





In Part 1 of this series, you used Flask and Connexion to create a REST API providing CRUD operations to a simple in-memory structure called PEOPLE. That worked to demonstrate how the Connexion module helps you build a nice REST API along with interactive documentation.
在本系列的第1部分中,您使用了Flask和Connexion创建了一个REST API,该API为一个简单的内存结构PEOPLE提供CRUD操作 。 这证明了Connexion模块如何帮助您构建一个不错的REST API以及交互式文档。
As some noted in the comments for Part 1, the PEOPLE structure is re-initialized every time the application is restarted. In this article, you’ll learn how to store the PEOPLE structure, and the actions the API provides, to a database using SQLAlchemy and Marshmallow.
如第1部分的注释中所述,每次重新启动应用程序时,都会重新初始化PEOPLE结构。 在本文中,您将学习如何使用SQLAlchemy和Marshmallow将PEOPLE结构以及API提供的操作存储到数据库中。
SQLAlchemy provides an Object Relational Model (ORM), which stores Python objects to a database representation of the object’s data. That can help you continue to think in a Pythonic way and not be concerned with how the object data will be represented in a database.
SQLAlchemy提供了一个对象关系模型( ORM ),该模型将Python对象存储到该对象数据的数据库表示中。 这可以帮助您继续以Python方式思考,而不用担心对象数据将如何在数据库中表示。
Marshmallow provides functionality to serialize and deserialize Python objects as they flow out of and into our JSON-based REST API. Marshmallow converts Python class instances to objects that can be converted to JSON.
Marshmallow提供了一些功能,可在Python对象流出和流入基于JSON的REST API时对它们进行序列化和反序列化。 棉花糖将Python类实例转换为可以转换为JSON的对象。
You can find the Python code for this article here.
您可以在此处找到本文的Python代码。
Free Bonus: Click here to download a copy of the “REST API Examples” Guide and get a hands-on introduction to Python + REST API principles with actionable examples.
免费红利: 单击此处下载“ REST API示例”指南的副本,并通过可行的示例获得有关Python + REST API原理的动手介绍。
本文适用于谁 (Who This Article Is For)
If you enjoyed Part 1 of this series, this article expands your tool belt even further. You’ll be using SQLAlchemy to access a database in a more Pythonic way than straight SQL. You’ll also use Marshmallow to serialize and deserialize the data managed by the REST API. To do this, you’ll be making use of basic Object Oriented Programming features available in Python.
如果您喜欢本系列的第1部分,那么本文将进一步扩展您的工具范围。 与直接SQL相比,您将使用SQLAlchemy以更加Python的方式访问数据库。 您还将使用棉花糖对由REST API管理的数据进行序列化和反序列化。 为此,您将利用Python中提供的基本的面向对象编程功能。
You’ll also be using SQLAlchemy to create a database as well as interact with it. This is necessary to get the REST API up and running with the PEOPLE data used in Part 1.
您还将使用SQLAlchemy创建数据库并与之交互。 要使REST API与第1部分中使用的PEOPLE数据一起运行,这是必需的。
The web application presented in Part 1 will have its HTML and JavaScript files modified in minor ways in order to support the changes as well. You can review the final version of the code from Part 1 here.
第1部分中介绍的Web应用程序将以较小的方式修改其HTML和JavaScript文件,以便也支持这些更改。 您可以在此处查看第1部分中代码的最终版本。
其他依赖 (Additional Dependencies)
Before you get started building this new functionality, you’ll need to update the virtualenv you created in order to run the Part 1 code, or create a new one for this project. The easiest way to do that after you have activated your virtualenv is to run this command:
在开始构建此新功能之前,您需要更新创建的virtualenv才能运行第1部分代码,或者为此项目创建一个新的虚拟环境 。 激活virtualenv之后,最简单的方法是运行以下命令:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
This adds more functionality to your virtualenv:
这为您的virtualenv增加了更多功能:
-
Flask-SQLAlchemyadds SQLAlchemy, along with some tie-ins to Flask, allowing programs to access databases. -
flask-marshmallowadds the Flask parts of Marshmallow, which lets programs convert Python objects to and from serializable structures. -
marshmallow-sqlalchemyadds some Marshmallow hooks into SQLAlchemy to allow programs to serialize and deserialize Python objects generated by SQLAlchemy. -
marshmallowadds the bulk of the Marshmallow functionality.
Flask-SQLAlchemy添加了SQLAlchemy以及一些绑定,从而允许程序访问数据库。flask-marshmallow添加了flask-marshmallow的Flask部分,使程序可以将Python对象与可序列化结构之间进行转换。marshmallow-sqlalchemy添加了一些棉花糖挂钩,以允许程序对SQLAlchemy生成的Python对象进行序列化和反序列化。marshmallow增加了棉花糖功能的大部分。
人数据 (People Data)
As mentioned above, the PEOPLE data structure in the previous article is an in-memory Python dictionary. In that dictionary, you used the person’s last name as the lookup key. The data structure looked like this in the code:
如上所述,上一篇文章中的PEOPLE数据结构是内存中的Python字典。 在该词典中,您使用该人的姓氏作为查找关键字。 数据结构在代码中如下所示:
The modifications you’ll make to the program will move all the data to a database table. This means the data will be saved to your disk and will exist between runs of the server.py program.
您将对该程序进行的修改会将所有数据移动到数据库表中。 这意味着数据将保存到磁盘,并且将在server.py程序的运行之间存在。
Because the last name was the dictionary key, the code restricted changing a person’s last name: only the first name could be changed. In addition, moving to a database will allow you to change the last name as it will no longer be used as the lookup key for a person.
由于姓氏是词典密钥,因此代码限制了更改人的姓氏:只能更改名字。 另外,移动到数据库将使您能够更改姓氏,因为它不再用作个人的查找键。
Conceptually, a database table can be thought of as a two-dimensional array where the rows are records, and the columns are fields in those records.
从概念上讲,数据库表可以看作是二维数组,其中行是记录,而列是这些记录中的字段。
Database tables usually have an auto-incrementing integer value as the lookup key to rows. This is called the primary key. Each record in the table will have a primary key whose value is unique across the entire table. Having a primary key independent of the data stored in the table frees you to modify any other field in the row.
数据库表通常具有一个自动递增的整数值作为行的查找键。 这称为主键。 表中的每个记录将具有一个主键,其值在整个表中是唯一的。 具有与存储在表中的数据无关的主键使您可以修改行中的任何其他字段。
Note:
注意:
The auto-incrementing primary key means that the database takes care of:
自动递增主键意味着数据库可以处理:
- Incrementing the largest existing primary key field every time a new record is inserted in the table
- Using that value as the primary key for the newly inserted data
- 每次在表中插入新记录时,递增最大的现有主键字段
- 使用该值作为新插入数据的主键
This guarantees a unique primary key as the table grows.
随着表的增长,这保证了唯一的主键。
You’re going to follow a database convention of naming the table as singular, so the table will be called person. Translating our PEOPLE structure above into a database table named person gives you this:
您将遵循数据库约定将表命名为单数,因此该表将被称为person 。 将我们上面的PEOPLE结构转换PEOPLE为person的数据库表,您会得到以下结果:
| person_id | person_id | lname | 名字 | fname | 名 | timestamp | 时间戳记 |
|---|---|---|---|---|---|---|---|
| 1 | 1个 | Farrell | 法雷尔 | Doug | 道格 | 2018-08-08 21:16:01.888444 | 2018-08-08 21:16:01.888444 |
| 2 | 2 | Brockman | 布罗克曼 | Kent | 肯特郡 | 2018-08-08 21:16:01.889060 | 2018-08-08 21:16:01.889060 |
| 3 | 3 | Easter | 复活节 | Bunny | 兔子 | 2018-08-08 21:16:01.886834 | 2018-08-08 21:16:01.886834 |
Each column in the table has a field name as follows:
表中的每一列都有一个字段名称,如下所示:
person_id: primary key field for each personlname: last name of the personfname: first name of the persontimestamp: timestamp associated with insert/update actions
-
person_id:每个人的主键字段 -
lname:此人的姓氏 -
fname:人的名字 -
timestamp:与插入/更新操作关联的时间戳
数据库交互 (Database Interaction)
You’re going to use SQLite as the database engine to store the PEOPLE data. SQLite is the mostly widely distributed database in the world, and it comes with Python for free. It’s fast, performs all its work using files, and is suitable for a great many projects. It’s a complete RDBMS (Relational Database Management System) that includes SQL, the language of many database systems.
您将使用SQLite作为数据库引擎来存储PEOPLE数据。 SQLite是世界上分布最广泛的数据库,它免费提供Python。 它速度很快,使用文件执行其所有工作,并且适合许多项目。 它是一个完整的RDBMS(关系数据库管理系统),其中包括SQL(许多数据库系统的语言)。
For the moment, imagine the person table already exists in a SQLite database. If you’ve had any experience with RDBMS, you’re probably aware of SQL, the Structured Query Language most RDBMSes use to interact with the database.
目前,假设person表已经存在于SQLite数据库中。 如果您有使用RDBMS的经验,则可能知道SQL,这是大多数RDBMS用来与数据库进行交互的结构化查询语言。
Unlike programming languages like Python, SQL doesn’t define how to get the data: it describes what data is desired, leaving the how up to the database engine.
与Python等编程语言不同,SQL并未定义如何获取数据:它描述了所需的数据,如何处理取决于数据库引擎。
A SQL query getting all of the data in our person table, sorted by last name, would look this this:
一个SQL查询,它获取我们的person表中的所有数据(按姓氏排序)将如下所示:
SELECT SELECT * * FROM FROM person person ORDER ORDER BY BY 'lname''lname' ;
;
This query tells the database engine to get all the fields from the person table and sort them in the default, ascending order using the lname field.
该查询告诉数据库引擎从人员表中获取所有字段,并使用lname字段以默认的升序对它们进行排序。
If you were to run this query against a SQLite database containing the person table, the results would be a set of records containing all the rows in the table, with each row containing the data from all the fields making up a row. Below is an example using the SQLite command line tool running the above query against the person database table:
如果要对包含person表SQLite数据库运行此查询,则结果将是一组记录,其中包含该表中的所有行,每行包含来自构成一个行的所有字段的数据。 以下是使用SQLite命令行工具对person数据库表运行上述查询的示例:
The output above is a list of all the rows in the person database table with pipe characters (‘|’) separating the fields in the row, which is done for display purposes by SQLite.
上面的输出是person数据库表中所有行的列表,其中用竖线字符('|')分隔了行中的字段,这是出于SQLite的显示目的而完成的。
Python is completely capable of interfacing with many database engines and executing the SQL query above. The results would most likely be a list of tuples. The outer list contains all the records in the person table. Each individual inner tuple would contain all the data representing each field defined for a table row.
Python完全能够与许多数据库引擎接口并执行上述SQL查询。 结果很可能是元组列表。 外部列表包含person表中的所有记录。 每个单独的内部元组将包含代表为表行定义的每个字段的所有数据。
Getting data this way isn’t very Pythonic. The list of records is okay, but each individual record is just a tuple of data. It’s up to the program to know the index of each field in order to retrieve a particular field. The following Python code uses SQLite to demonstrate how to run the above query and display the data:
用这种方式获取数据不是Python风格。 记录列表是可以的,但是每个单独的记录只是一个数据元组。 程序要知道每个字段的索引才能检索特定的字段。 以下Python代码使用SQLite演示如何运行上述查询并显示数据:
import import sqlite3
sqlite3
conn conn = = sqlite3sqlite3 .. connectconnect (( 'people.db''people.db' )
)
cur cur = = connconn .. cursorcursor ()
()
curcur .. executeexecute (( 'SELECT * FROM person ORDER BY lname''SELECT * FROM person ORDER BY lname' )
)
people people = = curcur .. fetchallfetchall ()
()
for for person person in in peoplepeople :
:
printprint (( ff '' {person[2]}{person[2]} {person[1]}{person[1]} '' )
)
The program above does the following:
上面的程序执行以下操作:
-
Line 1 imports the
sqlite3module. -
Line 3 creates a connection to the database file.
-
Line 4 creates a cursor from the connection.
-
Line 5 uses the cursor to execute a
SQLquery expressed as a string. -
Line 6 gets all the records returned by the
SQLquery and assigns them to thepeoplevariable. -
Line 7 & 8 iterate over the
peoplelist variable and print out the first and last name of each person.
第1行导入
sqlite3模块。第3行创建到数据库文件的连接。
第4行从连接中创建一个游标。
第5行使用光标执行以字符串表示的
SQL查询。第6行获取
SQL查询返回的所有记录,并将它们分配给people变量。第7和8行遍历
people列表变量,并打印出每个人员的名字和姓氏。
The people variable from Line 6 above would look like this in Python:
上面第6行的people变量在Python中看起来像这样:
The output of the program above looks like this:
上面程序的输出如下所示:
Kent Brockman
Kent Brockman
Bunny Easter
Bunny Easter
Doug Farrell
Doug Farrell
In the above program, you have to know that a person’s first name is at index 2, and a person’s last name is at index 1. Worse, the internal structure of person must also be known whenever you pass the iteration variable person as a parameter to a function or method.
在上面的程序中,您必须知道一个人的名字在索引2 ,一个人的姓在索引1 。 更糟糕的是,每当您将迭代变量person作为参数传递给函数或方法时, person的内部结构也必须已知。
It would be much better if what you got back for person was a Python object, where each of the fields is an attribute of the object. This is one of the things SQLAlchemy does.
这将是好得多,如果你得到了什么回来person是一个Python对象,其中每个字段是对象的属性。 这是SQLAlchemy要做的事情之一。
小鲍比表 (Little Bobby Tables)
In the above program, the SQL statement is a simple string passed directly to the database to execute. In this case, that’s not a problem because the SQL is a string literal completely under the control of the program. However, the use case for your REST API will take user input from the web application and use it to create SQL queries. This can open your application to attack.
在上面的程序中,SQL语句是一个直接传递给数据库以执行的简单字符串。 在这种情况下,这不是问题,因为SQL是完全在程序控制之下的字符串文字。 但是,REST API的用例将从Web应用程序获取用户输入,并将其用于创建SQL查询。 这可以打开您的应用程序进行攻击。
You’ll recall from Part 1 that the REST API to get a single person from the PEOPLE data looked like this:
您会从第1部分中回想起,从PEOPLE数据中获取一个person的REST API看起来像这样:
This means your API is expecting a variable, lname, in the URL endpoint path, which it uses to find a single person. Modifying the Python SQLite code from above to do this would look something like this:
这意味着您的API在URL端点路径中需要一个变量lname ,该变量用于查找一个person 。 从上面修改Python SQLite代码以执行此操作,如下所示:
lname lname = = 'Farrell'
'Farrell'
curcur .. executeexecute (( 'SELECT * FROM person WHERE lname = 'SELECT * FROM person WHERE lname = '' {}{} '' '' .. formatformat (( lnamelname ))
))
The above code snippet does the following:
上面的代码段执行以下操作:
-
Line 1 sets the
lnamevariable to'Farrell'. This would come from the REST API URL endpoint path. -
Line 2 uses Python string formatting to create a SQL string and execute it.
第1
lname变量设置为'Farrell'。 这将来自REST API URL端点路径。第2行使用Python字符串格式来创建SQL字符串并执行它。
To keep things simple, the above code sets the lname variable to a constant, but really it would come from the API URL endpoint path and could be anything supplied by the user. The SQL generated by the string formatting looks like this:
为简单lname ,以上代码将lname变量设置为常量,但实际上它来自API URL端点路径,并且可以由用户提供。 字符串格式生成SQL如下所示:
When this SQL is executed by the database, it searches the person table for a record where the last name is equal to 'Farrell'. This is what’s intended, but any program that accepts user input is also open to malicious users. In the program above, where the lname variable is set by user-supplied input, this opens your program to what’s called a SQL Injection Attack. This is what’s affectionately known as Little Bobby Tables:
当数据库执行此SQL时,它将在person表中搜索姓氏等于'Farrell' 。 这是预期的,但是任何接受用户输入的程序也向恶意用户开放。 在上面的程序中, lname变量由用户提供的输入设置,这会将您的程序打开到所谓的SQL Injection Attack。 这就是亲切的小鲍比表 :
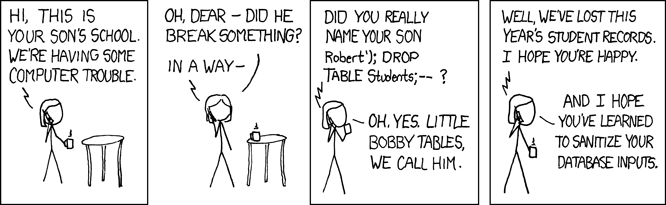
For example, imagine a malicious user called your REST API in this way:
例如,假设有一个恶意用户以这种方式调用了您的REST API:
GET /api/people/Farrell');DROP TABLE person;
GET /api/people/Farrell');DROP TABLE person;
The REST API request above sets the lname variable to 'Farrell');DROP TABLE person;', which in the code above would generate this SQL statement:
上面的REST API请求将lname变量设置为'Farrell');DROP TABLE person;' ,在上面的代码中将生成此SQL语句:
The above SQL statement is valid, and when executed by the database it will find one record where lname matches 'Farrell'. Then, it will find the SQL statement delimiter character ; and will go right ahead and drop the entire table. This would essentially wreck your application.
上面SQL语句是有效的,并且由数据库执行时,将找到一个与lname匹配'Farrell' 。 然后,它将找到SQL语句分隔符; 并继续前进并放下整个桌子。 这实质上会破坏您的应用程序。
You can protect your program by sanitizing all data you get from users of your application. Sanitizing data in this context means having your program examine the user-supplied data and making sure it doesn’t contain anything dangerous to the program. This can be tricky to do right and would have to be done everywhere user data interacts with the database.
您可以通过清除从应用程序用户那里获得的所有数据来保护程序。 在这种情况下清理数据意味着让程序检查用户提供的数据,并确保其中不包含任何对程序有害的数据。 正确地做起来可能很棘手,并且必须在用户数据与数据库进行交互的任何地方都要做。
There’s another way that’s much easier: use SQLAlchemy. It will sanitize user data for you before creating SQL statements. It’s another big advantage and reason to use SQLAlchemy when working with databases.
还有另一种方法容易得多:使用SQLAlchemy。 在创建SQL语句之前,它将为您清除用户数据。 使用数据库时,使用SQLAlchemy是另一个大优点和理由。
使用SQLAlchemy建模数据 (Modeling Data With SQLAlchemy)
SQLAlchemy is a big project and provides a lot of functionality to work with databases using Python. One of the things it provides is an ORM, or Object Relational Mapper, and this is what you’re going to use to create and work with the person database table. This allows you to map a row of fields from the database table to a Python object.
SQLAlchemy是一个大型项目,并提供了许多功能来使用Python处理数据库。 它提供的功能之一是ORM或对象关系映射器,这就是您将要用来创建和使用person数据库表的内容。 这使您可以将数据库表中的一行字段映射到Python对象。
Object Oriented Programming allows you to connect data together with behavior, the functions that operate on that data. By creating SQLAlchemy classes, you’re able to connect the fields from the database table rows to behavior, allowing you to interact with the data. Here’s the SQLAlchemy class definition for the data in the person database table:
面向对象编程使您可以将数据与行为(对数据进行操作的功能)连接在一起。 通过创建SQLAlchemy类,您可以将数据库表行中的字段连接到行为,从而允许您与数据进行交互。 这是person数据库表中数据SQLAlchemy类定义:
class class PersonPerson (( dbdb .. ModelModel ):
):
__tablename__ __tablename__ = = 'person'
'person'
person_id person_id = = dbdb .. ColumnColumn (( dbdb .. IntegerInteger ,
,
primary_keyprimary_key == TrueTrue )
)
lname lname = = dbdb .. ColumnColumn (( dbdb .. StringString )
)
fname fname = = dbdb .. ColumnColumn (( dbdb .. StringString )
)
timestamp timestamp = = dbdb .. ColumnColumn (( dbdb .. DateTimeDateTime ,
,
defaultdefault == datetimedatetime .. utcnowutcnow ,
,
onupdateonupdate == datetimedatetime .. utcnowutcnow )
)
The class Person inherits from db.Model, which you’ll get to when you start building the program code. For now, it means you’re inheriting from a base class called Model, providing attributes and functionality common to all classes derived from it.
Person类从db.Model继承,您将在开始构建程序代码时获得它。 目前,这意味着您要从名为Model的基类继承,提供从其派生的所有类共有的属性和功能。
The rest of the definitions are class-level attributes defined as follows:
其余的定义是类级别的属性,定义如下:
-
__tablename__ = 'person'connects the class definition to thepersondatabase table. -
person_id = db.Column(db.Integer, primary_key=True)creates a database column containing an integer acting as the primary key for the table. This also tells the database thatperson_idwill be an autoincrementing Integer value. -
lname = db.Column(db.String)creates the last name field, a database column containing a string value. -
fname = db.Column(db.String)creates the first name field, a database column containing a string value. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)creates a timestamp field, a database column containing a date/time value. Thedefault=datetime.utcnowparameter defaults the timestamp value to the currentutcnowvalue when a record is created. Theonupdate=datetime.utcnowparameter updates the timestamp with the currentutcnowvalue when the record is updated.
__tablename__ = 'person'将类定义连接到person数据库表。person_id = db.Column(db.Integer, primary_key=True)创建一个数据库列,其中包含一个用作表主键的整数。 这也告诉数据库person_id将是一个自动递增的Integer值。lname = db.Column(db.String)创建姓氏字段,即包含字符串值的数据库列。fname = db.Column(db.String)创建名字字段,即包含字符串值的数据库列。timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)创建一个timestamp字段,一个包含日期/时间值的数据库列。 创建记录时,default=datetime.utcnow参数将时间戳值默认为当前utcnow值。 当更新记录时,onupdate=datetime.utcnow参数使用当前utcnow值更新时间戳。
Note: UTC Timestamps
注意:UTC时间戳
You might be wondering why the timestamp in the above class defaults to and is updated by the datetime.utcnow() method, which returns a UTC, or Coordinated Universal Time. This is a way of standardizing your timestamp’s source.
您可能想知道为什么上述类中的时间戳默认为datetime.utcnow()方法并由其更新,该方法返回UTC或世界协调时间。 这是一种标准化时间戳记来源的方法。
The source, or zero time, is a line running north and south from the Earth’s north to south pole through the UK. This is the zero time zone from which all other time zones are offset. By using this as the zero time source, your timestamps are offsets from this standard reference point.
源(零时间)是一条从地球的北到南穿过英国南北延伸的线。 这是零时区,所有其他时区都从该时区偏移。 通过将其用作零时间源,您的时间戳是相对于该标准参考点的偏移量。
Should your application be accessed from different time zones, you have a way to perform date/time calculations. All you need is a UTC timestamp and the destination time zone.
如果应从不同时区访问您的应用程序,则可以使用一种方法来执行日期/时间计算。 您只需要一个UTC时间戳和目标时区即可。
If you were to use local time zones as your timestamp source, then you couldn’t perform date/time calculations without information about the local time zones offset from zero time. Without the timestamp source information, you couldn’t do any date/time comparisons or math at all.
如果要使用本地时区作为时间戳源,那么如果没有有关本地时区从零时开始偏移的信息,则无法执行日期/时间计算。 没有时间戳记源信息,您将无法进行任何日期/时间比较或数学运算。
Working with a timestamps based on UTC is a good standard to follow. Here’s a toolkit site to work with and better understand them.
使用基于UTC的时间戳是一个很好的遵循标准。 这是一个可以使用并更好地理解它们的工具包站点。
Where are you heading with this Person class definition? The end goal is to be able to run a query using SQLAlchemy and get back a list of instances of the Person class. As an example, let’s look at the previous SQL statement:
这个Person类的定义要去哪里? 最终目标是能够使用SQLAlchemy运行查询并获取Person类的实例列表。 作为示例,让我们看一下前面SQL语句:
Show the same small example program from above, but now using SQLAlchemy:
从上面显示相同的小示例程序,但现在使用SQLAlchemy:
from from models models import import Person
Person
people people = = PersonPerson .. queryquery .. order_byorder_by (( PersonPerson .. lnamelname )) .. allall ()
()
for for person person in in peoplepeople :
:
printprint (( ff '' {person.fname}{person.fname} {person.lname}{person.lname} '' )
)
Ignoring line 1 for the moment, what you want is all the person records sorted in ascending order by the lname field. What you get back from the SQLAlchemy statements Person.query.order_by(Person.lname).all() is a list of Person objects for all records in the person database table in that order. In the above program, the people variable contains the list of Person objects.
目前忽略第1行,您想要的是所有person记录,并按lname字段以升序排序。 从SQLAlchemy语句中获得的信息Person.query.order_by(Person.lname).all()是此person数据库表中所有记录Person.query.order_by(Person.lname).all()的Person对象的列表。 在上面的程序中, people变量包含Person对象的列表。
The program iterates over the people variable, taking each person in turn and printing out the first and last name of the person from the database. Notice the program doesn’t have to use indexes to get the fname or lname values: it uses the attributes defined on the Person object.
该程序遍历people变量,依次获取每个person并从数据库中打印出该人的名字和姓氏。 注意,程序不必使用索引来获取fname或lname值:它使用在Person对象上定义的属性。
Using SQLAlchemy allows you to think in terms of objects with behavior rather than raw SQL. This becomes even more beneficial when your database tables become larger and the interactions more complex.
使用SQLAlchemy可以让您根据具有行为的对象而不是原始SQL进行思考。 当您的数据库表越来越大且交互更加复杂时,这将变得更加有益。
序列化/反序列化建模数据 (Serializing/Deserializing Modeled Data)
Working with SQLAlchemy modeled data inside your programs is very convenient. It is especially convenient in programs that manipulate the data, perhaps making calculations or using it to create presentations on screen. Your application is a REST API essentially providing CRUD operations on the data, and as such it doesn’t perform much data manipulation.
在程序内部使用SQLAlchemy建模数据非常方便。 在处理数据,进行计算或使用它在屏幕上创建演示文稿的程序中,这特别方便。 您的应用程序是一个REST API,本质上提供了对数据的CRUD操作,因此它不会执行太多的数据操作。
The REST API works with JSON data, and here you can run into an issue with the SQLAlchemy model. Because the data returned by SQLAlchemy are Python class instances, Connexion can’t serialize these class instances to JSON formatted data. Remember from Part 1 that Connexion is the tool you used to design and configure the REST API using a YAML file, and connect Python methods to it.
REST API使用JSON数据,在这里您可能会遇到SQLAlchemy模型的问题。 由于SQLAlchemy返回的数据是Python类实例,因此Connexion无法将这些类实例序列化为JSON格式的数据。 请记住,在第1部分中,Connexion是用于使用YAML文件设计和配置REST API并将其与Python方法连接的工具。
In this context, serializing means converting Python objects, which can contain other Python objects and complex data types, into simpler data structures that can be parsed into JSON datatypes, which are listed here:
在这种情况下,序列化意味着将可以包含其他Python对象和复杂数据类型的Python对象转换为可以解析为JSON数据类型的更简单的数据结构,在此处列出:
string: a string typenumber: numbers supported by Python (integers, floats, longs)object: a JSON object, which is roughly equivalent to a Python dictionaryarray: roughly equivalent to a Python Listboolean: represented in JSON astrueorfalse, but in Python asTrueorFalsenull: essentially aNonein Python
-
string:字符串类型 -
number: Python支持的数字(整数,浮点数,长整数) -
object:一个JSON对象,大致等效于Python字典 -
array:大致等同于Python列表 -
boolean:在JSON中表示为true或false,但在Python中表示为True或False -
null:在Python中基本上为None
As an example, your Person class contains a timestamp, which is a Python DateTime. There is no date/time definition in JSON, so the timestamp has to be converted to a string in order to exist in a JSON structure.
例如,您的Person类包含一个时间戳,它是Python DateTime 。 JSON中没有日期/时间定义,因此必须将时间戳转换为字符串才能存在于JSON结构中。
Your Person class is simple enough so getting the data attributes from it and creating a dictionary manually to return from our REST URL endpoints wouldn’t be very hard. In a more complex application with many larger SQLAlchemy models, this wouldn’t be the case. A better solution is to use a module called Marshmallow to do the work for you.
您的Person类非常简单,因此从中获取数据属性并手动创建字典以从我们的REST URL端点返回并不难。 在具有许多较大SQLAlchemy模型的更复杂的应用程序中,情况并非如此。 更好的解决方案是使用一个名为Marshmallow的模块为您完成工作。
Marshmallow helps you to create a PersonSchema class, which is like the SQLAlchemy Person class we created. Here however, instead of mapping database tables and field names to the class and its attributes, the PersonSchema class defines how the attributes of a class will be converted into JSON-friendly formats. Here’s the Marshmallow class definition for the data in our person table:
棉花糖可以帮助您创建PersonSchema类,就像我们创建SQLAlchemy Person类一样。 但是,此处不是将数据库表和字段名称映射到该类及其属性, PersonSchema在PersonSchema类中定义如何将类的属性转换为JSON友好格式。 这是我们的person表中数据的棉花糖类定义:
The class PersonSchema inherits from ma.ModelSchema, which you’ll get to when you start building the program code. For now, this means PersonSchema is inheriting from a Marshmallow base class called ModelSchema, providing attributes and functionality common to all classes derived from it.
类PersonSchema继承自ma.ModelSchema ,当您开始构建程序代码时将获得该类。 目前,这意味着PersonSchema是从棉花糖基类PersonSchema继承的,该基类提供了PersonSchema继承的所有类所ModelSchema属性和功能。
The rest of the definition is as follows:
其余的定义如下:
-
class Metadefines a class namedMetawithin your class. TheModelSchemaclass that thePersonSchemaclass inherits from looks for this internalMetaclass and uses it to find the SQLAlchemy modelPersonand thedb.session. This is how Marshmallow finds attributes in thePersonclass and the type of those attributes so it knows how to serialize/deserialize them. -
modeltells the class what SQLAlchemy model to use to serialize/deserialize data to and from. -
db.sessiontells the class what database session to use to introspect and determine attribute data types.
class Meta类在您的类中定义了一个名为Meta的类。ModelSchema类PersonSchema继承的PersonSchema类将查找此内部Meta类,并使用它来查找SQLAlchemy模型Person和db.session。 这是棉花糖在Person类中查找属性的方式以及这些属性的类型,从而知道如何对它们进行序列化/反序列化。model告诉该类使用什么SQLAlchemy模型对数据进行序列化/反序列化。db.session告诉该类用于反思和确定属性数据类型的数据库会话。
Where are you heading with this class definition? You want to be able to serialize an instance of a Person class into JSON data, and to deserialize JSON data and create a Person class instances from it.
这个类的定义要去哪儿? 您希望能够将Person类的实例序列化为JSON数据,并反序列化JSON数据并从中创建Person类实例。
创建初始化的数据库 (Create the Initialized Database)
SQLAlchemy handles many of the interactions specific to particular databases and lets you focus on the data models as well as how to use them.
SQLAlchemy处理特定于特定数据库的许多交互,并让您专注于数据模型以及如何使用它们。
Now that you’re actually going to create a database, as mentioned before, you’ll use SQLite. You’re doing this for a couple of reasons. It comes with Python and doesn’t have to be installed as a separate module. It saves all of the database information in a single file and is therefore easy to set up and use.
如前所述,既然您实际上要创建一个数据库,您将使用SQLite 。 您这样做有两个原因。 它是Python附带的,不必作为单独的模块安装。 它将所有数据库信息保存在一个文件中,因此易于设置和使用。
Installing a separate database server like MySQL or PostgreSQL would work fine but would require installing those systems and getting them up and running, which is beyond the scope of this article.
安装单独的数据库服务器(如MySQL或PostgreSQL)可以很好地工作,但需要安装这些系统并使其启动并运行,这不在本文的讨论范围之内。
Because SQLAlchemy handles the database, in many ways it really doesn’t matter what the underlying database is.
因为SQLAlchemy处理数据库,所以在许多方面,底层数据库实际上并不重要。
You’re going to create a new utility program called build_database.py to create and initialize the SQLite people.db database file containing your person database table. Along the way, you’ll create two Python modules, config.py and models.py, which will be used by build_database.py and the modified server.py from Part 1.
您将创建一个名为build_database.py的新实用程序,以创建和初始化包含您的person数据库表SQLite people.db数据库文件。 在此过程中,您将创建两个Python模块config.py和models.py ,它们将由build_database.py和第1部分中修改后的server.py使用。
Here’s where you can find the source code for the modules you’re about to create, which are introduced here:
在这里,您可以找到要创建的模块的源代码 ,在此处介绍了这些源代码 :
-
config.pygets the necessary modules imported into the program and configured. This includes Flask, Connexion, SQLAlchemy, and Marshmallow. Because it will be used by bothbuild_database.pyandserver.py, some parts of the configuation will only apply to theserver.pyapplication. -
models.pyis the module where you’ll create thePersonSQLAlchemy andPersonSchemaMarshmallow class definitions described above. This module is dependent onconfig.pyfor some of the objects created and configured there.
config.py将必需的模块导入程序并进行配置。 这包括Flask,Connexion,SQLAlchemy和棉花糖。 因为build_database.py和server.py都将使用它,所以配置的某些部分仅适用于server.py应用程序。models.py是您将在其中创建上述PersonSQLAlchemy和PersonSchemaMarshmallow类定义的模块。 此模块依赖config.py来在此处创建和配置的某些对象。
配置模块 (Config Module)
The config.py module, as the name implies, is where all of the configuration information is created and initialized. We’re going to use this module for both our build_database.py program file and the soon to be updated server.py file from the Part 1 article. This means we’re going to configure Flask, Connexion, SQLAlchemy, and Marshmallow here.
顾名思义, config.py模块是在其中创建和初始化所有配置信息的模块。 我们将在build_database.py程序文件和第1部分文章中即将更新的server.py文件中都使用此模块。 这意味着我们将在此处配置Flask,Connexion,SQLAlchemy和棉花糖。
Even though the build_database.py program doesn’t make use of Flask, Connexion, or Marshmallow, it does use SQLAlchemy to create our connection to the SQLite database. Here is the code for the config.py module:
即使build_database.py程序未使用Flask,Connexion或棉花糖,它也使用SQLAlchemy创建了与SQLite数据库的连接。 这是config.py模块的代码:
import import os
os
import import connexion
connexion
from from flask_sqlalchemy flask_sqlalchemy import import SQLAlchemy
SQLAlchemy
from from flask_marshmallow flask_marshmallow import import Marshmallow
Marshmallow
basedir basedir = = osos .. pathpath .. abspathabspath (( osos .. pathpath .. dirnamedirname (( __file____file__ ))
))
# Create the Connexion application instance
# Create the Connexion application instance
connex_app connex_app = = connexionconnexion .. AppApp (( __name____name__ , , specification_dirspecification_dir == basedirbasedir )
)
# Get the underlying Flask app instance
# Get the underlying Flask app instance
app app = = connex_appconnex_app .. app
app
# Configure the SQLAlchemy part of the app instance
# Configure the SQLAlchemy part of the app instance
appapp .. configconfig [[ 'SQLALCHEMY_ECHO''SQLALCHEMY_ECHO' ] ] = = True
True
appapp .. configconfig [[ 'SQLALCHEMY_DATABASE_URI''SQLALCHEMY_DATABASE_URI' ] ] = = 'sqlite:' 'sqlite:' + + osos .. pathpath .. joinjoin (( basedirbasedir , , 'people.db''people.db' )
)
appapp .. configconfig [[ 'SQLALCHEMY_TRACK_MODIFICATIONS''SQLALCHEMY_TRACK_MODIFICATIONS' ] ] = = False
False
# Create the SQLAlchemy db instance
# Create the SQLAlchemy db instance
db db = = SQLAlchemySQLAlchemy (( appapp )
)
# Initialize Marshmallow
# Initialize Marshmallow
ma ma = = MarshmallowMarshmallow (( appapp )
)
Here’s what the above code is doing:
上面的代码正在执行以下操作:
-
Lines 2 – 4 import Connexion as you did in the
server.pyprogram from Part 1. It also importsSQLAlchemyfrom theflask_sqlalchemymodule. This gives your program database access. Lastly, it importsMarshmallowfrom theflask_marshamllowmodule. -
Line 6 creates the variable
basedirpointing to the directory the program is running in. -
Line 9 uses the
basedirvariable to create the Connexion app instance and give it the path to theswagger.ymlfile. -
Line 12 creates a variable
app, which is the Flask instance initialized by Connexion. -
Lines 15 uses the
appvariable to configure values used by SQLAlchemy. First it setsSQLALCHEMY_ECHOtoTrue. This causes SQLAlchemy to echo SQL statements it executes to the console. This is very useful to debug problems when building database programs. Set this toFalsefor production environments. -
Line 16 sets
SQLALCHEMY_DATABASE_URItosqlite:' + os.path.join(basedir, 'people.db'). This tells SQLAlchemy to use SQLite as the database, and a file namedpeople.dbin the current directory as the database file. Different database engines, like MySQL and PostgreSQL, will have differentSQLALCHEMY_DATABASE_URIstrings to configure them. -
Line 17 sets
SQLALCHEMY_TRACK_MODIFICATIONStoFalse, turning off the SQLAlchemy event system, which is on by default. The event system generates events useful in event-driven programs but adds significant overhead. Since you’re not creating an event-driven program, turn this feature off. -
Line 19 creates the
dbvariable by callingSQLAlchemy(app). This initializes SQLAlchemy by passing theappconfiguration information just set. Thedbvariable is what’s imported into thebuild_database.pyprogram to give it access to SQLAlchemy and the database. It will serve the same purpose in theserver.pyprogram andpeople.pymodule. -
Line 23 creates the
mavariable by callingMarshmallow(app). This initializes Marshmallow and allows it to introspect the SQLAlchemy components attached to the app. This is why Marshmallow is initialized after SQLAlchemy.
第2至4行像在第1部分的
server.py程序中一样导入Connexion。它也从flask_sqlalchemy模块中导入SQLAlchemy。 这使您可以访问程序数据库。 最后,它从flask_marshamllow模块导入Marshmallow。第6行创建变量
basedir指向程序在其中运行的目录。第9行使用
basedir变量创建Connexion应用程序实例,并为其提供swagger.yml文件的路径。第12行创建一个变量
app,它是由Connexion初始化的Flask实例。第15行使用
app变量来配置SQLAlchemy使用的值。 首先,它将SQLALCHEMY_ECHO设置为True。 这将导致SQLAlchemy将执行SQL语句回显到控制台。 这对于调试构建数据库程序时的问题非常有用。 对于生产环境,将其设置为False。第16
SQLALCHEMY_DATABASE_URI设置为sqlite:' + os.path.join(basedir, 'people.db')。 这告诉SQLAlchemy使用SQLite作为数据库,并使用当前目录中一个名为people.db的文件作为数据库文件。 不同的数据库引擎,例如MySQL和PostgreSQL,将具有不同的SQLALCHEMY_DATABASE_URI字符串来配置它们。第17
SQLALCHEMY_TRACK_MODIFICATIONS设置为False,以关闭默认打开SQLAlchemy事件系统。 事件系统生成对事件驱动程序有用的事件,但会增加大量开销。 由于您没有创建事件驱动程序,因此请关闭此功能。第19行通过调用
SQLAlchemy(app)创建db变量。 这通过传递刚刚设置的app配置信息来初始化SQLAlchemy。db变量是导入到build_database.py程序中的变量,以使其可以访问SQLAlchemy和数据库。 它将在server.py程序和people.py模块中达到相同的目的。第23行通过调用
Marshmallow(app)创建ma变量。 这将初始化棉花糖,并允许其对附加到应用程序SQLAlchemy组件进行自省。 这就是为什么棉花糖在SQLAlchemy之后初始化的原因。
型号模块 (Models Module)
The models.py module is created to provide the Person and PersonSchema classes exactly as described in the sections above about modeling and serializing the data. Here is the code for that module:
创建models.py模块的目的是提供与上面有关数据建模和序列化的部分完全相同的Person和PersonSchema类。 这是该模块的代码:
Here’s what the above code is doing:
上面的代码正在执行以下操作:
-
Line 1 imports the
datatimeobject from thedatetimemodule that comes with Python. This gives you a way to create a timestamp in thePersonclass. -
Line 2 imports the
dbandmainstance variables defined in theconfig.pymodule. This gives the module access to SQLAlchemy attributes and methods attached to thedbvariable, and the Marshmallow attributes and methods attached to themavariable. -
Lines 4 – 9 define the
Personclass as discussed in the data modeling section above, but now you know where thedb.Modelthat the class inherits from originates. This gives thePersonclass SQLAlchemy features, like a connection to the database and access to its tables. -
Lines 11 – 14 define the
PersonSchemaclass as was discussed in the data serialzation section above. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
1个线进口
datatime从对象datetime随Python模块。 这为您提供了一种在Person类中创建时间戳的方法。第2行导入
config.py模块中定义的db和ma实例变量。 这使模块可以访问附加到db变量SQLAlchemy属性和方法,以及附加到ma变量的棉花糖属性和方法。第4至9行定义了
Person类,如上面的数据建模部分所述,但是现在您知道了该类继承的db.Model的起源。 这提供了Person类SQLAlchemy功能,例如与数据库的连接和对其表的访问。第11至14行定义了
PersonSchema类,如上面的数据序列化部分所述。 此类从ma.ModelSchema继承,并提供PersonSchema类棉花糖功能,例如自检Person类以帮助序列化/反序列化该类的实例。
创建数据库 (Creating the Database)
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
您已经了解了如何将数据库表映射到SQLAlchemy类。 现在,使用您所学的知识来创建数据库并用数据填充它。 您将构建一个小型实用程序,以使用People数据创建和构建数据库。 这是build_database.py程序:
import import os
os
from from config config import import db
db
from from models models import import Person
Person
# Data to initialize database with
# Data to initialize database with
PEOPLE PEOPLE = = [
[
{{ 'fname''fname' : : 'Doug''Doug' , , 'lname''lname' : : 'Farrell''Farrell' },
},
{{ 'fname''fname' : : 'Kent''Kent' , , 'lname''lname' : : 'Brockman''Brockman' },
},
{{ 'fname''fname' : : 'Bunny''Bunny' ,, 'lname''lname' : : 'Easter''Easter' }
}
]
]
# Delete database file if it exists currently
# Delete database file if it exists currently
if if osos .. pathpath .. existsexists (( 'people.db''people.db' ):
):
osos .. removeremove (( 'people.db''people.db' )
)
# Create the database
# Create the database
dbdb .. create_allcreate_all ()
()
# Iterate over the PEOPLE structure and populate the database
# Iterate over the PEOPLE structure and populate the database
for for person person in in PEOPLEPEOPLE :
:
p p = = PersonPerson (( lnamelname == personperson [[ 'lname''lname' ], ], fnamefname == personperson [[ 'fname''fname' ])
])
dbdb .. sessionsession .. addadd (( pp )
)
dbdb .. sessionsession .. commitcommit ()
()
Here’s what the above code is doing:
上面的代码正在执行以下操作:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 & 14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodule. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclass. After it is instantiated, you call thedb.session.add(p)function. This uses the database connection instancedbto access thesessionobject. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobject. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
第2行从
config.py模块导入db实例。第3行从
models.py模块导入Person类定义。第6-10行创建
PEOPLE数据结构,该结构是包含您的数据的词典的列表。 结构经过精简以节省演示空间。第13和14行执行一些简单的整理工作,以删除
people.db文件(如果存在)。 该文件是维护SQLite数据库的位置。 如果必须重新初始化数据库才能完全启动,这可以确保在构建数据库时从头开始。第17行使用
db.create_all()调用创建数据库。 这将使用从config模块导入的db实例来创建数据库。db实例是我们与数据库的连接。第 20-22行在
PEOPLE列表上进行迭代,并使用其中的字典实例化Person类。 实例化之后,调用db.session.add(p)函数。 这使用数据库连接实例db访问session对象。 会话负责管理记录在会话中的数据库操作。 在这种情况下,您正在执行add(p)方法以将新的Person实例添加到session对象。第24行调用
db.session.commit()来将所有创建的人员对象实际保存到数据库中。
Note: At Line 22, no data has been added to the database. Everything is being saved within the session object. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
注意:在第22行,尚未将任何数据添加到数据库。 一切都保存在session对象中。 仅当您在第24行执行db.session.commit()调用时,会话才会与数据库交互并向数据库提交操作。
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAclchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
在SQLAlchemy中, session是重要的对象。 它充当数据库与程序中创建SQLAclchemy Python对象之间的通道。 该session有助于保持程序中的数据与数据库中存在的相同数据之间的一致性。 它保存所有数据库操作,并通过程序采取的显式和隐式操作相应地更新基础数据库。
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
现在,您可以运行build_database.py程序来创建和初始化新数据库。 您可以使用以下命令在Python虚拟环境处于活动状态时执行此操作:
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py file. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
程序运行时,它将SQLAlchemy日志消息打印到控制台。 这些是在config.py文件SQLALCHEMY_ECHO设置为True的结果。 SQLAlchemy记录的大部分内容是它生成的用于创建和构建people.db SQLite数据库文件的SQL命令。 这是该程序运行时输出的示例:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
CREATE TABLE person (
person_id INTEGER NOT NULL,
person_id INTEGER NOT NULL,
lname VARCHAR,
lname VARCHAR,
fname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
timestamp DATETIME,
PRIMARY KEY (person_id)
PRIMARY KEY (person_id)
)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
使用数据库 (Using the Database)
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
创建数据库后,您可以修改第1部分中的现有代码以使用它。 所有必要的修改都是由于在我们的数据库person_id主键值创建为唯一标识符而不是lname值。
更新REST API (Update the REST API)
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
这些更改都不会引起很大的变化,因此您将从重新定义REST API开始。 以下列表显示了第1部分中的API定义,但已更新为在URL路径中使用person_id变量:
| Action | 行动 | HTTP Verb | HTTP动词 | URL Path | URL路径 | Description | 描述 |
|---|---|---|---|---|---|---|---|
| Create | 创造 | POSTPOST | /api/people/api/people | Defines a unique URL to create a new person | 定义一个唯一的URL来创建一个新的人 | ||
| Read | 读 | GETGET | /api/people/api/people | Defines a unique URL to read a collection of people | 定义一个唯一的URL来读取人的集合 | ||
| Read | 读 | GETGET | /api/people/{person_id}/api/people/{person_id} | person_idperson_id读取特定的人 | |||
| Update | 更新资料 | PUTPUT | /api/people/{person_id}/api/people/{person_id} | person_idperson_id更新现有人员 | |||
| Delete | 删除 | DELETEDELETE | /api/orders/{person_id}/api/orders/{person_id} | person_idperson_id删除现有人员 |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people table. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
URL定义需要lname值时,现在它们需要对people表中的人员记录使用person_id (主键)。 这样,您就可以删除以前的应用中的代码,该代码人为地限制了用户编辑某人的姓氏。
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id, and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
为了实现这些更改,必须编辑第1部分中的swagger.yml文件。 在大多数情况下,任何lname参数值都将更改为person_id ,并将person_id添加到POST和PUT响应中。 您可以检出更新的swagger.yml文件。
更新REST API处理程序 (Update the REST API Handlers)
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname.
在更新swagger.yml文件以支持person_id标识符的使用之后,您还需要更新people.py文件中的处理程序以支持这些更改。 以与更新swagger.yml文件相同的方式,您需要更改people.py文件以使用person_id值而不是lname 。
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people:
这是更新的person.py模块的一部分,其中显示了REST URL端点GET /api/people的处理程序:
Here’s what the above code is doing:
上面的代码正在执行以下操作:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelist. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
第1至9行导入了一些Flask模块以创建REST API响应,以及从
config.py模块导入db实例。 另外,它导入SQLAlchemyPerson和MarshmallowPersonSchema类以访问person数据库表并序列化结果。第11行启动了
read_all()的定义,该定义响应REST API URL端点GET /api/people并返回person数据库表中的所有记录,这些记录按姓氏的升序排列。行19 - 22 SQLAlchemy的告诉查询
person的数据库表中的所有记录,其中排序按升序(默认排序顺序),并返回一个列表PersonPython对象作为变量people。第24行是棉花糖
PersonSchema类定义的价值所在。 您创建一个PersonSchema实例,并向PersonSchema传递参数many=True。 这告诉PersonSchema期望一个interable进行序列化,这就是people变量。第25行使用
PersonSchema实例变量(person_schema),并在people列表中调用其dump()方法。 结果是具有data属性的对象,该对象包含可以转换为JSON的people列表。 它由Connexion返回并转换为JSON,作为对REST API调用的响应。
Note: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
注意:由于Connexion不知道如何将timestamp字段转换为JSON,因此无法直接返回在上面的第24行上创建的people列表变量。 不使用棉花糖处理而返回人员列表会导致冗长的错误回溯,并最终导致以下异常:
TypeError: Object of type Person is not JSON serializable
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person database. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id}:
这是person.py模块的另一部分,它从person数据库中请求一个person 。 在这里, read_one(person_id)函数从REST URL路径接收一个person_id ,指示用户正在寻找特定的人。 这是更新的person.py模块的一部分,其中显示了REST URL端点GET /api/people/{person_id}的处理程序:
Here’s what the above code is doing:
上面的代码正在执行以下操作:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
第10 – 12
person_idSQLAlchemy查询中使用person_id参数,该查询使用查询对象的filter方法来搜索具有与传入的person_id相匹配的person_id属性的person_id。 而不是使用all()查询方法,而是使用one_or_none()方法来获得一个人,或者如果找不到匹配项,则返回None。第15行确定是否找到了一个
person。第17行显示,如果
person不是None(找到匹配的person),则序列化数据会有些不同。 您不会将many=True参数传递给PersonSchema()实例的创建。 相反,您传递many=False因为仅传递了一个对象以进行序列化。在第18行 ,调用
person_schema的dump方法,并返回结果对象的data属性。第23行显示,如果
person为None(未找到匹配的人员),则调用Flaskabort()方法以返回错误。
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person object. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people:
对person.py另一种修改是在数据库中创建一个新人员。 这使您有机会使用棉花糖PersonSchema反序列化随HTTP请求发送的JSON结构,以创建SQLAlchemy Person对象。 这是更新的person.py模块的一部分,其中显示了REST URL端点POST /api/people的处理程序:
def def createcreate (( personperson ):
):
"""
"""
This function creates a new person in the people structure
This function creates a new person in the people structure
based on the passed-in person data
based on the passed-in person data
:param person: person to create in people structure
:param person: person to create in people structure
:return: 201 on success, 406 on person exists
:return: 201 on success, 406 on person exists
"""
"""
fname fname = = personperson .. getget (( 'fname''fname' )
)
lname lname = = personperson .. getget (( 'lname''lname' )
)
existing_person existing_person = = PersonPerson .. query
query
.. filterfilter (( PersonPerson .. fname fname == == fnamefname )
)
.. filterfilter (( PersonPerson .. lname lname == == lnamelname )
)
.. one_or_noneone_or_none ()
()
# Can we insert this person?
# Can we insert this person?
if if existing_person existing_person is is NoneNone :
:
# Create a person instance using the schema and the passed-in person
# Create a person instance using the schema and the passed-in person
schema schema = = PersonSchemaPersonSchema ()
()
new_person new_person = = schemaschema .. loadload (( personperson , , sessionsession == dbdb .. sessionsession )) .. data
data
# Add the person to the database
# Add the person to the database
dbdb .. sessionsession .. addadd (( new_personnew_person )
)
dbdb .. sessionsession .. commitcommit ()
()
# Serialize and return the newly created person in the response
# Serialize and return the newly created person in the response
return return schemaschema .. dumpdump (( new_personnew_person )) .. datadata , , 201
201
# Otherwise, nope, person exists already
# Otherwise, nope, person exists already
elseelse :
:
abortabort (( 409409 , , ff 'Person 'Person {fname}{fname} {lname}{lname} exists already' exists already' )
)
Here’s what the above code is doing:
上面的代码正在执行以下操作:
-
Line 9 & 10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
第9行和第10行根据作为HTTP请求的
POST正文发送的Person数据结构设置fname和lname变量。第12-15行使用SQLAlchemy
Person类在数据库中查询是否存在与传入的person具有相同的fname和lname的person。第18个地址是否
existing_person是None。 (existing_person没有被发现。)第21行创建了一个名为
schema的PersonSchema()实例。第22行使用
schema变量加载person参数变量中包含的数据,并创建一个名为new_person的新SQLAlchemyPerson实例变量。第25
new_person实例添加到db.session。第26
new_person实例提交给数据库,该实例还将为数据库分配一个新的主键值(基于自动递增的整数)和一个基于UTC的时间戳。第33行显示,如果
existing_person不是None(找到匹配的人),则将调用Flaskabort()方法以返回错误。
更新Swagger UI (Update the Swagger UI)
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
完成上述更改后,您的REST API即可正常工作。 您所做的更改也会反映在更新的swagger UI界面中,并且可以以相同的方式进行交互。 以下是在GET /people/{person_id}部分打开的更新的swagger UI的屏幕截图。 UI的这一部分从数据库中获取一个人,如下所示:

As shown in the above screenshot, the path parameter lname has been replaced by person_id, which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
如上面的屏幕快照所示,路径参数lname已由person_id替换,该参数是REST API中人员的主键。 对UI swagger.yml的更改是更改swagger.yml文件以及为支持该更改而进行的代码更改的综合结果。
更新Web应用程序 (Update the Web Application)
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
REST API正在运行,并且CRUD操作正在持久保存到数据库中。 为了可以查看演示Web应用程序,必须更新JavaScript代码。
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id, so the value can be retrieved and used by the JavaScript code.
更新再次与使用person_id而不是lname作为人员数据的主键有关。 另外, person_id作为名为data-person-id HTML数据属性附加到显示表的行上,因此该值可以由JavaScript代码检索和使用。
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
本文重点介绍数据库,并让您的REST API使用它,这就是为什么只有链接到更新的JavaScript源的原因,而对其功能没有太多讨论。
范例程式码 (Example Code)
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
本文提供了所有示例代码。 有一个包含所有文件的代码版本,其中包括第1部分中的build_database.py实用程序和server.py修改后的示例程序。
结论 (Conclusion)
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
恭喜,您已经在本文中介绍了许多新材料,并为军火库添加了有用的工具!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
您已经了解了如何使用SQLAlchemy将Python对象保存到数据库中。 您还学习了如何使用棉花糖对SQLAlchemy对象进行序列化和反序列化,以及如何将它们与JSON REST API一起使用。 您所学到的东西肯定比第1部分中的简单REST API复杂了很多,但是这一步为您提供了两个非常强大的工具,可用于创建更复杂的应用程序。
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
SQLAlchemy和棉花糖本身就是很棒的工具。 一起使用它们可以帮助您创建由数据库支持的自己的Web应用程序。
In Part 3 of this series, you’ll focus on the R part of RDBMS: relationships, which provide even more power when you are using a database.
在本系列的第3部分中,您将专注于RDBMS的R部分:关系,当您使用数据库时,它们提供了更多的功能。















 2472
2472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









