





正则表达式python
We live in an information age where large volumes of data abound and the ability to extract meaningful information from data is a key differentiator for success. Fields such as analytics, data mining and data science are devoted to the study of data. In this article we will look at an essential, simple and powerful tool in the data scientist’s toolbox – the regular expression or regex for short. We will learn about regex and how to use them in python scripts to process textual data.
我们生活在一个信息时代,那里有大量数据,并且能够从数据中提取有意义的信息是成功的关键因素。 分析,数据挖掘和数据科学等领域专门用于数据研究。 在本文中,我们将研究数据科学家工具箱中的一个基本,简单而功能强大的工具- 正则表达式或简称regex 。 我们将学习正则表达式以及如何在python脚本中使用它们来处理文本数据。
Text is one of the basic forms of data and humans use text for communicating and expressing themselves such as in web pages, blog posts, documents, twitter/ RSS feeds, etc. This is where Regular Expressions are handy and powerful. Be it filtering data from web pages, data analytics or text mining – Regular expressions are the preferred tool to accomplish these tasks. Regular expressions make text processing tasks, like (NLP) simpler, thereby reducing efforts, time and errors which are bound to occur while writing manual scripts.
文本是数据的基本形式之一,人们使用文本进行交流和表达自己,例如在网页,博客文章,文档,Twitter / RSS提要等中。正则表达式非常方便而强大。 无论是从网页过滤数据,数据分析还是文本挖掘–正则表达式都是完成这些任务的首选工具。 正则表达式使诸如( NLP )之类的文本处理任务更加简单,从而减少了编写手动脚本时必然发生的工作量,时间和错误。
In this article, we will understand what are regular expressions and how they can be used in Python. Next, we will walk through usage and applications of commonly used regular expressions.
在本文中,我们将了解什么是正则表达式以及如何在Python中使用它们。 接下来,我们将逐步介绍常用正则表达式的用法和应用。
By the end of the article, you will learn how you can leverage the power of regular expressions to automate your day-to-day text processing tasks.
在本文结尾,您将学习如何利用正则表达式的功能来自动化日常文本处理任务。
什么是正则表达式? (What is a Regular Expression?)
A regular expression (RE or regex) is a sequence of characters which describes textual patterns. Using regular expressions we can match input data for certain patterns (aka searching), extract matching strings (filtering, splitting) as well as replace occurrences of patterns with substitutions, all with a minimum amount of code.
正则表达式 (RE或regex)是描述文本模式的一系列字符。 使用正则表达式,我们可以为某些模式匹配输入数据(又名搜索),提取匹配字符串(过滤,拆分),并用替换替换出现的模式,所有这些都使用最少的代码。
Most programming languages have built-in support for defining and operating with regular expressions. Perl, Python & Java are some notable programming languages with first-class support for regular expressions. The standard library functions in such programming languages provide highly-performant, robust and (almost) bug-free implementations of the regular expression operations (searching, filtering, etc.) that makes it easy to rapidly produce high-quality applications that process text efficiently.
大多数编程语言都内置了对正则表达式的定义和操作的支持。 Perl,Python和Java是一些著名的编程语言,具有对正则表达式的一流支持。 此类编程语言中的标准库函数提供了正则表达式操作(搜索,过滤等)的高性能,健壮且(几乎)无错误的实现,从而可以轻松快速地生成可有效处理文本的高质量应用程序。
Python正则表达式入门 ( Getting started with Python Regular expressions )
Python provides a built-in module called re to deal with regular expressions. To import Python’s re package, use:
Python提供了一个称为re的内置模块来处理正则表达式。 要导入Python的re软件包,请使用:
import reThe re package provides set of methods to perform common operations using regular expressions.
re软件包提供了一组使用正则表达式执行常见操作的方法。
在字符串中搜索模式 ( Searching for Patterns in a String )
One of the most common tasks in text processing is to search if a string contains a certain pattern or not. For instance, you may want to perform an operation on the string, based on the condition that the string contains a number. Or, you may want to validate a password by ensuring it contains numbers and special characters. The`match` operation of RE provides this capability.
文本处理中最常见的任务之一是搜索字符串是否包含某种模式。 例如,您可能希望基于字符串包含数字的条件对字符串执行操作。 或者,您可能想要通过确保密码包含数字和特殊字符来验证密码。 RE的“ match”操作提供了此功能。
Python offers two primitive operations based on regular expressions: re.match() function checks for a pattern match at the beginning of the string, whereas re.search() checks for a pattern match anywhere in the string. Let’s have a look at how these functions can be used:
Python提供了两个基于正则表达式的原始操作: re.match()函数在字符串的开头检查模式匹配,而re.search()在字符串的任何地方检查模式匹配。 让我们看看如何使用这些功能:
re.match()函数 ( The re.match() function )
The re.match() function checks if the RE matches at the beginning of the string. For example, initialise a variable “text” with some text, as follows:
re.match()函数检查RE是否在字符串的开头匹配。 例如,用一些文本初始化变量“ text”,如下所示:
text = ['Charles Babbage is regarded as the father of computing.', 'Regular expressions are used in search engines.']Let’s write a simple regular expression that matches a string of any length containing anything as long as it starts with the letter C:
让我们编写一个简单的正则表达式,它匹配一个包含以字母C开头的任何长度的字符串:
regex = r"C.*"For now, let’s not worry about how the declaration above is interpreted and assume that the above statement creates a variable called regex that matches strings starting with C.
现在,让我们不必担心上面的声明如何解释,并假设上面的语句创建了一个名为regex的变量,该变量与以C开头的字符串匹配。
We can test if the strings in text match the regex as shown below:
我们可以测试文本中的字符串是否与正则表达式匹配,如下所示:
for line in text:
ans = re.match(regex, line)
type(ans)
if(ans):
print(ans.group(0))Go ahead and run that code. Below is a screenshot of a python session with this code running.
继续并运行该代码。 下面是运行此代码的python会话的屏幕截图。
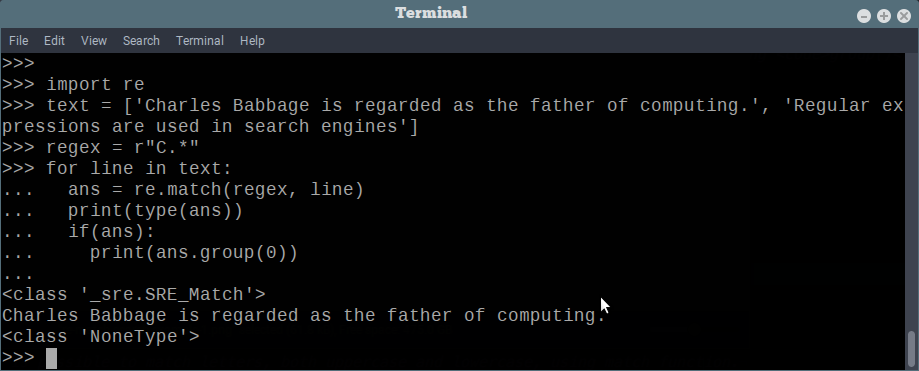
Regex Match Search Example 1
正则表达式匹配搜索示例1
The first string matches this regex, since it stats with the character “C”, whereas the second string starts with character “R” and does not match the regex. The `match` function returns _sre.SRE_Match object if a match is found, else it returns None.
第一个字符串与此正则表达式匹配,因为它以字符“ C”表示状态,而第二个字符串以字符“ R”开头且与正则表达式不匹配。 如果找到匹配项,match函数将返回_sre.SRE_Match对象,否则返回None 。
In python, regular expressions are specified as raw string literals. A raw string literal has a prefix r and is immediately followed by the string literal in quotes. Unlike normal string literals, Python does not interpret special characters like '\' inside raw string literals. This is important and necessary since the special characters have a different meaning in regular expression syntax than what they do in standard python string literals. More on this later.
在python中,正则表达式被指定为原始字符串文字。 原始字符串文字的前缀为r ,后跟引号的字符串文字。 与普通字符串文字不同,Python不会在原始字符串文字中解释特殊字符,例如'\' 。 这是非常重要且必要的,因为特殊字符在正则表达式语法中的含义与在标准python字符串文字中的含义不同。 稍后再详细介绍。
Once a match is found, we can get the part of the string that matched the pattern using group() method on the returned match object. We can get the entire matching string by passing 0 as the argument.
找到匹配项后,我们可以在返回的match对象上使用group()方法获取与模式匹配的字符串部分。 我们可以通过传递0作为参数来获取整个匹配字符串。
ans.group(0)Sample Output:
样本输出:
Charles Babbage is regarded as the father of computing.正则表达式的构建块 ( Building blocks of regular expressions )
In this section we will look at the elements that make up a regex and how regexes are built. A regex contains groups and each group contains various specifiers such as character classes, repeaters, identifiers etc. Specifiers are strings that match particular types of pattern and have their own format for describing the desired pattern. Let’s look at the common specifiers:
在本节中,我们将研究组成正则表达式的元素以及正则表达式的构建方式。 正则表达式包含组,每个组包含各种说明符,例如字符类,中继器,标识符等。说明符是与特定类型的模式匹配的字符串,并且具有用于描述所需模式的自己的格式。 让我们看一下常见的说明符:
身份标识 ( Identifiers )
An identifier matches a subset of characters e.g., lowercase alphabets, numeric digits, whitespace etc.,. Regex provides a list of handy identifiers to match different subsets. Some frequently used identifiers are:
标识符与字符的子集匹配,例如小写字母,数字,空格等。 正则表达式提供了方便的标识符列表,以匹配不同的子集。 一些常用的标识符是:
- \d = matches digits (numeric characters) in a string \ d =匹配字符串中的数字(数字字符)
- \D = matches anything but a digit \ D =匹配除数字以外的任何内容
- \s = matches white space (e.g., space, TAB, etc.,.) \ s =匹配空格(例如空格,TAB等)。
- \S = matches anything but a space \ S =匹配空格以外的任何内容
- \w = matches letters/ alphabets & numbers \ w =匹配字母/字母和数字
- \W = matches anything but a letter \ W =匹配字母以外的任何内容
- \b = matches any character that can separate words (e.g., space, hyphen, colon etc.,.) \ b =匹配可以分隔单词的任何字符(例如,空格,连字符,冒号等)。
- . = matches any character, except for a new line. Hence, it is called the wildcard operator. Thus, “.*” will match any character, any nuber of times. 。 =匹配任何字符,除了换行符。 因此,它被称为通配符。 因此,“。*”将与任何字符,任何时间匹配。
Note: In the above regex example and all others in this section we omit the leading
rfrom the regex string literal for sake of readability. Any literal given here should be declared as a raw string literal when used in python code.注意:在上面的正则表达式示例和本节中的所有其他示例中,为了便于阅读,我们省略了正则表达式字符串文字中的前导
r。 在python代码中使用时,此处给出的所有文字都应声明为原始字符串文字。
中继器 ( Repeaters )
A repeater is used to specify one or more occurrences of a group. Below are some commonly used repeaters.
中继器用于指定一个或多个组的出现。 以下是一些常用的中继器。
The `*` symbol
*符号
The asterisk operator indicates 0 or more repetitions of the preceding element, as many as possible. ‘ab*” will match ‘a’, ‘ab’, ‘abb’ or ‘a’ followed by any number of b’s.
星号运算符表示前一个元素的0个或多个重复,并尽可能多。 “ ab *”将匹配“ a”,“ ab”,“ abb”或“ a”,后跟任意多个b。
The `+` symbol
“ +”符号
The plus operator indicates 1 or more repetitions of the preceding element, as many as possible. ‘ab+’ will match ‘a’, ‘ab’, ‘abb’ or ‘a’ followed by at least 1 occurrence of ‘b’; it will not match ‘a’.
加号运算符表示前一个元素的1个或多个重复,并尽可能多。 “ ab +”将匹配“ a”,“ ab”,“ abb”或“ a”,然后至少出现1个“ b”; 它不会匹配“ a”。
The `?` symbol
“?”符号
This symbol specifies the preceding element occurs at most once, i.e., it may or may not be present in the string to be matched. For example, ‘ab+’ will match ‘a’ and ‘ab’.
该符号指定前面的元素最多出现一次,即,它可能存在或可能不存在于要匹配的字符串中。 例如,“ ab +”将匹配“ a”和“ ab”。
The `{n}` curly braces
{n}花括号
The curly braces specify the preceding element to be matched exactly n times. b{4} will match exactly four ‘b’ characters, but not more/less than 4.
花括号将前一个元素指定为精确匹配n次。 b {4}将精确匹配四个'b'字符,但不大于/小于4。
The symbols *,+,? and {} are called repeaters, as they specify the number of times the preceding element is repeated.
符号*,+ 、? 和{}被称为重复器,因为它们指定重复前一个元素的次数。
其他说明符 ( Miscellaneous specifiers )
The `[]` square braces
`[]`大括号
The square braces match any single character enclosed within it. For example [aeiou] will match any of the lowercase vowels while [a-z] will match any character from a-z(case-sensitive). This is also called a character class.
方括号匹配其中包含的任何单个字符。 例如,[aeiou]将匹配任何小写的元音,而[az]将匹配az(区分大小写)中的任何字符。 这也称为字符类。
The `|`
`|`
The vertical bar is used to separate alternatives. photo|foto matches either “photo” or “foto”.
竖线用于分隔其他选项。 photo | foto与“ photo”或“ foto”匹配。
The `^` symbol
`^`符号
The caret symbol specifies the position for the match, at the start of the string, except when used inside square braces. For example, “^I” will match a string starting with “I” but will not match strings that don’t have “I” at the beginning. This is essentially same as the functionality provided by the re.match function vs re.search function.
插入符号在字符串的开头指定匹配的位置,但在方括号内使用时除外。 例如,“ ^ I”将匹配以“ I”开头的字符串,但将不匹配以“ I”开头的字符串。 这基本上与re.match函数和re.search函数提供的功能相同。
When used as the first character inside a character class it inverts the matching character set for the character class. For example, “[^aeiou]” will match any character other than a, e, i, o or u.
当用作字符类中的第一个字符时,它会反转字符类的匹配字符集。 例如,“ [^ aeiou]”将匹配a,e,i,o或u以外的任何字符。
The `$` symbol
`$`符号
The dollar symbol specifies the position for a match, at end of the string.
美元符号指定字符串末尾的匹配位置。
The `()` paranthesis
`()`括号
The parenthesis is used for grouping different symbols of RE, to act as a single block. ([a-z]\d+) will match patterns containing a-z, followed by any digit. The whole match is treated as a group and can be extracted from the string. More on this later.
括号用于对RE的不同符号进行分组,以充当单个块。 ([az] \ d +)将匹配包含az的模式,后跟任意数字。 整个匹配项被视为一个组,可以从字符串中提取出来。 稍后再详细介绍。
Python正则表达式的典型用例 ( Typical use-cases for Python Regular Expressions )
Now, we have discussed the building blocks of writing RE. Let’s do some hands-on regex writing.
现在,我们讨论了编写RE的基础。 让我们做一些动手的正则表达式编写。
重新访问re.match()函数 ( The re.match() function revisited)
It is possible to match letters, both uppercase and lowercase, using match function.
使用匹配功能可以匹配大写和小写字母。
ans = re.match(r"[a-zA-Z]+", str)
print(ans.group(0))The above regex matches the first word found in the string. The `+` operator specifies that the string should have at least one character.
上面的正则表达式与字符串中找到的第一个单词匹配。 “ +”运算符指定字符串应至少包含一个字符。
Sample Output:
样本输出:
TheAs you see, the regex matches the first word found in the string. After the word “The”, there is a space, which is not treated as a letter. So, the matching is stopped and the function returns only the first match found. Let’s say, a string starts with a number. In this case, the match() function returns a null value, though the string has letters following the number. For example,
如您所见,正则表达式与字符串中找到的第一个单词匹配。 “ The”一词之后有一个空格,该空格不视为字母。 因此,匹配停止,该函数仅返回找到的第一个匹配项。 假设字符串以数字开头。 在这种情况下,尽管字符串在数字后有字母,但match()函数将返回空值。 例如,
str = "1837 was the year when Charles Babbage invented the Analytical Engine"
ans = re.match(r"[a-zA-Z]+", str)
type(ans)The above regex returns null, as the match function returns only the first element in the string. Though the string contains alphabets, it is preceded by a number. Therefore, match() function returns null. This problem can be avoided using the search() function.
上面的正则表达式返回null,因为match函数仅返回字符串中的第一个元素。 尽管该字符串包含字母,但它前面还有一个数字。 因此, match()函数返回null。 使用search()函数可以避免此问题。
re.search()函数 ( The re.search() function )
The search() function matches a specified pattern in a string, similar to match() function. The difference is, the search() function matches a pattern globally, unlike matching only the first element of a string. Let’s try the same example using search() function.
search()函数匹配字符串中的指定模式,类似于match()函数。 不同之处在于, search()函数全局匹配模式,这与仅匹配字符串的第一个元素不同。 让我们使用search()函数尝试相同的示例。
str = "1837 was the year when Charles Babbage invented the Analytical Engine"
ans = re.search(r"[a-zA-Z]+", str)
type(ans)Sample Output:
样本输出:
wasThis is because the search() function returns a match, though the string does not start with an alphabet, yet found elsewhere in the string.
这是因为search()函数返回一个匹配项,尽管该字符串不是以字母开头,而是在字符串的其他位置找到了。
从头到尾匹配字符串 ( Matching strings from start and from end )
We can use regex to find if a string starts with a particular pattern using caret operator ^. Similarly, $ a dollar operator is used to match if a string ends with a given pattern. Let’s write a regex to understand this:
我们可以使用正则表达式使用尖号运算符^查找字符串是否以特定模式开头。 同样,如果字符串以给定的模式结尾,则使用$ Dollars运算符进行匹配。 让我们写一个正则表达式来了解这一点:
str = "1937 was the year when Charles Babbage invented the Analytical Engine"
if re.search(r"^1837", str):
print("The string starts with a number")
else:
print("The string does not start with a number")
type(ans)Sample Output:
样本输出:
The string starts with a number re.sub()函数 ( The re.sub() function )
We have explored using regex to find a pattern in a string. Let’s move ahead to find how to substitute a text in a string. For this, we use the sub() function. The sub() function searches for a particular pattern in a string and replaces it with a new pattern.
我们已经探索过使用正则表达式在字符串中查找模式。 让我们继续寻找如何在字符串中替换文本。 为此,我们使用sub()函数。 sub()函数在字符串中搜索特定的模式,并将其替换为新的模式。
str = "Analytical Engine was invented in the year 1837"
ans = re.sub(r"Analytical Engine", "Electric Telegraph", str)
print(ans)As you see, the first parameter of the sub() function is the regex that searches for a pattern to substitute. The second parameter contains the new text you wish to substitute for the old one. The third parameter is the string on which the “sub” operation is performed.
如您所见, sub()函数的第一个参数是正则表达式,该正则表达式搜索要替换的模式。 第二个参数包含您希望替换旧文本的新文本。 第三个参数是在其上执行“ sub”操作的字符串。
Sample Output:
样本输出:
Electric Telegraph was invented in the year 1837用标识符编写正则表达式 ( Writing Regexes with identifiers )
Let’s understand using regex containing identifiers, with an example. To remove digits in a string, we use the below regex:
让我们通过一个示例来了解如何使用包含标识符的正则表达式。 要删除字符串中的数字,我们使用以下正则表达式:
str = "Charles Babbage invented the Analytical Engine in the year 1937"
ans = re.sub(r"\d", "", str)
print(ans)The above script locates for digits in a string using the identifier “\d” and replaces it with an empty string.
上面的脚本使用标识符“ \ d”查找字符串中的数字,并将其替换为空字符串。
Sample Output:
样本输出:
Charles Babbage invented the Analytical Engine in the year分割字符串 ( Splitting a string )
The re package provides the split() function to split strings. This function returns a list of split tokens. for example, the following “split” function splits string of words, when a comma is found:
re包提供split()函数来拆分字符串。 此函数返回拆分令牌的列表。 例如,下面的“ split”函数在发现逗号时会拆分字符串:
str = "Charles Babbage was considered to be the father of computing, after his invention of the Analytical Engine, in 1837"
ans = re.split(r"\,", str)
print(ans)Sample Output:
样本输出:
['Charles Babbage was considered to be the father of computing', 'after his invention of the Analytical Engine', 'in 1837'] re.findall()函数 ( The re.findall() function )
The findall() function returns a list that contains all the matched utterances in a string.
findall()函数返回一个列表,该列表包含字符串中所有匹配的发音。
Let’s write a script to find domain type from a list of email id’s implementing the findall() function:
让我们编写一个脚本,以从实现findall()函数的电子邮件ID列表中查找域类型:
result=re.findall(r'@\w+.\w+','joe.sam@gmail.com, reema@yahoo.in, demo.user@samskitchen.com)
print resultSample Output:
样本输出:
['@gmail.com', '@yahoo.in', '@samskitchen.com']结论 ( Conclusion )
In this article, we understood what regular expressions are and how they can be built from their fundamental building blocks. We also looked at the re module in Python and its methods for leveraging regular expressions. Regular expressions are a simple yet powerful tool in text processing and we hope you enjoyed learning about them as much as we did building this article. Where could you use regex in your work/ hobby projects? Leave a comment below.
在本文中,我们了解了什么是正则表达式以及如何从其基本构建块构建它们。 我们还研究了Python中的re模块及其利用正则表达式的方法。 正则表达式是文本处理中一个简单但功能强大的工具,我们希望您像我们撰写本文一样乐于学习它们。 您在工作/业余项目中可以在哪里使用正则表达式? 在下面发表评论。
翻译自: https://www.journaldev.com/26904/python-regular-expressions
正则表达式python

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









