





查找两个字符串中相同字符串
Problem statement:
问题陈述:
Given two strings string1 and string2 find the minimum cost required to make the given two strings identical. We can delete characters from both the strings. The cost of deleting a character from string1 is costX and string2 is costY. The cost of removing any characters from the same string is the same. Like, removing any
给定两个字符串, string1和string2找到使给定两个字符串相同所需的最低成本。 我们可以从两个字符串中删除字符。 从string1删除字符的成本为costX,而string2为costY 。 从同一字符串中删除任何字符的成本是相同的。 喜欢,删除任何
Input:
The first line contains integers costX and costY.
The second line contains the two strings X and Y.
Output:
Print the total cost to make the two strings
equal for each test case in a new line.
Constraints:
1<= length of strings X and Y <=1000
1<= costX, costY <=1000
Explanation of Example:
示例说明:
Input:
1
10 20
"acba" "acdb"
Output:
30
Explanation:
The similar strings would be "acb".
So need to remove one from string1 and one from string2
costing total of 30.
Solution Approach:
解决方法:
The problem can be solved recursively,
该问题可以递归解决,
Let,
让,
N = length of string1
M = length of string1
F(n,m) = minimum cost to make two strings similar
Let us consider, what can be cases that can arrive for F(i,j) where 0 <= i<n && 0 <= j<m
让我们考虑一下,对于F(i,j) ,其中0 <= i <n && 0 <= j <m
Case 1.
情况1。
string1[i]==string2[j] that is indexed characters are similar
索引字符的string1 [i] == string2 [j]相似
In such a case, we don't need any additional cost to make strings similar, the cost will be similar to sub-problem of size i-1, j-1. This can be recursively written as
在这种情况下,我们不需要使字符串相似的任何额外费用,该费用将类似于大小为i-1 , j-1的子问题。 这可以递归写成
F(i,j) = F(i-1,j-1) if string1[i] == string2[j]
Case 2.
情况2
string1[i]!=string2[j] that is indexed characters are not similar.
索引字符的string1 [i]!= string2 [j]不相似。
In such a case we need to invest,
在这种情况下,我们需要投资,
One thing can remove the indexed character from string1 and change to indexed string2 character.
一件事可以从字符串 1中删除索引的字符,然后更改为索引的string2字符。
This can be recursively written as,
可以将其写为
F(i,j) = F(i-1,j) + costX if string1[i] != string2[j]Another way can be to remove the indexed character from string2 and change to string1 indexed character.
另一种方法是从string2删除索引字符,然后更改为string1索引字符。
This can be recursively written as,
可以将其写为
F(i,j) = F(i,j-1) + costY if string1[i] != string2[j]Remove characters from both.
从两者中删除字符。
This can be recursively written as,
可以将其写为
F(i,j) = F(i-1,j-1) + costY + costX if string1[i] != string2[j]Finally, we would take minimum out of this three cases.
So here goes the problem structure,
所以这里是问题的结构,
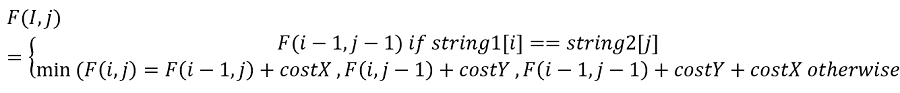
Now the above recursion will create many overlapping subproblems and hence we need two converts it into DP.
现在,上述递归将创建许多重叠的子问题,因此我们需要两次将其转换为DP。
Converting into DP
转换为DP
n = string1 length
m = string2 length
str1 = string1
str2 = string2
1) Declare int dp[n+1][m+1];
2) Base case
for i=0 to n
dp[i][0]=i*costX;
for j=0 to m
dp[0][j]=j*costY;
3) Fill the DP
for i=1 to n
for j=1 to m
//first case when str1[i-1]==str2[j-1]
dp[i][j]=dp[i-1][j-1];
if(str1[i-1]!=str2[j-1])
dp[i][j]+=costX+costY;
dp[i][j]=min(dp[i][j],min(dp[i-1][j]+costX,dp[i][j-1]+costY));
end if
end for
end for
4) return dp[n][m];
C++ Implementation:
C ++实现:
#include <bits/stdc++.h>
using namespace std;
int editdistance(string s1, string s2, int costX, int costY)
{
int n = s1.length();
int m = s2.length();
int dp[n + 1][m + 1];
for (int i = 0; i <= n; i++)
dp[i][0] = i * costX;
for (int j = 0; j <= m; j++)
dp[0][j] = j * costY;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
dp[i][j] = dp[i - 1][j - 1];
if (s1[i - 1] != s2[j - 1]) {
dp[i][j] += costX + costY;
dp[i][j] = min(dp[i][j], min(dp[i - 1][j] + costX, dp[i][j - 1] + costY));
}
}
}
return dp[n][m];
}
int main()
{
int costX, costY;
cout << "Cost of changing/removing character from string1: \n";
cin >> costX;
cout << "Cost of changing/removing character from string2: \n";
cin >> costY;
string s1, s2;
cout << "Input string1\n";
cin >> s1;
cout << "Input string2\n";
cin >> s2;
cout << "Minimum cost to make two string similar: " << editdistance(s1, s2, costX, costY) << endl;
return 0;
}
Output
输出量
Cost of changing/removing character from string1:
2
Cost of changing/removing character from string2:
3
Input string1
includehelp
Input string2
includuggu
Minimum cost to make two string similar: 22
翻译自: https://www.includehelp.com/icp/minimum-cost-to-make-two-strings-identical.aspx
查找两个字符串中相同字符串















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









