





 本文介绍了Python数据分析库Pandas的一些鲜为人知但实用的功能,包括在解释器启动时配置选项、使用测试模块创建数据结构、利用访问器方法、从组件列创建DatetimeIndex等,旨在提升代码可读性、灵活性和速度。
本文介绍了Python数据分析库Pandas的一些鲜为人知但实用的功能,包括在解释器启动时配置选项、使用测试模块创建数据结构、利用访问器方法、从组件列创建DatetimeIndex等,旨在提升代码可读性、灵活性和速度。
python熊猫图案
Pandas is a foundational library for analytics, data processing, and data science. It’s a huge project with tons of optionality and depth.
熊猫是用于分析,数据处理和数据科学的基础库。 这是一个庞大的项目,具有大量的可选项和深度。
This tutorial will cover some lesser-used but idiomatic Pandas capabilities that lend your code better readability, versatility, and speed, à la the Buzzfeed listicle.
本教程将介绍一些使用较少但惯用的Pandas功能,从而使您的代码具有更好的可读性,多功能性和速度,如Buzzfeed列表。
If you feel comfortable with the core concepts of Python’s Pandas library, hopefully you’ll find a trick or two in this article that you haven’t stumbled across previously. (If you’re just starting out with the library, 10 Minutes to Pandas is a good place to start.)
如果您对Python的Pandas库的核心概念感到满意,希望您会在本文中找到一两个以前没有偶然发现过的窍门。 (如果您只是从图书馆开始,那么到熊猫的十分钟是一个不错的起点。)
Note: The examples in this article are tested with Pandas version 0.23.2 and Python 3.6.6. However, they should also be valid in older versions.
注意 :本文中的示例已通过Pandas 0.23.2版和Python 3.6.6版进行了测试。 但是,它们在旧版本中也应有效。
1.在解释器启动时配置选项和设置 (1. Configure Options & Settings at Interpreter Startup)
You may have run across Pandas’ rich options and settings system before.
您之前可能已经运行过Pandas的丰富选项和设置系统。
It’s a huge productivity saver to set customized Pandas options at interpreter startup, especially if you work in a scripting environment. You can use pd.set_option() to configure to your heart’s content with a Python or IPython startup file.
在解释器启动时设置自定义的Pandas选项可以节省大量的生产力,尤其是在脚本环境中工作时。 您可以使用pd.set_option()通过Python或IPython启动文件来配置您的心脏内容。
The options use a dot notation such as pd.set_option('display.max_colwidth', 25), which lends itself well to a nested dictionary of options:
这些选项使用点表示法,例如pd.set_option('display.max_colwidth', 25) ,这很适合用于嵌套的选项字典:
import import pandas pandas as as pd
pd
def def startstart ():
():
options options = = {
{
'display''display' : : {
{
'max_columns''max_columns' : : NoneNone ,
,
'max_colwidth''max_colwidth' : : 2525 ,
,
'expand_frame_repr''expand_frame_repr' : : FalseFalse , , # Don't wrap to multiple pages
# Don't wrap to multiple pages
'max_rows''max_rows' : : 1414 ,
,
'max_seq_items''max_seq_items' : : 5050 , , # Max length of printed sequence
# Max length of printed sequence
'precision''precision' : : 44 ,
,
'show_dimensions''show_dimensions' : : False
False
},
},
'mode''mode' : : {
{
'chained_assignment''chained_assignment' : : None None # Controls SettingWithCopyWarning
# Controls SettingWithCopyWarning
}
}
}
}
for for categorycategory , , option option in in optionsoptions .. itemsitems ():
():
for for opop , , value value in in optionoption .. itemsitems ():
():
pdpd .. set_optionset_option (( ff '' {category}{category} .. {op}{op} '' , , valuevalue ) ) # Python 3.6+
# Python 3.6+
if if __name__ __name__ == == '__main__''__main__' :
:
startstart ()
()
del del start start # Clean up namespace in the interpreter
# Clean up namespace in the interpreter
If you launch an interpreter session, you’ll see that everything in the startup script has been executed, and Pandas is imported for you automatically with your suite of options:
如果启动解释器会话,您将看到启动脚本中的所有内容均已执行,并且使用您的选项套件会自动为您导入Pandas:
Let’s use some data on abalone hosted by the UCI Machine Learning Repository to demonstrate the formatting that was set in the startup file. The data will truncate at 14 rows with 4 digits of precision for floats:
让我们使用UCI机器学习存储库托管的鲍鱼上的一些数据来演示在启动文件中设置的格式。 数据将在14行中截断,且浮点数的精度为4位:
>>> >>> url url = = (( 'https://archive.ics.uci.edu/ml/'
'https://archive.ics.uci.edu/ml/'
... ... 'machine-learning-databases/abalone/abalone.data''machine-learning-databases/abalone/abalone.data' )
)
>>> >>> cols cols = = [[ 'sex''sex' , , 'length''length' , , 'diam''diam' , , 'height''height' , , 'weight''weight' , , 'rings''rings' ]
]
>>> >>> abalone abalone = = pdpd .. read_csvread_csv (( urlurl , , usecolsusecols == [[ 00 , , 11 , , 22 , , 33 , , 44 , , 88 ], ], namesnames == colscols )
)
>>> >>> abalone
abalone
sex length diam height weight rings
sex length diam height weight rings
0 M 0.455 0.365 0.095 0.5140 15
0 M 0.455 0.365 0.095 0.5140 15
1 M 0.350 0.265 0.090 0.2255 7
1 M 0.350 0.265 0.090 0.2255 7
2 F 0.530 0.420 0.135 0.6770 9
2 F 0.530 0.420 0.135 0.6770 9
3 M 0.440 0.365 0.125 0.5160 10
3 M 0.440 0.365 0.125 0.5160 10
4 I 0.330 0.255 0.080 0.2050 7
4 I 0.330 0.255 0.080 0.2050 7
5 I 0.425 0.300 0.095 0.3515 8
5 I 0.425 0.300 0.095 0.3515 8
6 F 0.530 0.415 0.150 0.7775 20
6 F 0.530 0.415 0.150 0.7775 20
... ... .. .. ... ... ... ... ... ... ... ... ...
...
4170 M 0.550 0.430 0.130 0.8395 10
4170 M 0.550 0.430 0.130 0.8395 10
4171 M 0.560 0.430 0.155 0.8675 8
4171 M 0.560 0.430 0.155 0.8675 8
4172 F 0.565 0.450 0.165 0.8870 11
4172 F 0.565 0.450 0.165 0.8870 11
4173 M 0.590 0.440 0.135 0.9660 10
4173 M 0.590 0.440 0.135 0.9660 10
4174 M 0.600 0.475 0.205 1.1760 9
4174 M 0.600 0.475 0.205 1.1760 9
4175 F 0.625 0.485 0.150 1.0945 10
4175 F 0.625 0.485 0.150 1.0945 10
4176 M 0.710 0.555 0.195 1.9485 12
4176 M 0.710 0.555 0.195 1.9485 12
You’ll see this dataset pop up in other examples later as well.
稍后您还将在其他示例中看到此数据集弹出。
2.使用熊猫的测试模块制作玩具数据结构 (2. Make Toy Data Structures With Pandas’ Testing Module)
Hidden way down in Pandas’ testing module are a number of convenient functions for quickly building quasi-realistic Series and DataFrames:
熊猫testing模块中隐藏的许多便捷功能可用于快速构建准真实的Series和DataFrames:
There are around 30 of these, and you can see the full list by calling dir() on the module object. Here are a few:
其中大约有30个,您可以通过在模块对象上调用dir()来查看完整列表。 这里有一些:
>>> >>> [[ i i for for i i in in dirdir (( tmtm ) ) if if ii .. startswithstartswith (( 'make''make' )]
)]
['makeBoolIndex',
['makeBoolIndex',
'makeCategoricalIndex',
'makeCategoricalIndex',
'makeCustomDataframe',
'makeCustomDataframe',
'makeCustomIndex',
'makeCustomIndex',
# ...,
# ...,
'makeTimeSeries',
'makeTimeSeries',
'makeTimedeltaIndex',
'makeTimedeltaIndex',
'makeUIntIndex',
'makeUIntIndex',
'makeUnicodeIndex']
'makeUnicodeIndex']
These can be useful for benchmarking, testing assertions, and experimenting with Pandas methods that you are less familiar with.
这些对于基准测试,测试断言以及尝试使用您不太熟悉的Pandas方法很有用。
3.利用访问器方法 (3. Take Advantage of Accessor Methods)
Perhaps you’ve heard of the term accessor, which is somewhat like a getter (although getters and setters are used infrequently in Python). For our purposes here, you can think of a Pandas accessor as a property that serves as an interface to additional methods.
也许您听说过accessor一词,它有点像一个getter(尽管在Python中很少使用getter和setter)。 对于我们这里的目的,您可以将Pandas访问器视为可充当其他方法的接口的属性。
Pandas Series have three of them:
熊猫系列有三个:
Yes, that definition above is a mouthful, so let’s take a look at a few examples before discussing the internals.
是的,上面的定义非常详尽,因此在讨论内部原理之前,让我们看一些示例。
.cat is for categorical data, .str is for string (object) data, and .dt is for datetime-like data. Let’s start off with .str: imagine that you have some raw city/state/ZIP data as a single field within a Pandas Series.
.cat用于分类数据, .str用于字符串(对象)数据, .dt用于类似日期时间的数据。 让我们从.str开始:假设您有一些原始的城市/州/邮政编码数据作为“熊猫系列”中的单个字段。
Pandas string methods are vectorized, meaning that they operate on the entire array without an explicit for-loop:
Pandas字符串方法是矢量化的 ,这意味着它们可以在整个数组上运行而无需显式的for循环:
>>> >>> addr addr = = pdpd .. SeriesSeries ([
([
... ... 'Washington, D.C. 20003''Washington, D.C. 20003' ,
,
... ... 'Brooklyn, NY 11211-1755''Brooklyn, NY 11211-1755' ,
,
... ... 'Omaha, NE 68154''Omaha, NE 68154' ,
,
... ... 'Pittsburgh, PA 15211'
'Pittsburgh, PA 15211'
... ... ])
])
>>> >>> addraddr .. strstr .. upperupper ()
()
0 WASHINGTON, D.C. 20003
0 WASHINGTON, D.C. 20003
1 BROOKLYN, NY 11211-1755
1 BROOKLYN, NY 11211-1755
2 OMAHA, NE 68154
2 OMAHA, NE 68154
3 PITTSBURGH, PA 15211
3 PITTSBURGH, PA 15211
dtype: object
dtype: object
>>> >>> addraddr .. strstr .. countcount (( rr 'd''d' ) ) # 5 or 9-digit zip?
# 5 or 9-digit zip?
0 5
0 5
1 9
1 9
2 5
2 5
3 5
3 5
dtype: int64
dtype: int64
For a more involved example, let’s say that you want to separate out the three city/state/ZIP components neatly into DataFrame fields.
对于更复杂的示例,假设您想将三个城市/州/邮政编码区域巧妙地分离到DataFrame字段中。
You can pass a regular expression to .str.extract() to “extract” parts of each cell in the Series. In .str.extract(), .str is the accessor, and .str.extract() is an accessor method:
您可以将正则表达式传递给.str.extract()以“提取”系列中每个单元格的部分。 在.str.extract() , .str是访问器, .str.extract()是访问器方法:
This also illustrates what is known as method-chaining, where .str.extract(regex) is called on the result of addr.str.replace('.', ''), which cleans up use of periods to get a nice 2-character state abbreviation.
这也说明了所谓的方法链接,其中在addr.str.replace('.', '')的结果上调用.str.extract(regex) addr.str.replace('.', '') ,它清理了句点的使用以获得漂亮的2 -字符状态的缩写。
It’s helpful to know a tiny bit about how these accessor methods work as a motivating reason for why you should use them in the first place, rather than something like addr.apply(re.findall, ...).
稍微了解一下这些访问器方法的工作方式是很有帮助的,这是为什么您应该首先使用它们的动机,而不是诸如addr.apply(re.findall, ...) 。
Each accessor is itself a bona fide Python class:
每个访问器本身都是真正的Python类:
.strmaps toStringMethods..dtmaps toCombinedDatetimelikeProperties..catroutes toCategoricalAccessor.
-
.str映射到StringMethods。 -
.dt映射到CombinedDatetimelikeProperties。 -
.cat路由到CategoricalAccessor。
These standalone classes are then “attached” to the Series class using a CachedAccessor. It is when the classes are wrapped in CachedAccessor that a bit of magic happens.
然后,使用CachedAccessor将这些独立的类“附加”到Series类。 当类包装在CachedAccessor ,发生了一些魔术。
CachedAccessor is inspired by a “cached property” design: a property is only computed once per instance and then replaced by an ordinary attribute. It does this by overloading the .__get__() method, which is part of Python’s descriptor protocol.
CachedAccessor受“缓存属性”设计的启发:每个实例仅计算一次属性,然后将其替换为普通属性。 它通过重载.__get__()方法来实现此目的,该方法是Python的描述符协议的一部分。
Note: If you’d like to read more about the internals of how this works, see the Python Descriptor HOWTO and this post on the cached property design. Python 3 also introduced functools.lru_cache(), which offers similar functionality.
注 :如果您想了解更多关于这个作品,是如何看待的内部Python的描述符HOWTO和这个职位上缓存的性能设计。 Python 3还引入了functools.lru_cache() ,它提供了类似的功能。
The second accessor, .dt, is for datetime-like data. It technically belongs to Pandas’ DatetimeIndex, and if called on a Series, it is converted to a DatetimeIndex first:
第二个访问器.dt用于类似日期时间的数据。 从技术上讲,它属于Pandas的DatetimeIndex ,如果在Series上调用,它将首先转换为DatetimeIndex :
>>> >>> daterng daterng = = pdpd .. SeriesSeries (( pdpd .. date_rangedate_range (( '2017''2017' , , periodsperiods == 99 , , freqfreq == 'Q''Q' ))
))
>>> >>> daterng
daterng
0 2017-03-31
0 2017-03-31
1 2017-06-30
1 2017-06-30
2 2017-09-30
2 2017-09-30
3 2017-12-31
3 2017-12-31
4 2018-03-31
4 2018-03-31
5 2018-06-30
5 2018-06-30
6 2018-09-30
6 2018-09-30
7 2018-12-31
7 2018-12-31
8 2019-03-31
8 2019-03-31
dtype: datetime64[ns]
dtype: datetime64[ns]
>>> >>> daterngdaterng .. dtdt .. day_nameday_name ()
()
0 Friday
0 Friday
1 Friday
1 Friday
2 Saturday
2 Saturday
3 Sunday
3 Sunday
4 Saturday
4 Saturday
5 Saturday
5 Saturday
6 Sunday
6 Sunday
7 Monday
7 Monday
8 Sunday
8 Sunday
dtype: object
dtype: object
>>> >>> # Second-half of year only
# Second-half of year only
>>> >>> daterngdaterng [[ daterngdaterng .. dtdt .. quarter quarter > > 22 ]
]
2 2017-09-30
2 2017-09-30
3 2017-12-31
3 2017-12-31
6 2018-09-30
6 2018-09-30
7 2018-12-31
7 2018-12-31
dtype: datetime64[ns]
dtype: datetime64[ns]
>>> >>> daterngdaterng [[ daterngdaterng .. dtdt .. is_year_endis_year_end ]
]
3 2017-12-31
3 2017-12-31
7 2018-12-31
7 2018-12-31
dtype: datetime64[ns]
dtype: datetime64[ns]
The third accessor, .cat, is for Categorical data only, which you’ll see shortly in its own section.
第三个访问器.cat仅用于分类数据,您将在其自己的部分中很快看到。
4.从组件列创建DatetimeIndex (4. Create a DatetimeIndex From Component Columns)
Speaking of datetime-like data, as in daterng above, it’s possible to create a Pandas DatetimeIndex from multiple component columns that together form a date or datetime:
说到类似日期时间的数据,就像上面的daterng一样,可以从多个组成日期或日期DatetimeIndex组件列中创建Pandas DatetimeIndex :
Finally, you can drop the old individual columns and convert to a Series:
最后,您可以删除旧的单个列并转换为Series:
>>> >>> df df = = dfdf .. dropdrop (( datecolsdatecols , , axisaxis == 11 )) .. squeezesqueeze ()
()
>>> >>> dfdf .. headhead ()
()
2017-01-01 -0.0767
2017-01-01 -0.0767
2017-01-02 -1.2798
2017-01-02 -1.2798
2017-01-03 0.4032
2017-01-03 0.4032
2017-02-01 1.2377
2017-02-01 1.2377
2017-02-02 -0.2060
2017-02-02 -0.2060
Name: data, dtype: float64
Name: data, dtype: float64
>>> >>> dfdf .. indexindex .. dtype_str
dtype_str
'datetime64[ns]
'datetime64[ns]
The intuition behind passing a DataFrame is that a DataFrame resembles a Python dictionary where the column names are keys, and the individual columns (Series) are the dictionary values. That’s why pd.to_datetime(df[datecols].to_dict(orient='list')) would also work in this case. This mirrors the construction of Python’s datetime.datetime, where you pass keyword arguments such as datetime.datetime(year=2000, month=1, day=15, hour=10).
传递DataFrame的直觉是,DataFrame类似于Python字典,其中列名是键,而各个列(系列)是字典值。 这就是为什么pd.to_datetime(df[datecols].to_dict(orient='list'))在这种情况下也可以工作的原因。 这反映了Python的datetime.datetime的构造,在其中传递了诸如datetime.datetime(year=2000, month=1, day=15, hour=10)关键字参数。
5.使用分类数据节省时间和空间 (5. Use Categorical Data to Save on Time and Space)
One powerful Pandas feature is its Categorical dtype.
熊猫的一项强大功能是其Categorical dtype。
Even if you’re not always working with gigabytes of data in RAM, you’ve probably run into cases where straightforward operations on a large DataFrame seem to hang up for more than a few seconds.
即使您不总是在RAM中处理千兆字节的数据,您也可能会遇到在大型DataFrame上进行简单操作挂起超过几秒钟的情况。
Pandas object dtype is often a great candidate for conversion to category data. (object is a container for Python str, heterogeneous data types, or “other” types.) Strings occupy a significant amount of space in memory:
熊猫object dtype通常是转换为类别数据的理想选择。 ( object是Python str ,异构数据类型或“其他”类型的容器。)字符串在内存中占据了大量空间:
Note: I used sys.getsizeof() to show the memory occupied by each individual value in the Series. Keep in mind these are Python objects that have some overhead in the first place. (sys.getsizeof('') will return 49 bytes.)
注意:我使用sys.getsizeof()来显示Series中每个值所占用的内存。 请记住,这些是Python对象,它们首先具有一些开销。 ( sys.getsizeof('')将返回49个字节。)
There is also colors.memory_usage(), which sums up the memory usage and relies on the .nbytes attribute of the underlying NumPy array. Don’t get too bogged down in these details: what is important is relative memory usage that results from type conversion, as you’ll see next.
还有colors.memory_usage() ,它汇总内存使用情况并依赖于基础NumPy数组的.nbytes属性。 不要对这些细节感到困惑:重要的是类型转换产生的相对内存使用率,正如您将在接下来看到的。
Now, what if we could take the unique colors above and map each to a less space-hogging integer? Here is a naive implementation of that:
现在,如果我们可以采用上面的独特颜色并将每个颜色映射到一个不占用空间的整数,该怎么办? 这是一个简单的实现:
>>> >>> mapper mapper = = {{ vv : : k k for for kk , , v v in in enumerateenumerate (( colorscolors .. uniqueunique ())}
())}
>>> >>> mapper
mapper
{'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4}
{'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4}
>>> >>> as_int as_int = = colorscolors .. mapmap (( mappermapper )
)
>>> >>> as_int
as_int
0 0
0 0
1 1
1 1
2 2
2 2
3 0
3 0
4 2
4 2
5 3
5 3
6 3
6 3
7 1
7 1
8 3
8 3
9 4
9 4
dtype: int64
dtype: int64
>>> >>> as_intas_int .. applyapply (( syssys .. getsizeofgetsizeof )
)
0 24
0 24
1 28
1 28
2 28
2 28
3 24
3 24
4 28
4 28
5 28
5 28
6 28
6 28
7 28
7 28
8 28
8 28
9 28
9 28
dtype: int64
dtype: int64
Note: Another way to do this same thing is with Pandas’ pd.factorize(colors):
注意 :另一种执行此操作的方法是使用Pandas的pd.factorize(colors) :
Either way, you are encoding the object as an enumerated type (categorical variable).
无论哪种方式,您都将对象编码为枚举类型(分类变量)。
You’ll notice immediately that memory usage is just about cut in half compared to when the full strings are used with object dtype.
您会立即注意到,与将完整字符串与object dtype一起使用时相比,内存使用量几乎减少了一半。
Earlier in the section on accessors, I mentioned the .cat (categorical) accessor. The above with mapper is a rough illustration of what is happening internally with Pandas’ Categorical dtype:
在有关访问器的部分的前面,我提到了.cat (类别)访问器。 上面带有mapper的内容是对Pandas Categorical dtype内部发生的情况的粗略说明:
“The memory usage of a
Categoricalis proportional to the number of categories plus the length of the data. In contrast, anobjectdtype is a constant times the length of the data.” (Source)“
Categorical的内存使用量与Categorical的数量加上数据的长度成正比。 相反,objectdtype是数据长度的常数倍。” (资源)
In colors above, you have a ratio of 2 values for every unique value (category):
在上述colors ,每个唯一值(类别)的比率为2:
>>> >>> lenlen (( colorscolors ) ) / / colorscolors .. nuniquenunique ()
()
2.0
2.0
As a result, the memory savings from converting to Categorical is good, but not great:
结果,从转换为Categorical节省的内存是不错的,但效果不佳:
However, if you blow out the proportion above, with a lot of data and few unique values (think about data on demographics or alphabetic test scores), the reduction in memory required is over 10 times:
但是,如果您浪费了上面的比例,却拥有大量数据和唯一值(想想人口统计数据或字母测试分数的数据),则所需内存减少了10倍以上:
>>> >>> manycolors manycolors = = colorscolors .. repeatrepeat (( 1010 )
)
>>> >>> lenlen (( manycolorsmanycolors ) ) / / manycolorsmanycolors .. nuniquenunique () () # Much greater than 2.0x
# Much greater than 2.0x
20.0
20.0
>>> >>> manycolorsmanycolors .. memory_usagememory_usage (( indexindex == FalseFalse , , deepdeep == TrueTrue )
)
6500
6500
>>> >>> manycolorsmanycolors .. astypeastype (( 'category''category' )) .. memory_usagememory_usage (( indexindex == FalseFalse , , deepdeep == TrueTrue )
)
585
585
A bonus is that computational efficiency gets a boost too: for categorical Series, the string operations are performed on the .cat.categories attribute rather than on each original element of the Series.
一个额外的好处是计算效率也得到提高:对于分类Series ,字符串操作是在.cat.categories属性上执行的,而不是在Series每个原始元素上执行的。
In other words, the operation is done once per unique category, and the results are mapped back to the values. Categorical data has a .cat accessor that is a window into attributes and methods for manipulating the categories:
换句话说,该操作对每个唯一类别执行一次,然后将结果映射回这些值。 分类数据具有.cat访问器,该访问器是用于操纵类别的属性和方法的窗口:
In fact, you can reproduce something similar to the example above that you did manually:
实际上,您可以重现与上面示例类似的内容:
>>> >>> ccolorsccolors .. catcat .. codes
codes
0 3
0 3
1 1
1 1
2 0
2 0
3 3
3 3
4 0
4 0
5 4
5 4
6 4
6 4
7 1
7 1
8 4
8 4
9 2
9 2
dtype: int8
dtype: int8
All that you need to do to exactly mimic the earlier manual output is to reorder the codes:
要完全模仿早期的手动输出,您需要做的就是对代码重新排序:
Notice that the dtype is NumPy’s int8, an 8-bit signed integer that can take on values from -127 to 128. (Only a single byte is needed to represent a value in memory. 64-bit signed ints would be overkill in terms of memory usage.) Our rough-hewn example resulted in int64 data by default, whereas Pandas is smart enough to downcast categorical data to the smallest numerical dtype possible.
请注意,dtype是NumPy的int8 ,这是一个8位带符号整数 ,可以接受-127到128之间的值。(只需要一个字节就可以表示内存中的值。就以下方面而言,64位带符号的ints可能会过大。我们的粗略示例默认情况下会生成int64数据,而Pandas足够聪明,可以将分类数据转换为可能的最小数字dtype。
Most of the attributes for .cat are related to viewing and manipulating the underlying categories themselves:
.cat大多数属性与查看和操作基础类别本身有关:
>>> >>> [[ i i for for i i in in dirdir (( ccolorsccolors .. catcat ) ) if if not not ii .. startswithstartswith (( '_''_' )]
)]
['add_categories',
['add_categories',
'as_ordered',
'as_ordered',
'as_unordered',
'as_unordered',
'categories',
'categories',
'codes',
'codes',
'ordered',
'ordered',
'remove_categories',
'remove_categories',
'remove_unused_categories',
'remove_unused_categories',
'rename_categories',
'rename_categories',
'reorder_categories',
'reorder_categories',
'set_categories']
'set_categories']
There are a few caveats, though. Categorical data is generally less flexible. For instance, if inserting previously unseen values, you need to add this value to a .categories container first:
不过,有一些警告。 分类数据通常不太灵活。 例如,如果插入以前看不见的值,则需要首先将此值添加到.categories容器中:
If you plan to be setting values or reshaping data rather than deriving new computations, Categorical types may be less nimble.
如果您打算设置值或重塑数据而不是派生新的计算,则Categorical类型可能不太灵活。
6.通过迭代自检Groupby对象 (6. Introspect Groupby Objects via Iteration)
When you call df.groupby('x'), the resulting Pandas groupby objects can be a bit opaque. This object is lazily instantiated and doesn’t have any meaningful representation on its own.
调用df.groupby('x') ,生成的Pandas groupby对象可能有点不透明。 该对象是延迟实例化的,并且本身没有任何有意义的表示。
You can demonstrate with the abalone dataset from example 1:
您可以使用示例1中的鲍鱼数据集进行演示:
>>> >>> abaloneabalone [[ 'ring_quartile''ring_quartile' ] ] = = pdpd .. qcutqcut (( abaloneabalone .. ringsrings , , qq == 44 , , labelslabels == rangerange (( 11 , , 55 ))
))
>>> >>> grouped grouped = = abaloneabalone .. groupbygroupby (( 'ring_quartile''ring_quartile' )
)
>>> >>> grouped
grouped
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x11c1169b0>
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x11c1169b0>
Alright, now you have a groupby object, but what is this thing, and how do I see it?
好了,现在您有了一个groupby对象,但是这是什么东西,我怎么看?
Before you call something like grouped.apply(func), you can take advantage of the fact that groupby objects are iterable:
在调用诸如grouped.apply(func)类的东西之前,您可以利用groupby对象可迭代的事实:
Each “thing” yielded by grouped.__iter__() is a tuple of (name, subsetted object), where name is the value of the column on which you’re grouping, and subsetted object is a DataFrame that is a subset of the original DataFrame based on whatever grouping condition you specify. That is, the data gets chunked by group:
由grouped.__iter__()产生的每个“事物”都是(name, subsetted object)的元组,其中name是您要分组的列的值,而子集的subsetted object是作为原始子集的DataFrame基于您指定的分组条件的DataFrame。 也就是说,数据按组分块:
>>> >>> for for idxidx , , frame frame in in groupedgrouped :
:
... ... printprint (( ff 'Ring quartile: {idx}''Ring quartile: {idx}' )
)
... ... printprint (( '-' '-' * * 1616 )
)
... ... printprint (( frameframe .. nlargestnlargest (( 33 , , 'weight''weight' ), ), endend == '' nnnn '' )
)
...
...
Ring quartile: 1
Ring quartile: 1
----------------
----------------
sex length diam height weight rings ring_quartile
sex length diam height weight rings ring_quartile
2619 M 0.690 0.540 0.185 1.7100 8 1
2619 M 0.690 0.540 0.185 1.7100 8 1
1044 M 0.690 0.525 0.175 1.7005 8 1
1044 M 0.690 0.525 0.175 1.7005 8 1
1026 M 0.645 0.520 0.175 1.5610 8 1
1026 M 0.645 0.520 0.175 1.5610 8 1
Ring quartile: 2
Ring quartile: 2
----------------
----------------
sex length diam height weight rings ring_quartile
sex length diam height weight rings ring_quartile
2811 M 0.725 0.57 0.190 2.3305 9 2
2811 M 0.725 0.57 0.190 2.3305 9 2
1426 F 0.745 0.57 0.215 2.2500 9 2
1426 F 0.745 0.57 0.215 2.2500 9 2
1821 F 0.720 0.55 0.195 2.0730 9 2
1821 F 0.720 0.55 0.195 2.0730 9 2
Ring quartile: 3
Ring quartile: 3
----------------
----------------
sex length diam height weight rings ring_quartile
sex length diam height weight rings ring_quartile
1209 F 0.780 0.63 0.215 2.657 11 3
1209 F 0.780 0.63 0.215 2.657 11 3
1051 F 0.735 0.60 0.220 2.555 11 3
1051 F 0.735 0.60 0.220 2.555 11 3
3715 M 0.780 0.60 0.210 2.548 11 3
3715 M 0.780 0.60 0.210 2.548 11 3
Ring quartile: 4
Ring quartile: 4
----------------
----------------
sex length diam height weight rings ring_quartile
sex length diam height weight rings ring_quartile
891 M 0.730 0.595 0.23 2.8255 17 4
891 M 0.730 0.595 0.23 2.8255 17 4
1763 M 0.775 0.630 0.25 2.7795 12 4
1763 M 0.775 0.630 0.25 2.7795 12 4
165 M 0.725 0.570 0.19 2.5500 14 4
165 M 0.725 0.570 0.19 2.5500 14 4
Relatedly, a groupby object also has .groups and a group-getter, .get_group():
相关地,一个groupby对象也具有.groups和一个group-getter .get_group() :
This can help you be a little more confident that the operation you’re performing is the one you want:
这可以帮助您更加确信自己正在执行的操作就是您想要的操作:
>>> >>> groupedgrouped [[ 'height''height' , , 'weight''weight' ]] .. aggagg ([([ 'mean''mean' , , 'median''median' ])
])
height weight
height weight
mean median mean median
mean median mean median
ring_quartile
ring_quartile
1 0.1066 0.105 0.4324 0.3685
1 0.1066 0.105 0.4324 0.3685
2 0.1427 0.145 0.8520 0.8440
2 0.1427 0.145 0.8520 0.8440
3 0.1572 0.155 1.0669 1.0645
3 0.1572 0.155 1.0669 1.0645
4 0.1648 0.165 1.1149 1.0655
4 0.1648 0.165 1.1149 1.0655
No matter what calculation you perform on grouped, be it a single Pandas method or custom-built function, each of these “sub-frames” is passed one-by-one as an argument to that callable. This is where the term “split-apply-combine” comes from: break the data up by groups, perform a per-group calculation, and recombine in some aggregated fashion.
无论您对grouped进行什么计算,无论是单个Pandas方法还是自定义函数,这些“子帧”中的每一个都会作为参数传递给该可调用对象。 这就是“拆分应用合并”一词的来源:按组分解数据,按组进行计算,然后以某种聚合方式重新组合。
If you’re having trouble visualizing exactly what the groups will actually look like, simply iterating over them and printing a few can be tremendously useful.
如果您无法准确地看到组的实际外观,则只需遍历它们并打印一些即可非常有用。
7.使用此映射技巧进行会员分组 (7. Use This Mapping Trick for Membership Binning)
Let’s say that you have a Series and a corresponding “mapping table” where each value belongs to a multi-member group, or to no groups at all:
假设您有一个Series和一个对应的“映射表”,其中每个值都属于一个多成员组,或者根本不属于任何组:
In other words, you need to map countries to the following result:
换句话说,您需要将countries映射到以下结果:
0 North America
0 North America
1 North America
1 North America
2 North America
2 North America
3 Europe
3 Europe
4 Europe
4 Europe
5 other
5 other
dtype: object
dtype: object
What you need here is a function similar to Pandas’ pd.cut(), but for binning based on categorical membership. You can use pd.Series.map(), which you already saw in example #5, to mimic this:
这里您需要的功能类似于Pandas的pd.cut() ,但是用于基于分类成员资格的装箱。 您可以使用在示例5中已经看到的pd.Series.map()来模仿:
This should be significantly faster than a nested Python loop through groups for each country in countries.
这应该是显著比Python的嵌套循环更快通过groups在每个国家countries 。
Here’s a test drive:
这是一个试驾:
>>> >>> membership_mapmembership_map (( countriescountries , , groupsgroups , , fillvaluefillvalue == 'other''other' )
)
0 North America
0 North America
1 North America
1 North America
2 North America
2 North America
3 Europe
3 Europe
4 Europe
4 Europe
5 other
5 other
dtype: object
dtype: object
Let’s break down what’s going on here. (Sidenote: this is a great place to step into a function’s scope with Python’s debugger, pdb, to inspect what variables are local to the function.)
让我们分解一下这里发生的事情。 (旁注:这是使用Python的调试器pdb进入函数范围的好地方,以检查哪些变量对于函数而言是本地的。)
The objective is to map each group in groups to an integer. However, Series.map() will not recognize 'ab'—it needs the broken-out version with each character from each group mapped to an integer. This is what the dictionary comprehension is doing:
目标是在每一个群映射groups为整数。 但是, Series.map()无法识别'ab'它需要将每个组中的每个字符映射为一个整数的细分版本。 这是字典理解的作用:
This dictionary can be passed to s.map() to map or “translate” its values to their corresponding group indices.
该字典可以传递给s.map()以将其值映射或“翻译”为其相应的组索引。
8.了解熊猫如何使用布尔运算符 (8. Understand How Pandas Uses Boolean Operators)
You may be familiar with Python’s operator precedence, where and, not, and or have lower precedence than arithmetic operators such as <, <=, >, >=, !=, and ==. Consider the two statements below, where < and > have higher precedence than the and operator:
您可能熟悉Python的运算符优先级 ,其中and , not和or有比算术运算符,如较低的优先级< , <= > , >= , !=和== 。 考虑下面的两个语句,其中<和>优先级高于and运算符:
>>> >>> # Evaluates to "False and True"
# Evaluates to "False and True"
>>> >>> 4 4 < < 3 3 and and 5 5 > > 4
4
False
False
>>> >>> # Evaluates to 4 < 5 > 4
# Evaluates to 4 < 5 > 4
>>> >>> 4 4 < < (( 3 3 and and 55 ) ) > > 4
4
True
True
Note: It’s not specifically Pandas-related, but 3 and 5 evaluates to 5 because of short-circuit evaluation:
注意 :它与Pandas无关,但是3 and 5 5由于短路评估而得出5 :
“The return value of a short-circuit operator is the last evaluated argument.” (Source)
“短路运算符的返回值是最后计算的参数。” (资源)
Pandas (and NumPy, on which Pandas is built) does not use and, or, or not. Instead, it uses &, |, and ~, respectively, which are normal, bona fide Python bitwise operators.
熊猫(以及构建熊猫的NumPy)不使用and , or或or not 。 而是使用& , | 和~ ,分别是普通的,善意的Python按位运算符。
These operators are not “invented” by Pandas. Rather, &, |, and ~ are valid Python built-in operators that have higher (rather than lower) precedence than arithmetic operators. (Pandas overrides dunder methods like .__ror__() that map to the | operator.) To sacrifice some detail, you can think of “bitwise” as “elementwise” as it relates to Pandas and NumPy:
这些运算符不是熊猫“发明”的。 而是& , | 和~是有效的Python内置运算符,其优先级比算术运算符高(而不是低)。 (Pandas覆盖了映射到|运算符的诸如.__ror__()类的dunder方法。)要牺牲一些细节,可以将“按位”视为与“ Pandas”和NumPy相关的“按元素”:
It pays to understand this concept in full. Let’s say that you have a range-like Series:
充分理解这个概念是值得的。 假设您有一个类似范围的系列:
>>> >>> s s = = pdpd .. SeriesSeries (( rangerange (( 1010 ))
))
I would guess that you may have seen this exception raised at some point:
我猜您可能在某个时候看到了此异常:
What’s happening here? It’s helpful to incrementally bind the expression with parentheses, spelling out how Python expands this expression step by step:
这里发生了什么事? 用括号将表达式增量绑定会很有帮助,阐明Python如何逐步扩展该表达式:
s s % % 2 2 == == 0 0 & & s s > > 3 3 # Same as above, original expression
# Same as above, original expression
(( s s % % 22 ) ) == == 0 0 & & s s > > 3 3 # Modulo is most tightly binding here
# Modulo is most tightly binding here
(( s s % % 22 ) ) == == (( 0 0 & & ss ) ) > > 3 3 # Bitwise-and is second-most-binding
# Bitwise-and is second-most-binding
(( s s % % 22 ) ) == == (( 0 0 & & ss ) ) and and (( 0 0 & & ss ) ) > > 3 3 # Expand the statement
# Expand the statement
(((( s s % % 22 ) ) == == (( 0 0 & & ss )) )) and and (((( 0 0 & & ss ) ) > > 33 ) ) # The `and` operator is least-binding
# The `and` operator is least-binding
The expression s % 2 == 0 & s > 3 is equivalent to (or gets treated as) ((s % 2) == (0 & s)) and ((0 & s) > 3). This is called expansion: x < y <= z is equivalent to x < y and y <= z.
表达式s % 2 == 0 & s > 3等效于( ((s % 2) == (0 & s)) and ((0 & s) > 3) 。 这称为扩展 : x < y <= z等效于x < y and y <= z 。
Okay, now stop there, and let’s bring this back to Pandas-speak. You have two Pandas Series that we’ll call left and right:
好吧,现在停在那儿,让我们把它带回给熊猫讲。 你有两个熊猫系列,我们会打电话给left和right :
You know that a statement of the form left and right is truth-value testing both left and right, as in the following:
你知道格式的语句, left and right为真值测试这两个left和right ,如下所示:
>>> >>> boolbool (( leftleft ) ) and and boolbool (( rightright )
)
The problem is that Pandas developers intentionally don’t establish a truth-value (truthiness) for an entire Series. Is a Series True or False? Who knows? The result is ambiguous:
问题在于,熊猫开发人员有意不为整个系列建立真值(真实性)。 系列是对还是错? 谁知道? 结果是模棱两可的:
The only comparison that makes sense is an elementwise comparison. That’s why, if an arithmetic operator is involved, you’ll need parentheses:
唯一有意义的比较是元素比较。 这就是为什么如果涉及算术运算符,则需要括号 :
>>> >>> (( s s % % 2 2 == == 00 ) ) & & (( s s > > 33 )
)
0 False
0 False
1 False
1 False
2 False
2 False
3 False
3 False
4 True
4 True
5 False
5 False
6 True
6 True
7 False
7 False
8 True
8 True
9 False
9 False
dtype: bool
dtype: bool
In short, if you see the ValueError above pop up with boolean indexing, the first thing you should probably look to do is sprinkle in some needed parentheses.
简而言之,如果您看到上面的ValueError带有布尔索引,那么您可能应该做的第一件事就是撒上一些所需的括号。
9.从剪贴板加载数据 (9. Load Data From the Clipboard)
It’s a common situation to need to transfer data from a place like Excel or Sublime Text to a Pandas data structure. Ideally, you want to do this without going through the intermediate step of saving the data to a file and afterwards reading in the file to Pandas.
通常需要将数据从Excel或Sublime Text等位置传输到Pandas数据结构。 理想情况下,您希望这样做而无需执行将数据保存到文件然后再将文件读入Pandas的中间步骤。
You can load in DataFrames from your computer’s clipboard data buffer with pd.read_clipboard(). Its keyword arguments are passed on to pd.read_table().
您可以使用pd.read_clipboard()从计算机的剪贴板数据缓冲区pd.read_clipboard() 。 它的关键字参数传递给pd.read_table() 。
This allows you to copy structured text directly to a DataFrame or Series. In Excel, the data would look something like this:
这使您可以将结构化文本直接复制到DataFrame或Series。 在Excel中,数据如下所示:
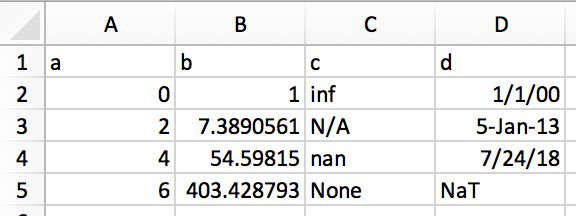
Its plain-text representation (for example, in a text editor) would look like this:
它的纯文本表示形式(例如,在文本编辑器中)如下所示:
Simply highlight and copy the plain text above, and call pd.read_clipboard():
只需突出显示并复制上面的纯文本,然后调用pd.read_clipboard() :
>>> >>> df df = = pdpd .. read_clipboardread_clipboard (( na_valuesna_values == [[ NoneNone ], ], parse_datesparse_dates == [[ 'd''d' ])
])
>>> >>> df
df
a b c d
a b c d
0 0 1.0000 inf 2000-01-01
0 0 1.0000 inf 2000-01-01
1 2 7.3891 NaN 2013-01-05
1 2 7.3891 NaN 2013-01-05
2 4 54.5982 NaN 2018-07-24
2 4 54.5982 NaN 2018-07-24
3 6 403.4288 NaN NaT
3 6 403.4288 NaN NaT
>>> >>> dfdf .. dtypes
dtypes
a int64
a int64
b float64
b float64
c float64
c float64
d datetime64[ns]
d datetime64[ns]
dtype: object
dtype: object
10.直接将熊猫对象写入压缩格式 (10. Write Pandas Objects Directly to Compressed Format)
This one’s short and sweet to round out the list. As of Pandas version 0.21.0, you can write Pandas objects directly to gzip, bz2, zip, or xz compression, rather than stashing the uncompressed file in memory and converting it. Here’s an example using the abalone data from trick #1:
这是一个简短而甜蜜的清单。 从Pandas 0.21.0版开始,您可以将Pandas对象直接写入gzip,bz2,zip或xz压缩,而不必将未压缩的文件存储在内存中并进行转换。 这是一个使用技巧#1中的abalone数据的示例:
In this case, the size difference is 11.6x:
在这种情况下,大小差为11.6倍:
>>> >>> import import os.path
os.path
>>> >>> abaloneabalone .. to_jsonto_json (( 'df.json''df.json' , , orientorient == 'records''records' , , lineslines == TrueTrue )
)
>>> >>> osos .. pathpath .. getsizegetsize (( 'df.json''df.json' ) ) / / osos .. pathpath .. getsizegetsize (( 'df.json.gz''df.json.gz' )
)
11.603035760226396
11.603035760226396
要添加到此列表? 让我们知道 (Want to Add to This List? Let Us Know)
Hopefully, you were able to pick up a couple of useful tricks from this list to lend your Pandas code better readability, versatility, and performance.
希望您能够从此列表中选出一些有用的技巧,以使您的Pandas代码具有更好的可读性,多功能性和性能。
If you have something up your sleeve that’s not covered here, please leave a suggestion in the comments or as a GitHub Gist. We will gladly add to this list and give credit where it’s due.
如果您有一些未在此处介绍的内容,请在评论中留下建议或作为GitHub Gist 。 我们很乐意将其添加到此列表中,并在适当的时候给予感谢。
翻译自: https://www.pybloggers.com/2018/08/python-pandas-tricks-features-you-may-not-know/
python熊猫图案















 2594
2594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









