





sql编程接收一个集合
介绍 (Introduction)
This article is the third and last one of a series of articles that aims to introduce set-based programming approach inside SQL Server, so using Transact SQL. In first article “An introduction to set-based vs procedural programming approaches in T-SQL”, we’ve compared procedural and set-based approaches and came to the conclusion that the second one can facilitate developer or DBA’s life. In second article “From mathematics to SQL Server, a fast introduction to set theory”, we’ve made the parallel between mathematical definition of set theory and its implementation in SQL Server. Now, we’ll discuss about some other features from T-SQL that can’t be left aside when considering sets.
本文是一系列文章的第三篇也是最后一篇,其目的是介绍在SQL Server中使用Transact SQL的基于集合的编程方法。 在第一篇文章“ T-SQL中基于集合的编程方法与过程编程方法的介绍”中 ,我们比较了基于过程的方法和基于集合的方法,得出的结论是第二篇文章可以促进开发人员或DBA的生活。 在第二篇文章“从数学到SQL Server,对集合论的快速介绍”中 ,我们对集合论的数学定义与其在SQL Server中的实现进行了并行。 现在,我们将讨论有关T-SQL的其他一些功能,而这些功能在考虑设置时是不能忽略的。
After some reminder from previous articles, we will look at different kinds of ways to combine records in tables using join operations. Then, we will cover a very useful feature called “common tabular expression”. Finally, we will implement or discuss solutions to real life problems.
在前几篇文章中有所提醒之后,我们将研究使用联接操作在表中组合记录的不同方式。 然后,我们将介绍一个非常有用的功能,称为“常用表格表达式”。 最后,我们将实施或讨论针对现实生活问题的解决方案。
提醒以前的文章 (Reminder from previous articles)
A set is defined as a collection of elements.
集合定义为元素的集合。
A finite number of sets can be graphically represented using a Venn diagram.
可以使用维恩图以图形表示有限的集合。
Theoretical examples will use notation A and B for general sets or tables.
理论示例将对通用集或表使用符号A和B。
Following convention will be used for these examples: A is represented by red circle while green circle represents Set B. The results of an operator is the grayscaled parts of those circles.
这些示例将使用以下约定: A用红色圆圈表示,而绿色圆圈表示Set B。 运算符的结果是这些圆圈的灰度部分。
More concrete examples that do not use A and B notation are also provided and built using Microsoft’s AdventureWorks database.
还提供了不使用A和B表示法的更具体的示例,并使用Microsoft的AdventureWorks数据库进行了构建。
A SQL join is an operation that allows row combination from two or more tables.
SQL连接是一项允许从两个或多个表进行行组合的操作。
SQL连接操作 (SQL join operations)
Overview
总览
In the second article of this series “From mathematics to SQL Server, a fast introduction to set theory”, we’ve already seen a cross join operation which generates all possible combinations of the elements of two sets. Actually, this is not the only join operation we can use in SQL Server. In contrast to cross join, these other join operations need the definition of a condition for join operation execution to lead to the addition of a row in its results set. We will refer to this condition as the join condition. Most often, this join condition is built on key columns of tables implied in join operation.
在本系列的第二篇文章“从数学到SQL Server,对集合论的快速介绍”中 ,我们已经看到了交叉连接操作,该操作会生成两个集合元素的所有可能组合。 实际上,这不是我们可以在SQL Server中使用的唯一联接操作。 与交叉联接相反,这些其他联接操作需要为联接操作执行定义条件,以在其结果集中添加一行。 我们将这个条件称为加入条件。 通常,此连接条件建立在连接操作隐含的表的关键列上。
Let’s now consider these other joins.
现在让我们考虑这些其他联接。
The typical join: INNER JOIN
典型的联接:INNER JOIN
The INNER JOIN is a join that only adds to its results set rows of both tables that lead to a true value for its join condition. This join condition is most often an equality condition on key columns.
INNER JOIN是仅将两个表的结果集行添加到其联接条件的真值的联接 。 此连接条件通常是键列上的相等条件。
In T-SQL, it looks like follows:
在T-SQL中,如下所示:
SELECT *
FROM A
INNER JOIN B
ON <join_condition>
Note
注意
It’s sometimes referred to as self-join when a table is “self-joined” to itself.
当表“自身联接”到自身时,有时称为“自我联接”。
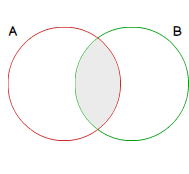
As only records matching join condition in both table are kept, an INNER JOIN can be represented by following figure. Let red circle be the set of records of A and the green one records of B both identified by the columns used in join condition, this operation can be seen as equivalent to the intersection between two sets.
由于仅保留两个表中符合连接条件的记录,因此下图可以表示一个INNER JOIN。 设红色圆圈为A的记录集,绿色的B为一个记录集,两者均由联接条件中使用的列标识,此操作可以看作等效于两组记录之间的交集。
You will find below an example query that returns some person information with its password hash and salt.
您将在下面找到一个示例查询,该查询返回一些带有密码哈希值和盐的人员信息。
SELECT
FirstName,
MiddleName,
LastName,
PasswordHash,
PasswordSalt
FROM Person.Person p
INNER JOIN Person.Password pp
ON pp.BusinessEntityID = p.BusinessEntityID
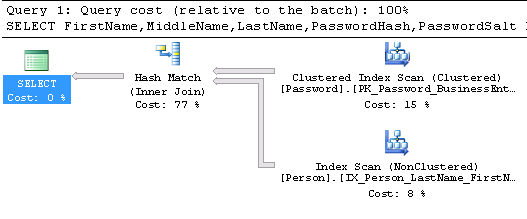
In this case, we only get results for persons defined in both Person and in Password tables. Here is the execution plan associated with the above query:
在这种情况下,我们只会获得在“ 人员”和“ 密码”表中定义的人员的结果。 这是与上述查询关联的执行计划:
LEFT (OUTER) JOIN
左(外)联接
A LEFT OUTER JOIN operation between table A and table B is a join that produces a set made up with rows of table A in conjunction with the matching rows of table B when join condition is met, i.e. when the value of join condition lead to a true value for those rows. For rows from table B that do not match join condition, SQL Server will set NULL values for columns from table B and append them to non-matching rows from the table A then add them to the results of this join operation.
表A和表B之间的LEFT OUTER JOIN操作是一种联接,当满足联接条件时,即当联接条件的值导致a时,将产生一个由表A的行与表B的匹配行组成的集合。这些行的真实值。 对于表B中不符合联接条件的行,SQL Server将为表B中的列设置NULL值,并将它们附加到表A中的不匹配行中,然后将它们添加到此联接操作的结果中。
We will use following notation to use this join.
我们将使用以下表示法来使用此联接。
SELECT *
FROM A
LEFT JOIN B
ON <join_condition>
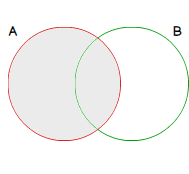
As all records from table A will be found as part of the results of a LEFT JOIN operation, it can be represented as follows:
由于表A中的所有记录都将作为LEFT JOIN操作的结果的一部分,因此可以表示为:
In AdventureWorks database, if we want to get all business entities and get persons information based on the value of BusinessEntityId column, we could get records with data from BusinessEntity table and NULL value for other columns.
在AdventureWorks数据库中,如果要基于BusinessEntityId列的值获取所有业务实体并获取人员信息,则可以从BusinessEntity表中获取包含数据的记录,而对于其他列则获取NULL值。
SELECT *
FROM Person.BusinessEntity be
left join Person.Person p
on be.BusinessEntityID = p.BusinessEntityID
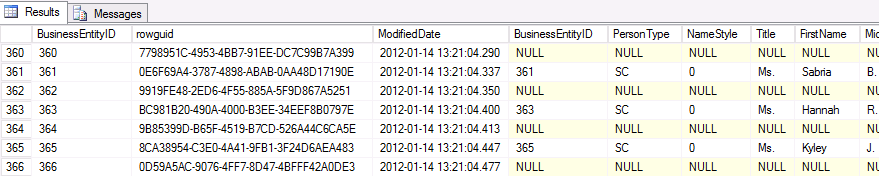
Sample results of this query:
该查询的样本结果:
RIGHT OUTER JOIN
右外连接
The right outer join operation is the same as left outer join except that roles of tables are reversed: it takes from rows from the table B and appends columns from the table A when matching join condition and NULL otherwise.
右外部联接操作与左外部联接相同,除了表的角色相反:它在匹配联接条件时取自表B的行,并从表A追加列,否则为NULL。
We use this operator as follows:
我们按如下方式使用此运算符:
SELECT *
FROM A
RIGHT JOIN B
ON <join_condition>
As all key columns from table B used in join condition will be in results set, it can be represented as this:
由于连接条件中使用的表B中的所有关键列都将在结果集中,因此可以表示为:
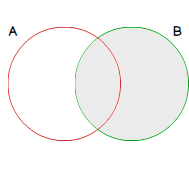
FULL OUTER JOIN
全外连接
A FULL OUTER JOIN is the combination or the UNION (see second article of the series) of a LEFT OUTER JOIN and a RIGHT OUTER JOIN. For this reason, we will get both matching and non-matching rows from both tables.
FULL OUTER JOIN是LEFT OUTER JOIN和RIGHT OUTER JOIN的组合或UNION(请参阅本系列的第二篇文章)。 因此,我们将从两个表中同时获得匹配和不匹配的行。
We could represent the results set of FULL OUTER JOIN operation as follows:
我们可以如下表示FULL OUTER JOIN操作的结果集:
常用表格表达式(CTE) (Common tabular expressions (CTE))
Overview
总览
Common tabular expression or CTE is a feature introduced in SQL Server since its 2005 version. You can think of it as a temporary results set loaded at execution in a single data management T-SQL statement.
自2005版以来,SQL Server中引入了公用表格表达式或CTE。 您可以将其视为在单个数据管理T-SQL语句中执行时加载的临时结果集。
As it’s defined inside a DML statement:
正如在DML语句中定义的那样:
- CTE is not an object and does not need to be created or dropped. CTE不是对象,不需要创建或删除。
- Its data are not kept after statement execution 语句执行后不保留其数据
- Can be referenced, even in itself (self-referencing) 甚至可以被引用(自我引用)
CTE can be used in multiple use cases:
CTE可用于多种用例:
- Replacement for a view 更换视图
- Building a recursive query 建立一个递归查询
- Reference results set of a query multiple times in the same statement 在同一条语句中多次引用查询结果集
- … …
Common tabular expression is an unavoidable element in set-based programming as it defines a set we can use in a statement.
常见的表格表达式在基于集合的编程中是不可避免的元素,因为它定义了我们可以在语句中使用的集合。
We will now have a look at its structure and we will notice directly that it becomes very handy in terms of readability and, de facto, of complex query maintenance.
现在我们来看看它的结构,我们将直接注意到它在可读性以及实际上复杂的查询维护方面变得非常方便。
Structure of a query using CTE
使用CTE的查询结构
A DML query that uses a common tabular expression always starts with the « WITH » keyword followed by a nickname or an alias for CTE’s subquery. Optionally, we can define column names for CTE columns when they will not be defined in a subquery. Then comes CTE’s subquery itself enclosed by parentheses. Note that we can chain CTE by replacing WITH keyword by a comma in subsequent CTE definitions. Finally comes the DML query itself.
使用通用表格表达式的DML查询始终以« WITH »关键字开头,后跟昵称或CTE子查询的别名。 (可选)当子查询中未定义CTE列时,我们可以为其定义列名。 然后是CTE的子查询本身,用括号括起来。 请注意,我们可以通过在后续CTE定义中用逗号替换WITH关键字来链接CTE。 最后是DML查询本身。
In pseudo-code:
用伪代码:
WITH expression_name [ ( column_name [,...n] ) ]
AS (
CTE_query_definition
)
[, Additional_CTE_definitions ]
DML_query
Example usage 1: Non-recursive query
用法示例1:非递归查询
Let’s review our first example. In this example, we will list records from Person table that did not change their password since at least a year.
让我们回顾第一个例子。 在此示例中,我们将列出“ 个人”表中至少一年以来没有更改其密码的记录。
To do it, we will first get the list of passwords with LastModifiedDate column with a value older than 365 days. This can be performed by following query:
为此,我们将首先获取带有LastModifiedDate列的密码列表,该列表的值早于365天。 可以通过以下查询来执行:
SELECT BusinessEntityID, ModifiedDate as LastPwdChangeDate
FROM Person.Password
WHERE DATEDIFF(DAY,ModifiedDate,GETDATE()) > 365
;
Now we have built a query that provides us the set of values of identifiers of interest. We can define this query as a CTE we will call UsersWithOldPassword .
现在,我们已经建立了一个查询,该查询为我们提供了感兴趣的标识符的值集。 我们可以将此查询定义为CTE,我们将其称为UsersWithOldPassword 。
We can now take the list of persons based on the value of BusinessEntityId column from our CTE. To do so, we will use the INNER JOIN operation presented above.
现在,我们可以根据CTE中BusinessEntityId列的值获取人员列表。 为此,我们将使用上面介绍的INNER JOIN操作。
Final query will look like follows:
最终查询将如下所示:
WITH UsersWithOldPassword
AS (
SELECT
BusinessEntityID,
ModifiedDate as LastPwdChangeDate
FROM Person.Password
WHERE DATEDIFF(DAY,ModifiedDate,GETDATE()) > 365
)
SELECT
p.BusinessEntityID,
p.FirstName,
p.MiddleName,
p.LastName,
uwop.LastPwdChangeDate
FROM Person.Person p
INNER JOIN
UsersWithOldPassword uwop
ON p.BusinessEntityID = uwop.BusinessEntityID
This simple example shows the advantages of using CTE: we can create subqueries, test them, then use them to provide final results.
这个简单的示例显示了使用CTE的优势:我们可以创建子查询,对其进行测试,然后使用它们提供最终结果。
Example 2: recursive query
示例2:递归查询
Recursive CTE are very handy to manage the hierarchical relationship between data. You will find below a list of different examples that come to my mind when I talk about recursive CTE:
递归CTE非常方便管理数据之间的层次关系。 您将在下面找到当我谈到递归CTE时想到的不同示例的列表:
- Generate a tree representation of process blocking chain (for DBAs) 生成流程阻塞链的树表示(用于DBA)
- Generate the complete path of a directory from a hierarchically defined DirectoryPath table
- 从分层定义的DirectoryPath表生成目录的完整路径
- Generate a set of ordered numbers 生成一组有序数字
- Generate effective permissions for a given SQL login or database user (for DBAs) 为给定SQL登录名或数据库用户生成有效权限(对于DBA)
- Checking an application user can actually access a resource (when the application uses an authorization system involving roles) 检查应用程序用户是否可以实际访问资源(当应用程序使用涉及角色的授权系统时)
- … …
As you can see, they are many applications to recursive CTE. We won’t review each of them, but we will focus on an example based on AdventureWorks database (for consistency). Details about this example will be explained at the appropriate moment.
如您所见,它们是递归CTE的许多应用程序。 我们不会复习它们中的每一个,但是我们将重点关注基于AdventureWorks数据库的示例(出于一致性考虑)。 有关此示例的详细信息将在适当的时候进行解释。
But before talking about it, you will find hereby the general syntax used to build a recursive common tabular expression:
但是在进行讨论之前,您会发现用于构建递归公用表格表达式的通用语法:
WITH NameOfTheCTE (ColumnA, ColumnB, …)
AS (
QueryDefinition_NoRecursion
UNION ALL
QueryDefinition_WithRecursion -- references NameOfTheCTE.
)
-- Statement using the CTE
SELECT *
FROM NameOfTheCTE
This way of building a recursive CTE reminds me my days at school where we had to demonstrate the formula of a series or recursive sums. We were used to start with a definition of one or more initial values of the series before considering the formula as thesis.
这种建立递归CTE的方式使我想起了我在学校的时候必须证明一系列或递归和的公式。 在将公式视为论文之前,我们通常先定义一个或多个序列的初始值。
Here, it’s kind of the same thing: we will consider sets that do not need recursion to produce results (the Initial Set) then take the union of this initial set with the results from a query that uses the CTE we are defining (the Recursive Call). By the way, we need to tell SQL Server where to stop in its recursion. It’s the recursion stop condition. Finally, we reference the CTE inside the DML query.
在这里,这是一回事:我们将考虑不需要递归生成结果的集(初始集),然后将该初始集与使用我们定义的CTE的查询的结果进行并集(递归呼叫)。 顺便说一句,我们需要告诉SQL Server递归在哪里停止。 这是递归停止条件。 最后,我们在DML查询中引用CTE。
Before diving into the actual example this section, we will take a closer look at an example recursive CTE that generates 30 numbers.
在进入本节的实际示例之前,我们将仔细研究生成30个数字的示例递归CTE。
WITH NumEnum
AS (
SELECT 1 as N -- <----------- INITIAL SET
UNION ALL
SELECT N+1 as N -- <----------- RECURSIVE CALL
FROM NumEnum
WHERE N < 30 -- <----------- RECURSION STOP CONDITION
)
SELECT N -- <----------- CTE INVOCATION
FROM NumEnum
Note
注意
SQL Server limits the depth of recursion. By default, this depth is limited to 100. When this limit is reached, we will get following message:
SQL Server限制了递归的深度。 默认情况下,此深度限制为100。达到此限制时,我们将收到以下消息:
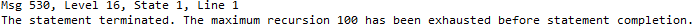
Now, it’s time to explain the example we will use in this section. We will consider Production.Product and Production.BillOfMaterials tables.
现在,是时候解释我们将在本节中使用的示例了。 我们将考虑Production.Product和Production.BillOfMaterials表。
First, let’s review some information about Product table. This information is taken from technet.
首先,让我们回顾一些有关Product表的信息。 此信息来自technet 。
- This table lists information about each product sold by Adventure Works Cycles or used to manufacture Adventure Works Cycles bicycles and bicycle components. 下表列出了Adventure Works Cycles出售的或用于制造Adventure Works Cycles自行车和自行车部件的每种产品的信息。
And now, let’s consider information about BillOfMaterials table:
现在,让我们考虑有关BillOfMaterials表的信息:
- This table lists of all the components used to manufacture bicycles and bicycle subassemblies. 下表列出了用于制造自行车和自行车组件的所有组件。
- The ProductAssemblyID column represents the parent, or primary, product and ComponentID represents the child, or individual, parts used to build the parent assembly.
- ProductAssemblyID列表示父产品或主要产品,而ComponentID列表示用于构建父部件的子零件或单个零件。
- The BOM_Level column indicates the level of the ComponentID relative to the ProductAssemblyID.
- BOM_Level列指示ComponentID相对于ProductAssemblyID的级别。
- An EndDate column with a value means that component stopped being used to assemble product.
- EndDate列的值表示该组件已停止用于组装产品。
So, basically, we can identify a Parent-Child relationship and an application like getting the list of a product sub-assemblies and parts that compose these assemblies.
因此,基本上,我们可以确定父子关系和一个应用程序,例如获取组成这些程序集的产品子程序集和零件的列表。
To do so, we will write a CTE called MaterialDetails. This CTE will be defined with the following columns:
为此,我们将编写一个名为MaterialDetails的CTE。 此CTE将通过以下各列进行定义:
- ProductId 产品编号
- ProductNumber, 产品编号,
- ProductName, 产品名称,
- MaterialQuantity, 材料数量
- ProductColor, 产品颜色
- HierarchyDepth, 层次深度,
- ProductAssemblyId ProductAssemblyId
- ProductNamePath 产品名称路径
So, first part of CTE will be as follows:
因此,CTE的第一部分如下:
WITH MaterialDetails (
ProductId, ProductNumber, ProductName, MaterialQuantity,
ProductColor, HierarchyDepth, ProductAssemblyId, ProductNamePath
)
AS (
Now, let’s build the initial set list. It’s done by getting the list of products that have a row in BillOfMaterials table with no parent assembly, so with ProductAssemblyId column set to NULL. We also need to filter out those materials that are not used anymore in the assembly of the product.
现在,让我们构建初始集合列表。 通过获取在BillOfMaterials表中具有一行且没有父装配的产品列表来完成,因此ProductAssemblyId列设置为NULL 。 我们还需要过滤掉那些在产品组装中不再使用的材料。
Here is the query to do so.
这是这样做的查询。
SELECT
p.ProductID,
p.ProductNumber,
p.Name,
CAST (1 AS DECIMAL (10, 2)),
p.Color,
1,
NULL,
CAST(P.Name AS VARCHAR(128))
FROM
Production.Product AS p
INNER JOIN
Production.BillOfMaterials AS bom
ON
bom.ComponentID = P.ProductID
AND bom.ProductAssemblyID IS NULL
AND (
bom.EndDate IS NULL
OR bom.EndDate > GETDATE()
)
;
Now, we have the initial set. As we will want to cross hierarchy of product assembly, it should be handy to generate a tree view of this hierarchy. To do so, we will append a string per hierarchy level to the name of sub-assembly.
现在,我们有了初始设置。 由于我们将要跨越产品组装的层次结构,因此生成该层次结构的树状视图应该很方便。 为此,我们将每个层次结构级别的字符串附加到子程序集的名称。
So, the recursive call should look like follows:
因此,递归调用应如下所示:
SELECT
-- current product informations
p.ProductID,
p.ProductNumber,
-- hierarchical tree visualization
CAST (REPLICATE(' ', md.HierarchyDepth - 1)
+ '|--- ' + P.Name AS VARCHAR (8000)),
-- current assembly quantity
bom.PerAssemblyQty,
-- current product color (when applicable)
p.Color,
-- we go deeper in hierarchy so...
md.HierarchyDepth + 1,
-- keep reference of current product identifier
md.ProductId,
-- this is for display
CAST(md.ProductNamePath + '\' + p.Name AS varchar(MAX))
FROM
-- take back last recursion results
MaterialDetails AS md
-- retrieve informations about current level of details
INNER JOIN
Production.BillOfMaterials AS bom
ON md.ProductId = bom.ProductAssemblyID
INNER JOIN
Production.Product AS p
on p.ProductID = bom.ComponentID
-- don't forget some parts may not be used anymore
WHERE (
bom.EndDate IS NULL
OR bom.EndDate > GETDATE()
)
The invocation of CTE is pretty easy as it will just be a SELECT statement from that CTE.
CTE的调用非常容易,因为它只是该CTE的SELECT语句。
SELECT
ProductId,
ProductNumber,
ProductName,
MaterialQuantity,
ProductColor,
HierarchyDepth,
ProductAssemblyId,
ProductNamePath
FROM MaterialDetails
Putting all these parts together, CTE will look like this:
将所有这些部分放在一起,CTE将如下所示:
WITH MaterialDetails (
ProductId, ProductNumber, ProductName, MaterialQuantity,
ProductColor, HierarchyDepth, ProductAssemblyId, ProductNamePath
)
AS (
SELECT
p.ProductID,
p.ProductNumber,
CAST(p.Name AS varchar(8000)),
CAST (1 AS DECIMAL (8, 2)),
p.Color,
1,
NULL,
CAST(P.Name AS VARCHAR(MAX))
FROM
Production.Product AS p
INNER JOIN
Production.BillOfMaterials AS bom
ON
bom.ComponentID = P.ProductID
AND bom.ProductAssemblyID IS NULL
AND (
bom.EndDate IS NULL
OR bom.EndDate > GETDATE()
)
UNION ALL
SELECT
-- current product informations
p.ProductID,
p.ProductNumber,
-- hierarchical tree visualization
CAST (REPLICATE(' ', md.HierarchyDepth - 1) + '|--- ' + P.Name AS VARCHAR (8000)),
-- current assembly quantity
bom.PerAssemblyQty,
-- current product color (when applicable)
p.Color,
-- we go deeper in hierarchy so...
md.HierarchyDepth + 1,
-- keep reference of current product identifier
md.ProductId,
-- this is for display
CAST(md.ProductNamePath + '\' + p.Name AS varchar(MAX))
FROM
-- take back last recursion results
MaterialDetails AS md
-- retrieve informations about current level of details
INNER JOIN
Production.BillOfMaterials AS bom
ON md.ProductId = bom.ProductAssemblyID
INNER JOIN
Production.Product AS p
on p.ProductID = bom.ComponentID
-- don't forget some parts may not be used anymore
WHERE (
bom.EndDate IS NULL
OR bom.EndDate > GETDATE()
)
)
SELECT
ProductId,
ProductNumber,
ProductName,
MaterialQuantity,
ProductColor,
HierarchyDepth,
ProductAssemblyId,
ProductNamePath
FROM MaterialDetails
ORDER BY ProductNamePath
;
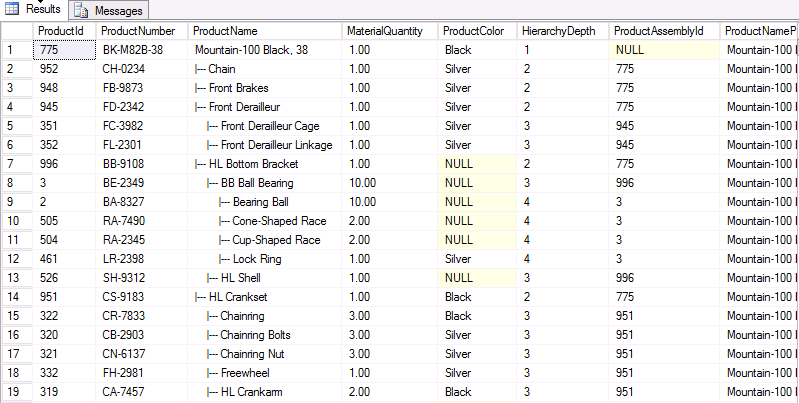
Here is a sample of the results of the query:
这是查询结果的示例:
If we would like to implement this function inside an application using procedural approach, we would have needed to write a lot more code involving at least the use of a cursor for initial step, a loop to read products from that cursor, a temporary table to insert results on the fly and a lot more. We could expect this solution to take so much more time and consume so much more resources compared to set-based solution.
如果我们想使用过程方法在应用程序内部实现此功能,则需要编写更多代码,至少涉及在初始步骤中使用游标,从该游标读取产品的循环,临时表,即时插入结果等等。 与基于集合的解决方案相比,我们可以预期此解决方案将花费更多的时间并消耗更多的资源。
进阶范例 (Advanced examples)
Generate all seconds in a day
每天生成所有秒
I already talked about an example usage for set-based approach which can be used to generate charts for data from your homemade monitoring tool. I use to save disk space and whenever possible, I log only occurrences of an event, not the absence of event with a timestamp corresponding to the moment it occurred.
我已经讨论了基于集合的方法的示例用法,该方法可用于从您的自制监视工具生成数据图表。 我用来节省磁盘空间,并且在可能的情况下,我仅记录事件的发生,而不记录事件的发生,并记录与事件发生的时间相对应的时间戳。
So, I’m used to have tables with following structure:
因此,我习惯于使用具有以下结构的表:
DateStamp DATETIME, <SpecificMonitoredData>
It’s a good candidate to generate charts with time as X axis and either a specific value (like the total RAM used) or the number of occurrences of the event as Y axis.
最好以时间为X轴并以特定值(如使用的总RAM)或事件的发生次数为Y轴来生成图表。
But, as I already explained previously, there can be holes in the data. If we want to plug that hole for a given day, we will use recursive CTE to generate all the X axis values and join them with data from monitoring using an INNER JOIN.
但是,正如我之前已经解释的那样,数据中可能存在漏洞。 如果要在给定的一天塞满该Kong,则将使用递归CTE生成所有X轴值,并将它们与使用INNER JOIN进行监视的数据结合起来。
So, we will have a fixed date in short format (yyyymmdd) and cross join it with a set of 24 numbers from 0 to 23 (for hours) and cross join it with a set of 60 numbers from 0 to 59 (for minutes) and cross join it once more with 60 numbers from 0 to 59 (for seconds).
因此,我们将使用短格式的固定日期(yyyymmdd),并将其与一组24个从0到23的数字进行交叉连接(持续数小时),并将其与一组60个从0到59的数字进行交叉连接(持续数分钟)。并使用0到59之间的60个数字(持续几秒钟)再次交叉连接。
Instead of using former query to generate these numbers, we will use following CTE:
代替使用以前的查询来生成这些数字,我们将使用以下CTE:
WITH NumberCollection (
N
)
AS (
SELECT ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a
CROSS JOIN sys.all_columns b
)
Following query will give you exactly what we need to perform the INNER JOIN with the monitoring history table.
以下查询将为您提供我们需要使用监视历史记录表执行INNER JOIN的确切信息。
WITH DayOfInterest
AS (
SELECT
convert(varchar(8), getdate(), 112) as DateShort
),
NumberCollection (
N
)
AS (
SELECT ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a
CROSS JOIN sys.all_columns b
),
Hourly
AS (
SELECT TOP 24 N from NumberCollection
),
MinuteAndSecondsly
AS (
SELECT TOP 60 N FROM NumberCollection
)
select
DayOfInterest.DateShort,
RIGHT('0000' + CONVERT(varchar(4),Hourly.N),2) AS HourCount,
RIGHT('0000' + CONVERT(varchar(4),Minutely.N),2) AS MinutesCount,
RIGHT('0000' + CONVERT(varchar(4),Secondly.N),2) AS SecondsCount
FROM DayOfInterest,
Hourly,
MinuteAndSecondsly as Minutely,
MinuteAndSecondsly as Secondly
As this generation of all seconds in a day can be time consuming, we could create a TimeDimension table and use it directly in hour developments.
由于一天中所有这种秒的生成可能很耗时,因此我们可以创建一个TimeDimension表并将其直接用于小时开发中。
Generate a calendar table
生成日历表
Calendar table have been explained by Ed Pollack in his articles series which first article is entitled Designing a Calendar Table. In short, it’s a table with dates and some data around dates. While he explains very well this concept, the stored procedure he defined to populate this table is designed using procedural approach. This stored procedure takes two parameters: StartDate and EndDate.
日历表已由Ed Pollack在他的文章系列中进行了解释,该文章系列的第一篇文章名为“ 设计日历表” 。 简而言之,它是一个包含日期和日期周围数据的表格。 尽管他很好地解释了这个概念,但他定义用于填充该表的存储过程是使用过程方法设计的。 该存储过程采用两个参数:StartDate和EndDate。
An alternative to his procedure would use a CTE composed with the definition of NumberCollection and another query that would generate dates between the values of these parameters.
他的过程的另一种选择是使用由NumberCollection的定义组成的CTE,以及另一个将在这些参数的值之间生成日期的查询。
Here is the beginning of a solution:
这是解决方案的开始:
DECLARE @StartDate DATETIME = GETDATE() - 10 ;
DECLARE @EndDate DATETIME = GETDATE() + 10 ;
WITH NumberCollection (
N
)
AS (
SELECT ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a
CROSS JOIN sys.all_columns b
),
NbDaysOfInterest
AS (
SELECT TOP (DATEDIFF(DAY,@StartDate,@EndDate))
N
FROM NumberCollection
),
DatesOfInterest (
DateShort
)
AS (
SELECT CONVERT(VARCHAR(12),@StartDate + N,112)
FROM NbDaysOfInterest
WHERE @StartDate + N <= @EndDate
)
SELECT *
FROM DatesOfInterest
;
摘要 (Summary)
In this series of articles, we’ve seen that we can get benefit to implement solutions to complex problems using set-based programming approach. You will find below a final table with all the different T-SQL commands we’ve reviewed.
在本系列文章中,我们已经看到,使用基于集合的编程方法来实现针对复杂问题的解决方案可以受益匪浅。 您将在最终表下方找到包含我们已审查的所有不同T-SQL命令的表格。
| Procedural Approach | Set-Based Approach |
SELECT and other DML operations, | SELECT and other DML operations, |
| 程序方法 | 基于集合的方法 |
SELECT和其他DML操作, | SELECT和其他DML操作, |
As a final warning, I would like to insist on the fact that set-based programming approach is a very cool way to solve problems but it won’t be the answer to any problems. Instead, we can build “hybrid” solutions that are procedural by design, but really take advantage of set-based approach so that we get the best out of both.
作为最后的警告,我想坚持这样一个事实,即基于集的编程方法是解决问题的一种非常酷的方法,但它不能解决任何问题。 取而代之的是,我们可以设计出按程序设计的“混合”解决方案,但实际上要利用基于集合的方法,以便从两者中获得最大的收益。
进一步阅读 (Further readings)
Previous articles in this series
本系列以前的文章
- An introduction to set-based vs procedural programming approaches in T-SQLT-SQL中基于集合的程序编程方法简介
- From mathematics to SQL Server, a fast introduction to set theory从数学到SQL Server,对集合论的快速介绍
翻译自: https://www.sqlshack.com/t-sql-asset-set-based-programming-approach/
sql编程接收一个集合















 9257
9257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









