





python 异步io
Async IO is a concurrent programming design that has received dedicated support in Python, evolving rapidly from Python 3.4 through 3.7, and probably beyond.
异步IO是一种并发编程设计,已获得Python的专门支持,从Python 3.4到3.7以及可能超越的版本Swift发展。
You may be thinking with dread, “Concurrency, parallelism, threading, multiprocessing. That’s a lot to grasp already. Where does async IO fit in?”
您可能会担心“并发,并行性,线程化,多处理。 已经掌握了很多东西。 异步IO放在哪里?”
This tutorial is built to help you answer that question, giving you a firmer grasp of Python’s approach to async IO.
本教程旨在帮助您回答该问题,从而使您更加牢固地掌握Python的异步IO方法。
Here’s what you’ll cover:
这是您要介绍的内容:
-
Asynchronous IO (async IO): a language-agnostic paradigm (model) that has implementations across a host of programming languages
-
async/await: two new Python keywords that are used to define coroutines -
asyncio: the Python package that provides a foundation and API for running and managing coroutines
异步IO(异步IO) :一种与语言无关的范例(模型),具有跨多种编程语言的实现
async/await:两个用于定义协程的新Python关键字asyncio:Python软件包,为运行和管理协程提供基础和API
Coroutines (specialized generator functions) are the heart of async IO in Python, and we’ll dive into them later on.
协程(专用的生成器函数)是Python中异步IO的核心,稍后我们将深入探讨它们。
Note: In this article, I use the term async IO to denote the language-agnostic design of asynchronous IO, while asyncio refers to the Python package.
注 :在本文中,我使用术语异步IO表示异步IO的语言无关的设计,同时asyncio指Python包。
Before you get started, you’ll need to make sure you’re set up to use asyncio and other libraries found in this tutorial.
在开始之前,您需要确保已设置为使用本教程中发现的asyncio和其他库。
Free Bonus: 5 Thoughts On Python Mastery, a free course for Python developers that shows you the roadmap and the mindset you’ll need to take your Python skills to the next level.
免费奖金: 关于Python精通的5个想法 ,这是针对Python开发人员的免费课程,向您展示了将Python技能提升到新水平所需的路线图和心态。
设置环境 (Setting Up Your Environment)
You’ll need Python 3.7 or above to follow this article in its entirety, as well as the aiohttp and aiofiles packages:
您需要Python 3.7或更高版本才能完整阅读本文,以及aiohttp和aiofiles软件包:
$ python3.7 -m venv ./py37async
$ python3.7 -m venv ./py37async
$ $ source ./py37async/bin/activate source ./py37async/bin/activate # Windows: .py37asyncScriptsactivate.bat
# Windows: .py37asyncScriptsactivate.bat
$ pip install --upgrade pip aiohttp aiofiles $ pip install --upgrade pip aiohttp aiofiles # Optional: aiodns
# Optional: aiodns
For help with installing Python 3.7 and setting up a virtual environment, check out Python 3 Installation & Setup Guide or Virtual Environments Primer.
有关安装Python 3.7和设置虚拟环境的帮助,请查看《 Python 3安装和设置指南》或《 虚拟环境入门》 。
With that, let’s jump in.
这样,让我们进入吧。
异步IO的10,000英尺视图 (The 10,000-Foot View of Async IO)
Async IO is a bit lesser known than its tried-and-true cousins, multiprocessing and threading. This section will give you a fuller picture of what async IO is and how it fits into its surrounding landscape.
异步IO比其久经考验的表亲,多处理和线程处理要少。 本节将为您提供什么是异步IO以及它如何适应其周围环境的完整图片。
异步IO放在哪里? (Where Does Async IO Fit In?)
Concurrency and parallelism are expansive subjects that are not easy to wade into. While this article focuses on async IO and its implementation in Python, it’s worth taking a minute to compare async IO to its counterparts in order to have context about how async IO fits into the larger, sometimes dizzying puzzle.
并发和并行性是不容易涉足的扩展主题。 尽管本文重点介绍异步IO及其在Python中的实现,但值得花一点时间将异步IO与同类产品进行比较,以了解异步IO如何适应更大,有时令人头晕的难题。
Parallelism consists of performing multiple operations at the same time. Multiprocessing is a means to effect parallelism, and it entails spreading tasks over a computer’s central processing units (CPUs, or cores). Multiprocessing is well-suited for CPU-bound tasks: tightly bound for loops and mathematical computations usually fall into this category.
并行性包括同时执行多个操作。 多处理是一种实现并行性的方法,它需要将任务分散到计算机的中央处理单元(CPU或内核)上。 多是非常适合的CPU密集型任务:紧密结合for循环和数学计算通常属于这一类。
Concurrency is a slightly broader term than parallelism. It suggests that multiple tasks have the ability to run in an overlapping manner. (There’s a saying that concurrency does not imply parallelism.)
并发是一个比并行性稍微宽泛的术语。 这表明多个任务具有以重叠方式运行的能力。 (有一种说法是并发并不意味着并行。)
Threading is a concurrent execution model whereby multiple threads take turns executing tasks. One process can contain multiple threads. Python has a complicated relationship with threading thanks to its GIL, but that’s beyond the scope of this article.
线程是并发执行模型,多个线程轮流执行任务。 一个进程可以包含多个线程。 由于其GIL ,Python与线程之间的关系非常复杂,但这超出了本文的范围。
What’s important to know about threading is that it’s better for IO-bound tasks. While a CPU-bound task is characterized by the computer’s cores continually working hard from start to finish, an IO-bound job is dominated by a lot of waiting on input/output to complete.
重要的是要知道线程化对于IO绑定的任务来说更好。 尽管CPU密集型任务的特点是计算机内核从头到尾不断地努力工作,但IO受限型工作主要由大量等待输入/输出来完成。
To recap the above, concurrency encompasses both multiprocessing (ideal for CPU-bound tasks) and threading (suited for IO-bound tasks). Multiprocessing is a form of parallelism, with parallelism being a specific type (subset) of concurrency. The Python standard library has offered longstanding support for both of these through its multiprocessing, threading, and concurrent.futures packages.
综上所述,并发既包含多处理(理想的是CPU绑定任务),也包含线程处理(适用于IO绑定任务)。 多处理是并行性的一种形式,并行性是并发的特定类型(子集)。 Python标准库通过其multiprocessing , threading和concurrent.futures软件包为这两者提供了长期支持 。
Now it’s time to bring a new member to the mix. Over the last few years, a separate design has been more comprehensively built into CPython: asynchronous IO, enabled through the standard library’s asyncio package and the new async and await language keywords. To be clear, async IO is not a newly invented concept, and it has existed or is being built into other languages and runtime environments, such as Go, C#, or Scala.
现在是时候让一个新成员加入了。 在过去的几年中,CPython中更全面地构建了一个独立的设计:异步IO,它通过标准库的asyncio包和新的async和await语言关键字启用。 需要明确的是,异步IO并不是一个新发明的概念,它已经存在或正在内置到其他语言和运行时环境中,例如Go , C#或Scala 。
The asyncio package is billed by the Python documentation as a library to write concurrent code. However, async IO is not threading, nor is it multiprocessing. It is not built on top of either of these.
Python文档将asyncio软件包记为一个用于编写并发代码的库 。 但是,异步IO不是线程化,也不是多处理。 它不是建立在这两个之上的。
In fact, async IO is a single-threaded, single-process design: it uses cooperative multitasking, a term that you’ll flesh out by the end of this tutorial. It has been said in other words that async IO gives a feeling of concurrency despite using a single thread in a single process. Coroutines (a central feature of async IO) can be scheduled concurrently, but they are not inherently concurrent.
实际上,异步IO是一种单线程,单进程设计:它使用协作多任务处理 ,这个术语将在本教程结束时充实。 换句话说,尽管在单个进程中使用单个线程,但异步IO却给人以并发的感觉。 协程(异步IO的主要功能)可以并发进行调度,但它们并不是固有并发的。
To reiterate, async IO is a style of concurrent programming, but it is not parallelism. It’s more closely aligned with threading than with multiprocessing but is very much distinct from both of these and is a standalone member in concurrency’s bag of tricks.
重申一下,异步IO是并发编程的一种形式,但它不是并行性。 与多线程处理相比,它与线程处理的关系更加紧密,但两者却截然不同,并且是并发技巧包中的独立成员。
That leaves one more term. What does it mean for something to be asynchronous? This isn’t a rigorous definition, but for our purposes here, I can think of two properties:
剩下一个任期。 异步是什么意思? 这不是一个严格的定义,但是出于我们此处的目的,我可以想到两个属性:
- Asynchronous routines are able to “pause” while waiting on their ultimate result and let other routines run in the meantime.
- Asynchronous code, through the mechanism above, facilitates concurrent execution. To put it differently, asynchronous code gives the look and feel of concurrency.
- 异步例程可以在等待其最终结果的同时“暂停”,并让其他例程同时运行。
- 通过上述机制,异步代码有助于并发执行。 换句话说,异步代码给出了并发的外观。
Here’s a diagram to put it all together. The white terms represent concepts, and the green terms represent ways in which they are implemented or effected:
这是将所有内容放在一起的图表。 白色术语代表概念,绿色术语代表实现或实现它们的方式:
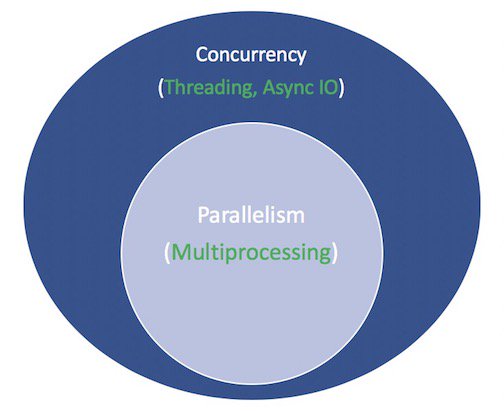
I’ll stop there on the comparisons between concurrent programming models. This tutorial is focused on the subcomponent that is async IO, how to use it, and the APIs that have sprung up around it. For a thorough exploration of threading versus multiprocessing versus async IO, pause here and check out Jim Anderson’s overview of concurrency in Python. Jim is way funnier than me and has sat in more meetings than me, to boot.
我将停止并发编程模型之间的比较。 本教程的重点是异步IO的子组件,如何使用它以及围绕它兴起的API。 要全面了解线程,多处理和异步IO,请在此处暂停并查看Jim Anderson 关于Python并发性的概述 。 吉姆比我有趣,参加比我更多的会议。
异步IO解释 (Async IO Explained)
Async IO may at first seem counterintuitive and paradoxical. How does something that facilitates concurrent code use a single thread and a single CPU core? I’ve never been very good at conjuring up examples, so I’d like to paraphrase one from Miguel Grinberg’s 2017 PyCon talk, which explains everything quite beautifully:
异步IO乍看起来似乎违反直觉和自相矛盾。 促进并发代码的事物如何使用单个线程和单个CPU内核? 我从来都不擅长制作示例,因此我想解释一下Miguel Grinberg在2017年PyCon演讲中的一个,它很好地解释了所有内容:
Chess master Judit Polgár hosts a chess exhibition in which she plays multiple amateur players. She has two ways of conducting the exhibition: synchronously and asynchronously.
国际象棋大师朱迪特·波尔加尔(JuditPolgár)举办国际象棋展览,在其中她扮演多个业余玩家。 她有两种举办展览的方式:同步和异步。
Assumptions:
假设:
- 24 opponents
- Judit makes each chess move in 5 seconds
- Opponents each take 55 seconds to make a move
- Games average 30 pair-moves (60 moves total)
- 24个对手
- Judit在5秒内使每盘棋移动
- 对手各花费55秒采取行动
- 游戏平均30对动作(总共60个动作)
Synchronous version: Judit plays one game at a time, never two at the same time, until the game is complete. Each game takes (55 + 5) * 30 == 1800 seconds, or 30 minutes. The entire exhibition takes 24 * 30 == 720 minutes, or 12 hours.
同步版本 :Judit一次只能玩一个游戏,在游戏完成之前绝不能同时玩两个游戏。 每个游戏需要(55 + 5)* 30 == 1800秒或30分钟。 整个展览需要24 * 30 == 720分钟或12个小时 。
Asynchronous version: Judit moves from table to table, making one move at each table. She leaves the table and lets the opponent make their next move during the wait time. One move on all 24 games takes Judit 24 * 5 == 120 seconds, or 2 minutes. The entire exhibition is now cut down to 120 * 30 == 3600 seconds, or just 1 hour. (Source)
异步版本 :Judit在一个表之间移动,在每个表上移动一个。 她离开桌子,让对手在等待时间内采取下一步行动。 在所有24场比赛中,一动需要Judit 24 * 5 == 120秒或2分钟。 现在整个展览减少到120 * 30 == 3600秒,或仅1小时 。 (资源)
There is only one Judit Polgár, who has only two hands and makes only one move at a time by herself. But playing asynchronously cuts the exhibition time down from 12 hours to one. So, cooperative multitasking is a fancy way of saying that a program’s event loop (more on that later) communicates with multiple tasks to let each take turns running at the optimal time.
JuditPolgár只有一只,只有两只手,并且一次只能动一动。 但是异步播放可以将展览时间从12小时减少到一小时。 因此,协作式多任务处理是一种奇特的方式,可以说程序的事件循环(稍后会详细介绍)与多个任务进行通信,以使每个任务在最佳时间轮流运行。
Async IO takes long waiting periods in which functions would otherwise be blocking and allows other functions to run during that downtime. (A function that blocks effectively forbids others from running from the time that it starts until the time that it returns.)
异步IO需要较长的等待时间,否则功能将被阻塞,并允许其他功能在停机期间运行。 (有效阻止的功能从开始到返回为止一直禁止其他人运行。)
异步IO并不容易 (Async IO Is Not Easy)
I’ve heard it said, “Use async IO when you can; use threading when you must.” The truth is that building durable multithreaded code can be hard and error-prone. Async IO avoids some of the potential speedbumps that you might otherwise encounter with a threaded design.
我听说它说:“尽可能使用异步IO; 必要时使用线程。” 事实是,构建持久的多线程代码可能很困难且容易出错。 异步IO避免了线程设计可能会遇到的某些潜在的速度颠簸。
But that’s not to say that async IO in Python is easy. Be warned: when you venture a bit below the surface level, async programming can be difficult too! Python’s async model is built around concepts such as callbacks, events, transports, protocols, and futures—just the terminology can be intimidating. The fact that its API has been changing continually makes it no easier.
但这并不是说Python中的异步IO很简单。 请注意:当您冒险进入底层时,异步编程也可能会很困难! Python的异步模型是基于诸如回调,事件,传输,协议和期货之类的概念构建的-只是术语可能令人生畏。 其API不断变化的事实使其变得不那么容易。
Luckily, asyncio has matured to a point where most of its features are no longer provisional, while its documentation has received a huge overhaul and some quality resources on the subject are starting to emerge as well.
幸运的是, asyncio已经发展到某种程度,它的大多数功能不再是临时的,而其文档已得到了巨大的改进,与此相关的一些优质资源也开始出现。
该asyncio包和async / await (The asyncio Package and async/await)
Now that you have some background on async IO as a design, let’s explore Python’s implementation. Python’s asyncio package (introduced in Python 3.4) and its two keywords, async and await, serve different purposes but come together to help you declare, build, execute, and manage asynchronous code.
既然您已经对异步IO进行了一些设计,那么让我们探索Python的实现。 Python的asyncio软件包(在Python 3.4中引入)及其两个关键字async和await具有不同的用途,但可以一起帮助您声明,构建,执行和管理异步代码。
async / await语法和本机协同程序 (The async/await Syntax and Native Coroutines)
A Word of Caution: Be careful what you read out there on the Internet. Python’s async IO API has evolved rapidly from Python 3.4 to Python 3.7. Some old patterns are no longer used, and some things that were at first disallowed are now allowed through new introductions. For all I know, this tutorial will join the club of the outdated soon too.
注意 :请注意在Internet上阅读的内容。 Python的异步IO API已从Python 3.4Swift发展到Python 3.7。 不再使用某些旧模式,现在通过新的介绍允许一些最初被禁止的功能。 就我所知,本教程也将很快加入过时的俱乐部。
At the heart of async IO are coroutines. A coroutine is a specialized version of a Python generator function. Let’s start with a baseline definition and then build off of it as you progress here: a coroutine is a function that can suspend its execution before reaching return, and it can indirectly pass control to another coroutine for some time.
异步IO的核心是协程。 协程是Python生成器函数的专用版本。 让我们从基线定义开始,然后在此处进行构建:协程是一个函数,可以在到达return之前暂停其执行,并且可以将控制权间接传递给另一个协程一段时间。
Later, you’ll dive a lot deeper into how exactly the traditional generator is repurposed into a coroutine. For now, the easiest way to pick up how coroutines work is to start making some.
稍后,您将更深入地研究如何将传统生成器准确地用于协程。 目前,了解协程工作方式的最简单方法是开始制作协程。
Let’s take the immersive approach and write some async IO code. This short program is the Hello World of async IO but goes a long way towards illustrating its core functionality:
让我们采用沉浸式方法并编写一些异步IO代码。 这个简短的程序是异步IO的Hello World ,但是在说明其核心功能方面还有很长的路要走:
When you execute this file, take note of what looks different than if you were to define the functions with just def and time.sleep():
执行此文件时,请注意与仅使用def和time.sleep()定义函数的外观有所不同:
$ python3 countasync.py
$ python3 countasync.py
One
One
One
One
One
One
Two
Two
Two
Two
Two
Two
countasync.py executed in 1.01 seconds.
countasync.py executed in 1.01 seconds.
The order of this output is the heart of async IO. Talking to each of the calls to count() is a single event loop, or coordinator. When each task reaches await asyncio.sleep(1), the function yells up to the event loop and gives control back to it, saying, “I’m going to be sleeping for 1 second. Go ahead and let something else meaningful be done in the meantime.”
此输出的顺序是异步IO的核心。 与count()每个调用进行交谈都是一个事件循环或协调器。 当每个任务到达await asyncio.sleep(1) ,该函数都会大喊事件循环并返回控制权,说:“我要睡一秒钟。 继续,让其他有意义的事情同时进行。”
Contrast this to the synchronous version:
将此与同步版本进行对比:
When executed, there is a slight but critical change in order and execution time:
当执行时,顺序和执行时间会有微小但关键的变化:
$ python3 countsync.py
$ python3 countsync.py
One
One
Two
Two
One
One
Two
Two
One
One
Two
Two
countsync.py executed in 3.01 seconds.
countsync.py executed in 3.01 seconds.
While using time.sleep() and asyncio.sleep() may seem banal, they are used as stand-ins for any time-intensive processes that involve wait time. (The most mundane thing you can wait on is a sleep() call that does basically nothing.) That is, time.sleep() can represent any time-consuming blocking function call, while asyncio.sleep() is used to stand in for a non-blocking call (but one that also takes some time to complete).
虽然使用asyncio.sleep() time.sleep()和asyncio.sleep()似乎是平庸的,但它们可以用作任何涉及等待时间的时间密集型进程的替身。 (您可以等待的最普通的事情是sleep()调用,该调用基本上什么都不做。)也就是说, time.sleep()可以表示任何耗时的阻塞函数调用,而asyncio.sleep()则可以用来代表进行非阻塞的呼叫(但也需要一些时间才能完成)。
As you’ll see in the next section, the benefit of awaiting something, including asyncio.sleep(), is that the surrounding function can temporarily cede control to another function that’s more readily able to do something immediately. In contrast, time.sleep() or any other blocking call is incompatible with asynchronous Python code, because it will stop everything in its tracks for the duration of the sleep time.
正如您将在下一节中看到的那样,等待某些内容(包括asyncio.sleep()的好处是,周围的函数可以暂时将控制权asyncio.sleep()另一个更容易立即执行某项功能的函数。 相反, time.sleep()或任何其他阻塞调用与异步Python代码不兼容,因为它将在睡眠时间内停止轨道中的所有内容。
异步IO规则 (The Rules of Async IO)
At this point, a more formal definition of async, await, and the coroutine functions that they create are in order. This section is a little dense, but getting a hold of async/await is instrumental, so come back to this if you need to:
此时, async , await和它们创建的协程函数的更正式定义是有序的。 这部分内容比较繁琐,但是掌握async / await非常重要,因此,如果需要,请回到async :
-
The syntax
async defintroduces either a native coroutine or an asynchronous generator. The expressionsasync withandasync forare also valid, and you’ll see them later on. -
The keyword
awaitpasses function control back to the event loop. (It suspends the execution of the surrounding coroutine.) If Python encounters anawait f()expression in the scope ofg(), this is howawaittells the event loop, “Suspend execution ofg()until whatever I’m waiting on—the result off()—is returned. In the meantime, go let something else run.”
语法
async def引入了本机协程或异步生成器 。async with和async for的表达式也有效,稍后您将看到它们。关键字
await将功能控制传递回事件循环。 (它暂停了周围协程的执行。)如果Python在g()范围内遇到await f()表达式,这就是await告诉事件循环的方式,“暂停g()执行,直到我等待的是onf()返回f()的结果f()。 同时,让其他东西运行。”
In code, that second bullet point looks roughly like this:
在代码中,第二个要点大致如下所示:
There’s also a strict set of rules around when and how you can and cannot use async/await. These can be handy whether you are still picking up the syntax or already have exposure to using async/await:
关于何时以及如何以及不能使用async / await的一套严格的规则。 无论您仍是语法还是已经使用async / await这些都可以很方便:
-
A function that you introduce with
async defis a coroutine. It may useawait,return, oryield, but all of these are optional. Declaringasync def noop(): passis valid:-
Using
awaitand/orreturncreates a coroutine function. To call a coroutine function, you mustawaitit to get its results. -
It is less common (and only recently legal in Python) to use
yieldin anasync defblock. This creates an asynchronous generator, which you iterate over withasync for. Forget about async generators for the time being and focus on getting down the syntax for coroutine functions, which useawaitand/orreturn. -
Anything defined with
async defmay not useyield from, which will raise aSyntaxError.
-
-
Just like it’s a
SyntaxErrorto useyieldoutside of adeffunction, it is aSyntaxErrorto useawaitoutside of anasync defcoroutine. You can only useawaitin the body of coroutines.
-
您使用
async def引入的功能是协程。 它可以使用await,return或yield,但是所有这些都是可选的。 声明async def noop(): pass有效:使用
await和/或return创建协程函数。 要调用协程函数,必须await它以获得结果。在
async def块中使用yield情况不太普遍(并且只有最近才在Python中合法)。 这将创建一个异步生成器 ,您可以使用async for迭代。 暂时不要使用异步生成器,而将重点放在获取使用await和/或return协程函数的语法上。用
async def定义的任何内容都可能不使用yield from,这将引发SyntaxError。
就像它是一个
SyntaxError,以使用yield一个外部def功能,它是一个SyntaxError使用await的外部async def协程。 您只能在协程体内使用await。
Here are some terse examples meant to summarize the above few rules:
以下是一些简短的示例,旨在总结上述几条规则:
async async def def ff (( xx ):
):
y y = = await await zz (( xx ) ) # OK - `await` and `return` allowed in coroutines
# OK - `await` and `return` allowed in coroutines
return return y
y
async async def def gg (( xx ):
):
yield yield x x # OK - this is an async generator
# OK - this is an async generator
async async def def mm (( xx ):
):
yield from yield from gengen (( xx ) ) # No - SyntaxError
# No - SyntaxError
def def mm (( xx ):
):
y y = = await await zz (( xx ) ) # Still no - SyntaxError (no `async def` here)
# Still no - SyntaxError (no `async def` here)
return return y
y
Finally, when you use await f(), it’s required that f() be an object that is awaitable. Well, that’s not very helpful, is it? For now, just know that an awaitable object is either (1) another coroutine or (2) an object defining an .__await__() dunder method that returns an iterator. If you’re writing a program, for the large majority of purposes, you should only need to worry about case #1.
最后,当您使用await f() ,要求f()是awaitable的对象。 好吧,这不是很有帮助,是吗? 现在,只知道一个可等待的对象是(1)另一个协程或(2)定义返回迭代器的.__await__() dunder方法的对象。 如果您正在编写程序,则出于大多数目的,您只需要担心案例1。
That brings us to one more technical distinction that you may see pop up: an older way of marking a function as a coroutine is to decorate a normal def function with @asyncio.coroutine. The result is a generator-based coroutine. This construction has been outdated since the async/await syntax was put in place in Python 3.5.
这给我们带来了另一个可能会弹出的技术区别:将函数标记为协程的一种较旧的方法是使用@asyncio.coroutine装饰一个普通的def函数。 结果是基于生成器的协程 。 自从Python 3.5中async / await语法以来,这种构造已经过时了。
These two coroutines are essentially equivalent (both are awaitable), but the first is generator-based, while the second is a native coroutine:
这两个协程在本质上是等效的(两者都是可以等待的),但是第一个协程是基于生成器的 ,而第二个是原生协程 :
If you’re writing any code yourself, prefer native coroutines for the sake of being explicit rather than implicit. Generator-based coroutines will be removed in Python 3.10.
如果您自己编写任何代码,则最好使用本机协程,以使其显式而不是隐式。 基于生成器的协程将在Python 3.10中删除 。
Towards the latter half of this tutorial, we’ll touch on generator-based coroutines for explanation’s sake only. The reason that async/await were introduced is to make coroutines a standalone feature of Python that can be easily differentiated from a normal generator function, thus reducing ambiguity.
在本教程的后半部分,我们仅出于解释的目的而涉及基于生成器的协程。 引入async / await的原因是为了使协程成为Python的独立功能,可以很容易地将其与普通的生成器功能区分开来,从而减少了歧义。
Don’t get bogged down in generator-based coroutines, which have been deliberately outdated by async/await. They have their own small set of rules (for instance, await cannot be used in a generator-based coroutine) that are largely irrelevant if you stick to the async/await syntax.
不要陷入基于生成器的协程中,这些协程已经被async / await 故意过时了。 它们具有自己的一小套规则(例如,不能在基于生成器的协程中使用await ),如果您坚持使用async / await语法,则它们在很大程度上是不相关的。
Without further ado, let’s take on a few more involved examples.
事不宜迟,让我们举一些更多的例子。
Here’s one example of how async IO cuts down on wait time: given a coroutine makerandom() that keeps producing random integers in the range [0, 10], until one of them exceeds a threshold, you want to let multiple calls of this coroutine not need to wait for each other to complete in succession. You can largely follow the patterns from the two scripts above, with slight changes:
这是一个异步IO如何减少等待时间的示例:给定一个协程makerandom() ,该协程不断产生范围为[ makerandom() ]的随机整数,直到其中一个超过阈值为止,您要让该协程多次调用不需要等待彼此相继完成。 您可以在很大程度上遵循上述两个脚本的模式,并稍作更改:
#!/usr/bin/env python3
#!/usr/bin/env python3
# rand.py
# rand.py
import import asyncio
asyncio
import import random
random
# ANSI colors
# ANSI colors
c c = = (
(
"" 3333 [0m"[0m" , , # End of color
# End of color
"" 3333 [36m"[36m" , , # Cyan
# Cyan
"" 3333 [91m"[91m" , , # Red
# Red
"" 3333 [35m"[35m" , , # Magenta
# Magenta
)
)
async async def def randintrandint (( aa : : intint , , bb : : intint ) ) -> -> intint :
:
return return randomrandom .. randintrandint (( aa , , bb )
)
async async def def makerandommakerandom (( idxidx : : intint , , thresholdthreshold : : int int = = 66 ) ) -> -> intint :
:
printprint (( cc [[ idx idx + + 11 ] ] + + ff "Initiated makerandom("Initiated makerandom( {idx}{idx} ).")." )
)
i i = = await await randintrandint (( 00 , , 1010 )
)
while while i i <= <= thresholdthreshold :
:
printprint (( cc [[ idx idx + + 11 ] ] + + ff "makerandom("makerandom( {idx}{idx} ) == ) == {i}{i} too low; retrying." too low; retrying." )
)
await await asyncioasyncio .. sleepsleep (( idx idx + + 11 )
)
i i = = await await randintrandint (( 00 , , 1010 )
)
printprint (( cc [[ idx idx + + 11 ] ] + + ff "---> Finished: makerandom("---> Finished: makerandom( {idx}{idx} ) == ) == {i}{i} " " + + cc [[ 00 ])
])
return return i
i
async async def def mainmain ():
():
res res = = await await asyncioasyncio .. gathergather (( ** (( makerandommakerandom (( ii , , 10 10 - - i i - - 11 ) ) for for i i in in rangerange (( 33 )))
)))
return return res
res
if if __name__ __name__ == == "__main__""__main__" :
:
randomrandom .. seedseed (( 444444 )
)
r1r1 , , r2r2 , , r3 r3 = = asyncioasyncio .. runrun (( mainmain ())
())
printprint ()
()
printprint (( ff "r1: "r1: {r1}{r1} , r2: , r2: {r2}{r2} , r3: , r3: {r3}{r3} "" )
)
The colorized output says a lot more than I can and gives you a sense for how this script is carried out:
彩色输出的内容超出了我的理解范围,使您对如何执行此脚本有所了解:
This program uses one main coroutine, makerandom(), and runs it concurrently across 3 different inputs. Most programs will contain small, modular coroutines and one wrapper function that serves to chain each of the smaller coroutines together. main() is then used to gather tasks (futures) by mapping the central coroutine across some iterable or pool.
该程序使用一个主协程makerandom() ,并在3个不同的输入上同时运行它。 大多数程序将包含小型模块化协程和一个包装器功能,用于将每个较小的协程链接在一起。 main()然后用于通过在一些可迭代或池中映射中央协程来收集任务(未来)。
In this miniature example, the pool is range(3). In a fuller example presented later, it is a set of URLs that need to be requested, parsed, and processed concurrently, and main() encapsulates that entire routine for each URL.
在此微型示例中,池为range(3) 。 在稍后提供的更完整的示例中,它是需要同时请求,解析和处理的一组URL,并且main()为每个URL封装整个例程。
While “making random integers” (which is CPU-bound more than anything) is maybe not the greatest choice as a candidate for asyncio, it’s the presence of asyncio.sleep() in the example that is designed to mimic an IO-bound process where there is uncertain wait time involved. For example, the asyncio.sleep() call might represent sending and receiving not-so-random integers between two clients in a message application.
尽管“制作随机整数”(比CPU绑定更多的东西)可能不是asyncio的最佳选择,但在示例中正是asyncio.sleep()的存在旨在模仿IO绑定的过程等待时间不确定的地方。 例如, asyncio.sleep()调用可能表示消息应用程序中两个客户端之间发送和接收非随机整数。
异步IO设计模式 (Async IO Design Patterns)
Async IO comes with its own set of possible script designs, which you’ll get introduced to in this section.
异步IO带有自己的一组可能的脚本设计,本节将介绍它们。
链协程 (Chaining Coroutines)
A key feature of coroutines is that they can be chained together. (Remember, a coroutine object is awaitable, so another coroutine can await it.) This allows you to break programs into smaller, manageable, recyclable coroutine:
协程的一个关键特征是它们可以链接在一起。 (请记住,一个协程对象是可以await ,因此另一个协程可以await它。)这使您可以将程序分解为较小的,可管理的,可回收的协程:
Pay careful attention to the output, where part1() sleeps for a variable amount of time, and part2() begins working with the results as they become available:
注意输出, part1()睡眠一段可变的时间, part2()在结果可用时开始处理它们:
$ python3 chained.py $ python3 chained.py 9 9 6 6 3
3
part1(9) sleeping for 4 seconds.
part1(9) sleeping for 4 seconds.
part1(6) sleeping for 4 seconds.
part1(6) sleeping for 4 seconds.
part1(3) sleeping for 0 seconds.
part1(3) sleeping for 0 seconds.
Returning part1(3) == result3-1.
Returning part1(3) == result3-1.
part2(3, 'result3-1') sleeping for 4 seconds.
part2(3, 'result3-1') sleeping for 4 seconds.
Returning part1(9) == result9-1.
Returning part1(9) == result9-1.
part2(9, 'result9-1') sleeping for 7 seconds.
part2(9, 'result9-1') sleeping for 7 seconds.
Returning part1(6) == result6-1.
Returning part1(6) == result6-1.
part2(6, 'result6-1') sleeping for 4 seconds.
part2(6, 'result6-1') sleeping for 4 seconds.
Returning part2(3, 'result3-1') == result3-2 derived from result3-1.
Returning part2(3, 'result3-1') == result3-2 derived from result3-1.
-->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds).
-->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds).
Returning part2(6, 'result6-1') == result6-2 derived from result6-1.
Returning part2(6, 'result6-1') == result6-2 derived from result6-1.
-->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds).
-->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds).
Returning part2(9, 'result9-1') == result9-2 derived from result9-1.
Returning part2(9, 'result9-1') == result9-2 derived from result9-1.
-->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds).
-->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds).
Program finished in 11.01 seconds.
Program finished in 11.01 seconds.
In this setup, the runtime of main() will be equal to the maximum runtime of the tasks that it gathers together and schedules.
在此设置中, main()的运行时间将等于它收集在一起并计划的任务的最大运行时间。
使用队列 (Using a Queue)
The asyncio package provides queue classes that are designed to be similar to classes of the queue module. In our examples so far, we haven’t really had a need for a queue structure. In chained.py, each task (future) is composed of a set of coroutines that explicitly await each other and pass through a single input per chain.
asyncio软件包提供的队列类旨在与queue模块的类相似。 到目前为止,在我们的示例中,我们实际上并不需要队列结构。 在chained.py ,每个任务(未来)都由一组协程组成,这些协程明确地彼此等待并通过每个链上的单个输入。
There is an alternative structure that can also work with async IO: a number of producers, which are not associated with each other, add items to a queue. Each producer may add multiple items to the queue at staggered, random, unannounced times. A group of consumers pull items from the queue as they show up, greedily and without waiting for any other signal.
还有一种可以与异步IO一起使用的替代结构:彼此不相关的许多生产者将项目添加到队列中。 每个生产者可以在交错,随机,未通知的时间将多个项目添加到队列中。 一群消费者在贪婪地出现时将它们从队列中拉出,而不必等待任何其他信号。
In this design, there is no chaining of any individual consumer to a producer. The consumers don’t know the number of producers, or even the cumulative number of items that will be added to the queue, in advance.
在这种设计中,没有任何个人消费者链接到生产者。 消费者不知道生产者的数量,甚至不知道要添加到队列中的项目的累计数量。
It takes an individual producer or consumer a variable amount of time to put and extract items from the queue, respectively. The queue serves as a throughput that can communicate with the producers and consumers without them talking to each other directly.
每个生产者或消费者花费可变的时间分别从队列中放入和提取项目。 队列用作可以与生产者和消费者进行通信的吞吐量,而无需他们彼此直接交谈。
Note: While queues are often used in threaded programs because of the thread-safety of queue.Queue(), you shouldn’t need to concern yourself with thread safety when it comes to async IO. (The exception is when you’re combining the two, but that isn’t done in this tutorial.)
注意 :尽管由于queue.Queue()的线程安全性, queue.Queue()队列经常在线程程序中使用,但是当涉及异步IO时,您不必担心线程安全。 (例外是将两者结合在一起时,但本教程中没有这样做。)
One use-case for queues (as is the case here) is for the queue to act as a transmitter for producers and consumers that aren’t otherwise directly chained or associated with each other.
队列的一个用例(如此处的情况)是队列充当生产者和消费者的发送者,否则它们不会直接链接或彼此关联。
The synchronous version of this program would look pretty dismal: a group of blocking producers serially add items to the queue, one producer at a time. Only after all producers are done can the queue be processed, by one consumer at a time processing item-by-item. There is a ton of latency in this design. Items may sit idly in the queue rather than be picked up and processed immediately.
该程序的同步版本看起来非常令人沮丧:一组阻塞的生产者将项目串行添加到队列中,一次添加一个生产者。 只有在所有生产者都完成之后,才能由一个消费者逐项处理队列。 此设计存在大量延迟。 物品可能闲置地排在队列中,而不是立即拿起并处理。
An asynchronous version, asyncq.py, is below. The challenging part of this workflow is that there needs to be a signal to the consumers that production is done. Otherwise, await q.get() will hang indefinitely, because the queue will have been fully processed, but consumers won’t have any idea that production is complete.
下面是一个异步版本asyncq.py 。 此工作流程中具有挑战性的部分是,需要向消费者发出生产已完成的信号。 否则, await q.get()将无限期地挂起,因为队列已被完全处理,但是消费者不会知道生产已经完成。
(Big thanks for some help from a StackOverflow user for helping to straighten out main(): the key is to await q.join(), which blocks until all items in the queue have been received and processed, and then to cancel the consumer tasks, which would otherwise hang up and wait endlessly for additional queue items to appear.)
(非常感谢StackOverflow 用户提供的一些帮助,帮助他们整理了main() :关键是await q.join() ,该操作将阻塞直到队列中的所有项目都已接收并处理,然后取消使用方任务,否则将挂断并无休止地等待其他队列项目出现。)
Here is the full script:
这是完整的脚本:
The first few coroutines are helper functions that return a random string, a fractional-second performance counter, and a random integer. A producer puts anywhere from 1 to 5 items into the queue. Each item is a tuple of (i, t) where i is a random string and t is the time at which the producer attempts to put the tuple into the queue.
前几个协程是辅助函数,它们返回一个随机字符串,一个小数秒性能计数器和一个随机整数。 生产者将1到5个项目放入队列中。 每个项目都是(i, t)的元组,其中i是随机字符串, t是生产者尝试将元组放入队列的时间。
When a consumer pulls an item out, it simply calculates the elapsed time that the item sat in the queue using the timestamp that the item was put in with.
消费者将商品拉出时,它仅使用放入商品的时间戳来计算商品在队列中的经过时间。
Keep in mind that asyncio.sleep() is used to mimic some other, more complex coroutine that would eat up time and block all other execution if it were a regular blocking function.
请记住, asyncio.sleep()用于模仿其他一些更复杂的协程,如果这是常规的阻止函数,则会消耗时间并阻止所有其他执行。
Here is a test run with two producers and five consumers:
这是由两个生产者和五个消费者进行的测试:
$ python3 asyncq.py -p $ python3 asyncq.py -p 2 -c 2 -c 5
5
Producer 0 sleeping for 3 seconds.
Producer 0 sleeping for 3 seconds.
Producer 1 sleeping for 3 seconds.
Producer 1 sleeping for 3 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 sleeping for 3 seconds.
Consumer 2 sleeping for 3 seconds.
Consumer 3 sleeping for 5 seconds.
Consumer 3 sleeping for 5 seconds.
Consumer 4 sleeping for 4 seconds.
Consumer 4 sleeping for 4 seconds.
Producer 0 added <377b1e8f82> to queue.
Producer 0 added <377b1e8f82> to queue.
Producer 0 sleeping for 5 seconds.
Producer 0 sleeping for 5 seconds.
Producer 1 added <413b8802f8> to queue.
Producer 1 added <413b8802f8> to queue.
Consumer 1 got element <377b1e8f82> in 0.00013 seconds.
Consumer 1 got element <377b1e8f82> in 0.00013 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 got element <413b8802f8> in 0.00009 seconds.
Consumer 2 got element <413b8802f8> in 0.00009 seconds.
Consumer 2 sleeping for 4 seconds.
Consumer 2 sleeping for 4 seconds.
Producer 0 added <06c055b3ab> to queue.
Producer 0 added <06c055b3ab> to queue.
Producer 0 sleeping for 1 seconds.
Producer 0 sleeping for 1 seconds.
Consumer 0 got element <06c055b3ab> in 0.00021 seconds.
Consumer 0 got element <06c055b3ab> in 0.00021 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 0 sleeping for 4 seconds.
Producer 0 added <17a8613276> to queue.
Producer 0 added <17a8613276> to queue.
Consumer 4 got element <17a8613276> in 0.00022 seconds.
Consumer 4 got element <17a8613276> in 0.00022 seconds.
Consumer 4 sleeping for 5 seconds.
Consumer 4 sleeping for 5 seconds.
Program completed in 9.00954 seconds.
Program completed in 9.00954 seconds.
In this case, the items process in fractions of a second. A delay can be due to two reasons:
在这种情况下,项目将在几分之一秒内完成处理。 延迟可能有两个原因:
- Standard, largely unavoidable overhead
- Situations where all consumers are sleeping when an item appears in the queue
- 标准,在很大程度上是不可避免的开销
- 当项目出现在队列中时所有消费者都在睡觉的情况
With regards to the second reason, luckily, it is perfectly normal to scale to hundreds or thousands of consumers. You should have no problem with python3 asyncq.py -p 5 -c 100. The point here is that, theoretically, you could have different users on different systems controlling the management of producers and consumers, with the queue serving as the central throughput.
关于第二个原因,幸运的是,扩展到成百上千的消费者是完全正常的。 python3 asyncq.py -p 5 -c 100应该没有问题。 这里的重点是,从理论上讲,您可以在不同的系统上使用不同的用户来控制生产者和消费者的管理,而队列则作为中心吞吐量。
So far, you’ve been thrown right into the fire and seen three related examples of asyncio calling coroutines defined with async and await. If you’re not completely following or just want to get deeper into the mechanics of how modern coroutines came to be in Python, you’ll start from square one with the next section.
到目前为止,您已经陷入asyncio ,看到了三个与asyncio调用用async和await定义的协程相关的相关示例。 如果您不完全遵循或只是想更深入地了解现代协程在Python中的使用机理,那么您将从下一节开始。
异步IO的根源 (Async IO’s Roots in Generators)
Earlier, you saw an example of the old-style generator-based coroutines, which have been outdated by more explicit native coroutines. The example is worth re-showing with a small tweak:
之前,您看到了一个基于生成器的老式协程的示例,这些协程已被更明确的本地协程过时了。 该示例值得稍作调整以重新显示:
As an experiment, what happens if you call py34_coro() or py35_coro() on its own, without await, or without any calls to asyncio.run() or other asyncio “porcelain” functions? Calling a coroutine in isolation returns a coroutine object:
作为实验,如果您不经await或不对asyncio.run()或其他asyncio “瓷器”函数的任何调用而asyncio.run()调用py34_coro()或py35_coro()会发生什么情况? 孤立地调用协程将返回协程对象:
>>> py35_coro()
<coroutine object py35_coro at 0x10126dcc8>
This isn’t very interesting on its surface. The result of calling a coroutine on its own is an awaitable coroutine object.
表面上这不是很有趣。 单独调用协程的结果是一个等待的协程对象 。
Time for a quiz: what other feature of Python looks like this? (What feature of Python doesn’t actually “do much” when it’s called on its own?)
测验时间:Python的其他功能是什么样子? (当单独调用Python时,Python的什么功能实际上并没有“做什么”?)
Hopefully you’re thinking of generators as an answer to this question, because coroutines are enhanced generators under the hood. The behavior is similar in this regard:
希望您将生成器视为此问题的答案,因为协程是引擎盖下的增强型生成器。 在这方面,行为是相似的:
>>> def gen():
... yield 0x10, 0x20, 0x30
...
>>> g = gen()
>>> g # Nothing much happens - need to iterate with `.__next__()`
<generator object gen at 0x1012705e8>
>>> next(g)
(16, 32, 48)
Generator functions are, as it so happens, the foundation of async IO (regardless of whether you declare coroutines with async def rather than the older @asyncio.coroutine wrapper). Technically, await is more closely analogous to yield from than it is to yield. (But remember that yield from x() is just syntactic sugar to replace for i in x(): yield i.)
碰巧的是,生成器函数是异步IO的基础(无论您是否使用async def声明协程,而不是使用旧的@asyncio.coroutine包装器声明协程)。 从技术上讲, await比yield from更接近yield 。 (但是请记住, yield from x()只是语法上的糖,可以代替for i in x(): yield i 。)
One critical feature of generators as it pertains to async IO is that they can effectively be stopped and restarted at will. For example, you can break out of iterating over a generator object and then resume iteration on the remaining values later. When a generator function reaches yield, it yields that value, but then it sits idle until it is told to yield its subsequent value.
与异步IO有关的生成器的一项关键功能是可以有效地随意停止和重新启动它们。 例如,您可以break对生成器对象的迭代,然后在以后的剩余值上恢复迭代。 当生成器函数达到yield ,它将产生该值,但随后会处于空闲状态,直到被告知要产生其后续值为止。
This can be fleshed out through an example:
可以通过一个例子充实一下:
>>> from itertools import cycle
>>> def endless():
... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever"""
... yield from cycle((9, 8, 7, 6))
>>> e = endless()
>>> total = 0
>>> for i in e:
... if total < 30:
... print(i, end=" ")
... total += i
... else:
... print()
... # Pause execution. We can resume later.
... break
9 8 7 6 9 8 7 6 9 8 7 6 9 8
>>> # Resume
>>> next(e), next(e), next(e)
(6, 9, 8)
The await keyword behaves similarly, marking a break point at which the coroutine suspends itself and lets other coroutines work. “Suspended,” in this case, means a coroutine that has temporarily ceded control but not totally exited or finished. Keep in mind that yield, and by extension yield from and await, mark a break point in a generator’s execution.
关键字await行为类似,它标记了协程自身暂停并让其他协程工作的断点。 在这种情况下,“暂停”是指已暂时放弃控制权但尚未完全退出或结束的协程。 请记住, yield ,并通过扩展yield from和await ,在生成器的执行中标记一个断点。
This is the fundamental difference between functions and generators. A function is all-or-nothing. Once it starts, it won’t stop until it hits a return, then pushes that value to the caller (the function that calls it). A generator, on the other hand, pauses each time it hits a yield and goes no further. Not only can it push this value to calling stack, but it can keep a hold of its local variables when you resume it by calling next() on it.
这是函数和生成器之间的根本区别。 一个功能是全有还是全无。 一旦启动,它直到return时才会停止,然后将该值推送给调用方(调用它的函数)。 另一方面,发电机每次达到yield都会暂停,并且不再前进。 它不仅可以将该值推送到调用堆栈,而且还可以通过在其上调用next()来保留其局部变量。
There’s a second and lesser-known feature of generators that also matters. You can send a value into a generator as well through its .send() method. This allows generators (and coroutines) to call (await) each other without blocking. I won’t get any further into the nuts and bolts of this feature, because it matters mainly for the implementation of coroutines behind the scenes, but you shouldn’t ever really need to use it directly yourself.
生成器的第二个鲜为人知的功能也很重要。 您也可以通过其.send()方法将值发送到生成器中。 这允许生成器(和协程)在不阻塞的情况下相互调用( await )。 我将不进一步介绍此功能,因为它主要对幕后协程的实现很重要,但是您根本不需要自己直接使用它。
If you’re interested in exploring more, you can start at PEP 342, where coroutines were formally introduced. Brett Cannon’s How the Heck Does Async-Await Work in Python is also a good read, as is the PYMOTW writeup on asyncio. Lastly, there’s David Beazley’s Curious Course on Coroutines and Concurrency, which dives deep into the mechanism by which coroutines run.
如果您有兴趣探索更多内容,可以从正式引入协程的PEP 342开始。 布雷特·坎农(Brett Cannon)的《 如何在Python中进行异步等待》也是一本不错的书, 关于asyncio的PYMOTW文章asyncio 。 最后,还有大卫·比兹利(David Beazley) 关于协程和并发的好奇课程 ,深入探讨了协程运行的机制。
Let’s try to condense all of the above articles into a few sentences: there is a particularly unconventional mechanism by which these coroutines actually get run. Their result is an attribute of the exception object that gets thrown when their .send() method is called. There’s some more wonky detail to all of this, but it probably won’t help you use this part of the language in practice, so let’s move on for now.
让我们尝试将以上所有文章压缩成几句话:这些协程实际上是通过一种特殊的非常规机制运行的。 它们的结果是异常对象的属性,该异常对象在调用其.send()方法时被抛出。 所有这些还有一些更奇怪的细节,但它可能无法帮助您在实践中使用这部分语言,因此让我们继续。
To tie things together, here are some key points on the topic of coroutines as generators:
为了将事情联系在一起,以下是协程作为生成器的一些关键点:
-
Coroutines are repurposed generators that take advantage of the peculiarities of generator methods.
-
Old generator-based coroutines use
yield fromto wait for a coroutine result. Modern Python syntax in native coroutines simply replacesyield fromwithawaitas the means of waiting on a coroutine result. Theawaitis analogous toyield from, and it often helps to think of it as such. -
The use of
awaitis a signal that marks a break point. It lets a coroutine temporarily suspend execution and permits the program to come back to it later.
协程是经过重新利用的生成器 ,可以利用生成器方法的独特性。
基于老式生成器的协程使用
yield from等待协程结果。 本机协程中的现代Python语法仅将yield from与await替换为等待协程结果的方法。await与从yield from类似,通常有助于将其视为yield from。使用
await是标记断点的信号。 它允许协程暂时中止执行,并允许程序稍后返回。
其他功能: async for和异步生成器+理解 (Other Features: async for and Async Generators + Comprehensions)
Along with plain async/await, Python also enables async for to iterate over an asynchronous iterator. The purpose of an asynchronous iterator is for it to be able to call asynchronous code at each stage when it is iterated over.
与普通的async / await ,Python还使async for在异步迭代器上进行迭代 。 异步迭代器的目的是使它能够在迭代时在每个阶段调用异步代码。
A natural extension of this concept is an asynchronous generator. Recall that you can use await, return, or yield in a native coroutine. Using yield within a coroutine became possible in Python 3.6 (via PEP 525), which introduced asynchronous generators with the purpose of allowing await and yield to be used in the same coroutine function body:
这个概念的自然扩展是异步生成器 。 回想一下,您可以在本地协程中使用await , return或yield 。 在Python 3.6(通过PEP 525)中,可以在协程中使用yield ,它引入了异步生成器,目的是允许在同一个协程函数体中使用await和yield :
>>> async def mygen(u: int = 10):
... """Yield powers of 2."""
... i = 0
... while i < u:
... yield 2 ** i
... i += 1
... await asyncio.sleep(0.1)
Last but not least, Python enables asynchronous comprehension with async for. Like its synchronous cousin, this is largely syntactic sugar:
最后但并非最不重要的一点是,Python使用的async for启用了异步理解 。 像其同步表亲一样,这在很大程度上是语法糖:
>>> async def main():
... # This does *not* introduce concurrent execution
... # It is meant to show syntax only
... g = [i async for i in mygen()]
... f = [j async for j in mygen() if not (j // 3 % 5)]
... return g, f
...
>>> g, f = asyncio.run(main())
>>> g
[1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
>>> f
[1, 2, 16, 32, 256, 512]
This is a crucial distinction: neither asynchronous generators nor comprehensions make the iteration concurrent. All that they do is provide the look-and-feel of their synchronous counterparts, but with the ability for the loop in question to give up control to the event loop for some other coroutine to run.
这是一个关键的区别: 异步生成器和理解都不会使迭代并发 。 他们所做的只是提供同步对象的外观,但具有使相关循环放弃对事件循环的控制权以便其他协程运行的能力。
In other words, asynchronous iterators and asynchronous generators are not designed to concurrently map some function over a sequence or iterator. They’re merely designed to let the enclosing coroutine allow other tasks to take their turn. The async for and async with statements are only needed to the extent that using plain for or with would “break” the nature of await in the coroutine. This distinction between asynchronicity and concurrency is a key one to grasp.
换句话说,异步迭代器和异步生成器并未设计为在序列或迭代器上同时映射某些功能。 它们只是为了使封闭的协程允许其他任务轮流使用。 仅在使用plain for或with会“破坏”协程中await的性质的情况下,才需要async for和async with语句。 异步和并发之间的区别是要把握的关键。
事件循环和asyncio.run() (The Event Loop and asyncio.run())
You can think of an event loop as something like a while True loop that monitors coroutines, taking feedback on what’s idle, and looking around for things that can be executed in the meantime. It is able to wake up an idle coroutine when whatever that coroutine is waiting on becomes available.
您可以将事件循环视为类似于while True循环的事件,该循环监视协程,获取有关空闲状态的反馈并四处寻找可以同时执行的事情。 当协程正在等待的任何可用时,它能够唤醒空闲的协程。
Thus far, the entire management of the event loop has been implicitly handled by one function call:
到目前为止,事件循环的整个管理已由一个函数调用隐式处理:
asyncioasyncio .. runrun (( mainmain ()) ()) # Python 3.7+
# Python 3.7+
asyncio.run(), introduced in Python 3.7, is responsible for getting the event loop, running tasks until they are marked as complete, and then closing the event loop.
Python 3.7中引入的asyncio.run()负责获取事件循环,运行任务直到将其标记为完成,然后关闭事件循环。
There’s a more long-winded way of managing the asyncio event loop, with get_event_loop(). The typical pattern looks like this:
使用get_event_loop()可以更get_event_loop()管理asyncio事件循环。 典型的模式如下所示:
You’ll probably see loop.get_event_loop() floating around in older examples, but unless you have a specific need to fine-tune control over the event loop management, asyncio.run() should be sufficient for most programs.
在较早的示例中,您可能会看到loop.get_event_loop() ,但是除非您有特定的需求需要微调对事件循环管理的控制, asyncio.run()对于大多数程序而言就足够了。
If you do need to interact with the event loop within a Python program, loop is a good-old-fashioned Python object that supports introspection with loop.is_running() and loop.is_closed(). You can manipulate it if you need to get more fine-tuned control, such as in scheduling a callback by passing the loop as an argument.
如果确实需要与Python程序中的事件循环进行交互,则loop是一种老式的Python对象,它支持使用loop.is_running()和loop.is_closed()内省。 如果您需要获得更精细的控制,则可以进行操作,例如在通过将循环作为参数传递来安排回调的过程中。
What is more crucial is understanding a bit beneath the surface about the mechanics of the event loop. Here are a few points worth stressing about the event loop.
更关键的是要对事件循环的机制有一些了解。 以下是有关事件循环的一些要点。
#1: Coroutines don’t do much on their own until they are tied to the event loop.
#1:协程在依靠事件循环之前并不会做很多事情。
You saw this point before in the explanation on generators, but it’s worth restating. If you have a main coroutine that awaits others, simply calling it in isolation has little effect:
您之前在有关生成器的说明中已经看到了这一点,但是值得重申一下。 如果您有一个等待他人的主要协程,则简单地单独调用它几乎没有效果:
>>> import asyncio
>>> async def main():
... print("Hello ...")
... await asyncio.sleep(1)
... print("World!")
>>> routine = main()
>>> routine
<coroutine object main at 0x1027a6150>
Remember to use asyncio.run() to actually force execution by scheduling the main() coroutine (future object) for execution on the event loop:
请记住使用asyncio.run()通过调度main()协程(未来对象)在事件循环上执行来实际强制执行:
>>> asyncio.run(routine)
Hello ...
World!
(Other coroutines can be executed with await. It is typical to wrap just main() in asyncio.run(), and chained coroutines with await will be called from there.)
(其他协程可以使用await来执行。通常将main()包装在asyncio.run() ,然后从那里调用带有await链式协程。)
#2: By default, an async IO event loop runs in a single thread and on a single CPU core. Usually, running one single-threaded event loop in one CPU core is more than sufficient. It is also possible to run event loops across multiple cores. Check out this talk by John Reese for more, and be warned that your laptop may spontaneously combust.
#2:默认情况下,异步IO事件循环在单个线程和单个CPU内核上运行。 通常,在一个CPU内核中运行一个单线程事件循环绰绰有余。 也可以跨多个内核运行事件循环。 请查看约翰·里斯(John Reese)的演讲,以获取更多信息,并被警告您的笔记本电脑可能会自燃。
#3. Event loops are pluggable. That is, you could, if you really wanted, write your own event loop implementation and have it run tasks just the same. This is wonderfully demonstrated in the uvloop package, which is an implementation of the event loop in Cython.
#3。 事件循环是可插入的。 也就是说,如果您确实需要,可以编写自己的事件循环实现,并使它运行相同的任务。 这在uvloop软件包中得到了很好的演示,该软件包是Cython中事件循环的实现。
That is what is meant by the term “pluggable event loop”: you can use any working implementation of an event loop, unrelated to the structure of the coroutines themselves. The asyncio package itself ships with two different event loop implementations, with the default being based on the selectors module. (The second implementation is built for Windows only.)
这就是“可插入事件循环”一词的含义:您可以使用事件循环的任何有效实现,而与协程本身的结构无关。 asyncio程序包本身带有两个不同的事件循环实现 ,默认实现基于selectors模块。 (第二种实现仅适用于Windows。)
完整程序:异步请求 (A Full Program: Asynchronous Requests)
You’ve made it this far, and now it’s time for the fun and painless part. In this section, you’ll build a web-scraping URL collector, areq.py, using aiohttp, a blazingly fast async HTTP client/server framework. (We just need the client part.) Such a tool could be used to map connections between a cluster of sites, with the links forming a directed graph.
到目前为止,您已经做到了,现在是时候进行有趣而轻松的工作了。 在本节中,您将使用aiohttp (一个非常快的异步HTTP客户端/服务器框架)构建一个抓取Web的URL收集器areq.py (我们只需要客户端部分。)这样的工具可用于映射站点集群之间的连接,链接形成有向图 。
Note: You may be wondering why Python’s requests package isn’t compatible with async IO. requests is built on top of urrlib3, which in turn uses Python’s http and socket modules.
注意 :您可能想知道为什么Python的requests包与异步IO不兼容。 requests建立在urrlib3 ,后者又使用Python的http和socket模块。
By default, socket operations are blocking. This means that Python won’t like await requests.get(url) because .get() is not awaitable. In contrast, almost everything in aiohttp is an awaitable coroutine, such as session.request() and response.text(). It’s a great package otherwise, but you’re doing yourself a disservice by using requests in asynchronous code.
默认情况下,套接字操作处于阻塞状态。 这意味着Python不会喜欢await requests.get(url) request.get await requests.get(url)因为.get()无法等待。 相反, aiohttp中的几乎所有aiohttp都是可等待的协程,例如session.request()和response.text() 。 否则,它是一个很棒的程序包,但是通过使用异步代码中的requests ,您正在对自己造成损害。
The high-level program structure will look like this:
高级程序结构如下所示:
-
Read a sequence of URLs from a local file,
urls.txt. -
Send GET requests for the URLs and decode the resulting content. If this fails, stop there for a URL.
-
Search for the URLs within
hreftags in the HTML of the responses. -
Write the results to
foundurls.txt. -
Do all of the above as asynchronously and concurrently as possible. (Use
aiohttpfor the requests, andaiofilesfor the file-appends. These are two primary examples of IO that are well-suited for the async IO model.)
从本地文件
urls.txt读取URL序列。发送对URL的GET请求并解码结果内容。 如果失败,请在此处停止输入URL。
在响应HTML中的
href标记内搜索URL。将结果写入
foundurls.txt。尽可能异步和同时执行上述所有操作。 (将
aiohttp用于请求,将aiofiles用于文件aiofiles。这是两个非常适合异步IO模型的IO主要示例。)
Here are the contents of urls.txt. It’s not huge, and contains mostly highly trafficked sites:
这是urls.txt的内容。 它并不庞大,并且包含流量最高的站点:
$ cat urls.txt
$ cat urls.txt
https://regex101.com/
https://regex101.com/
https://docs.python.org/3/this-url-will-404.html
https://docs.python.org/3/this-url-will-404.html
https://www.nytimes.com/guides/
https://www.nytimes.com/guides/
https://www.mediamatters.org/
https://www.mediamatters.org/
https://1.1.1.1/
https://1.1.1.1/
https://www.politico.com/tipsheets/morning-money
https://www.politico.com/tipsheets/morning-money
https://www.bloomberg.com/markets/economics
https://www.bloomberg.com/markets/economics
https://www.ietf.org/rfc/rfc2616.txt
https://www.ietf.org/rfc/rfc2616.txt
The second URL in the list should return a 404 response, which you’ll need to handle gracefully. If you’re running an expanded version of this program, you’ll probably need to deal with much hairier problems than this, such a server disconnections and endless redirects.
列表中的第二个URL应该返回404响应,您需要对其进行适当处理。 如果您正在运行此程序的扩展版本,则可能需要处理比这更棘手的问题,例如服务器断开连接和无止尽的重定向。
The requests themselves should be made using a single session, to take advantage of reusage of the session’s internal connection pool.
应该使用单个会话发出请求本身,以利用会话的内部连接池的重用。
Let’s take a look at the full program. We’ll walk through things step-by-step after:
让我们看一下完整的程序。 我们将逐步介绍以下内容:
This script is longer than our initial toy programs, so let’s break it down.
该脚本比我们最初的玩具程序要长,所以让我们对其进行分解。
The constant HREF_RE is a regular expression to extract what we’re ultimately searching for, href tags within HTML:
常量HREF_RE是一个正则表达式,用于提取我们最终在HTML中搜索的href标签:
>>> HREF_RE.search('Go to <a href="https://realpython.com/">Real Python</a>')
<re.Match object; span=(15, 45), match='href="https://realpython.com/"'>
The coroutine fetch_html() is a wrapper around a GET request to make the request and decode the resulting page HTML. It makes the request, awaits the response, and raises right away in the case of a non-200 status:
协程fetch_html()是GET请求的包装,用于发出请求并解码生成的页面HTML。 它发出请求,等待响应,并在非200状态下立即引发:
resp resp = = await await sessionsession .. requestrequest (( methodmethod == "GET""GET" , , urlurl == urlurl , , **** kwargskwargs )
)
respresp .. raise_for_statusraise_for_status ()
()
If the status is okay, fetch_html() returns the page HTML (a str). Notably, there is no exception handling done in this function. The logic is to propagate that exception to the caller and let it be handled there:
如果状态正常,则fetch_html()返回页面HTML(a str )。 值得注意的是,此功能没有完成任何异常处理。 逻辑是将该异常传播给调用者,并在那里进行处理:
We await session.request() and resp.text() because they’re awaitable coroutines. The request/response cycle would otherwise be the long-tailed, time-hogging portion of the application, but with async IO, fetch_html() lets the event loop work on other readily available jobs such as parsing and writing URLs that have already been fetched.
我们await session.request()和resp.text()因为它们是等待的协程。 请求/响应周期否则将是应用程序的长尾,耗时的部分,但是使用异步IO, fetch_html()可以使事件循环在其他易于使用的作业(例如,解析和写入已获取的URL)上工作。
Next in the chain of coroutines comes parse(), which waits on fetch_html() for a given URL, and then extracts all of the href tags from that page’s HTML, making sure that each is valid and formatting it as an absolute path.
协程链中的下一个是parse() ,它在fetch_html()上等待给定的URL,然后从该页面HTML中提取所有href标记,确保每个标记均有效并将其格式化为绝对路径。
Admittedly, the second portion of parse() is blocking, but it consists of a quick regex match and ensuring that the links discovered are made into absolute paths.
诚然, parse()的第二部分是阻塞的,但是它由快速的正则表达式匹配组成,并确保将发现的链接设置为绝对路径。
In this specific case, this synchronous code should be quick and inconspicuous. But just remember that any line within a given coroutine will block other coroutines unless that line uses yield, await, or return. If the parsing was a more intensive process, you might want to consider running this portion in its own process with loop.run_in_executor().
在这种特定情况下,此同步代码应该快速而不起眼。 但是,请记住,给定协程中的任何行都会阻塞其他协程,除非该行使用yield , await或return 。 如果解析是一个更加繁琐的过程,则可能需要考虑使用loop.run_in_executor()在其自己的过程中运行此部分。
Next, the coroutine write() takes a file object and a single URL, and waits on parse() to return a set of the parsed URLs, writing each to the file asynchronously along with its source URL through use of aiofiles, a package for async file IO.
接下来,协程write()接收一个文件对象和一个URL,然后等待parse()返回一set已解析的URL,通过使用aiofiles (用于打包的包)将每个URL及其源URL异步写入文件中。异步文件IO。
Lastly, bulk_crawl_and_write() serves as the main entry point into the script’s chain of coroutines. It uses a single session, and a task is created for each URL that is ultimately read from urls.txt.
最后, bulk_crawl_and_write()作为脚本协程链的主要入口。 它使用单个会话,并为最终从urls.txt读取的每个URL创建一个任务。
Here are a few additional points that deserve mention:
以下是一些值得一提的其他要点:
-
The default
ClientSessionhas an adapter with a maximum of 100 open connections. To change that, pass an instance ofasyncio.connector.TCPConnectortoClientSession. You can also specify limits on a per-host basis. -
You can specify max timeouts for both the session as a whole and for individual requests.
-
This script also uses
async with, which works with an asynchronous context manager. I haven’t devoted a whole section to this concept because the transition from synchronous to asynchronous context managers is fairly straightforward. The latter has to define.__aenter__()and.__aexit__()rather than.__exit__()and.__enter__(). As you might expect,async withcan only be used inside a coroutine function declared withasync def.
默认的
ClientSession具有最多100个打开连接的适配器 。 要更改此设置,asyncio.connector.TCPConnector的实例asyncio.connector.TCPConnector给ClientSession。 您还可以基于每个主机指定限制。您可以为整个会话和单个请求指定最大超时 。
该脚本还使用
async with,它与异步上下文管理器一起使用 。 我没有专门讨论这个概念,因为从同步上下文管理器到异步上下文管理器的转换非常简单。 后者必须定义.__aenter__()和.__aexit__()而不是.__exit__()和.__enter__()。 如您所料,async with只能在用async def声明的协程函数中使用。
If you’d like to explore a bit more, the companion files for this tutorial up at GitHub have comments and docstrings attached as well.
如果您想探索更多内容,可以在GitHub上的本教程随附文件中附加注释和文档字符串。
Here’s the execution in all of its glory, as areq.py gets, parses, and saves results for 9 URLs in under a second:
这是所有执行过程的结果,因为areq.py在一秒钟之内areq.py获取,解析并保存9个URL的结果:
$ python3 areq.py
$ python3 areq.py
21:33:22 DEBUG:asyncio: Using selector: KqueueSelector
21:33:22 DEBUG:asyncio: Using selector: KqueueSelector
21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/
21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/
21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt
21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found
21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found
21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/
21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/
21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/
21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/
21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics
21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/
21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/
21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/
21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/
21:33:23 INFO:areq: Found 23 links for https://regex101.com/
21:33:23 INFO:areq: Found 23 links for https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/
21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/
That’s not too shabby! As a sanity check, you can check the line-count on the output. In my case, it’s 626, though keep in mind this may fluctuate:
不太破旧! 作为健全性检查,您可以检查输出中的行数。 在我的情况下为626,尽管请记住,这可能会有所波动:
Next Steps: If you’d like to up the ante, make this webcrawler recursive. You can use aio-redis to keep track of which URLs have been crawled within the tree to avoid requesting them twice, and connect links with Python’s networkx library.
后续步骤 :如果您想提高底注,请使此网络爬虫递归。 您可以使用aio-redis跟踪树中已爬网的URL,以避免两次请求,并将链接与Python的networkx库连接。
Remember to be nice. Sending 1000 concurrent requests to a small, unsuspecting website is bad, bad, bad. There are ways to limit how many concurrent requests you’re making in one batch, such as in using the sempahore objects of asyncio or using a pattern like this one. If you don’t heed this warning, you may get a massive batch of TimeoutError exceptions and only end up hurting your own program.
记住要友善。 发送1000个并发请求到一个小的,毫无戒心的网站是不好的,不好的,不好的。 有办法限制多少并发请求你让一个批次中,如在使用sempahore的对象asyncio或使用图案像这样的 。 如果您不注意此警告,则可能会收到大量的TimeoutError异常,最终只会损害您自己的程序。
上下文中的异步IO (Async IO in Context)
Now that you’ve seen a healthy dose of code, let’s step back for a minute and consider when async IO is an ideal option and how you can make the comparison to arrive at that conclusion or otherwise choose a different model of concurrency.
既然您已经看到了健康的代码,那么让我们退后一分钟,考虑一下什么时候异步IO是理想的选择,以及如何进行比较以得出结论或选择其他并发模型。
什么时候以及为什么异步IO是正确的选择? (When and Why Is Async IO the Right Choice?)
This tutorial is no place for an extended treatise on async IO versus threading versus multiprocessing. However, it’s useful to have an idea of when async IO is probably the best candidate of the three.
本教程没有关于异步IO,线程与多处理的扩展论述。 但是,了解异步IO何时可能是三个中的最佳候选者很有用。
The battle over async IO versus multiprocessing is not really a battle at all. In fact, they can be used in concert. If you have multiple, fairly uniform CPU-bound tasks (a great example is a grid search in libraries such as scikit-learn or keras), multiprocessing should be an obvious choice.
异步IO与多处理之间的斗争根本不是一场争斗。 实际上,它们可以一起使用 。 如果您有多个相当统一的CPU绑定任务(一个很好的例子是在诸如scikit-learn或keras库中进行网格搜索 ),那么多处理应该是一个明显的选择。
Simply putting async before every function is a bad idea if all of the functions use blocking calls. (This can actually slow down your code.) But as mentioned previously, there are places where async IO and multiprocessing can live in harmony.
如果所有函数都使用阻塞调用,则简单地在每个函数之前放置async是一个坏主意。 (这实际上可能会使您的代码变慢。)但是,如前所述,异步IO和多处理在某些地方可以和谐共处 。
The contest between async IO and threading is a little bit more direct. I mentioned in the introduction that “threading is hard.” The full story is that, even in cases where threading seems easy to implement, it can still lead to infamous impossible-to-trace bugs due to race conditions and memory usage, among other things.
异步IO与线程之间的竞争更为直接。 我在导言中提到“线程很难实现”。 全文是,即使在线程似乎易于实现的情况下,由于竞争条件和内存使用等原因,它仍可能导致臭名昭著的无法跟踪的错误。
Threading also tends to scale less elegantly than async IO, because threads are a system resource with a finite availability. Creating thousands of threads will fail on many machines, and I don’t recommend trying it in the first place. Creating thousands of async IO tasks is completely feasible.
由于线程是具有有限可用性的系统资源,因此线程的扩展也往往比异步IO的扩展规模小。 在许多计算机上创建数千个线程将失败,因此我不建议首先尝试。 创建数千个异步IO任务是完全可行的。
Async IO shines when you have multiple IO-bound tasks where the tasks would otherwise be dominated by blocking IO-bound wait time, such as:
当您有多个IO绑定任务时,异步IO会发光,否则这些任务将通过阻塞IO绑定等待时间来控制,例如:
-
Network IO, whether your program is the server or the client side
-
Serverless designs, such as a peer-to-peer, multi-user network like a group chatroom
-
Read/write operations where you want to mimic a “fire-and-forget” style but worry less about holding a lock on whatever you’re reading and writing to
网络IO,无论您的程序是服务器端还是客户端
无服务器设计,例如对等,多用户网络(如群组聊天室)
您想要模仿“即弃即忘”风格的读/写操作,而不必担心将所读取和写入的内容锁定在上面
The biggest reason not to use it is that await only supports a specific set of objects that define a specific set of methods. If you want to do async read operations with a certain DBMS, you’ll need to find not just a Python wrapper for that DBMS, but one that supports the async/await syntax. Coroutines that contain synchronous calls block other coroutines and tasks from running.
不使用它的最大原因是, await仅支持定义一组特定方法的一组特定对象。 如果要对某个DBMS进行异步读取操作,则不仅需要查找该DBMS的Python包装器,还需要查找支持async / await语法的包装器。 包含同步调用的协程会阻止其他协程和任务运行。
For a shortlist of libraries that work with async/await, see the list at the end of this tutorial.
有关使用async / await的库的简短列表 ,请参阅本教程末尾的列表 。
异步IO是,但是哪个? (Async IO It Is, but Which One?)
This tutorial focuses on async IO, the async/await syntax, and using asyncio for event-loop management and specifying tasks. asyncio certainly isn’t the only async IO library out there. This observation from Nathaniel J. Smith says a lot:
本教程重点介绍异步IO, async / await语法以及如何将asyncio用于事件循环管理和指定任务。 当然, asyncio并不是唯一的异步IO库。 纳撒尼尔·史密斯(Nathaniel J.Smith)的观察表明:
[In] a few years,
asynciomight find itself relegated to becoming one of those stdlib libraries that savvy developers avoid, likeurllib2.在几年内,
asyncio可能会asyncio为成为精明的开发人员避免使用的stdlib库之一,例如urllib2。…
…
What I’m arguing, in effect, is that
asynciois a victim of its own success: when it was designed, it used the best approach possible; but since then, work inspired byasyncio– like the addition ofasync/await– has shifted the landscape so that we can do even better, and nowasynciois hamstrung by its earlier commitments. (Source)实际上,我要说的是
asyncio是其自身成功的受害者:设计时,它使用了最佳方法。 但是从那时起,async启发下的asyncio-例如添加async/await-改变了形势,以便我们可以做得更好,现在asyncio已被其早期的承诺所束缚。 (资源)
To that end, a few big-name alternatives that do what asyncio does, albeit with different APIs and different approaches, are curio and trio. Personally, I think that if you’re building a moderately sized, straightforward program, just using asyncio is plenty sufficient and understandable, and lets you avoid adding yet another large dependency outside of Python’s standard library.
为此,尽管使用不同的API和不同的方法,但可以做asyncio的一些大型替代方案是curio和trio 。 我个人认为,如果您要构建大小适中,简单明了的程序,仅使用asyncio就足够了并且可以理解,并且可以避免在Python标准库之外添加其他大型依赖项。
But by all means, check out curio and trio, and you might find that they get the same thing done in a way that’s more intuitive for you as the user. Many of the package-agnostic concepts presented here should permeate to alternative async IO packages as well.
但是,无论如何,请查看curio和trio ,您可能会发现它们以一种对用户而言更直观的方式完成了相同的工作。 这里介绍的许多与软件包无关的概念也应渗透到其他异步IO软件包中。
什物 (Odds and Ends)
In these next few sections, you’ll cover some miscellaneous parts of asyncio and async/await that haven’t fit neatly into the tutorial thus far, but are still important for building and understanding a full program.
在接下来的几节中,您将介绍asyncio和async / await其他各个部分,这些部分asyncio还没有很好地适合本教程,但是对于构建和理解完整的程序仍然很重要。
其他顶级asyncio功能 (Other Top-Level asyncio Functions)
In addition to asyncio.run(), you’ve seen a few other package-level functions such as asyncio.create_task() and asyncio.gather().
除了asyncio.run() ,您还看到了其他一些包级功能,例如asyncio.create_task()和asyncio.gather() 。
You can use create_task() to schedule the execution of a coroutine object, followed by asyncio.run():
您可以使用create_task()来安排协程对象的执行,然后使用asyncio.run() :
>>> import asyncio
>>> async def coro(seq) -> list:
... """'IO' wait time is proportional to the max element."""
... await asyncio.sleep(max(seq))
... return list(reversed(seq))
...
>>> async def main():
... # This is a bit redundant in the case of one task
... # We could use `await coro([3, 2, 1])` on its own
... t = asyncio.create_task(coro([3, 2, 1])) # Python 3.7+
... await t
... print(f't: type {type(t)}')
... print(f't done: {t.done()}')
...
>>> t = asyncio.run(main())
t: type <class '_asyncio.Task'>
t done: True
There’s a subtlety to this pattern: if you don’t await t within main(), it may finish before main() itself signals that it is complete. Because asyncio.run(main()) calls loop.run_until_complete(main()), the event loop is only concerned (without await t present) that main() is done, not that the tasks that get created within main() are done. Without await t, the loop’s other tasks will be cancelled, possibly before they are completed. If you need to get a list of currently pending tasks, you can use asyncio.Task.all_tasks().
这种模式有一个微妙之处:如果您不await t main() await t ,它可能在main()本身发出完成信号之前就结束了。 因为asyncio.run(main()) 调用loop.run_until_complete(main()) ,所以事件循环仅关注main()完成(而不await t ),而不涉及在main()中创建的任务是否完成。完成。 如果不await t ,则循环的其他任务可能会在完成之前被取消 。 如果需要获取当前待处理任务的列表,则可以使用asyncio.Task.all_tasks() 。
Note: asyncio.create_task() was introduced in Python 3.7. In Python 3.6 or lower, use asyncio.ensure_future() in place of create_task().
注意 : asyncio.create_task()是Python 3.7中引入的。 在Python 3.6或更低版本中,请使用asyncio.ensure_future()代替create_task() 。
Separately, there’s asyncio.gather(). While it doesn’t do anything tremendously special, gather() is meant to neatly put a collection of coroutines (futures) into a single future. As a result, it returns a single future object, and, if you await asyncio.gather() and specify multiple tasks or coroutines, you’re waiting for all of them to be completed. (This somewhat parallels queue.join() from our earlier example.) The result of gather() will be a list of the results across the inputs:
另外,还有asyncio.gather() 。 尽管它没有做任何特别的事情,但是gather()目的是将协程(期货)的集合整齐地放入单个未来中。 结果,它返回一个将来的对象,并且,如果您await asyncio.gather()并指定多个任务或协程,则您正在等待所有这些任务或协程完成。 (这个有点平行queue.join()从我们前面的例子。)的结果gather()将横跨输入的结果的列表:
>>> import time
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0])) # Python 3.7+
... print('Start:', time.strftime('%X'))
... a = await asyncio.gather(t, t2)
... print('End:', time.strftime('%X')) # Should be 10 seconds
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
... return a
...
>>> a = asyncio.run(main())
Start: 16:20:11
End: 16:20:21
Both tasks done: True
>>> a
[[1, 2, 3], [0, 5, 10]]
You probably noticed that gather() waits on the entire result set of the Futures or coroutines that you pass it. Alternatively, you can loop over asyncio.as_completed() to get tasks as they are completed, in the order of completion. The function returns an iterator that yields tasks as they finish. Below, the result of coro([3, 2, 1]) will be available before coro([10, 5, 0]) is complete, which is not the case with gather():
您可能已经注意到, gather()等待传递的期货或协程的整个结果集。 或者,您可以遍历asyncio.as_completed()以按完成顺序获取任务完成时的任务。 该函数返回一个迭代器,该迭代器在完成任务时产生任务。 下面,结果coro([3, 2, 1])将是可利用之前coro([10, 5, 0])是完整的,这是不符合的情况下gather()
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0]))
... print('Start:', time.strftime('%X'))
... for res in asyncio.as_completed((t, t2)):
... compl = await res
... print(f'res: {compl} completed at {time.strftime("%X")}')
... print('End:', time.strftime('%X'))
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
...
>>> a = asyncio.run(main())
Start: 09:49:07
res: [1, 2, 3] completed at 09:49:10
res: [0, 5, 10] completed at 09:49:17
End: 09:49:17
Both tasks done: True
Lastly, you may also see asyncio.ensure_future(). You should rarely need it, because it’s a lower-level plumbing API and largely replaced by create_task(), which was introduced later.
最后,您可能还会看到asyncio.ensure_future() 。 您很少需要它,因为它是一个较低级的管道API,并在很大程度上被稍后介绍的create_task()所取代。
await的先例 (The Precedence of await)
While they behave somewhat similarly, the await keyword has significantly higher precedence than yield. This means that, because it is more tightly bound, there are a number of instances where you’d need parentheses in a yield from statement that are not required in an analogous await statement. For more information, see examples of await expressions from PEP 492.
尽管它们的行为有些相似,但是await关键字的优先级比yield优先级高得多。 这意味着,由于绑定更紧密,因此在许多情况下,您需要在yield from语句中使用括号,而在类似的await语句中则不需要。 有关更多信息,请参见PEP 492中的await表达式示例 。
结论 (Conclusion)
You’re now equipped to use async/await and the libraries built off of it. Here’s a recap of what you’ve covered:
现在,您已准备好使用async / await和基于它构建的库。 以下是您所涵盖内容的回顾:
-
Asynchronous IO as a language-agnostic model and a way to effect concurrency by letting coroutines indirectly communicate with each other
-
The specifics of Python’s new
asyncandawaitkeywords, used to mark and define coroutines -
asyncio, the Python package that provides the API to run and manage coroutines
异步IO作为与语言无关的模型,以及通过使协程彼此间接通信来实现并发的方法
Python的新
async和await关键字的细节,用于标记和定义协程asyncio,Python包,提供用于运行和管理协程的API
资源资源 (Resources)
Python版本细节 (Python Version Specifics)
Async IO in Python has evolved swiftly, and it can be hard to keep track of what came when. Here’s a list of Python minor-version changes and introductions related to asyncio:
Python中的异步IO发展Swift,因此很难跟踪何时发生了什么。 以下是与asyncio相关的Python次要版本更改和介绍的asyncio :
-
3.3: The
yield fromexpression allows for generator delegation. -
3.4:
asynciowas introduced in the Python standard library with provisional API status. -
3.5:
asyncandawaitbecame a part of the Python grammar, used to signify and wait on coroutines. They were not yet reserved keywords. (You could still define functions or variables namedasyncandawait.) -
3.6: Asynchronous generators and asynchronous comprehensions were introduced. The API of
asynciowas declared stable rather than provisional. -
3.7:
asyncandawaitbecame reserved keywords. (They cannot be used as identifiers.) They are intended to replace theasyncio.coroutine()decorator.asyncio.run()was introduced to theasynciopackage, among a bunch of other features.
3.3:表达式的
yield from允许生成器委派。3.4:
asyncio在Python标准库中以临时API状态引入。3.5:
async和await成为Python语法的一部分,用于表示和等待协程。 它们还不是保留关键字。 (您仍然可以定义名为async和await函数或变量。)3.6:引入了异步生成器和异步理解。
asyncio的API被声明为稳定的,而不是临时的。3.7:
async和await成为保留关键字。 (它们不能用作标识符。)它们旨在替换asyncio.coroutine()装饰器。asyncio.run()引入了asyncio包,其中包括许多其他功能 。
If you want to be safe (and be able to use asyncio.run()), go with Python 3.7 or above to get the full set of features.
如果您想安全(并能够使用asyncio.run() ),请使用Python 3.7或更高版本以获取全部功能。
文章 (Articles)
Here’s a curated list of additional resources:
以下是精选的其他资源列表:
- Real Python: Speed up your Python Program with Concurrency
- Real Python: What is the Python Global Interpreter Lock?
- CPython: The
asynciopackage source - Python docs: Data model > Coroutines
- TalkPython: Async Techniques and Examples in Python
- Brett Cannon: How the Heck Does Async-Await Work in Python 3.5?
- PYMOTW:
asyncio - A. Jesse Jiryu Davis and Guido van Rossum: A Web Crawler With asyncio Coroutines
- Andy Pearce: The State of Python Coroutines:
yield from - Nathaniel J. Smith: Some Thoughts on Asynchronous API Design in a Post-
async/awaitWorld - Armin Ronacher: I don’t understand Python’s Asyncio
- Andy Balaam: series on
asyncio(4 posts) - Stack Overflow: Python
asyncio.semaphoreinasync–awaitfunction - Yeray Diaz:
- 真正的Python: 通过并发加速您的Python程序
- 真正的Python: 什么是Python全局解释器锁?
- CPython:
asyncio包源 - Python文档: 数据模型>协程
- TalkPython: Python中的异步技术和示例
- Brett Cannon: 在Python 3.5中异步等待如何工作?
- PYMOTW:
asyncio - A. Jesse Jiryu Davis和Guido van Rossum: 具有异步协程的网络爬虫
- 安迪·皮尔斯(Andy Pearce): Python协程的状态:
yield from - Nathaniel J. Smith: 后
async/await世界中有关异步API设计的一些想法 - Armin Ronacher: 我不了解Python的Asyncio
- 安迪·巴兰(Andy
asyncio): 关于asyncio系列 (共4个帖子) - 堆栈溢出:
asyncPythonasyncio.semaphore–await功能 - Yeray Diaz:
A few Python What’s New sections explain the motivation behind language changes in more detail:
一些Python新增功能部分更详细地说明了语言更改的动机:
- What’s New in Python 3.3 (
yield fromand PEP 380) - What’s New in Python 3.6 (PEP 525 & 530)
- Python 3.3的新功能 (和PEP 380的
yield from) - Python 3.6 (PEP 525和530) 的新增功能
From David Beazley:
从大卫·比兹利(David Beazley):
- Generator: Tricks for Systems Programmers
- A Curious Course on Coroutines and Concurrency
- Generators: The Final Frontier
YouTube talks:
YouTube讲座:
- John Reese – Thinking Outside the GIL with AsyncIO and Multiprocessing – PyCon 2018
- Keynote David Beazley – Topics of Interest (Python Asyncio)
- David Beazley – Python Concurrency From the Ground Up: LIVE! – PyCon 2015
- Raymond Hettinger, Keynote on Concurrency, PyBay 2017
- Thinking about Concurrency, Raymond Hettinger, Python core developer
- Miguel Grinberg Asynchronous Python for the Complete Beginner PyCon 2017
- Yury Selivanov asyncawait and asyncio in Python 3 6 and beyond PyCon 2017
- Fear and Awaiting in Async: A Savage Journey to the Heart of the Coroutine Dream
- What Is Async, How Does It Work, and When Should I Use It? (PyCon APAC 2014)
- John Reese –通过AsyncIO和多处理在GIL之外进行思考– PyCon 2018
- 主题演讲David Beazley –感兴趣的主题(Python Asyncio)
- David Beazley –从头开始进行Python并发:现场直播! – PyCon 2015
- Raymond Hettinger,并发主题演讲,PyBay 2017
- 关于并发性,Python核心开发人员Raymond Hettinger
- Miguel Grinberg面向完整初学者PyCon 2017的异步Python
- Yury Selivanov Python 3 6及更高版本PyCon 2017中的asyncawait和asyncio
- 恐惧与异步等待:协程梦之心的野蛮之旅
- 什么是异步,它如何工作,什么时候应该使用它? (PyCon亚太地区2014)
相关PEP (Related PEPs)
| PEP | PEP | Date Created | 创建日期 |
|---|---|---|---|
| PEP 342 – Coroutines via Enhanced GeneratorsPEP 342 –通过增强型生成器协程 | 2005-05 | 2005-05 | |
| PEP 380 – Syntax for Delegating to a SubgeneratorPEP 380 –委托给子发电机的语法 | 2009-02 | 2009-02 | |
| PEP 3153 – Asynchronous IO supportPEP 3153 –异步IO支持 | 2011-05 | 2011-05 | |
| PEP 3156 – Asynchronous IO Support Rebooted: the “asyncio” ModulePEP 3156 –重新启动了异步IO支持:“异步”模块 | 2012-12 | 2012-12 | |
| PEP 492 – Coroutines with async and await syntaxPEP 492 –具有异步和等待语法的协程 | 2015-04 | 2015-04 | |
| PEP 525 – Asynchronous GeneratorsPEP 525 –异步发电机 | 2016-07 | 2016-07 | |
| PEP 530 – Asynchronous ComprehensionsPEP 530 –异步理解 | 2016-09 | 2016-09 |
使用async / await库 (Libraries That Work With async/await)
From aio-libs:
从aio-libs :
aiohttp: Asynchronous HTTP client/server frameworkaioredis: Async IO Redis supportaiopg: Async IO PostgreSQL supportaiomcache: Async IO memcached clientaiokafka: Async IO Kafka clientaiozmq: Async IO ZeroMQ supportaiojobs: Jobs scheduler for managing background tasksasync_lru: Simple LRU cache for async IO
-
aiohttp:异步HTTP客户端/服务器框架 -
aioredis:异步IO Redis支持 -
aiopg:异步IO PostgreSQL支持 -
aiomcache:异步IO memcached客户端 -
aiokafka:异步IO Kafka客户端 -
aiozmq:异步IO ZeroMQ支持 -
aiojobs:用于管理后台任务的Jobs Scheduler -
async_lru:异步IO的简单LRU缓存
From magicstack:
从magicstack中 :
From other hosts:
从其他主机:
trio: Friendlierasynciointended to showcase a radically simpler designaiofiles: Async file IOasks: Async requests-like http libraryasyncio-redis: Async IO Redis supportaioprocessing: Integratesmultiprocessingmodule withasyncioumongo: Async IO MongoDB clientunsync: Unsynchronizeasyncioaiostream: Likeitertools, but async
-
trio:友好的asyncio旨在展示一种更为简单的设计 -
aiofiles:异步文件IO -
asks:类似异步请求的http库 -
asyncio-redis:异步IO Redis支持 -
aioprocessing:将multiprocessing模块与asyncio集成 -
umongo:异步IO MongoDB客户端 -
unsync同步:asyncio同步asyncio -
aiostream:与itertools,但异步
翻译自: https://www.pybloggers.com/2019/01/async-io-in-python-a-complete-walkthrough/
python 异步io














 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









