






lucene搜索引擎
无可估量的高贵的Apache软件基金会(Apache Software Foundation)产生了许多巨大的产品(Ant,CouchDB,Hadoop,JMeter,Maven,OpenOffice,Subversion等),这些产品有助于构建我们的数字世界。 Lucene也许是一个鲜为人知的瑰宝,它“……提供基于Java的索引和搜索技术,以及拼写检查,命中突出显示和高级分析/令牌化功能。” 尽管从标题上避开了,Lucene还是许多Apache(和第三方)项目中一个安静但不可或缺的组成部分。


让我们看一下这个出色且成功的产品的基础结构。
在开始之前,请先进行以下四个警告。
- 作为一种语法结构分析,此评论对程序语义或无论多么精致的交付用户体验都不太在意。
- 结构本身值得进行调查,因为它支配着变更潜在成本的可预测性。 结构不良的系统表现出过度的互连性,其中的连锁React会严重影响更改成本估算的准确性。 结构良好的系统维护和升级的费用不一定便宜,但是通常它们带来的麻烦更少。
- 该分析将包装结构描绘为斯皮克林图,其中圆圈表示包装,直线表示从上方绘制的包装到下方绘制的包装的依赖性,而曲线线表示从下方绘制的包装到上方绘制的包装的依赖性。 。 程序包的颜色表示它所参与的可传递程序包依赖关系的相对数量:越红,可传递程序依赖关系越多。
- 没有图可以证明结构价值或成本。 高级分析仅在提示问题的答案被埋在代码的地质层之下时才进行。
因此,为了生意……
崛起 …
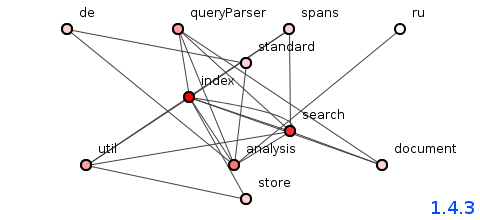

图1:Lucene 1.4.3版的软件包结构。
图1显示了仍然归档的Lucene的最早版本之一,版本1.4.3。 回想一下,简单的结构测试表明随机选择了一个程序包,并询问:“如果该程序包发生更改,它最有可能影响其他哪些程序包?”
以索引为例。 很明显的QueryParser和跨度都依赖于它,因此可以通过任何变化指标受到影响,而曲线显示,搜索就靠它呢。 这种容易的依赖关系识别是整个图形的特征,使其结构合理。
布拉沃(Bravo),露西娜(Lucene),您的开局很好。
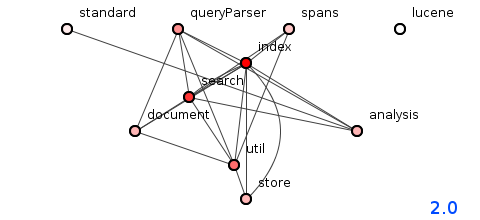

图2:Lucene 2.0版的程序包结构。
图2显示了2.0版(请注意,我们不会研究每个发行版,而是沿着整个发行路径均匀地划分里程碑),并且互连的简单性仍在继续。 尽管方法的数量从1.4.3的1,637版上升到2.0的2,085版,但程序包的数量却从11个减少到10个。这促使有效耦合效率从41%降至37%略有下降,但是好的设计原则显然可以精通此系统。
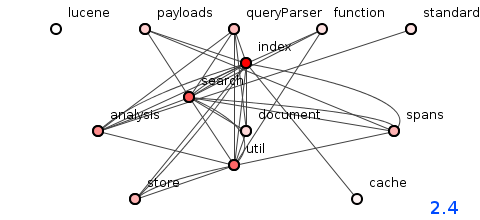

图3:Lucene 2.4版的软件包结构。
上面的图3中呈现的2.4版本-尽管远没有明显的不良结构-却显示出苦恼的最初迹象。
的确,许多包裹与邻居之间有着明显的联系。 但是现在有些没有。 特别是搜索和索引似乎已经陷入彼此的事务中。
但是,这种结构的轻微退化掩盖了幕后发生的动荡变化。 在2.0版本有2,085个方法的地方,2.4版本的大小增加了一倍多,达到4,176个方法。 在2.0版只有9,767个传递依赖项的情况下,2.4版在繁重的48,370个传递依赖项之下下垂。 正如我们将看到的那样,一些结构性的裂缝已经在方法级别上深层拉开,以触发依赖关系的五倍增长,这是Lucene的程序员从未发现或密封的裂缝,并且困扰着以后的修订。
不仅依赖关系的数量急剧增加,而且程序的深度(其传递依赖关系的平均长度)也增加了,从2.0版的7跳到了2.4版的8.6,不仅在涟漪效应可能会扑朔迷离,但将这些音轨扩展到更远的地方以分流虚假的冲击。
尽管如此,这种结构仍然没有解决任何问题。 专注于设计可以恢复早期版本所具有的简单性。
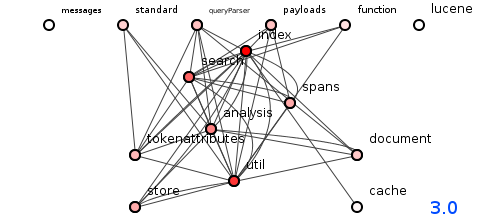

图4:Lucene 3.0版的程序包结构。
las,版本3.0(如上图4所示)似乎继续以很小的幅度下降。 再次,图4并没有呈现出一种不可挽回的结构:我们可以通过拆开包装来了解它们之间如何相互连接。 但是,这项任务变得更加艰巨。
分析和跨度都被搜索和索引所吸引。 预测更改这四个软件包中任何一个的影响现在似乎需要对所有其他软件包进行自动调查。
导致互连性增加的原因是此修订版增加了800种方法。 即使传递依存关系的数量已下降到46,917,但平均长度却又增加了,这次是9.3。
系统的结构是否超出了希望? 一点也不:许多软件包与同事之间都享有明确的依赖关系。 然而,即将到来的是版本3.5和大量传递依赖,尽管这些依赖并不是立即致命的,但证明对所有药物都具有抗药性。
还有秋天……
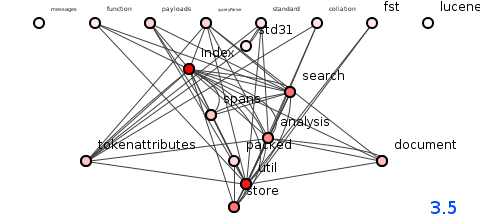

图5:Lucene 3.5版的程序包结构。
令人欣慰的是,如上图5所示,版本3.5引入了额外的三个软件包(总数达到18个),试图分发和分离系统的功能。 慷慨的还可能会提出,尽管程序包的结构已从上一修订版明显地再次衰减了,但这种衰减仍然在一定程度上是局部的:坏男孩分析,跨度,搜索和索引继续使Lucene镇表现良好的其他人群感到恐惧。
但是慷慨到此为止。
因为尽管仅增加了1800种方法,但修订版3.5的传递依赖项数量猛增至109,357,这些依赖项的平均长度达到11种方法,这是整个发展过程中令人遗憾的最大值。 考虑到结构复杂性的显着提高,我们想知道包装设计的效果如何—实际上,这种协调性是短暂的,因为应变最终破坏了下一个修订里程碑中的所有控制外观。
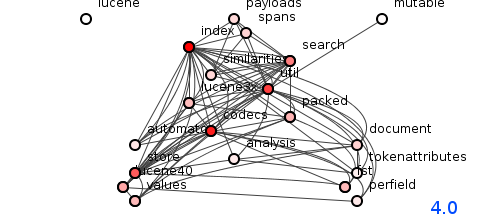

图5:Lucene 4.0版的程序包结构。
如图5所示,修订版4.0在先前的修订版中增加了1600种方法,使总数增加到8,474,传递依赖项的数量相对适度地增加到116,211,但是从图中可以看出,发生了一些可怕的事情。
先前版本的Swift发展的互连性突然系统化,导致该结构内陷到可怕的缠结的依赖球中,这使得代码影响预测极为不可靠。
确实,此修订版增加了另外两个软件包–将潜在的耦合效率提高到43%–并将(轻微)传递依赖项长度减少到10.4,但是控制如此大量的传递依赖项的巨大努力只是破坏了系统。 它不会恢复。
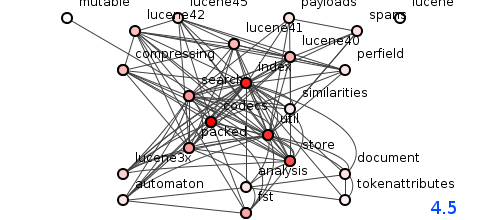

图6:Lucene 4.5版的软件包结构。
在图6所示的修订版4.5中,一些英勇的行动将传递依赖项的数量减少到106,242,同时仍将方法的数量增加到9,562,也许某些软件包设法使自己远离系统上狂躁的黑洞旋转。核心。 但是工作太少了,太迟了。
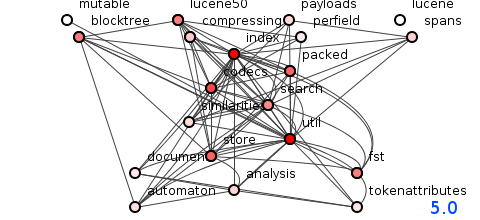

图7:Lucene 5.0版的程序包结构。
如图7所示,修订版5.0尝试通过删除200种方法来驯服野兽,但这奇怪地导致可传递依赖项的数量再次增加到113,556。
版本5.0看起来和版本4.5一样糟糕吗? 好吧,也许不是。 看起来有点干净。 但是,我们不应该让这种情况使我们对图7所示的巨大混乱视而不见:该系统痛苦不堪。 预测更改任何这些中央软件包的成本已经变得很困难。
为什么?
要了解破坏系统初始结构完整性的原因,我们必须检查3.5版。 再次,这看起来可能不是最糟糕的结构,但是此修订版预示了最终导致破产的变化。
主要的变化不仅是规模上的变化:更大的系统不一定会陷入不良的结构。 修订版3.5将方法数量增加了35%,但修订版2.4将方法数量增加了100%以上,而没有破坏整个组织。
相反,罪魁祸首是传递依赖项的数量及其在系统中的分布。
修订版3.5中引入的新的传递依赖项数量惊人,从46,917增至109,357。 这使依赖方法比达到了动脉硬化16。
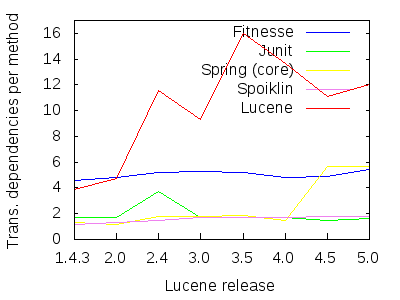

图8:比较Lucene的方法传递依存关系比率。
依赖于方法的比率已经太高了。 但是,在以前的版本中,这些可传递依赖项在很大程度上只限于一个或两个程序包。 在版本3.0中,所有传递方法依赖项的95%终止于其原始包或仅一个依赖项的包中。 这给了希望,在某种意义上,更改可能会将自己限制在接近原点的区域,而很少有更改会溢出到整个系统中,并且无法进行成本预测。
但是,修订版3.5看到该数字骤降至75%。 这意味着所有修订版3.5的传递依赖项中有25%溢出到三个或更多程序包中。 将这两个因素结合在一起,就可以发现,有33,000多个依赖项需要等待远远超出其起源的弹射变化。 最重要的是,这注定了产品会进一步结构衰减。
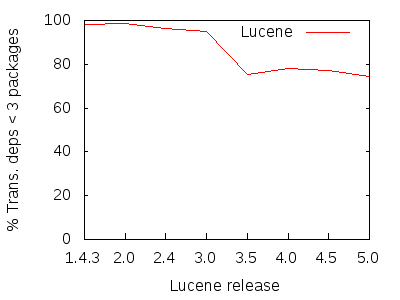

图9:Lucene传递依赖项的百分比,少于3个包。
然后,这结束了对Lucene包级别结构的检查。 我们是否应该深入研究套餐级别? 我们是否应该梳理各个软件包以检查各种类别的星座? 不可以。根据Blighttown的推论,如果包装级别的结构不好,我们不希望在下面找到钻石。 所以我们不会。
最终成绩
让我们尝试对Lucene的结构进行客观评分(其最终修订版本此处为5.0)。
我们将使用四个因素的平均值。 第一个度量Lucene尝试限制可能形成的依赖关系数量。 第二和第三次尝试捕获传递依赖项的长度,第四次尝试捕获传递依赖项的数量。 当然,大型系统总会比小型系统具有更多的依赖关系,因此我们不能仅仅因为系统A的依赖关系少就说系统A的结构比系统B更完善。 取而代之的是,我们必须通过标准化大小或使测量在某种意义上具有自参考性,得出可以公平比较的测量。
首先,我们将测量其绝对理想效率:这将分析结构的潜在耦合,并基本询问封装了多少种方法而不使用其他方法,因此可以想象创建了多少依赖项。 如果将每种方法都放在一个类中,则每种方法对彼此都是可见的,因此效率为0%。 随着将更多方法设为私有方法并置于单独的包私有类中,该方法的价值也随之增加,从而使方法之间的封装越来越多。
Lucene得分为44%,表明它至少已尝试封装其功能,但是可以做更多的事情。
其次,我们将以一种允许程序之间公平比较的形式来衡量Lucene的传递依赖项的长度。 为此,我们将使用CDF图来显示Lucene的传递方法依赖关系占其最长传递依赖关系的百分比。
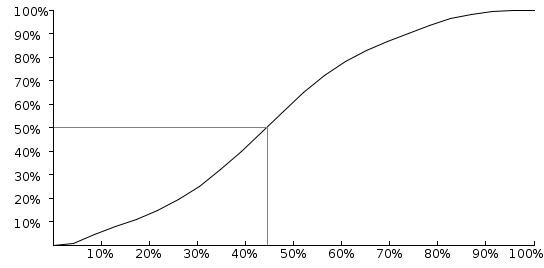

图10:Lucene的传递依赖CDF。
在上面的图10中,我们看到Lucene的传递依存关系的一半短于其最长的传递依存关系的长度的45%。 这不好。 系统对纹波效应的抵抗力取决于其大部分依赖关系是否短暂。 例如, JUnit的传递依赖的一半仅占其最长依赖关系长度的30%。
当我们需要一个具有改进结构的数字时,我们将使用100减去该数字,因此Lucene将获得100 – 45 = 55的分数,该值应接近70。
我们将讨论的第三个因素是:跨越两个或更少程序包的方法所占的百分比,这个数字为75.5%。 听起来不错,但是使用现代结构技术,几乎没有理由将该值小于90%。
最后,我们需要一个因素来衡量系统中有多少依赖项,因为依赖项的数量越少越好。 为了规范化大小,我们想测量每个方法的方法相关性数量。 不幸的是,在这里我们必须估算出行业最低的分数。 一些研究表明,25似乎是一个合适的数字:如果系统每个方法包含25个以上的依赖项,则该系统的结构是如此糟糕,以至于所有其他所有其他指标都失去了重要性。
前面我们看到,Lucene每种方法有12个巨大的依赖关系。 因此我们将使用的数字为25-12 = 13,以25的百分比表示,得出52%。 如图8所示,其他系统的每种方法的依赖关系低至6,这个指标的收益率超过70%。
这使得Lucene的最终得分为226.5 / 400分,即57%。 根据牢固的结构原理,现代程序的分数很容易超过80%,所以这是一个很差的分数,表示,这是一个糟糕的结构。 Lucene在本系列到目前为止所分析的系统的排行榜中排名倒数第二。
| 因子 | 得分 |
| 绝对势偶效率% | 44 |
| 100 –(最长依赖关系长度的一半,即一半系统短于该长度) | 55 |
| 方法传递相关性百分比,范围不超过2个软件包 | 75.5 |
| ((25-(每个方法的传递方法依赖项数)/ 25),以25的百分比表示 | 52 |
| 平均 | 57% |
表1:Lucene 5.0的结构评估。
概要
| 程序 | 结构得分 |
| Spoiklin Soice | 84% |
| JUnit的 | 67% |
| Struts | 67% |
| FitNesse | 62% |
| 弹簧 | 60% |
| Lucene | 57% |
| 蚂蚁 | 24% |
表2:Lucene在排行榜上的位置。
可以做的更好。
翻译自: https://www.javacodegeeks.com/2015/05/the-structure-of-apache-lucene.html
lucene搜索引擎















 2183
2183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









