





 本文详细介绍如何在C/C++中实现Trie树数据结构,包括插入、搜索和删除单词的功能,以及完整的代码示例。
本文详细介绍如何在C/C++中实现Trie树数据结构,包括插入、搜索和删除单词的功能,以及完整的代码示例。
trie树的数据结构
A Trie data structure acts as a container for a dynamic array. In this article, we shall look at how we can implement a Trie in C/C++.
Trie数据结构充当动态数组的容器。 在本文中,我们将研究如何在C / C ++中实现Trie。
This is based on the tree data structure but does not necessarily store keys. Here, each node only has a value, which is defined based on the position.
这基于树数据结构,但不一定存储键。 在此,每个节点仅具有一个基于位置定义的值。
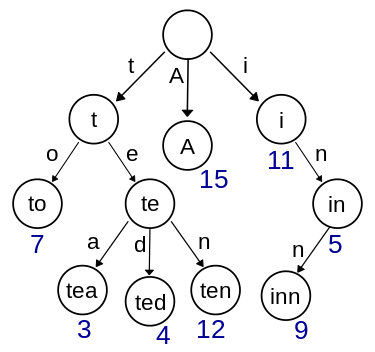
So, the value of each node denotes the prefix, because it is the point from the root node after a series of matches.
因此,每个节点的值表示前缀,因为它是一系列匹配后来自根节点的点。
We call such matches as prefix matches. Therefore, we can use Tries to store words of a dictionary!
我们称这种匹配为前缀匹配 。 因此,我们可以使用Tries来存储字典中的单词!
For example, in the above figure, the root node is empty, so every string matches the root node. Node 7 matches a prefix string of to, while node 3 matches a prefix string of tea.
例如,在上图中,根节点为空,因此每个字符串都与根节点匹配。 节点7匹配到to的前缀字符串,而节点3匹配tea的前缀字符串。
Here, the keys are only stored in the leaf node positions, since prefix matching stops at any leaf node. So any non-leaf node does NOT store the whole string, but only the prefix match character.
此处,关键字仅存储在叶节点位置,因为前缀匹配在任何叶节点处停止。 因此,任何非叶子节点都不会存储整个字符串,而只会存储前缀匹配字符。
Tries are called prefix trees for all these reasons. Now let’s understand how we can implement this data structure, from a programmer’s point of view.
由于所有这些原因,尝试被称为前缀树 。 现在让我们从程序员的角度了解如何实现这种数据结构。
在C / C ++中实现Trie数据结构 (Implementing a Trie Data Structure in C/C++)
Let’s first write down the Trie structure. A Trie Node has notably two components:
让我们首先写下Trie结构。 Trie节点主要包括两个组件:
- It’s children 是孩子
- A marker to indicate a leaf node. 指示叶节点的标记。
But, since we’ll be printing the Trie too, it will be easier if we can store one more attribute in the data part.
但是,由于我们也将打印Trie,因此如果我们可以在数据部分中存储一个以上的属性,则将更加容易。
So let’s define the TrieNode structure. Here, since I will be storing only the lower case alphabets, I will implement this as a 26-ary-tree. So, each node will have pointers to 26 children.
因此,让我们定义TrieNode结构。 在这里,由于我将仅存储小写字母,因此我将其实现为26进制树。 因此,每个节点将具有指向26个子节点的指针。
// The number of children for each node
// We will construct a N-ary tree and make it
// a Trie
// Since we have 26 english letters, we need
// 26 children per node
#define N 26
typedef struct TrieNode TrieNode;
struct TrieNode {
// The Trie Node Structure
// Each node has N children, starting from the root
// and a flag to check if it's a leaf node
char data; // Storing for printing purposes only
TrieNode* children[N];
int is_leaf;
};
Now that we’ve defined our structure, let’s write functions to initialize a TrieNode in memory, and also to free it’s pointer.
现在,我们已经定义了结构,让我们编写函数以初始化内存中的TrieNode并释放其指针。
TrieNode* make_trienode(char data) {
// Allocate memory for a TrieNode
TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode));
for (int i=0; i<N; i++)
node->children[i] = NULL;
node->is_leaf = 0;
node->data = data;
return node;
}
void free_trienode(TrieNode* node) {
// Free the trienode sequence
for(int i=0; i<N; i++) {
if (node->children[i] != NULL) {
free_trienode(node->children[i]);
}
else {
continue;
}
}
free(node);
}
在Trie上插入一个单词 (Inserting a word onto the Trie)
We’ll now write the insert_trie() function, that takes a pointer to the root node (topmost node) and inserts a word to the Trie.
现在,我们将编写insert_trie()函数,该函数需要一个指向根节点(最高节点)的指针,并向Trie中插入一个单词。
The insertion procedure is simple. It iterates through the word character by character and evaluates the relative position.
插入过程很简单。 它逐个字符地遍历单词并评估相对位置。
For example, a character of b will have a position of 1, so will be the second child.
例如,字符b的位置为1,因此第二个孩子也是。
for (int i=0; word[i] != '\0'; i++) {
// Get the relative position in the alphabet list
int idx = (int) word[i] - 'a';
if (temp->children[idx] == NULL) {
// If the corresponding child doesn't exist,
// simply create that child!
temp->children[idx] = make_trienode(word[i]);
}
else {
// Do nothing. The node already exists
}
We will match the prefix character by character, and simply initialize a node if it doesn’t exist.
我们将逐字符匹配前缀,并简单地初始化节点(如果不存在)。
Otherwise, we simply keep moving down the chain, until we have matched all the characters.
否则,我们只是继续沿着链条向下移动,直到匹配所有字符为止。
temp = temp->children[idx];
Finally, we will have inserted all unmatched characters, and we will return back the updated Trie.
最后,我们将插入所有不匹配的字符,然后返回更新的Trie。
TrieNode* insert_trie(TrieNode* root, char* word) {
// Inserts the word onto the Trie
// ASSUMPTION: The word only has lower case characters
TrieNode* temp = root;
for (int i=0; word[i] != '\0'; i++) {
// Get the relative position in the alphabet list
int idx = (int) word[i] - 'a';
if (temp->children[idx] == NULL) {
// If the corresponding child doesn't exist,
// simply create that child!
temp->children[idx] = make_trienode(word[i]);
}
else {
// Do nothing. The node already exists
}
// Go down a level, to the child referenced by idx
// since we have a prefix match
temp = temp->children[idx];
}
// At the end of the word, mark this node as the leaf node
temp->is_leaf = 1;
return root;
}
在Trie中搜索单词 (Search for a word in the Trie)
Now that we’ve implemented insertion onto a Trie, let’s look at searching for a given pattern.
现在,我们已经在Trie中实现了插入,让我们看一下搜索给定的模式。
We’ll try to match the string character by character, using the same prefix matching strategy as above.
我们将尝试使用与上述相同的前缀匹配策略来逐字符匹配字符串。
If we have reached the end of the chain and haven’t yet found a match, that means that the string does not exist, as a complete prefix match is not done.
如果我们已到达链的末尾但尚未找到匹配项,则表示该字符串不存在,因为尚未完成完整的前缀匹配。
For this to return correctly, our pattern must exactly match, and after we finish matching, we must reach a leaf node.
为了使此方法正确返回,我们的模式必须完全匹配,并且在完成匹配之后,我们必须到达叶节点。
int search_trie(TrieNode* root, char* word)
{
// Searches for word in the Trie
TrieNode* temp = root;
for(int i=0; word[i]!='\0'; i++)
{
int position = word[i] - 'a';
if (temp->children[position] == NULL)
return 0;
temp = temp->children[position];
}
if (temp != NULL && temp->is_leaf == 1)
return 1;
return 0;
}
Okay, so we’ve completed the insert and search procedures.
好的,我们已经完成了insert和search过程。
To test it, we’ll first write a print_tree() function, that prints the data of every node.
为了测试它,我们将首先编写一个print_tree()函数,该函数将打印每个节点的数据。
void print_trie(TrieNode* root) {
// Prints the nodes of the trie
if (!root)
return;
TrieNode* temp = root;
printf("%c -> ", temp->data);
for (int i=0; i<N; i++) {
print_trie(temp->children[i]);
}
}
Now that we have done that, let’s just run the complete program until now, to check that it’s working correctly.
现在我们已经完成了,现在让我们运行完整的程序,以检查其是否正常运行。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// The number of children for each node
// We will construct a N-ary tree and make it
// a Trie
// Since we have 26 english letters, we need
// 26 children per node
#define N 26
typedef struct TrieNode TrieNode;
struct TrieNode {
// The Trie Node Structure
// Each node has N children, starting from the root
// and a flag to check if it's a leaf node
char data; // Storing for printing purposes only
TrieNode* children[N];
int is_leaf;
};
TrieNode* make_trienode(char data) {
// Allocate memory for a TrieNode
TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode));
for (int i=0; i<N; i++)
node->children[i] = NULL;
node->is_leaf = 0;
node->data = data;
return node;
}
void free_trienode(TrieNode* node) {
// Free the trienode sequence
for(int i=0; i<N; i++) {
if (node->children[i] != NULL) {
free_trienode(node->children[i]);
}
else {
continue;
}
}
free(node);
}
TrieNode* insert_trie(TrieNode* root, char* word) {
// Inserts the word onto the Trie
// ASSUMPTION: The word only has lower case characters
TrieNode* temp = root;
for (int i=0; word[i] != '\0'; i++) {
// Get the relative position in the alphabet list
int idx = (int) word[i] - 'a';
if (temp->children[idx] == NULL) {
// If the corresponding child doesn't exist,
// simply create that child!
temp->children[idx] = make_trienode(word[i]);
}
else {
// Do nothing. The node already exists
}
// Go down a level, to the child referenced by idx
// since we have a prefix match
temp = temp->children[idx];
}
// At the end of the word, mark this node as the leaf node
temp->is_leaf = 1;
return root;
}
int search_trie(TrieNode* root, char* word)
{
// Searches for word in the Trie
TrieNode* temp = root;
for(int i=0; word[i]!='\0'; i++)
{
int position = word[i] - 'a';
if (temp->children[position] == NULL)
return 0;
temp = temp->children[position];
}
if (temp != NULL && temp->is_leaf == 1)
return 1;
return 0;
}
void print_trie(TrieNode* root) {
// Prints the nodes of the trie
if (!root)
return;
TrieNode* temp = root;
printf("%c -> ", temp->data);
for (int i=0; i<N; i++) {
print_trie(temp->children[i]);
}
}
void print_search(TrieNode* root, char* word) {
printf("Searching for %s: ", word);
if (search_trie(root, word) == 0)
printf("Not Found\n");
else
printf("Found!\n");
}
int main() {
// Driver program for the Trie Data Structure Operations
TrieNode* root = make_trienode('\0');
root = insert_trie(root, "hello");
root = insert_trie(root, "hi");
root = insert_trie(root, "teabag");
root = insert_trie(root, "teacan");
print_search(root, "tea");
print_search(root, "teabag");
print_search(root, "teacan");
print_search(root, "hi");
print_search(root, "hey");
print_search(root, "hello");
print_trie(root);
free_trienode(root);
return 0;
}
After compiling with your gcc compiler, you’ll get the following output.
使用gcc编译器进行编译后,您将获得以下输出。
Searching for tea: Not Found
Searching for teabag: Found!
Searching for teacan: Found!
Searching for hi: Found!
Searching for hey: Not Found
Searching for hello: Found!
-> h -> e -> l -> l -> o -> i -> t -> e -> a -> b -> a -> g -> c -> a -> n ->
While it may be obvious how it’s being printed, the clue is to look at the print_tree() method. Since that prints the current node, and then all of its children, the order does indicate that.
虽然很明显是如何打印的,但线索是看一下print_tree()方法。 由于该命令将打印当前节点,然后打印其所有子节点,因此该顺序的确表明了这一点。
So, now let’s implement the delete method!
因此,现在让我们实现delete方法!
从Trie删除单词 (Delete a word from a Trie)
This one is actually a bit more tricky than the other two methods.
这个方法实际上比其他两种方法更棘手。
There doesn’t exist any format algorithm of sorts since there is no explicit way in which we store the keys and values.
由于没有明确的方式存储键和值,因此不存在任何种类的格式算法。
But, for the purpose of this article, I’ll handle deletions only if the word to be deleted is a leaf node. That is, it must be prefix matched all the way, until a leaf node.
但是,出于本文的目的,仅当要删除的单词是叶节点时,我才会处理删除。 也就是说,必须一直对其进行前缀匹配,直到叶子节点为止。
So let’s start. Our signature for the delete function will be:
因此,让我们开始吧。 我们对delete函数的签名为:
TrieNode* delete_trie(TrieNode* root, char* word);
As mentioned earlier, this will delete only if the prefix match is done until a leaf node. So let’s write another function is_leaf_node(), that does this for us.
如前所述,仅当前缀匹配完成直到叶节点时,此操作才会删除。 因此,让我们编写另一个函数is_leaf_node() ,为我们做到这一点。
int is_leaf_node(TrieNode* root, char* word) {
// Checks if the prefix match of word and root
// is a leaf node
TrieNode* temp = root;
for (int i=0; word[i]; i++) {
int position = (int) word[i] - 'a';
if (temp->children[position]) {
temp = temp->children[position];
}
}
return temp->is_leaf;
}
Okay, so with that completed, let’s look at the draft of our delete_trie() method.
好的,完成后,让我们看一下delete_trie()方法的草稿。
TrieNode* delete_trie(TrieNode* root, char* word) {
// Will try to delete the word sequence from the Trie only it
// ends up in a leaf node
if (!root)
return NULL;
if (!word || word[0] == '\0')
return root;
// If the node corresponding to the match is not a leaf node,
// we stop
if (!is_leaf_node(root, word)) {
return root;
}
// TODO
}
After this check is done, we now know that our word will end in a leaf node.
完成此检查后,我们现在知道单词将以叶节点结尾。
But there is another situation to handle. What if there exists another word that has a partial prefix match of the current string?
但是还有另一种情况要处理。 如果存在另一个单词,该单词的当前前缀部分匹配,该怎么办?
For example, in the below Trie, the words tea and ted have a partial common match until te.
例如,在下面的Trie中,单词tea和ted具有部分共同的匹配项,直到te为止。
So, if this happens, we cannot simply delete the whole sequence from t to a, as then, both the chains will be deleted, as they are linked!
因此,如果发生这种情况,我们不能简单地从t到a删除整个序列,因为那样,两个链都将被删除,因为它们被链接了!
Therefore, we need to find the deepest point until which such matches occur. Only after that, can we delete the remaining chain.
因此,我们需要找到最深的匹配点。 只有在那之后,我们才能删除剩余的链。
This involves finding the longest prefix string, so let’s write another function.
这涉及查找最长的前缀字符串,因此让我们编写另一个函数。
char* longest_prefix(TrieNode* root, char* word);
This will return the longest match in the Trie, which is not the current word (word). The below code explains every intermediate step in the comments.
这将返回Trie中最长的匹配项,而不是当前单词( word )。 下面的代码解释了注释中的每个中间步骤。
char* find_longest_prefix(TrieNode* root, char* word) {
// Finds the longest common prefix substring of word
// in the Trie
if (!word || word[0] == '\0')
return NULL;
// Length of the longest prefix
int len = strlen(word);
// We initially set the longest prefix as the word itself,
// and try to back-track from the deepest position to
// a point of divergence, if it exists
char* longest_prefix = (char*) calloc (len + 1, sizeof(char));
for (int i=0; word[i] != '\0'; i++)
longest_prefix[i] = word[i];
longest_prefix[len] = '\0';
// If there is no branching from the root, this
// means that we're matching the original string!
// This is not what we want!
int branch_idx = check_divergence(root, longest_prefix) - 1;
if (branch_idx >= 0) {
// There is branching, We must update the position
// to the longest match and update the longest prefix
// by the branch index length
longest_prefix[branch_idx] = '\0';
longest_prefix = (char*) realloc (longest_prefix, (branch_idx + 1) * sizeof(char));
}
return longest_prefix;
}
There is another twist here! Since we try to find the longest match, the algorithm will actually greedily match the original string itself! This is not what we want.
这里还有另外一个转折! 由于我们尝试找到最长的匹配项,因此该算法实际上会贪婪地匹配原始字符串本身! 这不是我们想要的。
We want the longest match that is NOT the input string. So, we must have a check with another method check_divergence().
我们希望最长的匹配不是输入字符串。 因此,我们必须使用另一种方法check_divergence()进行检查。
This will check if there is any branching from the root to the current position, and return the length of the best match which is NOT the input.
这将检查从根到当前位置是否有任何分支,并返回不是输入的最佳匹配的长度。
If we are in the bad chain, that corresponds to the original string, then there will be no branching from the point! So this is a good way for us to avoid that nasty point, using check_divergence().
如果我们处于与原始字符串相对应的坏链中,那么从该点开始就不会出现分支! 因此,这是使用check_divergence()避免该讨厌点的好方法。
int check_divergence(TrieNode* root, char* word) {
// Checks if there is branching at the last character of word
//and returns the largest position in the word where branching occurs
TrieNode* temp = root;
int len = strlen(word);
if (len == 0)
return 0;
// We will return the largest index where branching occurs
int last_index = 0;
for (int i=0; i < len; i++) {
int position = word[i] - 'a';
if (temp->children[position]) {
// If a child exists at that position
// we will check if there exists any other child
// so that branching occurs
for (int j=0; j<N; j++) {
if (j != position && temp->children[j]) {
// We've found another child! This is a branch.
// Update the branch position
last_index = i + 1;
break;
}
}
// Go to the next child in the sequence
temp = temp->children[position];
}
}
return last_index;
}
Finally, we’ve ensured that we don’t just delete the whole chain blindly. So now let’s move on with our delete method.
最后,我们确保我们不只是盲目地删除整个链。 现在,让我们继续delete方法。
TrieNode* delete_trie(TrieNode* root, char* word) {
// Will try to delete the word sequence from the Trie only it
// ends up in a leaf node
if (!root)
return NULL;
if (!word || word[0] == '\0')
return root;
// If the node corresponding to the match is not a leaf node,
// we stop
if (!is_leaf_node(root, word)) {
return root;
}
TrieNode* temp = root;
// Find the longest prefix string that is not the current word
char* longest_prefix = find_longest_prefix(root, word);
//printf("Longest Prefix = %s\n", longest_prefix);
if (longest_prefix[0] == '\0') {
free(longest_prefix);
return root;
}
// Keep track of position in the Trie
int i;
for (i=0; longest_prefix[i] != '\0'; i++) {
int position = (int) longest_prefix[i] - 'a';
if (temp->children[position] != NULL) {
// Keep moving to the deepest node in the common prefix
temp = temp->children[position];
}
else {
// There is no such node. Simply return.
free(longest_prefix);
return root;
}
}
// Now, we have reached the deepest common node between
// the two strings. We need to delete the sequence
// corresponding to word
int len = strlen(word);
for (; i < len; i++) {
int position = (int) word[i] - 'a';
if (temp->children[position]) {
// Delete the remaining sequence
TrieNode* rm_node = temp->children[position];
temp->children[position] = NULL;
free_trienode(rm_node);
}
}
free(longest_prefix);
return root;
}
The above code simply finds the deepest node for the prefix match and deletes the remaining sequence matching word from the Trie, since that is independent of any other match.
上面的代码只是找到前缀匹配的最深节点,并从Trie中删除其余的序列匹配词,因为它与任何其他匹配均无关。
上述程序的时间复杂度 (Time Complexity for the above Procedures)
The Time Complexity of the procedures are mentioned below.
该过程的时间复杂度在下面提到。
| Procedure | Time Complexity of Implementation |
search_trie() | O(n) -> n is the length of the input string |
insert_trie() | O(n) -> n is the length of the input string |
delete_trie() | O(C*n) -> C is the number of alphabets, n is the length of the input word |
| 程序 | 实施的时间复杂度 |
search_trie() | O(n) -> n是输入字符串的长度 |
insert_trie() | O(n) -> n是输入字符串的长度 |
delete_trie() | O(C * n) -> C是字母的数目, n是输入单词的长度 |
For almost all cases, the number of alphabets is a constant, so the complexity of delete_trie() is also reduced to O(n).
在几乎所有情况下,字母的数量都是一个常数,因此delete_trie()的复杂度也降低为O(n) 。
Trie数据结构的完整C / C ++程序 (The Complete C/C++ program for the Trie Data Structure)
At long last, we’ve (hopefully), completed our delete_trie() function. Let’s check if what we’ve written was correct, using our driver program.
最后,我们(希望)完成了delete_trie()函数。 让我们使用驱动程序检查我们编写的内容是否正确。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// The number of children for each node
// We will construct a N-ary tree and make it
// a Trie
// Since we have 26 english letters, we need
// 26 children per node
#define N 26
typedef struct TrieNode TrieNode;
struct TrieNode {
// The Trie Node Structure
// Each node has N children, starting from the root
// and a flag to check if it's a leaf node
char data; // Storing for printing purposes only
TrieNode* children[N];
int is_leaf;
};
TrieNode* make_trienode(char data) {
// Allocate memory for a TrieNode
TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode));
for (int i=0; i<N; i++)
node->children[i] = NULL;
node->is_leaf = 0;
node->data = data;
return node;
}
void free_trienode(TrieNode* node) {
// Free the trienode sequence
for(int i=0; i<N; i++) {
if (node->children[i] != NULL) {
free_trienode(node->children[i]);
}
else {
continue;
}
}
free(node);
}
TrieNode* insert_trie(TrieNode* root, char* word) {
// Inserts the word onto the Trie
// ASSUMPTION: The word only has lower case characters
TrieNode* temp = root;
for (int i=0; word[i] != '\0'; i++) {
// Get the relative position in the alphabet list
int idx = (int) word[i] - 'a';
if (temp->children[idx] == NULL) {
// If the corresponding child doesn't exist,
// simply create that child!
temp->children[idx] = make_trienode(word[i]);
}
else {
// Do nothing. The node already exists
}
// Go down a level, to the child referenced by idx
// since we have a prefix match
temp = temp->children[idx];
}
// At the end of the word, mark this node as the leaf node
temp->is_leaf = 1;
return root;
}
int search_trie(TrieNode* root, char* word)
{
// Searches for word in the Trie
TrieNode* temp = root;
for(int i=0; word[i]!='\0'; i++)
{
int position = word[i] - 'a';
if (temp->children[position] == NULL)
return 0;
temp = temp->children[position];
}
if (temp != NULL && temp->is_leaf == 1)
return 1;
return 0;
}
int check_divergence(TrieNode* root, char* word) {
// Checks if there is branching at the last character of word
// and returns the largest position in the word where branching occurs
TrieNode* temp = root;
int len = strlen(word);
if (len == 0)
return 0;
// We will return the largest index where branching occurs
int last_index = 0;
for (int i=0; i < len; i++) {
int position = word[i] - 'a';
if (temp->children[position]) {
// If a child exists at that position
// we will check if there exists any other child
// so that branching occurs
for (int j=0; j<N; j++) {
if (j != position && temp->children[j]) {
// We've found another child! This is a branch.
// Update the branch position
last_index = i + 1;
break;
}
}
// Go to the next child in the sequence
temp = temp->children[position];
}
}
return last_index;
}
char* find_longest_prefix(TrieNode* root, char* word) {
// Finds the longest common prefix substring of word
// in the Trie
if (!word || word[0] == '\0')
return NULL;
// Length of the longest prefix
int len = strlen(word);
// We initially set the longest prefix as the word itself,
// and try to back-tracking from the deepst position to
// a point of divergence, if it exists
char* longest_prefix = (char*) calloc (len + 1, sizeof(char));
for (int i=0; word[i] != '\0'; i++)
longest_prefix[i] = word[i];
longest_prefix[len] = '\0';
// If there is no branching from the root, this
// means that we're matching the original string!
// This is not what we want!
int branch_idx = check_divergence(root, longest_prefix) - 1;
if (branch_idx >= 0) {
// There is branching, We must update the position
// to the longest match and update the longest prefix
// by the branch index length
longest_prefix[branch_idx] = '\0';
longest_prefix = (char*) realloc (longest_prefix, (branch_idx + 1) * sizeof(char));
}
return longest_prefix;
}
int is_leaf_node(TrieNode* root, char* word) {
// Checks if the prefix match of word and root
// is a leaf node
TrieNode* temp = root;
for (int i=0; word[i]; i++) {
int position = (int) word[i] - 'a';
if (temp->children[position]) {
temp = temp->children[position];
}
}
return temp->is_leaf;
}
TrieNode* delete_trie(TrieNode* root, char* word) {
// Will try to delete the word sequence from the Trie only it
// ends up in a leaf node
if (!root)
return NULL;
if (!word || word[0] == '\0')
return root;
// If the node corresponding to the match is not a leaf node,
// we stop
if (!is_leaf_node(root, word)) {
return root;
}
TrieNode* temp = root;
// Find the longest prefix string that is not the current word
char* longest_prefix = find_longest_prefix(root, word);
//printf("Longest Prefix = %s\n", longest_prefix);
if (longest_prefix[0] == '\0') {
free(longest_prefix);
return root;
}
// Keep track of position in the Trie
int i;
for (i=0; longest_prefix[i] != '\0'; i++) {
int position = (int) longest_prefix[i] - 'a';
if (temp->children[position] != NULL) {
// Keep moving to the deepest node in the common prefix
temp = temp->children[position];
}
else {
// There is no such node. Simply return.
free(longest_prefix);
return root;
}
}
// Now, we have reached the deepest common node between
// the two strings. We need to delete the sequence
// corresponding to word
int len = strlen(word);
for (; i < len; i++) {
int position = (int) word[i] - 'a';
if (temp->children[position]) {
// Delete the remaining sequence
TrieNode* rm_node = temp->children[position];
temp->children[position] = NULL;
free_trienode(rm_node);
}
}
free(longest_prefix);
return root;
}
void print_trie(TrieNode* root) {
// Prints the nodes of the trie
if (!root)
return;
TrieNode* temp = root;
printf("%c -> ", temp->data);
for (int i=0; i<N; i++) {
print_trie(temp->children[i]);
}
}
void print_search(TrieNode* root, char* word) {
printf("Searching for %s: ", word);
if (search_trie(root, word) == 0)
printf("Not Found\n");
else
printf("Found!\n");
}
int main() {
// Driver program for the Trie Data Structure Operations
TrieNode* root = make_trienode('\0');
root = insert_trie(root, "hello");
root = insert_trie(root, "hi");
root = insert_trie(root, "teabag");
root = insert_trie(root, "teacan");
print_search(root, "tea");
print_search(root, "teabag");
print_search(root, "teacan");
print_search(root, "hi");
print_search(root, "hey");
print_search(root, "hello");
print_trie(root);
printf("\n");
root = delete_trie(root, "hello");
printf("After deleting 'hello'...\n");
print_trie(root);
printf("\n");
root = delete_trie(root, "teacan");
printf("After deleting 'teacan'...\n");
print_trie(root);
printf("\n");
free_trienode(root);
return 0;
}
Output
输出量
Searching for tea: Not Found
Searching for teabag: Found!
Searching for teacan: Found!
Searching for hi: Found!
Searching for hey: Not Found
Searching for hello: Found!
-> h -> e -> l -> l -> o -> i -> t -> e -> a -> b -> a -> g -> c -> a -> n ->
After deleting 'hello'...
-> h -> i -> t -> e -> a -> b -> a -> g -> c -> a -> n ->
After deleting 'teacan'...
-> h -> i -> t -> e -> a -> b -> a -> g ->
With that, we’ve come to the end of our Trie Data Structure implementation in C/C++. I know that this is a long read, but hopefully you’ve understood how you can apply these methods correctly!
这样,我们就结束了C / C ++中Trie数据结构实现的过程。 我知道这是一本长篇小说,但希望您已经了解如何正确应用这些方法!
下载代码 (Download the Code)
You can find the complete code in a Github Gist that I’ve uploaded. It may not be the most efficient code, but I’ve tried my best to ensure that it’s working correctly.
您可以在我上传的Github Gist中找到完整的代码。 它可能不是最有效的代码,但我已尽力确保它正常工作。
If you have any questions or suggestions, do raise them in the comment section below!
如果您有任何疑问或建议,请在下面的评论部分提出!
参考资料 (References)
推荐读物: (Recommended Reads:)
If you’re interested in similar topics, you can refer to the Data Structures and Algorithms section, which includes topics like Hash Tables and Graph Theory.
如果您对类似的主题感兴趣,可以参考“ 数据结构和算法”部分,其中包括诸如哈希表和图论之类的主题。
翻译自: https://www.journaldev.com/36507/trie-data-structure-in-c-plus-plus
trie树的数据结构


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









