





python线程创建线程
Python threading allows you to have different parts of your program run concurrently and can simplify your design. If you’ve got some experience in Python and want to speed up your program using threads, then this tutorial is for you!
Python线程允许您让程序的不同部分同时运行,并可以简化设计。 如果您具有Python的使用经验,并且想使用线程来加速程序,那么本教程非常适合您!
In this article, you’ll learn:
在本文中,您将学习:
- What threads are
- How to create threads and wait for them to finish
- How to use a
ThreadPoolExecutor - How to avoid race conditions
- How to use the common tools that Python
threadingprovides
- 什么是线程
- 如何创建线程并等待它们完成
- 如何使用
ThreadPoolExecutor - 如何避免比赛条件
- 如何使用Python
threading提供的常用工具
This article assumes you’ve got the Python basics down pat and that you’re using at least version 3.6 to run the examples. If you need a refresher, you can start with the Python Learning Paths and get up to speed.
本文假设您已经掌握了Python基础知识,并且至少使用3.6版来运行示例。 如果需要复习,可以从Python学习路径入手,并快速上手。
If you’re not sure if you want to use Python threading, asyncio, or multiprocessing, then you can check out Speed Up Your Python Program With Concurrency.
如果不确定是否要使用Python threading , asyncio或多multiprocessing ,则可以签出“使用并发加速Python程序” 。
All of the sources used in this tutorial are available to you in the Real Python GitHub repo.
在Real Python GitHub存储库中可以使用本教程中使用的所有资源。
Free Bonus: 5 Thoughts On Python Mastery, a free course for Python developers that shows you the roadmap and the mindset you’ll need to take your Python skills to the next level.
免费奖金: 关于Python精通的5个想法 ,这是针对Python开发人员的免费课程,向您展示了将Python技能提升到新水平所需的路线图和心态。
Take the Quiz: Test your knowledge with our interactive “Python Threading” quiz. Upon completion you will receive a score so you can track your learning progress over time:
参加测验:通过我们的交互式“ Python线程”测验测试您的知识。 完成后,您将获得一个分数,因此您可以跟踪一段时间内的学习进度:
什么是线程? (What Is a Thread?)
A thread is a separate flow of execution. This means that your program will have two things happening at once. But the different threads do not actually happen at once: they merely appear to.
线程是单独的执行流程。 这意味着您的程序将同时发生两件事。 但是不同的线程实际上并不会立即发生:它们只是看起来而已。
It’s tempting to think of threading as having two (or more) different processors running on your program, each one doing an independent task at the same time. That’s almost right, but that’s what multiprocessing provides.
将线程视为在程序上运行两个(或多个)不同的处理器,每个处理器同时执行一项独立的任务,这很容易使人感到困惑。 几乎是正确的,但这就是multiprocessing提供的。
threading is similar, but there is only a single processor running your program. The different tasks, called threads, are all run on a single core, with the operating system managing when your program works on which thread.
threading是类似的,但是只有一个处理器在运行您的程序。 不同的任务(称为线程)都在单个内核上运行,由操作系统管理程序在哪个线程上工作的时间。
The best real-world analogy I’ve read is in the intro of Async IO in Python: A Complete Walkthrough, which likens it to a grand-master chess player competing against many opponents at once. It’s all the same grand master, but she needs to switch tasks and maintain where she was (usually called the state) for each game.
我读过的最好的现实世界比喻是Python中的Async IO简介:完整演练 ,它类似于一次与众多对手竞争的国际象棋大师。 都是相同的大师,但是她需要切换任务并保持每场比赛的状态 (通常称为状态 )。
Because threading runs on a single CPU, it is good at speeding up some tasks but not all tasks. Tasks that require heavy CPU computation and spend little time waiting for external events will not run faster with threading, so you should look to multiprocessing instead.
因为threading运行在单个CPU上,所以它擅长加速某些任务,但不是全部任务。 需要大量CPU计算并且花很少时间等待外部事件的任务,使用线程处理不会更快地运行,因此您应该使用multiprocessing 。
Architecting your program to use threading can also provide gains in design clarity. Most of the examples you’ll learn about in this tutorial are not necessarily going to run faster because they use threads. Using threading in them helps to make the design cleaner and easier to reason about.
设计您的程序以使用线程也可以提高设计的清晰度。 您将在本教程中学习的大多数示例不一定会运行得更快,因为它们使用线程。 在其中使用线程有助于使设计更简洁,更易于推理。
So, let’s stop talking about threading and start using it!
因此,让我们停止谈论线程并开始使用它!
启动线程 (Starting a Thread)
Now that you’ve got an idea of what a thread is, let’s learn how to make one. The Python standard library provides threading, which contains most of the primitives you’ll see in this article. Thread, in this module, nicely encapsulates threads, providing a clean interface to work with them.
现在您已经了解了什么是线程,让我们学习如何创建一个线程。 Python标准库提供了threading ,其中包含您将在本文中看到的大多数原语。 在这个模块中, Thread很好地封装了线程,提供了一个干净的接口来使用它们。
To start a separate thread, you create a Thread instance and then tell it to .start():
要启动一个单独的线程,请创建一个Thread实例,然后将其告知.start() :
import import logging
logging
import import threading
threading
import import time
time
def def thread_functionthread_function (( namename ):
):
logginglogging .. infoinfo (( "Thread "Thread %s%s : starting": starting" , , namename )
)
timetime .. sleepsleep (( 22 )
)
logginglogging .. infoinfo (( "Thread "Thread %s%s : finishing": finishing" , , namename )
)
if if __name__ __name__ == == "__main__""__main__" :
:
format format = = "" %(asctime)s%(asctime)s : : %(message)s%(message)s "
"
logginglogging .. basicConfigbasicConfig (( formatformat == formatformat , , levellevel == logginglogging .. INFOINFO ,
,
datefmtdatefmt == "%H:%M:%S""%H:%M:%S" )
)
logginglogging .. infoinfo (( "Main : before creating thread""Main : before creating thread" )
)
x x = = threadingthreading .. ThreadThread (( targettarget == thread_functionthread_function , , argsargs == (( 11 ,))
,))
logginglogging .. infoinfo (( "Main : before running thread""Main : before running thread" )
)
xx .. startstart ()
()
logginglogging .. infoinfo (( "Main : wait for the thread to finish""Main : wait for the thread to finish" )
)
# x.join()
# x.join()
logginglogging .. infoinfo (( "Main : all done""Main : all done" )
)
If you look around the logging statements, you can see that the main section is creating and starting the thread:
如果查看日志记录语句,可以看到main部分正在创建和启动线程:
When you create a Thread, you pass it a function and a list containing the arguments to that function. In this case, you’re telling the Thread to run thread_function() and to pass it 1 as an argument.
创建Thread ,会向其传递一个函数和一个包含该函数参数的列表。 在这种情况下,您要告诉Thread运行thread_function()并将其作为参数传递给1 。
For this article, you’ll use sequential integers as names for your threads. There is threading.get_ident(), which returns a unique name for each thread, but these are usually neither short nor easily readable.
在本文中,您将使用连续整数作为线程的名称。 有threading.get_ident() ,它为每个线程返回一个唯一的名称,但是这些名称通常都不简短也不易于阅读。
thread_function() itself doesn’t do much. It simply logs some messages with a time.sleep() in between them.
thread_function()本身并没有做太多事情。 它只是记录一些消息,并在它们之间带有time.sleep() 。
When you run this program as it is (with line twenty commented out), the output will look like this:
当您按原样运行该程序(注释掉第20行)时,输出将如下所示:
$ ./single_thread.py
$ ./single_thread.py
Main : before creating thread
Main : before creating thread
Main : before running thread
Main : before running thread
Thread 1: starting
Thread 1: starting
Main : wait for the thread to finish
Main : wait for the thread to finish
Main : all done
Main : all done
Thread 1: finishing
Thread 1: finishing
You’ll notice that the Thread finished after the Main section of your code did. You’ll come back to why that is and talk about the mysterious line twenty in the next section.
您会注意到, Thread在代码的Main部分完成之后完成。 您将回到原因所在,并在下一节中讨论神秘的第20行。
守护进程线程 (Daemon Threads)
In computer science, a daemon is a process that runs in the background.
在计算机科学中, daemon是在后台运行的进程。
Python threading has a more specific meaning for daemon. A daemon thread will shut down immediately when the program exits. One way to think about these definitions is to consider the daemon thread a thread that runs in the background without worrying about shutting it down.
Python threading对于daemon具有更具体的含义。 程序退出时, daemon线程将立即关闭。 考虑这些定义的一种方法是将daemon线程视为daemon运行的线程,而不必担心将其关闭。
If a program is running Threads that are not daemons, then the program will wait for those threads to complete before it terminates. Threads that are daemons, however, are just killed wherever they are when the program is exiting.
如果程序运行的不是daemons Threads ,则该程序将在终止之前等待这些线程完成。 但是,当程序退出时,作为守护程序的Threads将被杀死,无论它们位于何处。
Let’s look a little more closely at the output of your program above. The last two lines are the interesting bit. When you run the program, you’ll notice that there is a pause (of about 2 seconds) after __main__ has printed its all done message and before the thread is finished.
让我们更仔细地看一下上面程序的输出。 最后两行是有趣的部分。 当您运行该程序时,您会注意到在__main__打印完all done消息后且线程完成之前有一个暂停(大约2秒)。
This pause is Python waiting for the non-daemonic thread to complete. When your Python program ends, part of the shutdown process is to clean up the threading routine.
此暂停是Python等待非守护线程完成。 当您的Python程序结束时,关闭过程的一部分是清理线程例程。
If you look at the source for Python threading, you’ll see that threading._shutdown() walks through all of the running threads and calls .join() on every one that does not have the daemon flag set.
如果查看Python threading的源代码 ,您会看到threading._shutdown()遍历所有正在运行的线程,并在每个未设置daemon标志的线程上调用.join() 。
So your program waits to exit because the thread itself is waiting in a sleep. As soon as it has completed and printed the message, .join() will return and the program can exit.
因此您的程序等待退出,因为线程本身正在睡眠中。 完成并打印消息后, .join()将返回,程序可以退出。
Frequently, this behavior is what you want, but there are other options available to us. Let’s first repeat the program with a daemon thread. You do that by changing how you construct the Thread, adding the daemon=True flag:
通常,这种行为是您想要的,但是我们还有其他选择。 让我们首先用daemon线程重复该程序。 您可以通过更改构造Thread做到这一点,并添加daemon=True标志:
When you run the program now, you should see this output:
现在运行程序时,应该看到以下输出:
$ ./daemon_thread.py
$ ./daemon_thread.py
Main : before creating thread
Main : before creating thread
Main : before running thread
Main : before running thread
Thread 1: starting
Thread 1: starting
Main : wait for the thread to finish
Main : wait for the thread to finish
Main : all done
Main : all done
The difference here is that the final line of the output is missing. thread_function() did not get a chance to complete. It was a daemon thread, so when __main__ reached the end of its code and the program wanted to finish, the daemon was killed.
此处的区别是输出的最后一行丢失了。 thread_function()没有机会完成。 这是一个daemon线程,因此当__main__到达其代码末尾且程序要完成时,该守护程序被杀死。
join()一个线程 (join() a Thread)
Daemon threads are handy, but what about when you want to wait for a thread to stop? What about when you want to do that and not exit your program? Now let’s go back to your original program and look at that commented out line twenty:
守护程序线程很方便,但是当您要等待线程停止时该怎么办? 如果您想这样做而不退出程序呢? 现在,让我们回到您的原始程序,看看注释掉的第20行:
To tell one thread to wait for another thread to finish, you call .join(). If you uncomment that line, the main thread will pause and wait for the thread x to complete running.
要告诉一个线程等待另一个线程完成,请调用.join() 。 如果取消注释该行,则主线程将暂停并等待线程x完成运行。
Did you test this on the code with the daemon thread or the regular thread? It turns out that it doesn’t matter. If you .join() a thread, that statement will wait until either kind of thread is finished.
您是否使用守护程序线程或常规线程在代码上对此进行了测试? 事实证明,这并不重要。 如果您使用.join()线程,则该语句将等待,直到任何一种线程完成为止。
使用许多线程 (Working With Many Threads)
The example code so far has only been working with two threads: the main thread and one you started with the threading.Thread object.
到目前为止,示例代码仅适用于两个线程:主线程和一个您从threading.Thread对象开始的threading.Thread 。
Frequently, you’ll want to start a number of threads and have them do interesting work. Let’s start by looking at the harder way of doing that, and then you’ll move on to an easier method.
通常,您需要启动多个线程并使它们执行有趣的工作。 让我们先来看一下更困难的方法,然后再继续使用更简单的方法。
The harder way of starting multiple threads is the one you already know:
启动多个线程的较难方式是您已经知道的一种:
import import logging
logging
import import threading
threading
import import time
time
def def thread_functionthread_function (( namename ):
):
logginglogging .. infoinfo (( "Thread "Thread %s%s : starting": starting" , , namename )
)
timetime .. sleepsleep (( 22 )
)
logginglogging .. infoinfo (( "Thread "Thread %s%s : finishing": finishing" , , namename )
)
if if __name__ __name__ == == "__main__""__main__" :
:
format format = = "" %(asctime)s%(asctime)s : : %(message)s%(message)s "
"
logginglogging .. basicConfigbasicConfig (( formatformat == formatformat , , levellevel == logginglogging .. INFOINFO ,
,
datefmtdatefmt == "%H:%M:%S""%H:%M:%S" )
)
threads threads = = listlist ()
()
for for index index in in rangerange (( 33 ):
):
logginglogging .. infoinfo (( "Main : create and start thread "Main : create and start thread %d%d ."." , , indexindex )
)
x x = = threadingthreading .. ThreadThread (( targettarget == thread_functionthread_function , , argsargs == (( indexindex ,))
,))
threadsthreads .. appendappend (( xx )
)
xx .. startstart ()
()
for for indexindex , , thread thread in in enumerateenumerate (( threadsthreads ):
):
logginglogging .. infoinfo (( "Main : before joining thread "Main : before joining thread %d%d ."." , , indexindex )
)
threadthread .. joinjoin ()
()
logginglogging .. infoinfo (( "Main : thread "Main : thread %d%d done" done" , , indexindex )
)
This code uses the same mechanism you saw above to start a thread, create a Thread object, and then call .start(). The program keeps a list of Thread objects so that it can then wait for them later using .join().
此代码使用与上面看到的相同的机制来启动线程,创建Thread对象,然后调用.start() 。 该程序保留Thread对象的列表,以便稍后可以使用.join()等待它们。
Running this code multiple times will likely produce some interesting results. Here’s an example output from my machine:
多次运行此代码可能会产生一些有趣的结果。 这是我的机器的输出示例:
If you walk through the output carefully, you’ll see all three threads getting started in the order you might expect, but in this case they finish in the opposite order! Multiple runs will produce different orderings. Look for the Thread x: finishing message to tell you when each thread is done.
如果仔细浏览输出,您将看到所有三个线程都以您期望的顺序开始,但在这种情况下,它们以相反的顺序完成! 多次运行将产生不同的顺序。 查找“ Thread x: finishing消息以告诉您每个线程何时完成。
The order in which threads are run is determined by the operating system and can be quite hard to predict. It may (and likely will) vary from run to run, so you need to be aware of that when you design algorithms that use threading.
线程的运行顺序由操作系统确定,可能很难预测。 它可能(并且可能会)因运行而异,因此在设计使用线程的算法时需要注意这一点。
Fortunately, Python gives you several primitives that you’ll look at later to help coordinate threads and get them running together. Before that, let’s look at how to make managing a group of threads a bit easier.
幸运的是,Python为您提供了几个原语,您将在稍后查看它们,以帮助协调线程并使它们一起运行。 在此之前,让我们看一下如何简化一组线程的管理。
使用ThreadPoolExecutor (Using a ThreadPoolExecutor)
There’s an easier way to start up a group of threads than the one you saw above. It’s called a ThreadPoolExecutor, and it’s part of the standard library in concurrent.futures (as of Python 3.2).
与上面看到的相比,有一种更简单的方法来启动一组线程。 它被称为ThreadPoolExecutor ,它是concurrent.futures标准库中的标准库的一部分(从Python 3.2开始)。
The easiest way to create it is as a context manager, using the with statement to manage the creation and destruction of the pool.
创建它的最简单方法是作为上下文管理器,使用with语句来管理池的创建和销毁。
Here’s the __main__ from the last example rewritten to use a ThreadPoolExecutor:
这是最后一个使用ThreadPoolExecutor重写的示例中的__main__ :
import import concurrent.futures
concurrent.futures
[[ rest rest of of codecode ]
]
if if __name__ __name__ == == "__main__""__main__" :
:
format format = = "" %(asctime)s%(asctime)s : : %(message)s%(message)s "
"
logginglogging .. basicConfigbasicConfig (( formatformat == formatformat , , levellevel == logginglogging .. INFOINFO ,
,
datefmtdatefmt == "%H:%M:%S""%H:%M:%S" )
)
with with concurrentconcurrent .. futuresfutures .. ThreadPoolExecutorThreadPoolExecutor (( max_workersmax_workers == 33 ) ) as as executorexecutor :
:
executorexecutor .. mapmap (( thread_functionthread_function , , rangerange (( 33 ))
))
The code creates a ThreadPoolExecutor as a context manager, telling it how many worker threads it wants in the pool. It then uses .map() to step through an iterable of things, in your case range(3), passing each one to a thread in the pool.
该代码创建一个ThreadPoolExecutor作为上下文管理器,告诉它在池中需要多少个工作线程。 然后,它使用.map()逐步遍历可迭代的事物,在您的情况下, range(3) ,将每个事物传递给池中的线程。
The end of the with block causes the ThreadPoolExecutor to do a .join() on each of the threads in the pool. It is strongly recommended that you use ThreadPoolExecutor as a context manager when you can so that you never forget to .join() the threads.
with块的末尾使ThreadPoolExecutor对ThreadPoolExecutor每个线程执行.join() 。 强烈建议您在可能的情况下使用ThreadPoolExecutor作为上下文管理器,以免您忘记使用.join()线程。
Note: Using a ThreadPoolExecutor can cause some confusing errors.
注意:使用ThreadPoolExecutor可能会导致一些令人困惑的错误。
For example, if you call a function that takes no parameters, but you pass it parameters in .map(), the thread will throw an exception.
例如,如果调用不带参数的函数,但在.map()传递参数,则线程将引发异常。
Unfortunately, ThreadPoolExecutor will hide that exception, and (in the case above) the program terminates with no output. This can be quite confusing to debug at first.
不幸的是, ThreadPoolExecutor将隐藏该异常,并且(在上述情况下)该程序将终止,没有任何输出。 一开始调试起来可能会很混乱。
Running your corrected example code will produce output that looks like this:
运行正确的示例代码将产生如下所示的输出:
Again, notice how Thread 1 finished before Thread 0. The scheduling of threads is done by the operating system and does not follow a plan that’s easy to figure out.
再次注意Thread 1在Thread 0之前如何完成。 线程的调度是由操作系统完成的,并不遵循容易解决的计划。
比赛条件 (Race Conditions)
Before you move on to some of the other features tucked away in Python threading, let’s talk a bit about one of the more difficult issues you’ll run into when writing threaded programs: race conditions.
在继续介绍Python threading包含的其他功能之前,让我们先谈谈编写线程程序时会遇到的更困难的问题之一: 竞争条件 。
Once you’ve seen what a race condition is and looked at one happening, you’ll move on to some of the primitives provided by the standard library to prevent race conditions from happening.
一旦了解了竞争情况并查看了发生的情况,您将继续使用标准库提供的一些原语,以防止发生竞争情况。
Race conditions can occur when two or more threads access a shared piece of data or resource. In this example, you’re going to create a large race condition that happens every time, but be aware that most race conditions are not this obvious. Frequently, they only occur rarely, and they can produce confusing results. As you can imagine, this makes them quite difficult to debug.
当两个或多个线程访问共享的数据或资源时,可能会发生争用情况。 在此示例中,您将创建一个每次都会发生的大型竞争条件,但请注意,大多数竞争条件并不明显。 通常,它们很少发生,并且可能产生令人困惑的结果。 可以想象,这使它们很难调试。
Fortunately, this race condition will happen every time, and you’ll walk through it in detail to explain what is happening.
幸运的是,这种竞争情况每次都会发生,您将详细介绍它以解释发生了什么。
For this example, you’re going to write a class that updates a database. Okay, you’re not really going to have a database: you’re just going to fake it, because that’s not the point of this article.
对于此示例,您将编写一个更新数据库的类。 好的,您实际上并没有要拥有的数据库:您只是要伪造数据库,因为这不是本文的重点。
Your FakeDatabase will have .__init__() and .update() methods:
您的FakeDatabase将具有.__init__()和.update()方法:
class class FakeDatabaseFakeDatabase :
:
def def __init____init__ (( selfself ):
):
selfself .. value value = = 0
0
def def updateupdate (( selfself , , namename ):
):
logginglogging .. infoinfo (( "Thread "Thread %s%s : starting update": starting update" , , namename )
)
local_copy local_copy = = selfself .. value
value
local_copy local_copy += += 1
1
timetime .. sleepsleep (( 0.10.1 )
)
selfself .. value value = = local_copy
local_copy
logginglogging .. infoinfo (( "Thread "Thread %s%s : finishing update": finishing update" , , namename )
)
FakeDatabase is keeping track of a single number: .value. This is going to be the shared data on which you’ll see the race condition.
FakeDatabase跟踪单个数字: .value 。 这将是共享数据,您将在该数据上查看竞争状况。
.__init__() simply initializes .value to zero. So far, so good.
.__init__()只是将.value初始化为零。 到目前为止,一切都很好。
.update() looks a little strange. It’s simulating reading a value from a database, doing some computation on it, and then writing a new value back to the database.
.update()看起来有些奇怪。 它是在模拟从数据库中读取值,对其进行一些计算,然后将新值写回到数据库中。
In this case, reading from the database just means copying .value to a local variable. The computation is just to add one to the value and then .sleep() for a little bit. Finally, it writes the value back by copying the local value back to .value.
在这种情况下,从数据库中读取仅意味着将.value复制到本地变量。 计算只是在值上加一个,然后在.sleep()上加一点。 最后,它通过将本地值复制回.value来写回该值。
Here’s how you’ll use this FakeDatabase:
这是使用此FakeDatabase :
The program creates a ThreadPoolExecutor with two threads and then calls .submit() on each of them, telling them to run database.update().
该程序创建一个带有两个线程的ThreadPoolExecutor ,然后在每个线程上调用.submit() ,告诉它们运行database.update() 。
.submit() has a signature that allows both positional and named arguments to be passed to the function running in the thread:
.submit()具有一个签名,该签名允许将位置参数和命名参数都传递给线程中运行的函数:
.. submitsubmit (( functionfunction , , ** argsargs , , **** kwargskwargs )
)
In the usage above, index is passed as the first and only positional argument to database.update(). You’ll see later in this article where you can pass multiple arguments in a similar manner.
在上面的用法中,将index作为第一个也是唯一的位置参数传递给database.update() 。 您将在本文后面看到,您可以通过类似的方式传递多个参数。
Since each thread runs .update(), and .update() adds one to .value, you might expect database.value to be 2 when it’s printed out at the end. But you wouldn’t be looking at this example if that was the case. If you run the above code, the output looks like this:
由于每个线程都运行.update() ,并且.update()将一个值添加到.value ,所以您可能希望在最后打印出database.value将其设为2 。 但是,如果是这种情况,您就不会看这个例子。 如果运行上面的代码,则输出如下所示:
You might have expected that to happen, but let’s look at the details of what’s really going on here, as that will make the solution to this problem easier to understand.
您可能已经预料到会发生这种情况,但是让我们看一下这里实际发生的情况的详细信息,因为这将使该问题的解决方案更容易理解。
一线 (One Thread)
Before you dive into this issue with two threads, let’s step back and talk a bit about some details of how threads work.
在深入探讨具有两个线程的问题之前,让我们退后一步,谈谈线程如何工作的一些细节。
You won’t be diving into all of the details here, as that’s not important at this level. We’ll also be simplifying a few things in a way that won’t be technically accurate but will give you the right idea of what is happening.
您不会在这里深入了解所有细节,因为在此级别上这并不重要。 我们还将以技术上不准确的方式简化一些操作,但是会为您提供正确的信息。
When you tell your ThreadPoolExecutor to run each thread, you tell it which function to run and what parameters to pass to it: executor.submit(database.update, index).
当您告诉ThreadPoolExecutor运行每个线程时,您告诉它要运行哪个函数以及要传递给它的参数: executor.submit(database.update, index) 。
The result of this is that each of the threads in the pool will call database.update(index). Note that database is a reference to the one FakeDatabase object created in __main__. Calling .update() on that object calls an instance method on that object.
其结果是池中的每个线程都将调用database.update(index) 。 请注意, database是对在__main__创建的一个FakeDatabase对象的引用。 在该对象上调用.update()在该对象上调用实例方法 。
Each thread is going to have a reference to the same FakeDatabase object, database. Each thread will also have a unique value, index, to make the logging statements a bit easier to read: https://treyhunner.com/2019/03/unique-and-sentinel-values-in-python/
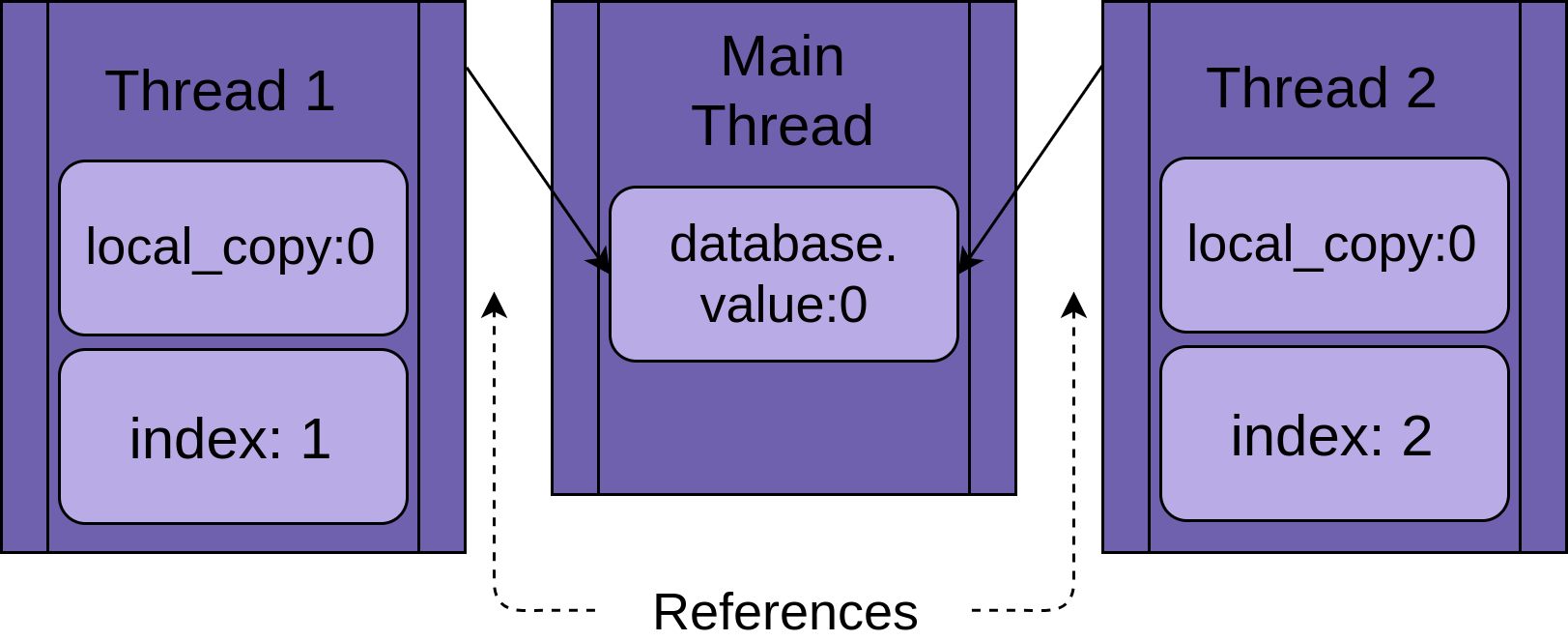
每个线程都将引用相同的FakeDatabase对象database 。 每个线程还将具有唯一值index ,以使日志记录语句更易于阅读:https://treyhunner.com/2019/03/unique-and-sentinel-values-in-python/
When the thread starts running .update(), it has its own version of all of the data local to the function. In the case of .update(), this is local_copy. This is definitely a good thing. Otherwise, two threads running the same function would always confuse each other. It means that all variables that are scoped (or local) to a function are thread-safe.
当线程开始运行.update() ,该函数在函数本地的所有数据中都有其自己的版本。 如果是.update() ,则为local_copy 。 这绝对是一件好事。 否则,运行相同功能的两个线程将始终相互混淆。 这意味着所有作用域(或局部作用域)的变量都是线程安全的 。
Now you can start walking through what happens if you run the program above with a single thread and a single call to .update().
现在,您可以开始.update()了解如果使用单个线程和对.update()的单个调用来运行上述程序,将会发生什么情况。
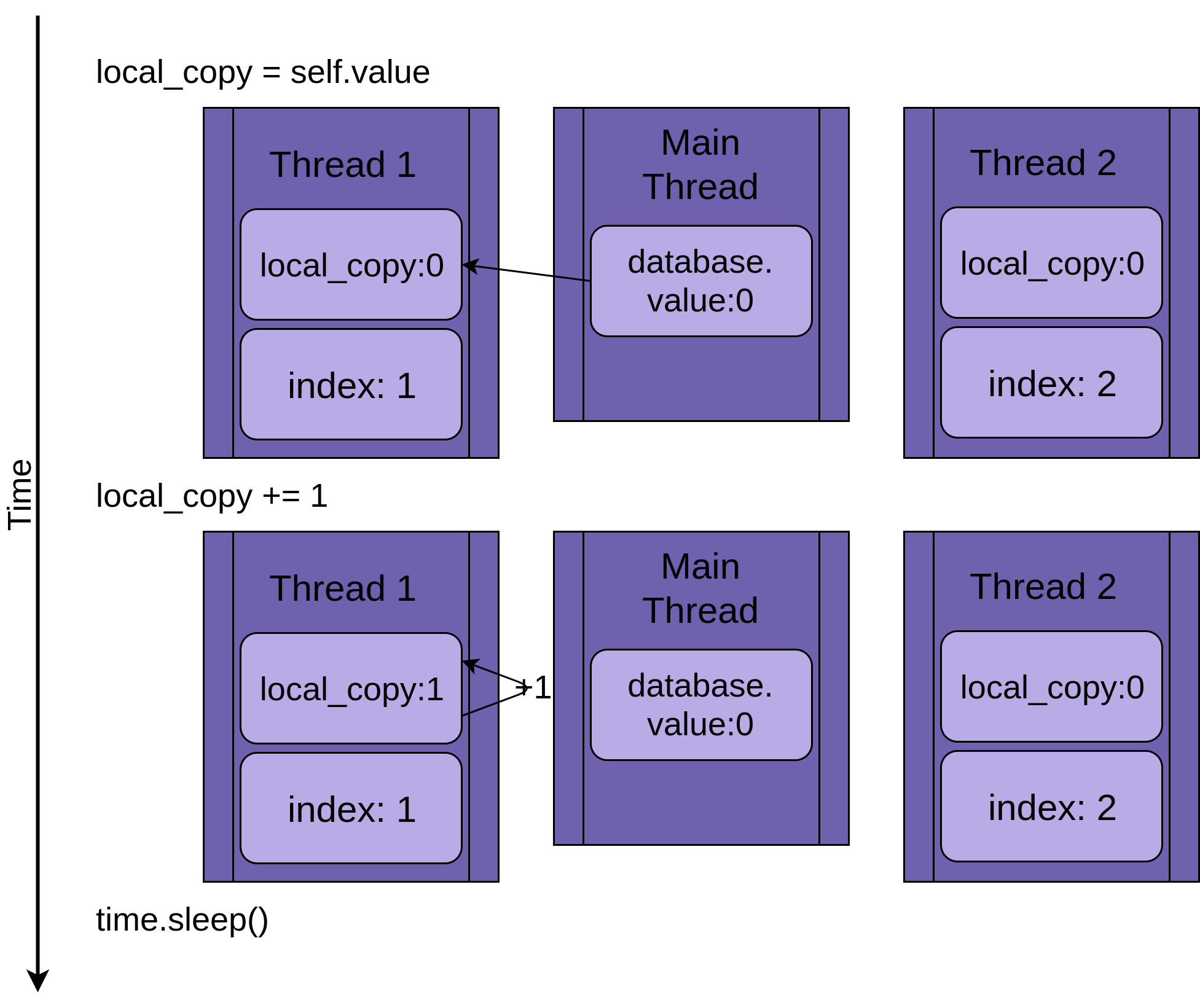
The image below steps through the execution of .update() if only a single thread is run. The statement is shown on the left followed by a diagram showing the values in the thread’s local_value and the shared database.value:
如果仅运行单个线程,则下面的图像逐步执行.update() 。 该语句显示在左侧,然后是一个图,该图显示了线程的local_value和共享的database.value :

The diagram is laid out so that time increases as you move from top to bottom. It begins when Thread 1 is created and ends when it is terminated.
该图的布局使您从上到下移动的时间越来越长。 它在创建Thread 1时开始,在Thread 1终止时结束。
When Thread 1 starts, FakeDatabase.value is zero. The first line of code in the method, local_copy = self.value, copies the value zero to the local variable. Next it increments the value of local_copy with the local_copy += 1 statement. You can see .value in Thread 1 getting set to one.
当Thread 1启动时, FakeDatabase.value为零。 方法的第一行代码local_copy = self.value ,将值零复制到局部变量。 接下来,它使用local_copy += 1语句增加local_copy的值。 您可以看到Thread 1 .value设置为1。
Next time.sleep() is called, which makes the current thread pause and allows other threads to run. Since there is only one thread in this example, this has no effect.
下次time.sleep() ,它将使当前线程暂停并允许其他线程运行。 由于在此示例中只有一个线程,因此没有任何效果。
When Thread 1 wakes up and continues, it copies the new value from local_copy to FakeDatabase.value, and then the thread is complete. You can see that database.value is set to one.
当Thread 1唤醒并继续执行时,它将新值从local_copy到FakeDatabase.value ,然后该线程完成。 您可以看到database.value设置为1。
So far, so good. You ran .update() once and FakeDatabase.value was incremented to one.
到目前为止,一切都很好。 您运行一次.update() ,并且FakeDatabase.value增加到一个。
两个线程 (Two Threads)
Getting back to the race condition, the two threads will be running concurrently but not at the same time. They will each have their own version of local_copy and will each point to the same database. It is this shared database object that is going to cause the problems.
回到竞争状态,两个线程将同时运行,但不能同时运行。 他们每个人都有自己的local_copy版本,并且每个人都指向同一个database 。 正是这个共享database对象将导致问题。
The program starts with Thread 1 running .update():
该程序从运行.update() Thread 1开始:
When Thread 1 calls time.sleep(), it allows the other thread to start running. This is where things get interesting.
当Thread 1调用time.sleep() ,它允许另一个线程开始运行。 这就是事情变得有趣的地方。
Thread 2 starts up and does the same operations. It’s also copying database.value into its private local_copy, and this shared database.value has not yet been updated:
Thread 2启动并执行相同的操作。 它还local_copy database.value复制到其私有的local_copy ,并且此共享的database.value尚未更新:

When Thread 2 finally goes to sleep, the shared database.value is still unmodified at zero, and both private versions of local_copy have the value one.
当Thread 2最终进入睡眠状态时,共享的database.value仍未local_copy为零,并且local_copy两个私有版本的值local_copy 1。
Thread 1 now wakes up and saves its version of local_copy and then terminates, giving Thread 2 a final chance to run. Thread 2 has no idea that Thread 1 ran and updated database.value while it was sleeping. It stores its version of local_copy into database.value, also setting it to one:
现在, Thread 1唤醒并保存其版本的local_copy ,然后终止,从而为Thread 2了最终运行的机会。 Thread 2不知道Thread 1在睡眠时运行并更新了database.value 。 它将local_copy版本存储到database.value , local_copy其设置为一个:
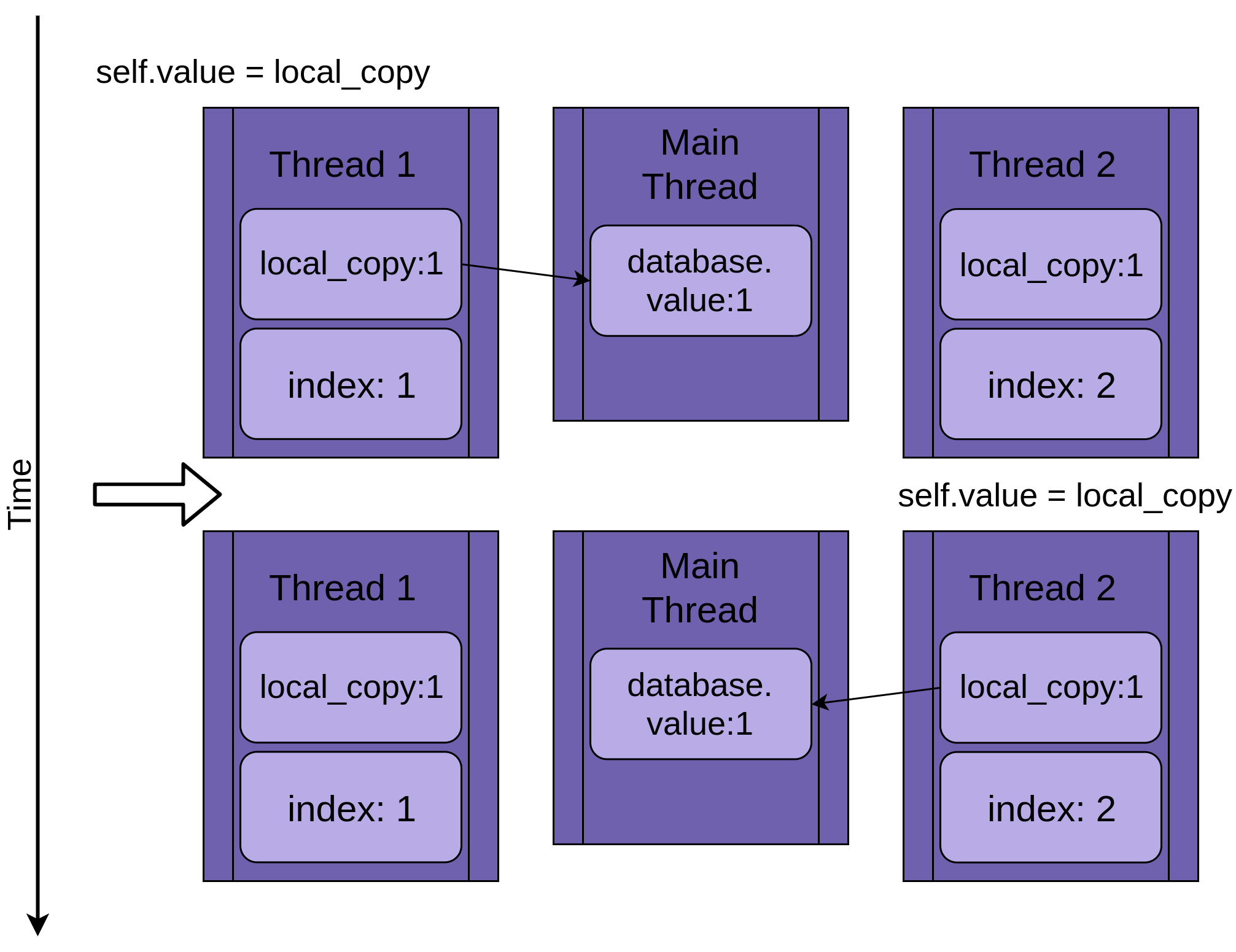
The two threads have interleaving access to a single shared object, overwriting each other’s results. Similar race conditions can arise when one thread frees memory or closes a file handle before the other thread is finished accessing it.
这两个线程可以对单个共享对象进行交错访问,从而覆盖彼此的结果。 当一个线程在另一线程完成访问之前释放内存或关闭文件句柄时,可能会发生类似的竞争情况。
为什么这不是一个愚蠢的例子 (Why This Isn’t a Silly Example)
The example above is contrived to make sure that the race condition happens every time you run your program. Because the operating system can swap out a thread at any time, it is possible to interrupt a statement like x = x+1 after it has read the value of x but before it has written back the incremented value.
上面的示例旨在确保每次运行程序时都发生竞争情况。 因为操作系统可以随时换出线程,所以在读取x的值之后但在回写递增的值之前,可以中断x = x+1类的语句。
The details of how this happens are quite interesting, but not needed for the rest of this article, so feel free to skip over this hidden section.
这种情况的发生方式的细节非常有趣,但本文其余部分并不需要,因此可以跳过该隐藏部分。
The code above isn’t quite as out there as you might originally have thought. It was designed to force a race condition every time you run it, but that makes it much easier to solve than most race conditions.
上面的代码并不像您最初想象的那样。 它旨在在每次运行时强制出现竞争条件,但这比大多数竞争条件要容易得多。
There are two things to keep in mind when thinking about race conditions:
在考虑比赛条件时,要记住两件事:
-
Even an operation like
x += 1takes the processor many steps. Each of these steps is a separate instruction to the processor. -
The operating system can swap which thread is running at any time. A thread can be swapped out after any of these small instructions. This means that a thread can be put to sleep to let another thread run in the middle of a Python statement.
甚至
x += 1类的操作也需要处理器执行许多步骤。 这些步骤中的每一个都是对处理器的单独指令。操作系统可以随时交换正在运行的线程。 这些小指令中的任何一条都可以换出一个线程。 这意味着可以将一个线程置于睡眠状态,以使另一个线程在Python语句的中间运行。
Let’s look at this in detail. The REPL below shows a function that takes a parameter and increments it:
让我们详细看一下。 下面的REPL显示了一个接受参数并将其递增的函数:
>>> def inc(x):
... x += 1
...
>>> import dis
>>> dis.dis(inc)
2 0 LOAD_FAST 0 (x)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (x)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
The REPL example uses dis from the Python standard library to show the smaller steps that the processor does to implement your function. It does a LOAD_FAST of the data value x, it does a LOAD_CONST 1, and then it uses the INPLACE_ADD to add those values together.
REPL示例使用Python标准库中的dis来显示处理器为实现您的功能所做的较小步骤。 它确实LOAD_FAST数据值的x时,它调用LOAD_CONST 1 ,然后它使用INPLACE_ADD这些值相加。
We’re stopping here for a specific reason. This is the point in .update() above where time.sleep() forced the threads to switch. It is entirely possible that, every once in while, the operating system would switch threads at that exact point even without sleep(), but the call to sleep() makes it happen every time.
我们出于特定原因在此停止。 这是.update()上方的时间点,其中.update() time.sleep()强制线程进行切换。 很有可能每隔一段时间,即使没有sleep() ,操作系统也会在那个确切的时间点切换线程,但是对sleep()的调用使它每次都发生。
As you learned above, the operating system can swap threads at any time. You’ve walked down this listing to the statement marked 4. If the operating system swaps out this thread and runs a different thread that also modifies x, then when this thread resumes, it will overwrite x with an incorrect value.
如上所学,操作系统可以随时交换线程。 您已将此清单转到标记为4的语句。 如果操作系统换出该线程并运行另一个也修改x线程,则当该线程恢复时,它将使用不正确的值覆盖x 。
Technically, this example won’t have a race condition because x is local to inc(). It does illustrate how a thread can be interrupted during a single Python operation, however. The same LOAD, MODIFY, STORE set of operations also happens on global and shared values. You can explore with the dis module and prove that yourself.
从技术上讲,此示例不会出现争用条件,因为x是inc()局部inc() 。 它确实说明了如何在单个Python操作期间中断线程。 相同的LOAD,MODIFY,STORE操作集也发生在全局值和共享值上。 您可以使用dis模块进行探索并证明自己。
It’s rare to get a race condition like this to occur, but remember that an infrequent event taken over millions of iterations becomes likely to happen. The rarity of these race conditions makes them much, much harder to debug than regular bugs.
这种情况很少发生,但是要记住,发生在数百万次迭代中的罕见事件很可能会发生。 这些争用条件的稀有性使其比常规错误难以调试。
Now back to your regularly scheduled tutorial!
现在回到您定期安排的教程!
Now that you’ve seen a race condition in action, let’s find out how to solve them!
现在,您已经看到了运行中的竞赛条件,让我们找出解决方法!
使用Lock基本同步 (Basic Synchronization Using Lock)
There are a number of ways to avoid or solve race conditions. You won’t look at all of them here, but there are a couple that are used frequently. Let’s start with Lock.
有许多避免或解决比赛条件的方法。 您不会在这里看到所有这些信息,但是有一些经常使用。 让我们从Lock开始。
To solve your race condition above, you need to find a way to allow only one thread at a time into the read-modify-write section of your code. The most common way to do this is called Lock in Python. In some other languages this same idea is called a mutex. Mutex comes from MUTual EXclusion, which is exactly what a Lock does.
要解决上述竞争条件,您需要找到一种方法,一次只允许一个线程进入代码的read-modify-write部分。 最常见的方法是在Python中Lock 。 在其他一些语言中,相同的想法称为mutex 。 Mutex来自互斥,这正是Lock所做的。
A Lock is an object that acts like a hall pass. Only one thread at a time can have the Lock. Any other thread that wants the Lock must wait until the owner of the Lock gives it up.
Lock是一个像大厅通道一样的对象。 一次只能有一个线程具有Lock 。 想要的任何其他线程Lock必须等到所有者Lock给它了。
The basic functions to do this are .acquire() and .release(). A thread will call my_lock.acquire() to get the lock. If the lock is already held, the calling thread will wait until it is released. There’s an important point here. If one thread gets the lock but never gives it back, your program will be stuck. You’ll read more about this later.
做到这一点的基本功能是.acquire()和.release() 。 线程将调用my_lock.acquire()获取锁。 如果已经持有该锁,则调用线程将等待直到释放它。 这里有一个重点。 如果一个线程获得了锁,但从未将其交还,则程序将被卡住。 稍后您将详细了解。
Fortunately, Python’s Lock will also operate as a context manager, so you can use it in a with statement, and it gets released automatically when the with block exits for any reason.
幸运的是,Python的Lock还将充当上下文管理器,因此您可以在with语句中使用它,并且由于任何原因退出with块时,它将自动释放。
Let’s look at the FakeDatabase with a Lock added to it. The calling function stays the same:
让我们看一下添加了Lock的FakeDatabase 。 调用函数保持不变:
class class FakeDatabaseFakeDatabase :
:
def def __init____init__ (( selfself ):
):
selfself .. value value = = 0
0
selfself .. _lock _lock = = threadingthreading .. LockLock ()
()
def def locked_updatelocked_update (( selfself , , namename ):
):
logginglogging .. infoinfo (( "Thread "Thread %s%s : starting update": starting update" , , namename )
)
logginglogging .. debugdebug (( "Thread "Thread %s%s about to lock" about to lock" , , namename )
)
with with selfself .. _lock_lock :
:
logginglogging .. debugdebug (( "Thread "Thread %s%s has lock" has lock" , , namename )
)
local_copy local_copy = = selfself .. value
value
local_copy local_copy += += 1
1
timetime .. sleepsleep (( 0.10.1 )
)
selfself .. value value = = local_copy
local_copy
logginglogging .. debugdebug (( "Thread "Thread %s%s about to release lock" about to release lock" , , namename )
)
logginglogging .. debugdebug (( "Thread "Thread %s%s after release" after release" , , namename )
)
logginglogging .. infoinfo (( "Thread "Thread %s%s : finishing update": finishing update" , , namename )
)
Other than adding a bunch of debug logging so you can see the locking more clearly, the big change here is to add a member called ._lock, which is a threading.Lock() object. This ._lock is initialized in the unlocked state and locked and released by the with statement.
除了添加一堆调试日志以便您可以更清楚地看到锁定之外,这里的最大变化是添加了一个名为._lock的成员,该成员是threading.Lock()对象。 该._lock初始化为解锁状态,并通过with语句锁定和释放。
It’s worth noting here that the thread running this function will hold on to that Lock until it is completely finished updating the database. In this case, that means it will hold the Lock while it copies, updates, sleeps, and then writes the value back to the database.
在这里值得注意的是,运行此功能的线程将一直保持该Lock直到完全完成更新数据库为止。 在这种情况下,这意味着它将在复制,更新,Hibernate然后将值写回数据库时保持Lock 。
If you run this version with logging set to warning level, you’ll see this:
如果您在将此日志记录设置为警告级别的情况下运行此版本,则会看到以下内容:
Look at that. Your program finally works!
看那个。 您的程序终于可以工作了!
You can turn on full logging by setting the level to DEBUG by adding this statement after you configure the logging output in __main__:
在__main__配置日志记录输出后,可以通过添加以下语句将级别设置为DEBUG来打开完整日志记录:
logginglogging .. getLoggergetLogger ()() .. setLevelsetLevel (( logginglogging .. DEBUGDEBUG )
)
Running this program with DEBUG logging turned on looks like this:
在打开DEBUG日志的情况下运行该程序,如下所示:
In this output you can see Thread 0 acquires the lock and is still holding it when it goes to sleep. Thread 1 then starts and attempts to acquire the same lock. Because Thread 0 is still holding it, Thread 1 has to wait. This is the mutual exclusion that a Lock provides.
在此输出中,您可以看到Thread 0获取了该锁,并且在进入睡眠状态时仍保持该锁。 然后, Thread 1启动并尝试获取相同的锁。 因为Thread 0仍在保留它,所以Thread 1必须等待。 这是Lock提供的互斥。
Many of the examples in the rest of this article will have WARNING and DEBUG level logging. We’ll generally only show the WARNING level output, as the DEBUG logs can be quite lengthy. Try out the programs with the logging turned up and see what they do.
本文其余部分中的许多示例都将具有WARNING和DEBUG级别的日志记录。 我们通常只显示WARNING级别的输出,因为DEBUG日志可能很长。 尝试打开日志记录的程序,然后查看它们的作用。
僵局 (Deadlock)
Before you move on, you should look at a common problem when using Locks. As you saw, if the Lock has already been acquired, a second call to .acquire() will wait until the thread that is holding the Lock calls .release(). What do you think happens when you run this code:
在继续之前,您应该查看使用Locks时的常见问题。 如您所见,如果已经获取了Lock ,则对.acquire()的第二次调用将等待,直到持有Lock的线程调用.release() 。 运行此代码时,您会怎么想:
import import threading
threading
l l = = threadingthreading .. LockLock ()
()
printprint (( "before first acquire""before first acquire" )
)
ll .. acquireacquire ()
()
printprint (( "before second acquire""before second acquire" )
)
ll .. acquireacquire ()
()
printprint (( "acquired lock twice""acquired lock twice" )
)
When the program calls l.acquire() the second time, it hangs waiting for the Lock to be released. In this example, you can fix the deadlock by removing the second call, but deadlocks usually happen from one of two subtle things:
当程序第二次调用l.acquire()时,它将挂起,等待释放Lock 。 在此示例中,您可以通过删除第二个调用来修复死锁,但是死锁通常是由以下两个微妙的事情之一引起的:
- An implementation bug where a
Lockis not released properly - A design issue where a utility function needs to be called by functions that might or might not already have the
Lock
-
Lock未正确释放的实现错误 - 一个设计问题,其中实用程序功能需要由可能具有或尚未具有
Lock功能的函数调用
The first situation happens sometimes, but using a Lock as a context manager greatly reduces how often. It is recommended to write code whenever possible to make use of context managers, as they help to avoid situations where an exception skips you over the .release() call.
第一种情况有时会发生,但是使用Lock作为上下文管理器会大大减少使用频率。 建议尽可能编写代码以使用上下文管理器,因为它们有助于避免出现异常使您跳过.release()调用的情况。
The design issue can be a bit trickier in some languages. Thankfully, Python threading has a second object, called RLock, that is designed for just this situation. It allows a thread to .acquire() an RLock multiple times before it calls .release(). That thread is still required to call .release() the same number of times it called .acquire(), but it should be doing that anyway.
在某些语言中,设计问题可能会有些棘手。 值得庆幸的是,Python线程还有另一个对象RLock ,专门针对这种情况而设计。 它允许一个线程.acquire()的RLock多次调用之前.release() 该线程仍然需要调用.release()相同数量的时候,它被称为.acquire()但它应该做的是反正。
Lock and RLock are two of the basic tools used in threaded programming to prevent race conditions. There are a few other that work in different ways. Before you look at them, let’s shift to a slightly different problem domain.
Lock和RLock是线程编程中用于防止竞争情况的两个基本工具。 还有其他一些以不同的方式工作。 在查看它们之前,让我们转到一个稍有不同的问题域。
生产者-消费者线程 (Producer-Consumer Threading)
The Producer-Consumer Problem is a standard computer science problem used to look at threading or process synchronization issues. You’re going to look at a variant of it to get some ideas of what primitives the Python threading module provides.
生产者-消费者问题是一种标准的计算机科学问题,用于查看线程或进程同步问题。 您将查看它的一个变体,以了解Python threading模块提供哪些原语。
For this example, you’re going to imagine a program that needs to read messages from a network and write them to disk. The program does not request a message when it wants. It must be listening and accept messages as they come in. The messages will not come in at a regular pace, but will be coming in bursts. This part of the program is called the producer.
对于此示例,您将想象一个程序,该程序需要从网络读取消息并将其写入磁盘。 该程序在需要时不请求消息。 它必须正在侦听并接受传入的消息。消息不会按常规速度传入,但会突然爆发。 程序的这一部分称为生产者。
On the other side, once you have a message, you need to write it to a database. The database access is slow, but fast enough to keep up to the average pace of messages. It is not fast enough to keep up when a burst of messages comes in. This part is the consumer.
另一方面,一旦收到消息,就需要将其写入数据库。 数据库访问很慢,但是足够快以跟上消息的平均速度。 当出现大量消息时,它赶不上足够快的速度。这部分是使用者。
In between the producer and the consumer, you will create a Pipeline that will be the part that changes as you learn about different synchronization objects.
在生产者和使用者之间,您将创建一个Pipeline ,该Pipeline将随着您了解不同的同步对象而发生变化。
That’s the basic layout. Let’s look at a solution using Lock. It doesn’t work perfectly, but it uses tools you already know, so it’s a good place to start.
这是基本布局。 让我们看一下使用Lock的解决方案。 它不能完美运行,但是会使用您已经知道的工具,因此是一个很好的起点。
使用Lock生产者-消费者 (Producer-Consumer Using Lock)
Since this is an article about Python threading, and since you just read about the Lock primitive, let’s try to solve this problem with two threads using a Lock or two.
由于这是一篇有关Python threading的文章,并且您刚刚阅读了Lock原语,所以我们尝试使用两个或两个Lock使用两个线程来解决此问题。
The general design is that there is a producer thread that reads from the fake network and puts the message into a Pipeline:
总体设计是,存在一个producer线程,该producer线程从假网络中读取并将消息放入Pipeline :
To generate a fake message, the producer gets a random number between one and one hundred. It calls .set_message() on the pipeline to send it to the consumer.
要生成虚假消息, producer将获得一个介于一百到一百之间的随机数。 它在pipeline上调用.set_message()以将其发送给consumer 。
The producer also uses a SENTINEL value to signal the consumer to stop after it has sent ten values. This is a little awkward, but don’t worry, you’ll see ways to get rid of this SENTINEL value after you work through this example.
producer还使用SENTINEL值来指示消费者在发送十个值后停止。 这有点尴尬,但是不用担心,在完成本示例后,您将看到摆脱SENTINEL值的方法。
On the other side of the pipeline is the consumer:
在另一侧pipeline是消费者:
def def consumerconsumer (( pipelinepipeline ):
):
""" Pretend we're saving a number in the database. """
""" Pretend we're saving a number in the database. """
message message = = 0
0
while while message message is is not not SENTINELSENTINEL :
:
message message = = pipelinepipeline .. get_messageget_message (( "Consumer""Consumer" )
)
if if message message is is not not SENTINELSENTINEL :
:
logginglogging .. infoinfo (( "Consumer storing message: "Consumer storing message: %s%s "" , , messagemessage )
)
The consumer reads a message from the pipeline and writes it to a fake database, which in this case is just printing it to the display. If it gets the SENTINEL value, it returns from the function, which will terminate the thread.
consumer从pipeline读取一条消息,并将其写入到伪造的数据库中,在这种情况下,该数据库只是将其打印到显示器上。 如果获得SENTINEL值,则从该函数返回,该函数将终止线程。
Before you look at the really interesting part, the Pipeline, here’s the __main__ section, which spawns these threads:
你看看真正有趣的部分,将前Pipeline ,这里的__main__部分,它会生成这些线程:
This should look fairly familiar as it’s close to the __main__ code in the previous examples.
这看起来很熟悉,因为它与前面的示例中的__main__代码非常接近。
Remember that you can turn on DEBUG logging to see all of the logging messages by uncommenting this line:
请记住,您可以通过取消注释以下行来打开DEBUG日志以查看所有日志消息:
# logging.getLogger().setLevel(logging.DEBUG)
# logging.getLogger().setLevel(logging.DEBUG)
It can be worthwhile to walk through the DEBUG logging messages to see exactly where each thread acquires and releases the locks.
遍历DEBUG日志消息以确切了解每个线程在何处获取和释放锁可能是值得的。
Now let’s take a look at the Pipeline that passes messages from the producer to the consumer:
现在让我们看一下将消息从producer传递到consumer的Pipeline :
Woah! That’s a lot of code. A pretty high percentage of that is just logging statements to make it easier to see what’s happening when you run it. Here’s the same code with all of the logging statements removed:
哇! 那是很多代码。 其中很大一部分只是记录语句,以使运行时更容易看到正在发生的事情。 以下是删除所有日志记录语句的相同代码:
class class PipelinePipeline :
:
"""Class to allow a single element pipeline between producer and consumer.
"""Class to allow a single element pipeline between producer and consumer.
"""
"""
def def __init____init__ (( selfself ):
):
selfself .. message message = = 0
0
selfself .. producer_lock producer_lock = = threadingthreading .. LockLock ()
()
selfself .. consumer_lock consumer_lock = = threadingthreading .. LockLock ()
()
selfself .. consumer_lockconsumer_lock .. acquireacquire ()
()
def def get_messageget_message (( selfself , , namename ):
):
selfself .. cosumer_lockcosumer_lock .. acquireacquire ()
()
message message = = selfself .. message
message
selfself .. producer_lockproducer_lock .. releaserelease ()
()
return return message
message
def def set_messageset_message (( selfself , , messagemessage , , namename ):
):
selfself .. producer_lockproducer_lock .. acquireacquire ()
()
selfself .. message message = = message
message
selfself .. consumer_lockconsumer_lock .. releaserelease ()
()
That seems a bit more manageable. The Pipeline in this version of your code has three members:
这似乎更易于管理。 此版本代码中的Pipeline具有三个成员:
.messagestores the message to pass..producer_lockis athreading.Lockobject that restricts access to the message by theproducerthread..consumer_lockis also athreading.Lockthat restricts access to the message by theconsumerthread.
-
.message存储要传递的消息。 -
.producer_lock是一个threading.Lock对象,用于限制producer线程对消息的访问。 -
.consumer_lock也是一个threading.Lock,它限制consumer线程对消息的访问。
__init__() initializes these three members and then calls .acquire() on the .consumer_lock. This is the state you want to start in. The producer is allowed to add a new message, but the consumer needs to wait until a message is present.
__init__()初始化这三个成员,然后在.consumer_lock上调用.acquire() 。 这是您要开始的状态。允许producer添加新消息,但是consumer需要等待直到出现消息为止。
.get_message() and .set_messages() are nearly opposites. .get_message() calls .acquire() on the consumer_lock. This is the call that will make the consumer wait until a message is ready.
.get_message()和.set_messages()几乎相反。 .get_message()调用.acquire()在consumer_lock 。 这是使consumer等待消息准备就绪的呼叫。
Once the consumer has acquired the .consumer_lock, it copies out the value in .message and then calls .release() on the .producer_lock. Releasing this lock is what allows the producer to insert the next message into the pipeline.
一旦consumer已经获得了.consumer_lock ,它复制出来的值.message ,然后调用.release()在.producer_lock 。 释放此锁定是使producer可以将下一条消息插入pipeline 。
Before you go on to .set_message(), there’s something subtle going on in .get_message() that’s pretty easy to miss. It might seem tempting to get rid of message and just have the function end with return self.message. See if you can figure out why you don’t want to do that before moving on.
你去之前.set_message()有什么东西在微妙的事情.get_message()这是很容易错过。 摆脱message似乎很诱人,而让函数以return self.message 。 在继续之前,先看看是否可以弄清楚为什么不想这样做。
Here’s the answer. As soon as the consumer calls .producer_lock.release(), it can be swapped out, and the producer can start running. That could happen before .release() returns! This means that there is a slight possibility that when the function returns self.message, that could actually be the next message generated, so you would lose the first message. This is another example of a race condition.
这就是答案。 consumer调用.producer_lock.release() ,就可以将其换出,并且producer可以开始运行。 这可能在.release()返回之前发生! 这意味着,当函数返回self.message ,极有可能实际上是下一条生成的消息,因此您将丢失第一条消息。 这是竞争条件的另一个示例。
Moving on to .set_message(), you can see the opposite side of the transaction. The producer will call this with a message. It will acquire the .producer_lock, set the .message, and the call .release() on then consumer_lock, which will allow the consumer to read that value.
转到.set_message() ,您可以看到事务的另一面。 producer将通过一条消息来调用它。 将收购.producer_lock ,设置.message ,以及呼叫.release()上,然后consumer_lock ,这将使consumer读取该值。
Let’s run the code that has logging set to WARNING and see what it looks like:
让我们运行将日志记录设置为WARNING的代码,看看它是什么样的:
At first, you might find it odd that the producer gets two messages before the consumer even runs. If you look back at the producer and .set_message(), you will notice that the only place it will wait for a Lock is when it attempts to put the message into the pipeline. This is done after the producer gets the message and logs that it has it.
起初,您可能会觉得奇怪,生产者在消费者运行之前就收到了两条消息。 如果回头查看producer和.set_message() ,您会注意到,它唯一等待Lock是当它尝试将消息放入管道时。 在producer获取消息并记录该消息后,便完成了此操作。
When the producer attempts to send this second message, it will call .set_message() the second time and it will block.
当producer尝试发送第二条消息时,它将第二次调用.set_message()并将其阻止。
The operating system can swap threads at any time, but it generally lets each thread have a reasonable amount of time to run before swapping it out. That’s why the producer usually runs until it blocks in the second call to .set_message().
操作系统可以随时交换线程,但是通常让每个线程在交换掉之前有合理的时间运行。 这就是producer通常运行直到它阻塞对.set_message()的第二次调用的.set_message() 。
Once a thread is blocked, however, the operating system will always swap it out and find a different thread to run. In this case, the only other thread with anything to do is the producer.
但是,一旦线程被阻塞,操作系统将始终将其换出并找到其他线程来运行。 在这种情况下,与生产有关的唯一其他线程是producer 。
The producer calls .get_message(), which reads the message and calls .release() on the .producer_lock, thus allowing the producer to run again the next time threads are swapped.
producer调用.get_message() ,该消息读取消息并在.producer_lock上调用.release() ,从而允许producer在下次交换线程时再次运行。
Notice that the first message was 43, and that is exactly what the consumer read, even though the producer had already generated the 45 message.
注意,第一个消息是43 ,即使producer已经生成了45消息,也正是consumer阅读的内容。
While it works for this limited test, it is not a great solution to the producer-consumer problem in general because it only allows a single value in the pipeline at a time. When the producer gets a burst of messages, it will have nowhere to put them.
尽管它适用于这种有限的测试,但是通常它并不是解决生产者-消费者问题的好方法,因为它一次只允许在管道中使用一个值。 当producer收到大量消息时,它将无处可放。
Let’s move on to a better way to solve this problem, using a Queue.
让我们继续使用Queue来解决此问题的更好方法。
生产者-消费者使用Queue (Producer-Consumer Using Queue)
If you want to be able to handle more than one value in the pipeline at a time, you’ll need a data structure for the pipeline that allows the number to grow and shrink as data backs up from the producer.
如果您希望一次处理一个管道中的多个值,则需要该管道的数据结构,该结构允许该数字随着producer备份的数据而增加和减少。
Python’s standard library has a queue module which, in turn, has a Queue class. Let’s change the Pipeline to use a Queue instead of just a variable protected by a Lock. You’ll also use a different way to stop the worker threads by using a different primitive from Python threading, an Event.
Python的标准库具有一个queue模块,该模块又具有一个Queue类。 让我们将Pipeline更改为使用Queue而不是仅使用Lock保护的变量。 您还将通过使用与Python threading不同的原语(即Event ,使用不同的方式来停止工作线程。
Let’s start with the Event. The threading.Event object allows one thread to signal an event while many other threads can be waiting for that event to happen. The key usage in this code is that the threads that are waiting for the event do not necessarily need to stop what they are doing, they can just check the status of the Event every once in a while.
让我们从Event开始。 threading.Event对象允许一个线程发出event信号,而其他许多线程可以等待该event发生。 此代码中的关键用法是,等待事件的线程不一定需要停止其正在执行的操作,它们仅可以偶尔检查一次Event的状态。
The triggering of the event can be many things. In this example, the main thread will simply sleep for a while and then .set() it:
事件的触发可能有很多事情。 在此示例中,主线程将仅Hibernate一段时间,然后对其进行.set() :
if if __name__ __name__ == == "__main__""__main__" :
:
format format = = "" %(asctime)s%(asctime)s : : %(message)s%(message)s "
"
logginglogging .. basicConfigbasicConfig (( formatformat == formatformat , , levellevel == logginglogging .. INFOINFO ,
,
datefmtdatefmt == "%H:%M:%S""%H:%M:%S" )
)
# logging.getLogger().setLevel(logging.DEBUG)
# logging.getLogger().setLevel(logging.DEBUG)
pipeline pipeline = = PipelinePipeline ()
()
event event = = threadingthreading .. EventEvent ()
()
with with concurrentconcurrent .. futuresfutures .. ThreadPoolExecutorThreadPoolExecutor (( max_workersmax_workers == 22 ) ) as as executorexecutor :
:
executorexecutor .. submitsubmit (( producerproducer , , pipelinepipeline , , eventevent )
)
executorexecutor .. submitsubmit (( consumerconsumer , , pipelinepipeline , , eventevent )
)
timetime .. sleepsleep (( 0.10.1 )
)
logginglogging .. infoinfo (( "Main: about to set event""Main: about to set event" )
)
eventevent .. setset ()
()
The only changes here are the creation of the event object on line 6, passing the event as a parameter on lines 8 and 9, and the final section on lines 11 to 13, which sleep for a second, log a message, and then call .set() on the event.
唯一的变化是在第6行创建了event对象,在第8行和第9行传递了该event作为参数,并在第11到13行的最后一节进行了睡眠,记录了一条消息,然后调用.set()在事件上。
The producer also did not have to change too much:
producer也不必改变太多:
It now will loop until it sees that the event was set on line 3. It also no longer puts the SENTINEL value into the pipeline.
现在它将循环直到看到事件在第3行设置。它也不再将SENTINEL值放入pipeline 。
consumer had to change a little more:
consumer不得不多做一些改变:
def def consumerconsumer (( pipelinepipeline , , eventevent ):
):
""" Pretend we're saving a number in the database. """
""" Pretend we're saving a number in the database. """
while while not not eventevent .. is_setis_set () () or or not not pipelinepipeline .. emptyempty ():
():
message message = = pipelinepipeline .. get_messageget_message (( "Consumer""Consumer" )
)
logginglogging .. infoinfo (
(
"Consumer storing message: "Consumer storing message: %s%s (queue size= (queue size= %s%s )")" ,
,
messagemessage ,
,
pipelinepipeline .. qsizeqsize (),
(),
)
)
logginglogging .. infoinfo (( "Consumer received EXIT event. Exiting""Consumer received EXIT event. Exiting" )
)
While you got to take out the code related to the SENTINEL value, you did have to do a slightly more complicated while condition. Not only does it loop until the event is set, but it also needs to keep looping until the pipeline has been emptied.
当您必须取出与SENTINEL值相关的代码时,您的确需要做一些稍微复杂的while条件。 它不仅会循环直到设置了event为止,而且还需要保持循环直到清空pipeline为止。
Making sure the queue is empty before the consumer finishes prevents another fun issue. If the consumer does exit while the pipeline has messages in it, there are two bad things that can happen. The first is that you lose those final messages, but the more serious one is that the producer can get caught on the producer_lock and never return.
在使用者完成操作之前确保队列为空可以防止出现另一个有趣的问题。 如果consumer确实在pipeline包含消息的情况下退出了,则可能发生两种不良情况。 首先是您丢失了最后的消息,但是更严重的是, producer可能会陷入producer_lock并永远不会返回。
This happens if the event gets triggered after the producer has checked the .is_set() condition but before it calls pipeline.set_message().
如果在producer检查.is_set()条件之后但在调用pipeline.set_message()之前触发了event则会发生这种情况。
If that happens, it’s possible for the producer to wake up and exit with the .producer_lock still being held. The producer will then try to .acquire() the .producer_lock, but the consumer has exited and will never .release() it.
如果发生这种情况,生产者有可能在仍保持.producer_lock的情况下唤醒并退出。 然后, producer将尝试.acquire() .producer_lock ,但是consumer已经退出,并且永远不会.release() 。
The rest of the consumer should look familiar.
其余的consumer应该看起来很熟悉。
The Pipeline has changed dramatically, however:
Pipeline发生了巨大变化,但是:
You can see that Pipeline is a subclass of queue.Queue. Queue has an optional parameter when initializing to specify a maximum size of the queue.
您可以看到Pipeline是queue.Queue的子类。 初始化时, Queue具有可选参数以指定队列的最大大小。
If you give a positive number for maxsize, it will limit the queue to that number of elements, causing .put() to block until there are fewer than maxsize elements. If you don’t specify maxsize, then the queue will grow to the limits of your computer’s memory.
如果为maxsize给出正数,则它将队列限制为该元素数,从而导致.put()阻塞,直到少于maxsize元素为止。 如果您未指定maxsize ,那么队列将增长到计算机内存的限制。
.get_message() and .set_message() got much smaller. They basically wrap .get() and .put() on the Queue. You might be wondering where all of the locking code that prevents the threads from causing race conditions went.
.get_message()和.set_message()变得更小。 他们基本上将.get()和.put()包装在Queue 。 您可能想知道阻止线程导致竞争条件的所有锁定代码都移到了哪里。
The core devs who wrote the standard library knew that a Queue is frequently used in multi-threading environments and incorporated all of that locking code inside the Queue itself. Queue is thread-safe.
编写标准库的核心开发人员知道Queue在多线程环境中经常使用,并将所有锁定代码合并到Queue本身中。 Queue是线程安全的。
Running this program looks like the following:
运行该程序如下所示:
$ ./prodcom_queue.py
$ ./prodcom_queue.py
Producer got message: 32
Producer got message: 32
Producer got message: 51
Producer got message: 51
Producer got message: 25
Producer got message: 25
Producer got message: 94
Producer got message: 94
Producer got message: 29
Producer got message: 29
Consumer storing message: 32 (queue size=3)
Consumer storing message: 32 (queue size=3)
Producer got message: 96
Producer got message: 96
Consumer storing message: 51 (queue size=3)
Consumer storing message: 51 (queue size=3)
Producer got message: 6
Producer got message: 6
Consumer storing message: 25 (queue size=3)
Consumer storing message: 25 (queue size=3)
Producer got message: 31
Producer got message: 31
[many lines deleted]
[many lines deleted]
Producer got message: 80
Producer got message: 80
Consumer storing message: 94 (queue size=6)
Consumer storing message: 94 (queue size=6)
Producer got message: 33
Producer got message: 33
Consumer storing message: 20 (queue size=6)
Consumer storing message: 20 (queue size=6)
Producer got message: 48
Producer got message: 48
Consumer storing message: 31 (queue size=6)
Consumer storing message: 31 (queue size=6)
Producer got message: 52
Producer got message: 52
Consumer storing message: 98 (queue size=6)
Consumer storing message: 98 (queue size=6)
Main: about to set event
Main: about to set event
Producer got message: 13
Producer got message: 13
Consumer storing message: 59 (queue size=6)
Consumer storing message: 59 (queue size=6)
Producer received EXIT event. Exiting
Producer received EXIT event. Exiting
Consumer storing message: 75 (queue size=6)
Consumer storing message: 75 (queue size=6)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 13 (queue size=0)
Consumer storing message: 13 (queue size=0)
Consumer received EXIT event. Exiting
Consumer received EXIT event. Exiting
If you read through the output in my example, you can see some interesting things happening. Right at the top, you can see the producer got to create five messages and place four of them on the queue. It got swapped out by the operating system before it could place the fifth one.
如果您在我的示例中仔细阅读了输出,您会发现一些有趣的事情正在发生。 在顶部,您可以看到producer必须创建五个消息并将其中四个放置在队列中。 它被操作系统替换掉,然后才可以放置第五个。
The consumer then ran and pulled off the first message. It printed out that message as well as how deep the queue was at that point:
consumer然后奔跑并提取了第一条消息。 它打印出该消息以及此时的队列深度:
This is how you know that the fifth message hasn’t made it into the pipeline yet. The queue is down to size three after a single message was removed. You also know that the queue can hold ten messages, so the producer thread didn’t get blocked by the queue. It was swapped out by the OS.
这就是您知道第五条消息尚未进入pipeline 。 删除单个消息后,队列的大小减小到三。 您还知道queue可以容纳十条消息,因此producer线程不会被queue阻塞。 它已被操作系统换出。
Note: Your output will be different. Your output will change from run to run. That’s the fun part of working with threads!
注意:您的输出将不同。 您的输出将在运行之间变化。 那是使用线程的乐趣所在!
As the program starts to wrap up, can you see the main thread generating the event which causes the producer to exit immediately. The consumer still has a bunch of work do to, so it keeps running until it has cleaned out the pipeline.
当程序开始结束时,您是否可以看到主线程生成了导致producer立即退出的event 。 consumer还有很多工作要做,因此它一直运行直到清理完pipeline 。
Try playing with different queue sizes and calls to time.sleep() in the producer or the consumer to simulate longer network or disk access times respectively. Even slight changes to these elements of the program will make large differences in your results.
尝试在producer或consumer使用不同的队列大小并调用time.sleep()来分别模拟更长的网络或磁盘访问时间。 即使对该程序的这些元素稍作更改,也会在结果上产生很大的差异。
This is a much better solution to the producer-consumer problem, but you can simplify it even more. The Pipeline really isn’t needed for this problem. Once you take away the logging, it just becomes a queue.Queue.
这是解决生产者-消费者问题的更好的解决方案,但是您可以进一步简化它。 这个问题确实不需要Pipeline 。 一旦取消日志记录,它就变成了queue.Queue 。
Here’s what the final code looks like using queue.Queue directly:
这是直接使用queue.Queue的最终代码:
import import concurrent.futures
concurrent.futures
import import logging
logging
import import queue
queue
import import random
random
import import threading
threading
import import time
time
def def producerproducer (( queuequeue , , eventevent ):
):
"""Pretend we're getting a number from the network."""
"""Pretend we're getting a number from the network."""
while while not not eventevent .. is_setis_set ():
():
message message = = randomrandom .. randintrandint (( 11 , , 101101 )
)
logginglogging .. infoinfo (( "Producer got message: "Producer got message: %s%s "" , , messagemessage )
)
queuequeue .. putput (( messagemessage )
)
logginglogging .. infoinfo (( "Producer received event. Exiting""Producer received event. Exiting" )
)
def def consumerconsumer (( queuequeue , , eventevent ):
):
""" Pretend we're saving a number in the database. """
""" Pretend we're saving a number in the database. """
while while not not eventevent .. is_setis_set () () or or not not pipelinepipeline .. emptyempty ():
():
message message = = queuequeue .. getget ()
()
logginglogging .. infoinfo (
(
"Consumer storing message: "Consumer storing message: %s%s (size= (size= %d%d )")" , , messagemessage , , queuequeue .. qsizeqsize ()
()
)
)
logginglogging .. infoinfo (( "Consumer received event. Exiting""Consumer received event. Exiting" )
)
if if __name__ __name__ == == "__main__""__main__" :
:
format format = = "" %(asctime)s%(asctime)s : : %(message)s%(message)s "
"
logginglogging .. basicConfigbasicConfig (( formatformat == formatformat , , levellevel == logginglogging .. INFOINFO ,
,
datefmtdatefmt == "%H:%M:%S""%H:%M:%S" )
)
pipeline pipeline = = queuequeue .. QueueQueue (( maxsizemaxsize == 1010 )
)
event event = = threadingthreading .. EventEvent ()
()
with with concurrentconcurrent .. futuresfutures .. ThreadPoolExecutorThreadPoolExecutor (( max_workersmax_workers == 22 ) ) as as executorexecutor :
:
executorexecutor .. submitsubmit (( producerproducer , , pipelinepipeline , , eventevent )
)
executorexecutor .. submitsubmit (( consumerconsumer , , pipelinepipeline , , eventevent )
)
timetime .. sleepsleep (( 0.10.1 )
)
logginglogging .. infoinfo (( "Main: about to set event""Main: about to set event" )
)
eventevent .. setset ()
()
That’s easier to read and shows how using Python’s built-in primitives can simplify a complex problem.
这更容易阅读,并显示了使用Python的内置原语如何简化复杂的问题。
Lock and Queue are handy classes to solve concurrency issues, but there are others provided by the standard library. Before you wrap up this tutorial, let’s do a quick survey of some of them.
Lock和Queue是解决并发问题的便捷类,但是标准库还提供了其他类。 在结束本教程之前,让我们对其中一些进行快速调查。
线程对象 (Threading Objects)
There are a few more primitives offered by the Python threading module. While you didn’t need these for the examples above, they can come in handy in different use cases, so it’s good to be familiar with them.
Python threading模块还提供了其他一些原语。 尽管您在上面的示例中不需要这些,但是它们可以在不同的用例中派上用场,因此熟悉它们是很好的。
信号 (Semaphore)
The first Python threading object to look at is threading.Semaphore. A Semaphore is a counter with a few special properties. The first one is that the counting is atomic. This means that there is a guarantee that the operating system will not swap out the thread in the middle of incrementing or decrementing the counter.
要查看的第一个Python threading对象是threading.Semaphore 。 Semaphore是具有一些特殊属性的计数器。 第一个是计数是原子的。 这意味着可以保证操作系统在递增或递减计数器的过程中不会换出线程。
The internal counter is incremented when you call .release() and decremented when you call .acquire().
当你调用内部计数器递增.release()当你调用递减.acquire()
The next special property is that if a thread calls .acquire() when the counter is zero, that thread will block until a different thread calls .release() and increments the counter to one.
下一个特殊的属性是,如果一个计数器在计数器为零时调用.acquire() ,则该线程将阻塞,直到另一个线程调用.release()并将计数器增加到一个。
Semaphores are frequently used to protect a resource that has a limited capacity. An example would be if you have a pool of connections and want to limit the size of that pool to a specific number.
信号量通常用于保护容量有限的资源。 例如,如果您有一个连接池,并希望将该池的大小限制为特定数目。
计时器 (Timer)
A threading.Timer is a way to schedule a function to be called after a certain amount of time has passed. You create a Timer by passing in a number of seconds to wait and a function to call:
threading.Timer是一种在经过一定时间后安排要调用的函数的方法。 通过传递等待的秒数和要调用的函数来创建Timer :
You start the Timer by calling .start(). The function will be called on a new thread at some point after the specified time, but be aware that there is no promise that it will be called exactly at the time you want.
您可以通过调用.start()启动Timer 。 在指定时间之后的某个时间,该函数将在新线程上被调用,但是请注意,不能保证它会在您希望的时间被完全调用。
If you want to stop a Timer that you’ve already started, you can cancel it by calling .cancel(). Calling .cancel() after the Timer has triggered does nothing and does not produce an exception.
如果要停止已经启动的Timer ,可以通过调用.cancel()来取消它。 Timer触发后调用.cancel()不会执行任何操作,也不会产生异常。
A Timer can be used to prompt a user for action after a specific amount of time. If the user does the action before the Timer expires, .cancel() can be called.
Timer可用于在特定时间段后提示用户采取措施。 如果用户在Timer到期之前执行了操作,则可以调用.cancel() 。
屏障 (Barrier)
A threading.Barrier can be used to keep a fixed number of threads in sync. When creating a Barrier, the caller must specify how many threads will be synchronizing on it. Each thread calls .wait() on the Barrier. They all will remain blocked until the specified number of threads are waiting, and then the are all released at the same time.
threading.Barrier可用于保持固定数量的线程同步。 创建Barrier ,调用者必须指定要在其上同步的线程数。 每个线程在Barrier上调用.wait() 。 它们将一直处于阻塞状态,直到指定数量的线程正在等待,然后所有线程都同时释放。
Remember that threads are scheduled by the operating system so, even though all of the threads are released simultaneously, they will be scheduled to run one at a time.
请记住,线程是由操作系统调度的,因此,即使所有线程同时释放,它们也将被调度为一次运行。
One use for a Barrier is to allow a pool of threads to initialize themselves. Having the threads wait on a Barrier after they are initialized will ensure that none of the threads start running before all of the threads are finished with their initialization.
Barrier一种用途是允许线程池初始化自己。 在初始化之后让线程在Barrier上等待将确保所有线程在初始化完成之前没有任何线程开始运行。
结论:Python中的线程 (Conclusion: Threading in Python)
You’ve now seen much of what Python threading has to offer and some examples of how to build threaded programs and the problems they solve. You’ve also seen a few instances of the problems that arise when writing and debugging threaded programs.
您现在已经了解了Python threading必须提供的许多功能,以及一些有关如何构建线程程序及其解决问题的示例。 您还看到了编写和调试线程程序时出现的一些问题实例。
If you’d like to explore other options for concurrency in Python, check out Speed Up Your Python Program With Concurrency.
如果您想探索Python中用于并发的其他选项,请查看“使用并发加快Python程序” 。
If you’re interested in doing a deep dive on the asyncio module, go read Async IO in Python: A Complete Walkthrough.
如果您想对asyncio模块进行深入研究,请阅读Python中的Async IO:A Complete Walkthrough 。
Whatever you do, you now have the information and confidence you need to write programs using Python threading!
无论您做什么,现在都拥有使用Python线程编写程序所需的信息和信心!
Take the Quiz: Test your knowledge with our interactive “Python Threading” quiz. Upon completion you will receive a score so you can track your learning progress over time:
参加测验:通过我们的交互式“ Python线程”测验测试您的知识。 完成后,您将获得一个分数,因此您可以跟踪一段时间内的学习进度:
翻译自: https://www.pybloggers.com/2019/03/an-intro-to-threading-in-python/
python线程创建线程















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









