





快排递归非递归python
Of all ideas I have introduced to children, recursion stands out as the one idea that is particularly able to evoke an excited response.Seymour Papert, Mindstorms
在我介绍给孩子们的所有想法中,递归特别引人注目,它是一种特别能引起激动的想法。 西摩·Perl特(Seymour Papert),《头脑风暴》

Problems (in life and also in computer science) can often seem big and scary. But if we keep chipping away at them, more often than not we can break them down into smaller chunks trivial enough to solve. This is the essence of thinking recursively, and my aim in this article is to provide you, my dear reader, with the conceptual tools necessary to approach problems from this recursive point of view.
问题(生活中以及计算机科学中的问题)通常看起来很可怕。 但是,如果我们不停地削减它们,往往会把它们分解成较小的小块,这些小块足以解决。 这是递归思考的本质,本文的目的是为您,亲爱的读者,提供从递归的角度解决问题所必需的概念工具。
Together, we’ll learn how to work with recursion in our Python programs by mastering concepts such as recursive functions and recursive data structures. We’ll also talk about maintaining state during recursion and avoiding recomputation by caching results. This is going to be a lot of fun. Onwards and upwards!
在一起,我们将通过掌握递归函数和递归数据结构等概念,学习如何在Python程序中使用递归。 我们还将讨论在递归过程中保持状态,以及通过缓存结果来避免重新计算。 这会很有趣。 向上和向上!
亲爱的Pythonic圣诞老人… (Dear Pythonic Santa Claus…)
I realize that as fellow Pythonistas we are all consenting adults here, but children seem to grok the beauty of recursion better. So let’s not be adults here for a moment and talk about how we can use recursion to help Santa Claus.
我意识到,与Pythonista一样,我们都同意这里的成年人,但是孩子们似乎更好地理解了递归的美丽。 因此,让我们暂时不要大人在这里谈论如何使用递归来帮助圣诞老人。
Have you ever wondered how Christmas presents are delivered? I sure have, and I believe Santa Claus has a list of houses he loops through. He goes to a house, drops off the presents, eats the cookies and milk, and moves on to the next house on the list. Since this algorithm for delivering presents is based on an explicit loop construction, it is called an iterative algorithm.
您是否想过圣诞节礼物如何交付? 我确实有,而且我相信圣诞老人会列出他所浏览的房屋清单。 他去了一所房子,放下礼物,吃饼干和牛奶,然后转到清单上的下一所房子。 由于此送达礼物的算法基于显式循环构造,因此称为迭代算法。

The algorithm for iterative present delivery implemented in Python:
用Python实现的迭代式当前传递算法:
houses houses = = [[ "Eric's house""Eric's house" , , "Kenny's house""Kenny's house" , , "Kyle's house""Kyle's house" , , "Stan's house""Stan's house" ]
]
def def deliver_presents_iterativelydeliver_presents_iteratively ():
():
for for house house in in houseshouses :
:
printprint (( "Delivering presents to""Delivering presents to" , , househouse )
)
But I feel for Santa. At his age, he shouldn’t have to deliver all the presents by himself. I propose an algorithm with which he can divide the work of delivering presents among his elves:
但是我觉得圣诞老人。 在他的年龄,他不必自己交付所有礼物。 我提出了一种算法,他可以利用该算法将送礼物的工作分配给他的小精灵:
- Appoint an elf and give all the work to him
- Assign titles and responsibilities to the elves based on the number of houses for which they are responsible:
> 1He is a manager and can appoint two elves and divide his work among them= 1He is a worker and has to deliver the presents to the house assigned to him
- 任命一个精灵并将所有工作交给他
- 根据精灵负责的房屋数量为他们分配头衔和职责:
> 1他是一位经理,可以任命两个精灵并在其中分配工作= 1他是一名工人,必须将礼物送到分配给他的房子里

This is the typical structure of a recursive algorithm. If the current problem represents a simple case, solve it. If not, divide it into subproblems and apply the same strategy to them.
这是递归算法的典型结构。 如果当前问题只是一个简单的案例,请解决它。 如果不是,则将其划分为子问题并对其应用相同的策略。
The algorithm for recursive present delivery implemented in Python:
用Python实现的递归当前传递算法:
houses houses = = [[ "Eric's house""Eric's house" , , "Kenny's house""Kenny's house" , , "Kyle's house""Kyle's house" , , "Stan's house""Stan's house" ]
]
# Each function call represents an elf doing his work
# Each function call represents an elf doing his work
def def deliver_presents_recursivelydeliver_presents_recursively (( houseshouses ):
):
# Worker elf doing his work
# Worker elf doing his work
if if lenlen (( houseshouses ) ) == == 11 :
:
house house = = houseshouses [[ 00 ]
]
printprint (( "Delivering presents to""Delivering presents to" , , househouse )
)
# Manager elf doing his work
# Manager elf doing his work
elseelse :
:
mid mid = = lenlen (( houseshouses ) ) // // 2
2
first_half first_half = = houseshouses [:[: midmid ]
]
second_half second_half = = houseshouses [[ midmid :]
:]
# Divides his work among two elves
# Divides his work among two elves
deliver_presents_recursivelydeliver_presents_recursively (( first_halffirst_half )
)
deliver_presents_recursivelydeliver_presents_recursively (( second_halfsecond_half )
)
Python中的递归函数 (Recursive Functions in Python)
Now that we have some intuition about recursion, let’s introduce the formal definition of a recursive function. A recursive function is a function defined in terms of itself via self-referential expressions. This means that the function will continue to call itself and repeat its behavior until some condition is met to return a result. All recursive functions share a common structure made up of two parts: base case and recursive case. To demonstrate this structure, let’s write a recursive function for calculating n!:
现在我们对递归有了一些直觉,让我们介绍一个递归函数的形式定义。 递归函数是通过自我引用表达式根据自身定义的函数。 这意味着该函数将继续调用自身并重复其行为,直到满足某些条件才能返回结果。 所有递归函数共享一个由两部分组成的通用结构:基本案例和递归案例。 为了演示这种结构,让我们编写一个用于计算n!的递归函数n! :
- Decompose the original problem into simpler instances of the same problem. This is the recursive case:
n! = n x (n−1) x (n−2) x (n−3) ⋅⋅⋅⋅ x 3 x 2 x 1 n! = n x (n−1)! - As the large problem is broken down into successively less complex ones, those subproblems must eventually become so simple that they can be solved without further subdivision. This is the base case:
- 将原始问题分解为相同问题的更简单实例。 这是递归的情况:
n! = n x (n−1) x (n−2) x (n−3) ⋅⋅⋅⋅ x 3 x 2 x 1 n! = n x (n−1)! - 随着大问题被分解为不那么复杂的问题,这些子问题最终必须变得如此简单,以至于无需进一步细分就可以解决。 这是基本情况:
Here, 1! is our base case, and it equals 1.
在这里1! 是我们的基本情况,等于1 。
Recursive function for calculating n! implemented in Python:
用于计算n!递归函数n! 用Python实现:
def def factorial_recursivefactorial_recursive (( nn ):
):
# Base case: 1! = 1
# Base case: 1! = 1
if if n n == == 11 :
:
return return 1
1
# Recursive case: n! = n * (n-1)!
# Recursive case: n! = n * (n-1)!
elseelse :
:
return return n n * * factorial_recursivefactorial_recursive (( nn -- 11 )
)
Behind the scenes, each recursive call adds a stack frame (containing its execution context) to the call stack until we reach the base case. Then, the stack begins to unwind as each call returns its results:
在幕后,每个递归调用都会向调用堆栈添加一个堆栈框架(包含其执行上下文),直到我们到达基本情况为止。 然后,随着每个调用返回其结果,堆栈开始展开:

维持状态 (Maintaining State)
When dealing with recursive functions, keep in mind that each recursive call has its own execution context, so to maintain state during recursion you have to either:
在处理递归函数时,请记住,每个递归调用都有其自己的执行上下文,因此要在递归期间保持状态,您必须:
- Thread the state through each recursive call so that the current state is part of the current call’s execution context
- Keep the state in global scope
- 将状态遍历每个递归调用,以使当前状态成为当前调用执行上下文的一部分
- 保持国家在全球范围内
A demonstration should make things clearer. Let’s calculate 1 + 2 + 3 ⋅⋅⋅⋅ + 10 using recursion. The state that we have to maintain is (current number we are adding, accumulated sum till now).
示范应该使事情更清楚。 让我们使用递归计算1 + 2 + 3 ⋅⋅⋅⋅ + 10 。 我们必须保持的状态是(我们正在添加的当前数量,到现在为止的累积总和)。
Here’s how you do that by threading it through each recursive call (i.e. passing the updated current state to each recursive call as arguments):
这是通过在每个递归调用中将其线程化(即将更新的当前状态作为参数传递给每个递归调用)来实现的:
def def sum_recursivesum_recursive (( current_numbercurrent_number , , accumulated_sumaccumulated_sum ):
):
# Base case
# Base case
# Return the final state
# Return the final state
if if current_number current_number == == 1111 :
:
return return accumulated_sum
accumulated_sum
# Recursive case
# Recursive case
# Thread the state through the recursive call
# Thread the state through the recursive call
elseelse :
:
return return sum_recursivesum_recursive (( current_number current_number + + 11 , , accumulated_sum accumulated_sum + + current_numbercurrent_number )
)
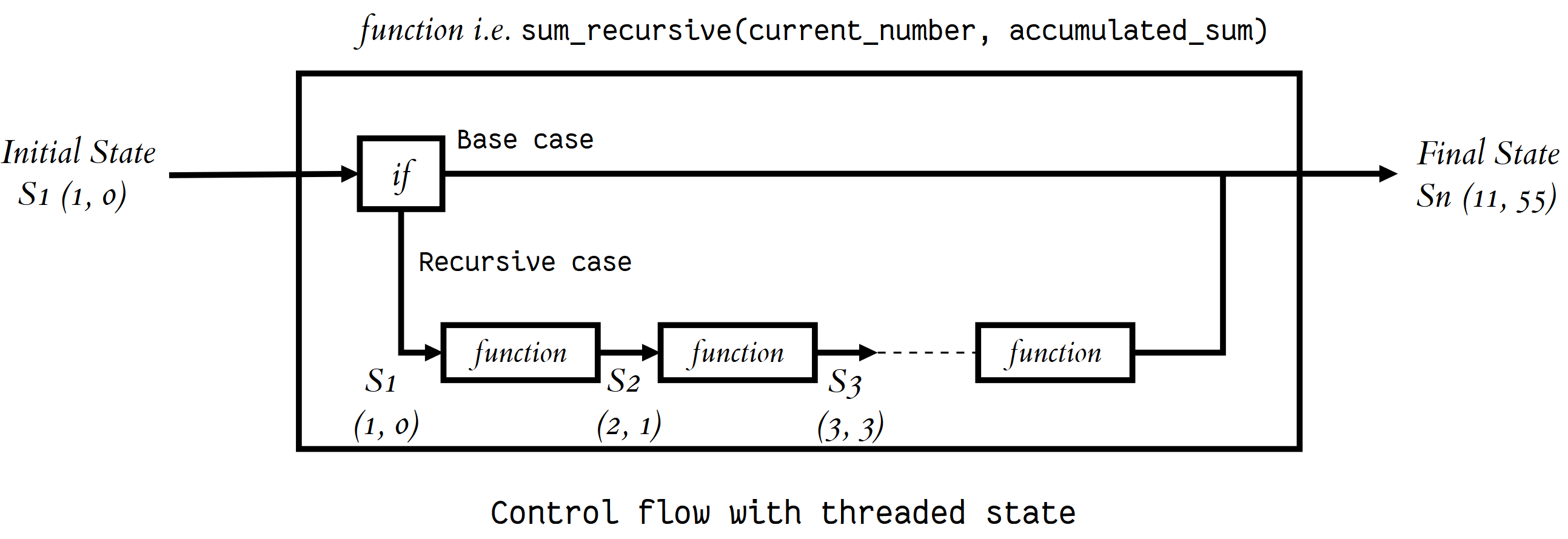
Here’s how you maintain the state by keeping it in global scope:
将状态保持在全局范围内的方法如下:
# Global mutable state
# Global mutable state
current_number current_number = = 1
1
accumulated_sum accumulated_sum = = 0
0
def def sum_recursivesum_recursive ():
():
global global current_number
current_number
global global accumulated_sum
accumulated_sum
# Base case
# Base case
if if current_number current_number == == 1111 :
:
return return accumulated_sum
accumulated_sum
# Recursive case
# Recursive case
elseelse :
:
accumulated_sum accumulated_sum = = accumulated_sum accumulated_sum + + current_number
current_number
current_number current_number = = current_number current_number + + 1
1
return return sum_recursivesum_recursive ()
()
I prefer threading the state through each recursive call because I find global mutable state to be evil, but that’s a discussion for a later time.
我更喜欢在每个递归调用中使用状态,因为我发现全局可变状态是邪恶的,但这是以后的讨论。
Python中的递归数据结构 (Recursive Data Structures in Python)
A data structure is recursive if it can be defined in terms of a smaller version of itself. A list is an example of a recursive data structure. Let me demonstrate. Assume that you have only an empty list at your disposal, and the only operation you can perform on it is this:
如果可以根据自身的较小版本定义数据结构,则该数据结构是递归的。 列表是递归数据结构的示例。 让我示范一下。 假设您只有一个空列表可供使用,并且可以对其执行的唯一操作是:
# Return a new list that is the result of
# Return a new list that is the result of
# adding element to the head (i.e. front) of input_list
# adding element to the head (i.e. front) of input_list
def def attach_headattach_head (( elementelement , , input_listinput_list ):
):
return return [[ elementelement ] ] + + input_list
input_list
Using the empty list and the attach_head operation, you can generate any list. For example, let’s generate [1, 46, -31, "hello"]:
使用空列表和attach_head操作,可以生成任何列表。 例如,让我们生成[1, 46, -31, "hello"] :
[1, 46, -31, 'hello']
[1, 46, -31, 'hello']

-
Starting with an empty list, you can generate any list by recursively applying the
attach_headfunction, and thus the list data structure can be defined recursively as: -
Recursion can also be seen as self-referential function composition. We apply a function to an argument, then pass that result on as an argument to a second application of the same function, and so on. Repeatedly composing
attach_headwith itself is the same asattach_headcalling itself repeatedly.
-
从一个空列表开始,可以通过递归应用
attach_head函数来生成任何列表,因此列表数据结构可以递归定义为:+---- attach_head(element, smaller list) list = + +---- empty list 递归也可以看作是自指功能组合。 我们将函数应用于参数,然后将结果作为参数传递给同一函数的第二个应用程序,依此类推。 与自身重复组成的
attach_head与重复调用自身的attach_head相同。
List is not the only recursive data structure. Other examples include set, tree, dictionary, etc.
列表不是唯一的递归数据结构。 其他示例包括集合,树,字典等。
Recursive data structures and recursive functions go together like bread and butter. The recursive function’s structure can often be modeled after the definition of the recursive data structure it takes as an input. Let me demonstrate this by calculating the sum of all the elements of a list recursively:
递归数据结构和递归函数像面包和黄油一样并存。 通常可以在定义递归数据结构作为输入之后,对递归函数的结构进行建模。 让我通过递归计算列表中所有元素的总和来说明这一点:
>>> >>> list_sum_recursivelist_sum_recursive ([([ 11 , , 22 , , 33 ])
])
6
6
天真递归就是天真 (Naive Recursion is Naive)
The Fibonacci numbers were originally defined by the Italian mathematician Fibonacci in the thirteenth century to model the growth of rabbit populations. Fibonacci surmised that the number of pairs of rabbits born in a given year is equal to the number of pairs of rabbits born in each of the two previous years, starting from one pair of rabbits in the first year. To count the number of rabbits born in the nth year, he defined the recurrence relation:
Fibonacci数最初是由意大利数学家Fibonacci在13世纪定义的,用于模拟兔的生长。 斐波那契推测,从第一年的一对兔子开始,给定年份出生的兔子对的数量等于前两年每年出生的兔子对的数量。 为了计算第n年出生的兔子数量,他定义了复发关系:
The base cases are:
基本情况是:
0 = 0 and F0 = 0 and F 1 = 11 = 1Let’s write a recursive function to compute the nth Fibonacci number:
让我们编写一个递归函数来计算第n个斐波那契数:
>>> >>> fibonacci_recursivefibonacci_recursive (( 55 )
)
Calculating F(5), Calculating F(4), Calculating F(3), Calculating F(2), Calculating F(1),
Calculating F(5), Calculating F(4), Calculating F(3), Calculating F(2), Calculating F(1),
Calculating F(0), Calculating F(1), Calculating F(2), Calculating F(1), Calculating F(0),
Calculating F(0), Calculating F(1), Calculating F(2), Calculating F(1), Calculating F(0),
Calculating F(3), Calculating F(2), Calculating F(1), Calculating F(0), Calculating F(1),
Calculating F(3), Calculating F(2), Calculating F(1), Calculating F(0), Calculating F(1),
5
5
Naively following the recursive definition of the nth Fibonacci number was rather inefficient. As you can see from the output above, we are unnecessarily recomputing values. Let’s try to improve fibonacci_recursive by caching the results of each Fibonacci computation Fk :
天真的遵循第n个斐波那契数的递归定义是相当低效的。 从上面的输出中可以看到,我们不必要地重新计算值。 让我们尝试通过缓存每个斐波那契计算F k的结果来改善fibonacci_recursive :
>>> >>> fibonacci_recursivefibonacci_recursive (( 55 )
)
Calculating F(5), Calculating F(4), Calculating F(3), Calculating F(2), Calculating F(1), Calculating F(0),
Calculating F(5), Calculating F(4), Calculating F(3), Calculating F(2), Calculating F(1), Calculating F(0),
5
5
lru_cache is a decorator that caches the results. Thus, we avoid recomputation by explicitly checking for the value before trying to compute it. One thing to keep in mind about lru_cache is that since it uses a dictionary to cache results, the positional and keyword arguments (which serve as keys in that dictionary) to the function must be hashable.
lru_cache是一个缓存结果的装饰器 。 因此,我们通过在尝试计算值之前显式检查值来避免重新计算。 关于lru_cache ,要记住的一件事是,由于它使用字典来缓存结果,因此该函数的位置和关键字参数(在该字典中用作键)必须是可哈希的。
讨厌的细节 (Pesky Details)
Python doesn’t have support for tail-call elimination. As a result, you can cause a stack overflow if you end up using more stack frames than the default call stack depth:
Python不支持尾调用消除 。 结果,如果最终使用的堆栈帧多于默认调用堆栈深度 ,则可能导致堆栈溢出:
Keep this limitation in mind if you have a program that requires deep recursion.
如果您的程序需要深度递归,请记住这一限制。
Also, Python’s mutable data structures don’t support structural sharing, so treating them like immutable data structures is going to negatively affect your space and GC (garbage collection) efficiency because you are going to end up unnecessarily copying a lot of mutable objects. For example, I have used this pattern to decompose lists and recurse over them:
而且,Python的可变数据结构不支持结构共享,因此将它们视为不可变数据结构将对您的空间和GC(垃圾收集)效率产生负面影响,因为您最终将不必要地复制许多可变对象。 例如,我已经使用此模式分解列表并对其进行递归:
>>> >>> input_list input_list = = [[ 11 , , 22 , , 33 ]
]
>>> >>> head head = = input_listinput_list [[ 00 ]
]
>>> >>> tail tail = = input_listinput_list [[ 11 :]
:]
>>> >>> printprint (( "head --""head --" , , headhead )
)
head -- 1
head -- 1
>>> >>> printprint (( "tail --""tail --" , , tailtail )
)
tail -- [2, 3]
tail -- [2, 3]
I did that to simplify things for the sake of clarity. Keep in mind that tail is being created by copying. Recursively doing that over large lists can negatively affect your space and GC efficiency.
为了清楚起见,我这样做是为了简化事情。 请记住,正在通过复制创建拖尾。 以递归方式在大型列表上执行此操作可能会对您的空间和GC效率产生负面影响。
鳍 (Fin)
I was once asked to explain recursion in an interview. I took a sheet of paper and wrote Please turn over on both sides. The interviewer didn’t get the joke, but now that you have read this article, hopefully you do 🙂 Happy Pythoning!
曾经有人要求我在面试中解释递归。 我拿了一张纸,写了Please turn over两边Please turn over 。 面试官没有开玩笑,但是现在您已经阅读了这篇文章,希望您会做🙂Happy Pythoning!
参考资料 (References)
- Thinking Recursively
- The Little Schemer
- Concepts, Techniques, and Models of Computer Programming
- The Algorithm Design Manual
- Haskell Programming from First Principles
翻译自: https://www.pybloggers.com/2018/03/thinking-recursively-in-python/
快排递归非递归python















 5600
5600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









