品。 此外,如果您的客户要购买房车胎,则有100%的可能性购买房车胎。
型号参数 (Model Parameters)
In Microsoft Sequence Regression there are two important parameters. Those two parameters are CLUSTER_COUNT and MAXIMUM_SEQUENCE_STATES. During the example, we got 15 clusters which are difficult to manage, so we can reduce the cluster count to a manageable number such as 5-8. MAXIMUM_SEQUENCE_STATES define the number of states. The number of states should be around 20-30 maximum. If you are setting this value to a number greater than 100, your model will be meaningless. The default value of this parameter is 64.
在Microsoft序列回归中,有两个重要参数。 这两个参数是CLUSTER_COUNT和MAXIMUM_SEQUENCE_STATES。 在示例中,我们获得了15个难以管理的集群,因此我们可以将集群数量减少到可管理的数量,例如5-8。 MAXIMUM_SEQUENCE_STATES定义状态数。 状态数最多应为20-30个。 如果将此值设置为大于100的数字,则模型将毫无意义。 此参数的默认值为64。
Let us set CLUSTER_COUNT to 5 and MAXIMUM_SEQUENCE_STATES to 8 and reprocess the Microsoft Sequence Cluster Model. Following is the Markov Model for the entire population.
让我们将CLUSTER_COUNT设置为5,将MAXIMUM_SEQUENCE_STATES设置为8,然后重新处理Microsoft序列聚类模型。 以下是整个人群的马尔可夫模型。
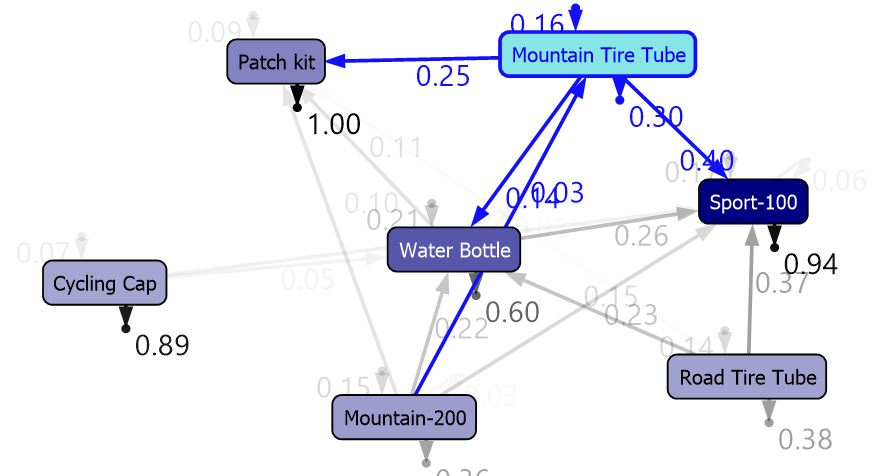
You can see that it is clearer than the previous model.
您可以看到它比以前的模型更清晰。
逻辑回归 (Logistic Regression)
We won’t be doing another article on Microsoft Logistic Regression as it is another variant for Microsoft Neural Network. The only difference is that, in the Logistic Regression, there won’t be any hidden layer as we discussed in the last article.
我们不会再发表有关Microsoft Logistic回归的文章,因为它是Microsoft Neural Network的另一种变体。 唯一的不同是,在Logistic回归中,不会像我们在上一篇文章中讨论的那样存在任何隐藏层。
结论 (Conclusion)
This is the last algorithm of the Microsoft SQL Server family. Microsoft Sequence Clustering in SQL Server is the combination of sequence and clustering techniques. In this technique, common sequences are clustered.
这是Microsoft SQL Server系列的最后一种算法。 SQL Server中的Microsoft序列群集是序列和群集技术的结合。 在这种技术中,公共序列被聚类。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/implementing-sequence-clustering-in-sql-server/
sql server序列














 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









