





When writing Python applications, caching is important. Using a cache to avoid recomputing data or accessing a slow database can provide you with a great performance boost.
在编写Python应用程序时,缓存很重要。 使用高速缓存来避免重新计算数据或访问速度较慢的数据库可以为您带来巨大的性能提升。
Python offers built-in possibilities for caching, from a simple dictionary to a more complete data structure such as functools.lru_cache. The latter can cache any item using a Least-Recently Used algorithm to limit the cache size.
Python提供了内置的缓存功能,从简单的字典到更完整的数据结构,例如functools.lru_cache 。 后者可以使用最近最少使用的算法来缓存任何项目,以限制缓存的大小。
Those data structures are, however, by definition local to your Python process. When several copies of your application run across a large platform, using a in-memory data structure disallows sharing the cached content. This can be a problem for large-scale and distributed applications.
但是,根据定义,这些数据结构是Python进程本地的。 当应用程序的多个副本在大型平台上运行时,使用内存中数据结构将无法共享缓存的内容。 对于大规模和分布式应用程序,这可能是个问题。
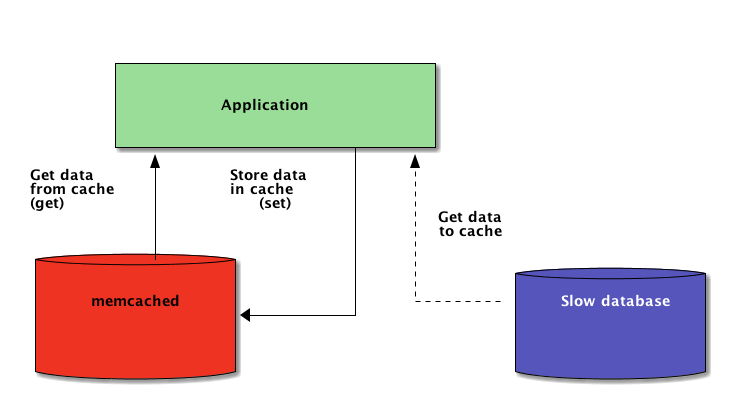
Therefore, when a system is distributed across a network, it also needs a cache that is distributed across a network. Nowadays, there are plenty of network servers that offer caching capability—we already covered how to use Redis for caching with Django.
因此,当系统跨网络分布时,它还需要一个跨网络分布的缓存。 如今,有很多提供缓存功能的网络服务器-我们已经介绍了如何使用Redis进行Django缓存 。
As you’re going to see in this tutorial, memcached is another great option for distributed caching. After a quick introduction to basic memcached usage, you’ll learn about advanced patterns such as “cache and set” and using fallback caches to avoid cold cache performance issues.
正如您将在本教程中看到的那样, memcached是分布式缓存的另一个不错的选择。 快速介绍了基本的内存缓存用法之后,您将了解高级模式,例如“缓存和设置”,以及使用后备缓存来避免缓存性能过低的问题。
安装memcached (Installing memcached)
Memcached is available for many platforms:
Memcached 可用于许多平台 :
- If you run Linux, you can install it using
apt-get install memcachedoryum install memcached. This will install memcached from a pre-built package but you can alse build memcached from source, as explained here. - For macOS, using Homebrew is the simplest option. Just run
brew install memcachedafter you’ve installed the Homebrew package manager. - On Windows, you would have to compile memcached yourself or find pre-compiled binaries.
- 如果运行Linux ,则可以使用
apt-get install memcached或yum install memcached。 这将从预构建的软件包安装memcached,但您也可以从源代码构建memcached, 如此处所述 。 - 对于macOS ,使用Homebrew是最简单的选项。 安装Homebrew软件包管理器后,只需运行
brew install memcached。 - 在Windows上 ,您必须自己编译memcached或找到预编译的二进制文件 。
Once installed, memcached can simply be launched by calling the memcached command:
安装后,只需调用memcached命令即可启动memcached :
$ memcached
$ memcached
Before you can interact with memcached from Python-land you’ll need to install a memcached client library. You’ll see how to do this in the next section, along with some basic cache access operations.
您需要先安装一个memcached客户端库,然后才能从Python-land与memcached进行交互。 您将在下一节中看到如何执行此操作,以及一些基本的缓存访问操作。
使用Python存储和检索缓存的值 (Storing and Retrieving Cached Values Using Python)
If you never used memcached, it is pretty easy to understand. It basically provides a giant network-available dictionary. This dictionary has a few properties that are different from a classical Python dictionnary, mainly:
如果您从未使用过memcached,则非常容易理解。 它基本上提供了一个庞大的网络可用字典。 该词典具有一些与经典Python词典不同的属性,主要是:
- Keys and values have to be bytes
- Keys and values are automatically deleted after an expiration time
- 键和值必须为字节
- 过期时间后,键和值会自动删除
Therefore, the two basic operations for interacting with memcached are set and get. As you might have guessed, they’re used to assign a value to a key or to get a value from a key, respectively.
因此, set和get与memcached交互的两个基本操作。 您可能已经猜到了,它们分别用于为键分配值或从键获取值。
My preferred Python library for interacting with memcached is pymemcache—I recommend using it. You can simply install it using pip:
与memcached交互的首选Python库是pymemcache我建议使用它。 您可以简单地使用pip安装它 :
The following code shows how you can connect to memcached and use it as a network-distributed cache in your Python applications:
以下代码显示了如何连接到memcached并将其用作Python应用程序中的网络分布式缓存:
>>> >>> from from pymemcache.client pymemcache.client import import base
base
# Don't forget to run `memcached' before running this next line:
# Don't forget to run `memcached' before running this next line:
>>> >>> client client = = basebase .. ClientClient (((( 'localhost''localhost' , , 1121111211 ))
))
# Once the client is instantiated, you can access the cache:
# Once the client is instantiated, you can access the cache:
>>> >>> clientclient .. setset (( 'some_key''some_key' , , 'some value''some value' )
)
# Retrieve previously set data again:
# Retrieve previously set data again:
>>> >>> clientclient .. getget (( 'some_key''some_key' )
)
'some value'
'some value'
memcached network protocol is really simple an its implementation extremely fast, which makes it useful to store data that would be otherwise slow to retrieve from the canonical source of data or to compute again:
记忆快取网路通讯协定确实非常简单,而且执行速度非常快,因此非常适合用来储存原本无法从标准资料来源撷取或重新计算的资料:
While straightforward enough, this example allows storing key/value tuples across the network and accessing them through multiple, distributed, running copies of your application. This is simplistic, yet powerful. And it’s a great first step towards optimizing your application.
尽管足够简单,但此示例允许在网络上存储键/值元组,并通过应用程序的多个分布式运行副本访问它们。 这很简单,但功能强大。 这是朝着优化应用程序迈出的重要第一步。
自动过期缓存的数据 (Automatically Expiring Cached Data)
When storing data into memcached, you can set an expiration time—a maximum number of seconds for memcached to keep the key and value around. After that delay, memcached automatically removes the key from its cache.
将数据存储到memcached中时,您可以设置到期时间-memcached保留密钥和值的最大秒数。 延迟之后,memcached会自动从其缓存中删除密钥。
What should you set this cache time to? There is no magic number for this delay, and it will entirely depend on the type of data and application that you are working with. It could be a few seconds, or it might be a few hours.
您应该将此缓存时间设置为什么? 此延迟没有神奇的数字,它将完全取决于您使用的数据类型和应用程序。 可能是几秒钟,也可能是几个小时。
Cache invalidation, which defines when to remove the cache because it is out of sync with the current data, is also something that your application will have to handle. Especially if presenting data that is too old or or stale is to be avoided.
高速缓存失效(它定义了何时删除高速缓存,因为它与当前数据不同步)也是您的应用程序必须处理的事情。 特别是如果要提供的数据过旧或过时,则应避免。
Here again, there is no magical recipe; it depends on the type of application you are building. However, there are several outlying cases that should be handled—which we haven’t yet covered in the above example.
再次,这里没有神奇的配方。 这取决于您正在构建的应用程序类型。 但是,有几个异常的情况应该处理-在上面的示例中我们还没有涉及。
A caching server cannot grow infinitely—memory is a finite resource. Therefore, keys will be flushed out by the caching server as soon as it needs more space to store other things.
缓存服务器不能无限增长-内存是有限的资源。 因此,一旦缓存服务器需要更多空间来存储其他内容,密钥就会被缓存服务器清除。
Some keys might also be expired because they reached their expiration time (also sometimes called the “time-to-live” or TTL.) In those cases the data is lost, and the canonical data source must be queried again.
有些密钥也可能已到期,因为它们已达到其到期时间(有时也称为“生存时间”或TTL)。在这些情况下,数据会丢失,因此必须再次查询规范数据源。
This sounds more complicated than it really is. You can generally work with the following pattern when working with memcached in Python:
这听起来比实际要复杂。 在Python中使用memcached时,通常可以使用以下模式:
Note: Handling missing keys is mandatory because of normal flush-out operations. It is also obligatory to handle the cold cache scenario, i.e. when memcached has just been started. In that case, the cache will be entirely empty and the cache needs to be fully repopulated, one request at a time.
注意:由于正常的清除操作,必须处理丢失的密钥。 还必须处理冷缓存方案,即刚启动memcached时。 在这种情况下,缓存将完全为空,并且需要完全重新填充缓存,一次仅一个请求。
This means you should view any cached data as ephemeral. And you should never expect the cache to contain a value you previously wrote to it.
这意味着您应该以临时方式查看所有缓存的数据。 而且,您永远不要指望缓存包含先前写入它的值。
预热冷缓存 (Warming Up a Cold Cache)
Some of the cold cache scenarios cannot be prevented, for example a memcached crash. But some can, for example migrating to a new memcached server.
无法避免某些冷缓存方案,例如内存缓存崩溃。 但是有些可以,例如,迁移到新的内存缓存服务器。
When it is possible to predict that a cold cache scenario will happen, it is better to avoid it. A cache that needs to be refilled means that all of the sudden, the canonical storage of the cached data will be massively hit by all cache users who lack a cache data (also known as the thundering herd problem.)
当可以预测将发生冷缓存情况时,最好避免这种情况。 需要重新填充的高速缓存意味着,所有缺少高速缓存数据的高速缓存用户都会突然对高速缓存的数据进行规范存储(也称为雷群问题) 。
pymemcache provides a class named FallbackClient that helps in implementing this scenario as demonstrated here:
pymemcache提供了一个名为FallbackClient的类,该类有助于实现此方案,如下所示:
from from pymemcache.client pymemcache.client import import base
base
from from pymemcache pymemcache import import fallback
fallback
def def do_some_querydo_some_query ():
():
# Replace with actual querying code to a database,
# Replace with actual querying code to a database,
# a remote REST API, etc.
# a remote REST API, etc.
return return 42
42
# Set `ignore_exc=True` so it is possible to shut down
# Set `ignore_exc=True` so it is possible to shut down
# the old cache before removing its usage from
# the old cache before removing its usage from
# the program, if ever necessary.
# the program, if ever necessary.
old_cache old_cache = = basebase .. ClientClient (((( 'localhost''localhost' , , 1121111211 ), ), ignore_excignore_exc == TrueTrue )
)
new_cache new_cache = = basebase .. ClientClient (((( 'localhost''localhost' , , 1121211212 ))
))
client client = = fallbackfallback .. FallbackClientFallbackClient (((( new_cachenew_cache , , old_cacheold_cache ))
))
result result = = clientclient .. getget (( 'some_key''some_key' )
)
if if result result is is NoneNone :
:
# The cache is empty, need to get the value
# The cache is empty, need to get the value
# from the canonical source:
# from the canonical source:
result result = = do_some_querydo_some_query ()
()
# Cache the result for next time:
# Cache the result for next time:
clientclient .. setset (( 'some_key''some_key' , , resultresult )
)
printprint (( resultresult )
)
The FallbackClient queries the old cache passed to its constructor, respecting the order. In this case, the new cache server will always be queried first, and in case of a cache miss, the old one will be queried—avoiding a possible return-trip to the primary source of data.
FallbackClient遵守顺序查询传递给其构造函数的旧缓存。 在这种情况下,将始终首先查询新的高速缓存服务器,并且在高速缓存未命中的情况下,将查询旧的高速缓存服务器-避免可能返回主数据源的情况。
If any key is set, it will only be set to the new cache. After some time, the old cache can be decommissioned and the FallbackClient can be replaced directed with the new_cache client.
如果设置了任何键,则只会将其设置为新的缓存。 一段时间后,可以停用旧的缓存,并可以使用new_cache客户端直接替换FallbackClient 。
检查并设置 (Check And Set)
When communicating with a remote cache, the usual concurrency problem comes back: there might be several clients trying to access the same key at the same time. memcached provides a check and set operation, shortened to CAS, which helps to solve this problem.
与远程缓存通信时,通常会出现并发问题:可能有多个客户端试图同时访问同一密钥。 memcached提供了一个检查和设置操作(简称CAS),有助于解决此问题。
The simplest example is an application that wants to count the number of users it has. Each time a visitor connects, a counter is incremented by 1. Using memcached, a simple implementation would be:
最简单的示例是一个应用程序,该应用程序要计算其拥有的用户数。 每次访客连接时,计数器都会增加1。使用memcached,一个简单的实现将是:
However, what happens if two instances of the application try to update this counter at the same time?
但是,如果应用程序的两个实例尝试同时更新此计数器,会发生什么情况?
The first call client.get('visitors') will return the same number of visitors for both of them, let’s say it’s 42. Then both will add 1, compute 43, and set the number of visitors to 43. That number is wrong, and the result should be 44, i.e. 42 + 1 + 1.
第一次调用client.get('visitors')将为他们返回相同数量的访问者,假设它是42。然后两者将加1,计算为43,并将访问者数量设置为43。这个数字是错误的,结果应为44,即42 +1 + 1。
To solve this concurrency issue, the CAS operation of memcached is handy. The following snippet implements a correct solution:
为了解决此并发问题,memcached的CAS操作非常方便。 以下代码段实现了正确的解决方案:
def def on_visiton_visit (( clientclient ):
):
while while TrueTrue :
:
resultresult , , cas cas = = clientclient .. getsgets (( 'visitors''visitors' )
)
if if result result is is NoneNone :
:
result result = = 1
1
elseelse :
:
result result += += 1
1
if if clientclient .. cascas (( 'visitors''visitors' , , resultresult , , cascas ):
):
break
break
The gets method returns the value, just like the get method, but it also returns a CAS value.
就像get方法一样, gets方法返回值,但是它也返回CAS值。
What is in this value is not relevant, but it is used for the next method cas call. This method is equivalent to the set operation, except that it fails if the value has changed since the gets operation. In case of success, the loop is broken. Otherwise, the operation is restarted from the beginning.
此值中的内容无关紧要,但用于下一个cas调用方法。 此方法等效于set操作,但是如果自gets操作以来值已更改,则该方法将失败。 如果成功,则循环中断。 否则,操作将从头开始重新启动。
In the scenario where two instances of the application try to update the counter at the same time, only one succeeds to move the counter from 42 to 43. The second instance gets a False value returned by the client.cas call, and have to retry the loop. It will retrieve 43 as value this time, will increment it to 44, and its cas call will succeed, thus solving our problem.
在应用程序的两个实例尝试同时更新计数器的情况下,只有一个实例成功将计数器从42移动到43。第二个实例获得client.cas调用返回的False值,并且必须重试循环。 这次它将检索43作为值,将其增加到44,并且其cas调用将成功,从而解决了我们的问题。
Incrementing a counter is interesting as an example to explain how CAS works because it is simplistic. However, memcached also provides the incr and decr methods to increment or decrement an integer in a single request, rather than doing multiple gets/cas calls. In real-world applications gets and cas are used for more complex data type or operations
作为一个简单的例子,增加一个计数器很有趣,可以解释CAS的工作原理。 但是,memcached还提供了incr和decr方法来在单个请求中递增或递减整数,而不是执行多次gets / cas调用。 在实际应用中gets和cas用于更复杂的数据类型或操作
Most remote caching server and data store provide such a mechanism to prevent concurrency issues. It is critical to be aware of those cases to make proper use of their features.
大多数远程缓存服务器和数据存储都提供了一种防止并发问题的机制。 了解这些情况以正确使用其功能至关重要。
超越缓存 (Beyond Caching)
The simple techniques illustrated in this article showed you how easy it is to leverage memcached to speed up the performances of your Python application.
本文介绍的简单技术向您展示了利用内存缓存提高Python应用程序性能的容易程度。
Just by using the two basic “set” and “get” operations you can often accelerate data retrieval or avoid recomputing results over and over again. With memcached you can share the cache accross a large number of distributed nodes.
仅通过使用两个基本的“设置”和“获取”操作,您通常可以加快数据检索速度,或者避免一遍又一遍地重新计算结果。 使用memcached,您可以跨大量分布式节点共享缓存。
翻译自: https://www.pybloggers.com/2018/01/python-memcached-efficient-caching-in-distributed-applications/















 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









