





selenium编写脚本
Prerequisites: Have the Selenium Python package working on your machine. See this guide for help.
先决条件:使Selenium Python软件包在您的计算机上工作。 请参阅本指南以获取帮助。
If you ever find yourself doing something repetitive online, there’s probably a Python package that can help you automate the process. One that’s extremely simple to use and flashy to show off to others is called Selenium. Selenium basically allows you to program a browser to do anything by itself that you could do manually with mouse and keyboard. This can often result in huge time savings with relatively simple scripts, and when non-programmers see your browser operating by itself they’ll think you’re a programming jedi.
如果您发现自己在网上重复做某件事,那么可能会有一个Python软件包可以帮助您自动化该过程。 一种非常简单易用且向他人炫耀的东西称为Selenium。 Selenium基本上允许您对浏览器进行编程,使其自身可以执行使用鼠标和键盘可以手动执行的任何操作。 通常,使用相对简单的脚本可以节省大量时间,并且当非程序员看到您的浏览器本身运行时,他们会认为您是编程的绝地。
In this post, we’re going to write an easy Selenium script just to illustrate the basics of the process. Once you get the gist of it, check out the post next week for a more involved programming adventure. And if you don’t already have Selenium up and running take a look at this guide, it’ll take just a minute to set up.
在本文中,我们将编写一个简单的Selenium脚本,以说明该过程的基础。 一旦掌握了要点,请在下周查看该帖子,以获取更多有关编程的知识。 而且,如果您还没有启动和运行Selenium,请参阅此指南 ,只需一分钟即可完成设置。
To demonstrate Selenium’s usage, we’re going to get some urls from the search engine DuckDuckGo. Specifically, we are going to grab the urls on the initial results page of some query. You can imagine this being useful for quickly testing whether the search results for something you query a lot have changed without actually having to look over all the results yourself. (This isn’t actually the package I would recommend for performing that task, but this is just an introductory example before we get deeper into Selenium. And even if Selenium isn’t the most efficient way to do something, it’s often the flashiest, which can have its uses.)
为了演示Selenium的用法,我们将从搜索引擎DuckDuckGo中获取一些URL。 具体来说,我们将在某些查询的初始结果页面上获取这些网址。 您可以想象一下,这对于快速测试您查询的很多内容的搜索结果是否已更改而无需亲自查看所有结果很有用。 (这实际上并不是我为执行该任务而推荐的软件包,但这只是在我们深入了解Selenium之前的介绍性示例。即使Selenium不是做某事的最有效方法,它通常也是最浮华的,有其用途。)
First things first, let’s fire up Selenium.
首先,让我们启动Selenium。
from selenium import webdriver
browser = webdriver.Chrome(executable_path="C:UsersgstantonDownloadschromedriver.exe")
url = "https://www.duckduckgo.com"
browser.get(url)
browser.maximize_window()
Great, so we can navigate to DuckDuckGo. But how do we actually enter something into the search bar and get the results? For that, we will need some way to identify specific elements of the web page. If you know anything about HMTL and CSS, you know that HTML gives a webpage its structure, and CSS gives a webpage its style. We will need to know our way around these things just a little bit to be able to select just the elements we are interested in and perform operations on them. We’ll see this in practice by searching the term “rebellion” and grabbing the resulting urls.
太好了,因此我们可以导航至DuckDuckGo。 但是,我们实际上如何在搜索栏中输入内容并获得结果呢? 为此,我们将需要一些方法来识别网页的特定元素。 如果您对HMTL和CSS有所了解,就知道HTML为其网页提供了结构,而CSS为其网页提供了样式。 我们将只需要稍微了解一下这些方法,就能选择我们感兴趣的元素并对其执行操作。 在实践中,我们将通过搜索“叛乱”一词并抓取相应的网址来了解这一点。
If we want DuckDuckGo to perform a search for us, there are two things we need to use: the search bar, and the search button. We will first enter our search query into the search bar, and then initiate the search by clicking the button. But how do we identify these elements? Well, to examine the underlying structure of the webpage, we will use Chrome’s Developer Tools. And to actually refer to a given element in our code, we have two options: XPath and CSS Selectors. We won’t go into details, so just know that here we’ll be using XPath. CSS Selectors will be covered in a later post.
如果我们希望DuckDuckGo为我们执行搜索,则需要使用两件事:搜索栏和搜索按钮。 我们将首先在搜索栏中输入搜索查询,然后通过单击按钮启动搜索。 但是我们如何识别这些元素? 好了,要检查网页的基础结构,我们将使用Chrome的开发人员工具。 为了实际引用代码中的给定元素,我们有两个选择:XPath和CSS选择器。 我们不会详细介绍,因此只知道在这里我们将使用XPath。 CSS选择器将在以后的文章中介绍。
First, manually navigate to https://www.duckduckgo.com in Chrome. In the upper right corner, click on the menu dropdown (for me, it looks like three stacked gray dots). Go to “More tools”, and then select “Developer tools”. You should now see something like this:
首先,在Chrome中手动导航至https://www.duckduckgo.com。 在右上角,单击菜单下拉菜单(对我来说,它看起来像三个堆叠的灰点)。 转到“更多工具”,然后选择“开发人员工具”。 您现在应该看到类似以下的内容:

The code there on the right in the upper half is the webpage’s HTML. You can click on the gray arrows next to elements to display and hide child elements, and then do the same with the child elements of those child elements, and so on.
上半部分右侧的代码是网页HTML。 您可以单击元素旁边的灰色箭头以显示和隐藏子元素,然后对那些子元素的子元素执行相同的操作,依此类推。
Instead of laboriously looking through all the HTML code for something that looks like a search bar element, the developer tools provide a great tool for instantly selecting any element you want. Notice that when your cursor hovers over the HTML, different elements on the actual page are highlighted. We want to do the reverse of this, selecting page elements and having the corresponding HTML highlighted. To do this, click on the arrow shown here:
开发人员工具无需费力地在所有HTML代码中查找看起来像搜索栏元素的内容,而是提供了一种出色的工具来立即选择所需的任何元素。 请注意,当光标悬停在HTML上时,实际页面上的不同元素将突出显示。 我们想做相反的事情,选择页面元素并突出显示相应HTML。 为此,请单击此处显示的箭头:
Now, when your cursor hovers over page elements, you should see the corresponding HTML elements highlighted on the right. Click on the search bar to select that element. On the right, you should now see an input tag highlighted. Notice that the input tag has an id attribute. We can refer to the search bar using this id like so: “//input[@id=’search_form_input_homepage’]”
现在,当光标悬停在页面元素上时,您应该看到右侧突出显示了相应HTML元素。 单击搜索栏以选择该元素。 在右侧,您现在应该看到一个突出显示的输入标签。 请注意,输入标签具有id属性。 我们可以使用此ID来引用搜索栏,例如:“ // input [@ id ='search_form_input_homepage']”
Doing the same procedure for the search button, the Xpath expression should look like: “//input[@id=’search_button_homepage’]”
对搜索按钮执行相同的过程,Xpath表达式应类似于:“ // input [@ id ='search_button_homepage']”
Now we can finally enter some text into the search bar, and then click the search button to view the results.
现在,我们终于可以在搜索栏中输入一些文本,然后单击搜索按钮以查看结果。
search_bar = browser.find_element_by_xpath("//input[@id='search_form_input_homepage']")
## also try the following line, a shorter, cleaner way when you're sure id's are unique
#search_bar = browser.find_element_by_id('search_form_input_homepage')
search_bar.send_keys("rebellion")
search_button = browser.find_element_by_xpath("//input[@id='search_button_homepage']")
#search_button = browser.find_element_by_id('search_button_homepage')
search_button.click()
This should get you to a page that looks something like this:
这应该使您进入一个看起来像这样的页面:
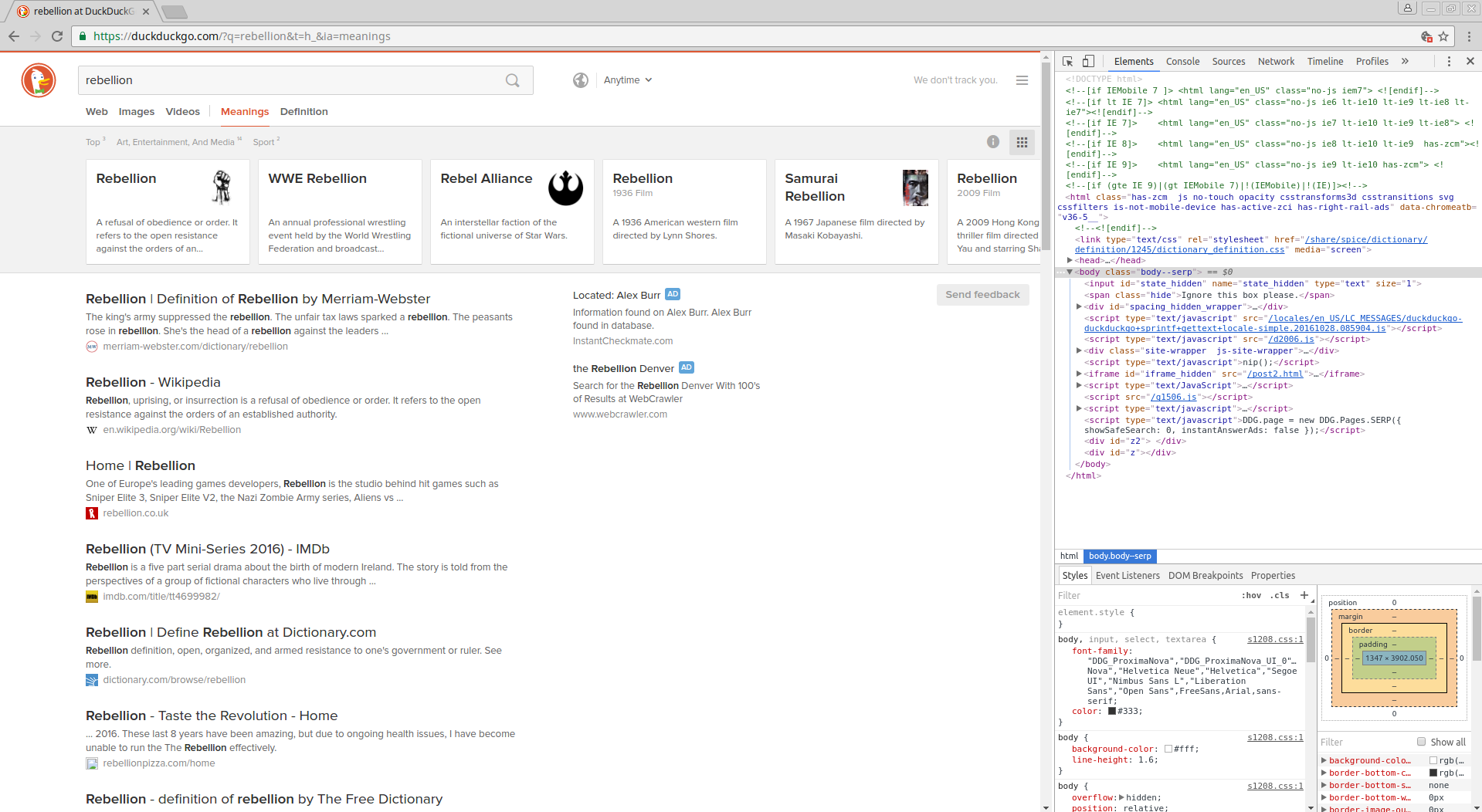
Okay, now we want to get the urls for each of the search results. Using our developer tools like before and selecting the heading of one of the search results, we find that the following XPath might be appropriate: “a[@class=’result__a’]”
好的,现在我们要获取每个搜索结果的网址。 使用像以前一样的开发人员工具并选择一个搜索结果的标题,我们发现以下XPath可能是合适的:“ a [@ class ='result__a']”
Let’s try it out.
让我们尝试一下。
## get every result element
search_results = browser.find_elements_by_xpath("//a[@class='result__a']")
## check that we are grabbing correct elements
print(len(search_results))
for result in search_results:
print(result.text)
Comparing the DuckDuckGo search results page to what we just printed, it looks like we are indeed grabbing the search result elements. Now we just need to extract the urls from them.
将DuckDuckGo搜索结果页面与我们刚刚打印的内容进行比较,似乎我们确实在抓取搜索结果元素。 现在,我们只需要从中提取网址即可。
## make a list of the url's
urls = []
for result in search_results:
urls.append(result.get_attribute("href"))
## print the url's to make sure they look correct
for url in urls:
print(url)
When I ran it, it looked like I picked up the urls for a couple of ads by mistake (they are the ones with the really long urls). If you want a challenge, see if you can figure out an XPath expression that excludes these ad urls. To see one way of doing it, check out the full script below.
当我运行它时,看起来好像是我错误地拿起了几个广告的网址(它们是那些网址很长的广告)。 如果您想挑战,请查看是否可以找出排除这些广告网址的XPath表达式。 要查看执行此操作的一种方法,请查看下面的完整脚本。
Well, there you have it. The basic idea is to use your browser’s developer tools to come up with expressions to select the elements you want. But this is just a taste of what Selenium is capable of. Almost anything you can do yourself with mouse and keyboard can be simulated in Selenium. This makes Selenium a really helpful tool for automating online procedures where lots of clicks and text submissions and general Javascript interactivity are involved. And non-programmers are often extremely impressed by it. Later, we’ll explore how to get the most out of Selenium with some more complex applications. If you have any problems you’d like to see solved with Selenium, feel free to let me know in the comments or via email.
好吧,那里有。 基本思想是使用浏览器的开发人员工具提供表达式来选择所需的元素。 但这只是Selenium所能提供的。 您几乎可以用鼠标和键盘做的任何事情都可以在Selenium中进行模拟。 这使得Selenium成为自动化在线过程的真正有用的工具,其中涉及大量的单击和文本提交以及一般的Javascript交互性。 非编程人员通常对此印象深刻。 稍后,我们将探讨如何通过一些更复杂的应用程序充分利用Selenium。 如果您希望使用Selenium解决任何问题,请随时在评论中或通过电子邮件告知我。
from selenium import webdriver
browser = webdriver.Chrome(executable_path="C:UsersgstantonDownloadschromedriver.exe")
url = "https://www.duckduckgo.com"
browser.get(url)
browser.maximize_window()
search_bar = browser.find_element_by_xpath("//input[@id='search_form_input_homepage']")
search_bar.send_keys("rebellion")
search_button = browser.find_element_by_xpath("//input[@id='search_button_homepage']")
search_button.click()
#search_results = browser.find_elements_by_xpath("//a[@class='result__a']")
search_results = browser.find_elements_by_xpath("//div[@id='links']/div/div/h2/a[@class='result__a']")
print(len(search_results))
for result in search_results:
print(result.text)
urls = []
for result in search_results:
urls.append(result.get_attribute("href"))
for url in urls:
print(url)
browser.quit()
selenium编写脚本















 6982
6982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









