





sql 查询数据库索引重建
Poor indexing is one of the top performance killers, and we will focus on them in this article.
索引编制不良是导致性能下降的主要原因之一,在本文中我们将重点介绍它们。
什么是索引? (What are indexes?)
An index is used to speed up data search and SQL query performance. The database indexes reduce the number of data pages that have to be read in order to find the specific record.
索引用于加快数据搜索和SQL查询的性能。 数据库索引减少了为找到特定记录而必须读取的数据页数。
The biggest challenge with indexing is to determine the right ones for each table.
索引的最大挑战是为每个表确定正确的索引。
We will start with explaining clustered and nonclustered indexes.
我们将从解释聚簇索引和非聚簇索引开始。
A table without a clustered index is called a heap, due to its unordered structure. Data in a heap table isn’t sorted, usually the records are added one after another, as they are inserted into the table. They can also be rearranged by the database engine, but again, without a specific order. When you insert a lot of rows into a heap table, the new records are written on data pages without a specific order. Finding a record in a heap table can be compared to finding a specific leaf in a heap of leaves. It is inefficient and requires time.
没有聚簇索引的表由于其无序结构而称为堆。 堆表中的数据不进行排序,通常是在将记录插入表中时,将记录一个接一个地添加。 它们也可以由数据库引擎重新排列,但同样,也无需特定顺序。 当您在堆表中插入很多行时,新记录将以特定顺序写入数据页。 在堆表中查找记录可以与在叶子堆中查找特定叶子进行比较。 它效率低下,需要时间。
A heap can have one or several nonclustered indexes, or no indexes at all.
堆可以具有一个或几个非聚集索引,或者根本没有索引。
A nonclustered index is made only of index pages that contain row locators (pointers) for records in data pages. It doesn’t contain data pages, like clustered indexes.
非聚集索引仅由索引页面组成,这些索引页面包含数据页面中记录的行定位器(指针)。 它不包含数据页,如聚簇索引。
A clustered index organizes table data, so data is queried quicker and more efficiently. A clustered index consists of both index and data pages, while a heap table has no index pages; it consists only of data pages. In other words, it is not just an index, i.e. a pointer to the data row that contains the key value, but it also contains table data. The data in the clustered table is sorted using the values of the columns the clustered index is made of.
聚集索引组织表数据,因此可以更快,更有效地查询数据。 聚集索引由索引和数据页组成,而堆表没有索引页。 它仅包含数据页。 换句话说,它不仅是索引,即指向包含键值的数据行的指针,而且还包含表数据。 聚簇表中的数据使用构成聚簇索引的列的值进行排序。
Finding a record from a table with a proper clustered index is quick and easy like finding a name in an alphabetically ordered list. A general recommendation for all SQL tables is to have a proper clustered index
从具有适当聚集索引的表中查找记录非常容易,就像在按字母顺序排列的列表中查找名称一样。 对于所有SQL表的一般建议是拥有适当的聚集索引
While there can be only one clustered index on a table, a table can have up to 999 nonclustered indexes
虽然表上只能有一个聚集索引,但一个表最多可以有999个非聚集索引
Indexes can be created using T-SQL.
可以使用T-SQL创建索引。
CREATE TABLE [Person].[Address](
[AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[AddressLine1] [nvarchar](60) NOT NULL,
[AddressLine2] [nvarchar](60) NULL,
[City] [nvarchar](30) NOT NULL,
CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED
(
[AddressID] ASC
) ON [PRIMARY]
When you execute the select statement on a clustered table where an ascending clustered index is created, the results will be ordered ascending by the clustered key column. In this example, it’s the AddressID column.
在创建升序聚簇索引的聚簇表上执行select语句时,结果将按聚簇键列升序排列。 在此示例中,它是AddressID列。
The same table, but with a descending clustered index will return the results sorted by the AddressID column descending. To create a descending clustered index, just replace ASC with DESC in code above, so the constraint syntax becomes.
相同的表,但聚集索引为降序,将返回按AddressID列降序排序的结果。 要创建降序聚集索引,只需在上面的代码中将ASC替换为DESC,约束语法就会变成。
CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED
(
[AddressID] DESC
)
The select statement on this table returns the AddressID column sorted descending.
此表上的select语句返回降序排列的AddressID列。
T-SQL code to create a table with a nonclustered index:
使用T-SQL代码创建具有非聚集索引的表:
CREATE TABLE [Person].[Address4](
[AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[AddressLine1] [nvarchar](60) NOT NULL,
[AddressLine2] [nvarchar](60) NULL,
[City] [nvarchar](30) NOT NULL)
CREATE NONCLUSTERED INDEX [IX_Address_StateProvinceID4] ON [Person].[Address4]
(
[AddressID] ASC
) ON [PRIMARY]
When you execute the select statement on a heap table with the same columns and data, the results returned will be unordered.
在具有相同列和数据的堆表上执行select语句时,返回的结果将是无序的。
Besides using T-SQL code to create an index, you can use SQL Server Management Studio. To create an index on an existing table:
除了使用T-SQL代码创建索引外,您还可以使用SQL Server Management Studio。 要在现有表上创建索引:
- Tables node in 对象资源管理器中展开“ Object Explorer表”节点
- Expand the table where you want to create the index and right-click it 展开要在其中创建索引的表,然后右键单击它
- Indexes索引
- New Index新索引
Select Clustered Index or Non-Clustered Index option
选择“ 聚集索引”或“ 非聚集索引”选项
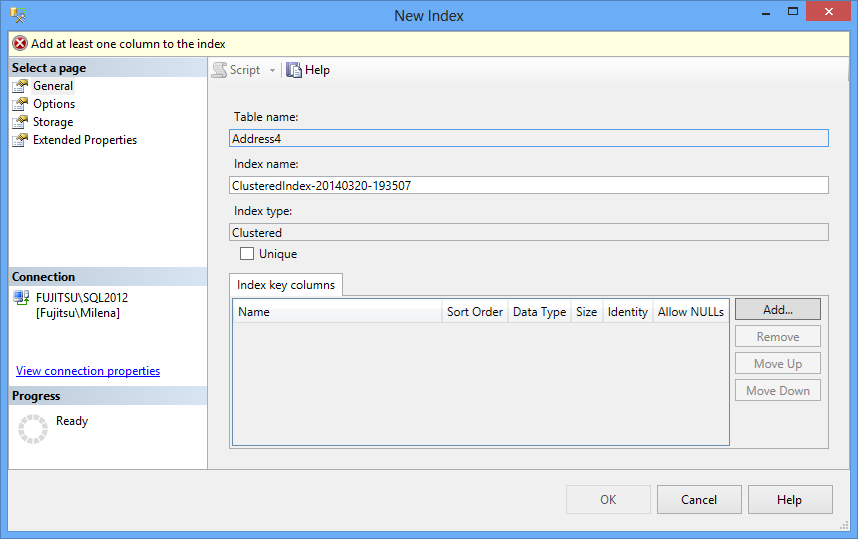
- Clustered Index option, the following dialog is shown. The index name is generated automatically, but it’s not very descriptive, so it’s recommended to change it and add the clustered index column names, e.g. ClusteredIndex_AddressID聚簇索引”选项,则会显示以下对话框。 索引名称是自动生成的,但是描述性不强,因此建议更改它并添加聚簇索引列名称,例如ClusteredIndex_AddressID
Click Add
点击添加
Select the column(s) you want to use as a clustered index
选择要用作聚簇索引的列
- OK. The selected column(s) will be listed in the 确定 。 所选列将列在“ Index key columns list索引键列”列表中
- Unique check box唯一”复选框
- Use other tabs to set index options, storage options, and extended properties 使用其他选项卡设置索引选项,存储选项和扩展属性
When the index in created successfully, it will be listed in the Indexes node for the specific table
成功创建索引后,它将在特定表的“ 索引”节点中列出
The steps are similar for creating a nonclustered index
创建非聚集索引的步骤类似
Another option to create a clustered index on the existing table using SQL Server management Studio is to:
使用SQL Server Management Studio在现有表上创建聚簇索引的另一种方法是:
- Design设计”。
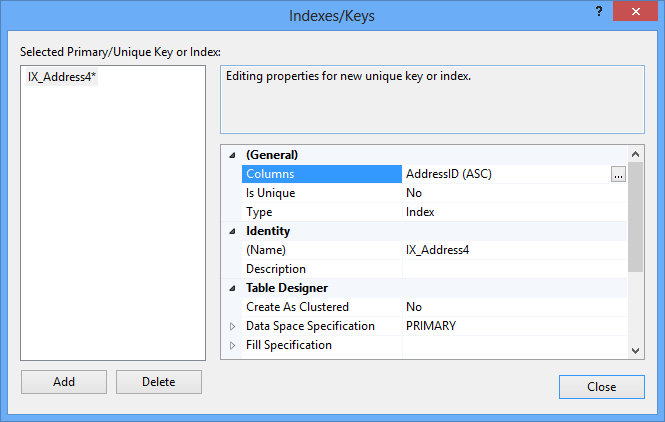
- Indexes/Keys索引/键
Click Add. By default, the identity column is added in the ascending order
点击添加 。 默认情况下,标识列按升序添加
To select another column, click the ellipsis button in the Columns row and select another column and sorting order
要选择另一列,请单击“列”行中的省略号按钮,然后选择另一列和排序顺序
- Create As Clustered column select 作为群集创建”列中,为群集索引选择“ Yes for a clustered index. Leave 是 ”。 保留“ No to create a nonclustered index否”以创建非聚集索引
- Again, it’s recommended to change the automatically created name in the Identity – (Name) row by a more descriptive one
- 同样,建议将“ 身份”((名称))行中自动创建的名称更改为更具描述性的名称
- Close关闭
- Save in the SQL Server management Studio menu to save the index保存 Studio菜单,保存指数
堆或群集SQL表? (Heap or clustered SQL table?)
When searching for a specific record in a heap table, SQL Server has to go through all table rows. This can be acceptable on a table with a small number of records.
在堆表中搜索特定记录时,SQL Server必须遍历所有表行。 这在具有少量记录的表上是可以接受的。
As rows in a heap table are unordered, they are identified by a row identifier (RID) which consists of the file number, page number, and slot number of the row.
由于堆表中的行是无序的,因此它们由行标识符(RID)标识,该标识符由该行的文件号,页号和插槽号组成。
It’s not recommended to use a heap table if you’re going to store a large number of records in the table. SQL query execution on a table with millions of records without a clustered index requires a lot of time. Also, if you need to get a sorted results list, it’s easier to define an ascending or descending clustered index, as shown in the examples above, than to sort the unsorted results set retrieved from a heap table. The same goes for grouping, filtering by a value range.
如果要在表中存储大量记录,则不建议使用堆表。 对具有数百万条记录且没有聚集索引的表执行SQL查询需要大量时间。 另外,如果需要获取排序结果列表,则如上面示例所示,定义升序或降序聚集索引比对从堆表中检索的未排序结果集进行排序更容易。 分组,按值范围过滤也是如此。
In this article, we showed how to create clustered and nonclustered indexes using T-SQL and SQL Server Management Studio options, and pointed out the main differences between a clustered and heap table. In the next part of this article, we will explain what is considered to be bad indexing practice and give recommendations for creating indexes.
在本文中,我们展示了如何使用T-SQL和SQL Server Management Studio选项创建群集索引和非群集索引,并指出了群集表和堆表之间的主要区别。 在本文的下一部分中,我们将解释什么是不良的索引编制实践,并提供有关创建索引的建议。
翻译自: https://www.sqlshack.com/sql-query-performance-killers-understanding-poor-database-indexing/
sql 查询数据库索引重建















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









