









一、获取网易云歌曲的url
1、进入网页版网易云音乐,选择一首歌曲,进去评论区
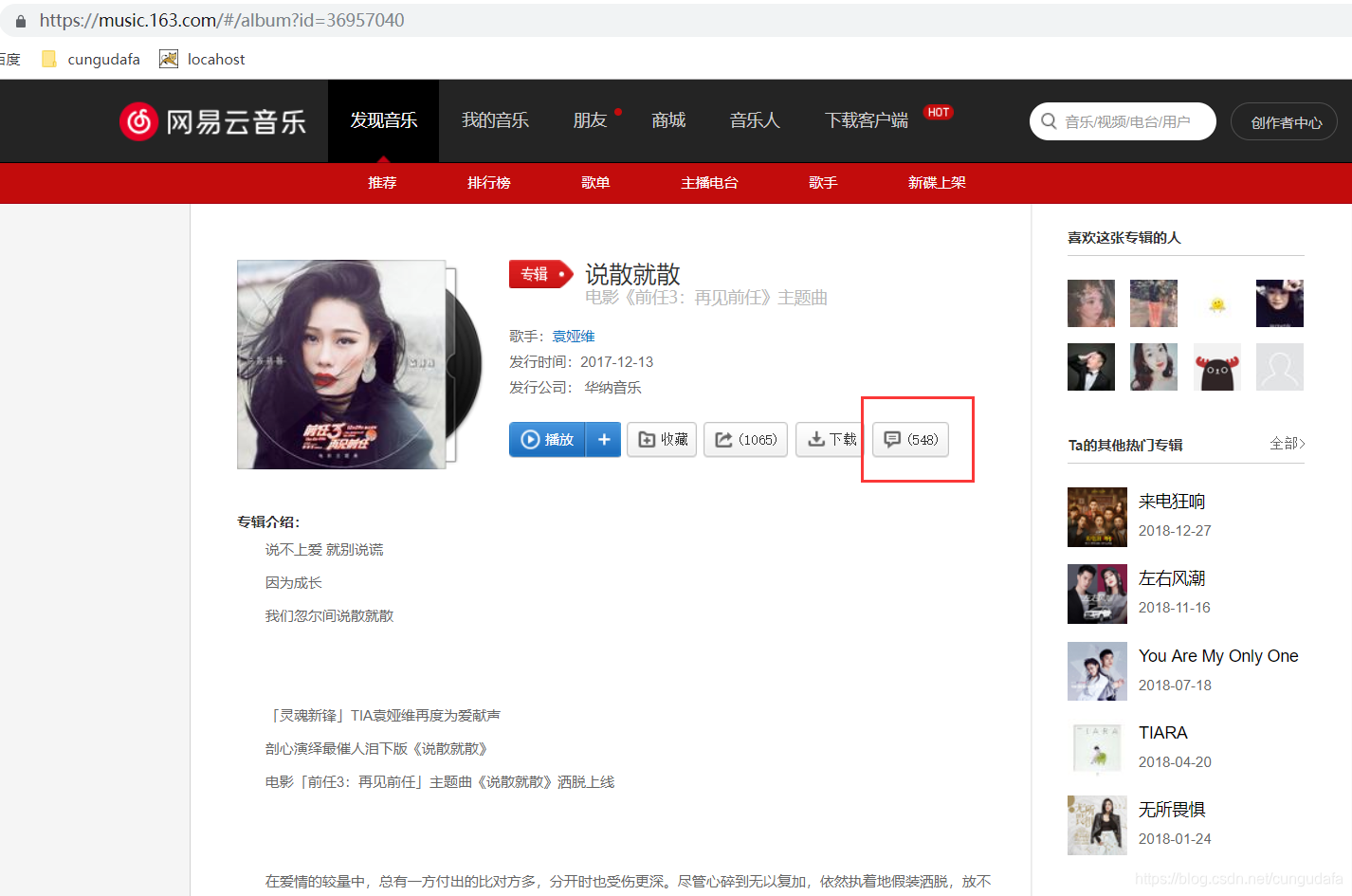
2、接着F12进入开发者控制台(审查元素),我们在搜索框里输入comments即可找到对应的获取评论的api的url,点击它在右边选择Response就可以看到返回的json了。
(右边进入Network->输入comments->左边选中评论->右边选择Response就可以看到返回数据了)
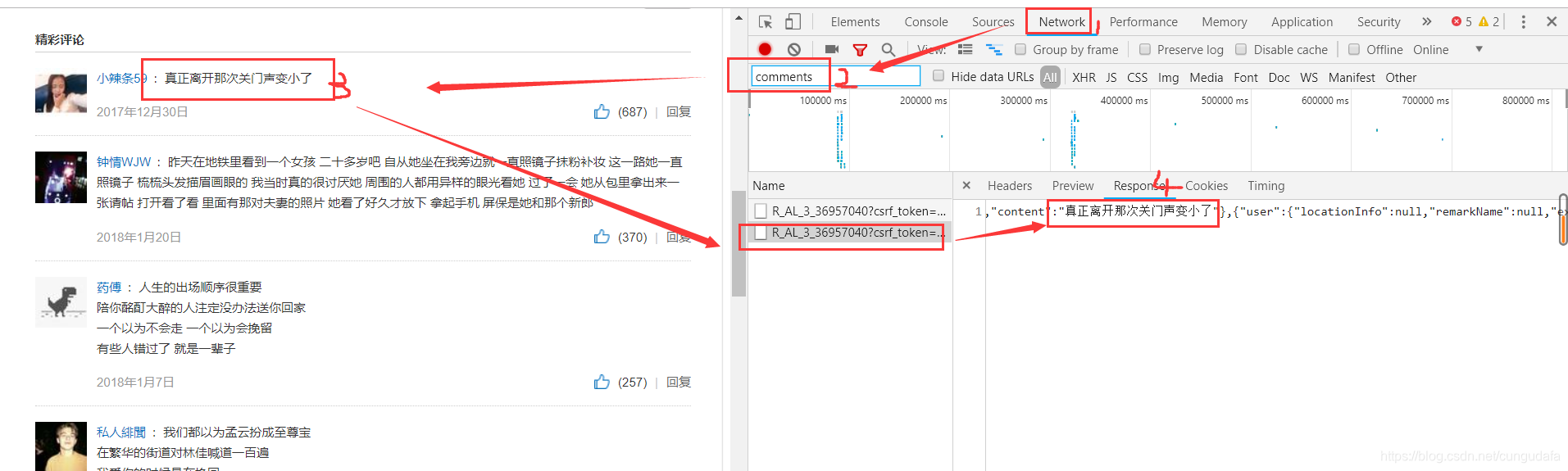
3、我们只需要分析这个api并模拟发送请求,获取json进行解析就好了。右键复制这个url下来:
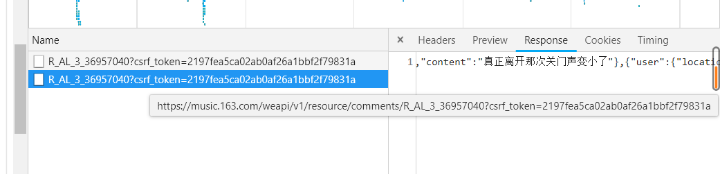
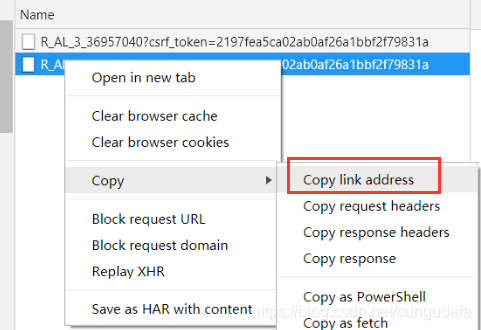
https://music.163.com/weapi/v1/resource/comments/R_AL_3_36957040?csrf_token=2197fea5ca02ab0af26a1bbf2f79831a
4、从浏览器的上的地址可以发现以上url里R_AL_3_后的数字就是歌曲的id,如下图:
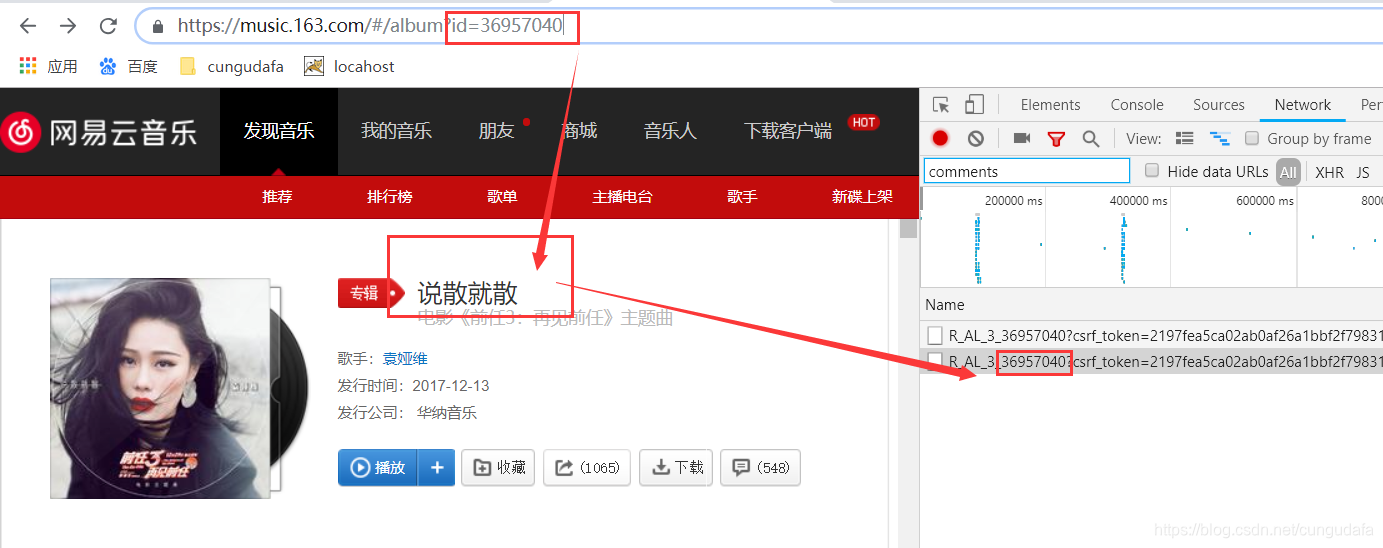
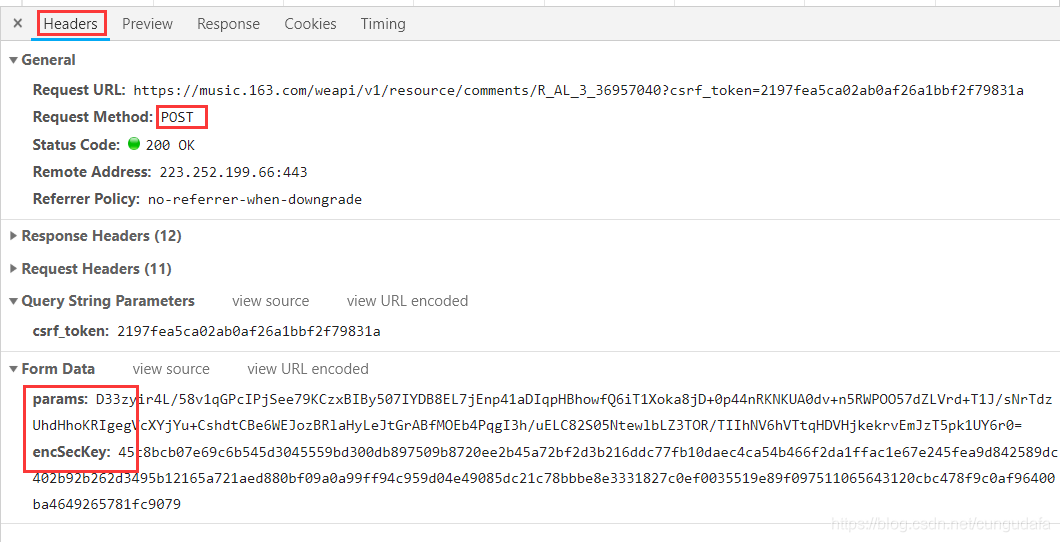
5、在开发者控制台里,点击Headers就可以看到请求方式为post,请求头里的表单数据有两个加过密的参数(params和encSecKey)。经测试,每一页面的加密参数都不同,这里会影响我们爬取;不过对于我们爬取热门评论,第一页就够了。
二、发送请求获取json
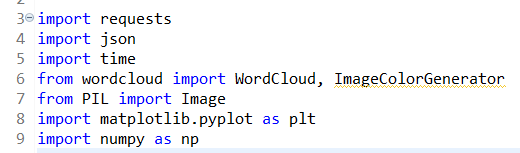
0 总项目目录及需要的库:
1 解析url内容:
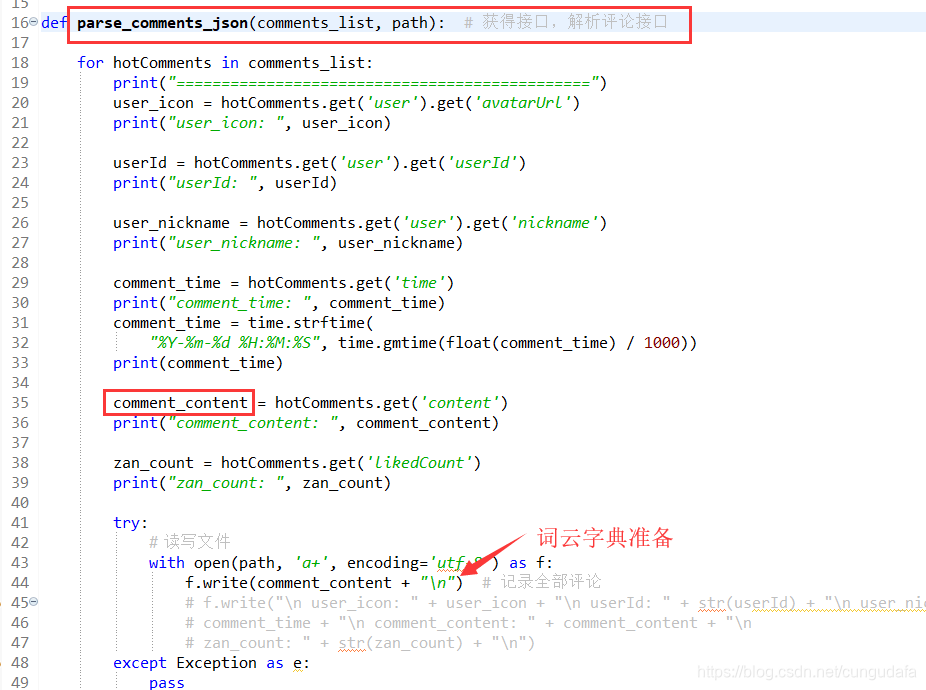
def parse_comments_json(comments_list, path):
2 获取热评:
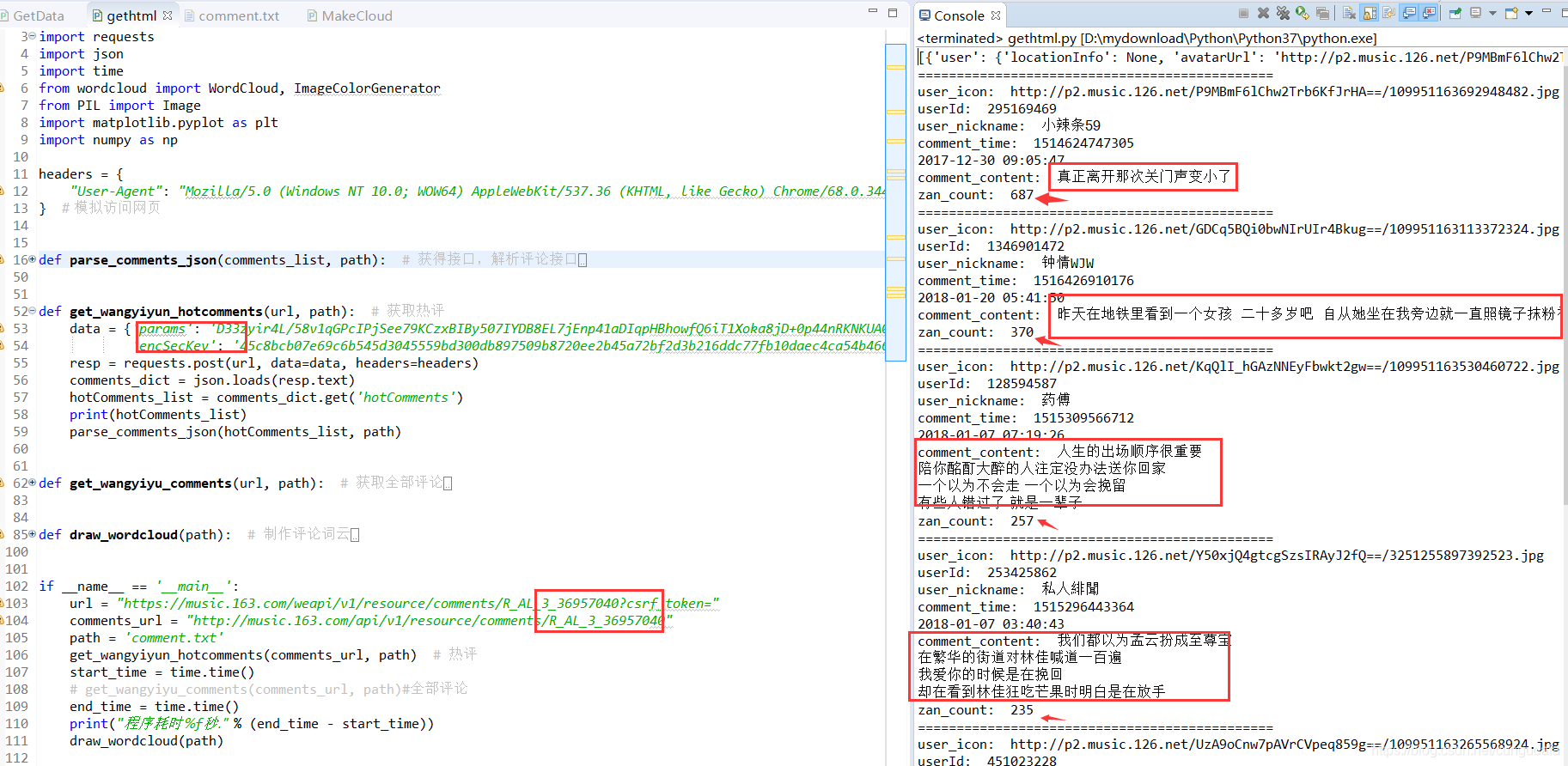
def get_wangyiyun_hotcomments(url, path):
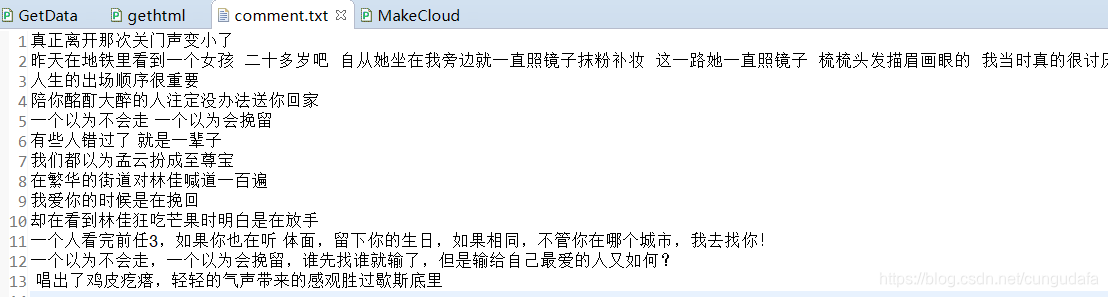
存入txt:
3 获取更多评论:
具体不知道有多少评论(我任意在1024条记录中取1024/20)
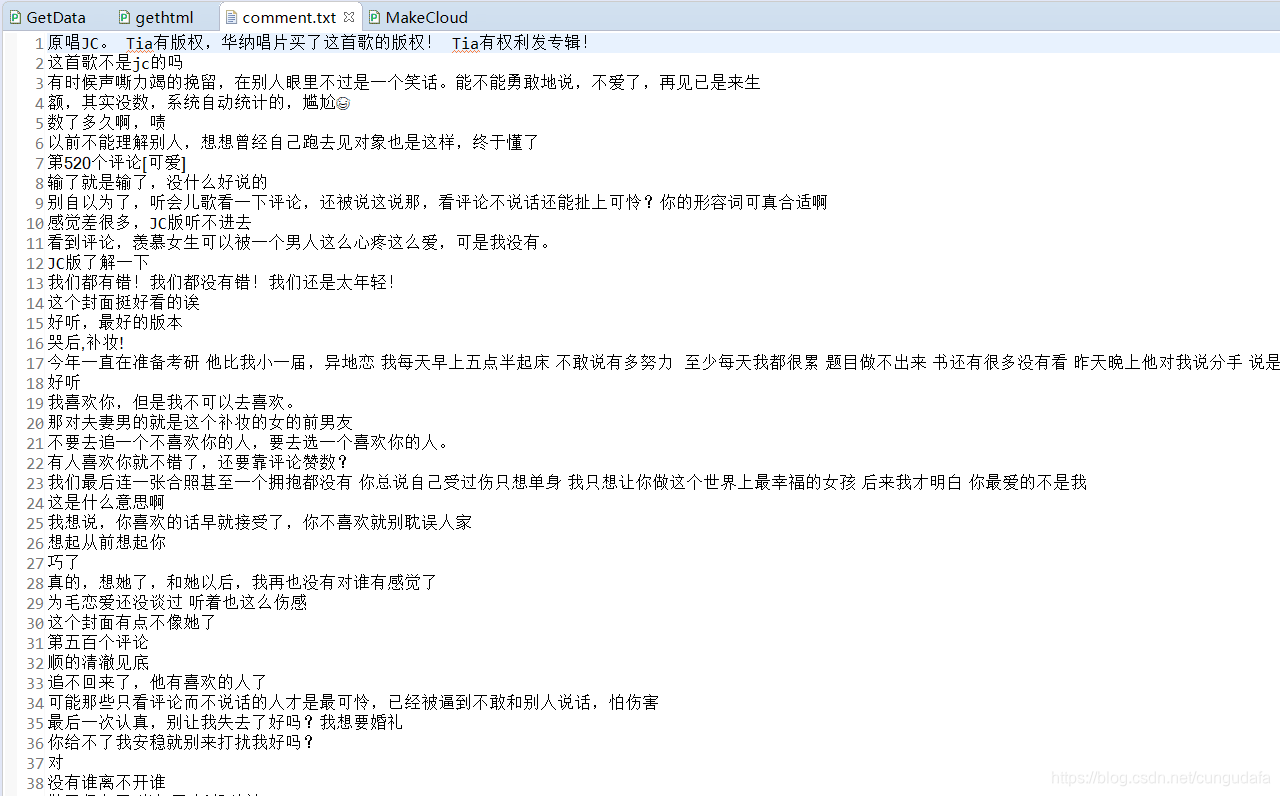
def draw_wordcloud(path):

三、生成词云
4 def draw_wordcloud(path):
左:热评、右:全部评论:(有点伤感了~)


全部源码:
# -*- coding:utf-8 -*-
import requests
import json
import time
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
} # 模拟访问网页
def parse_comments_json(comments_list, path): # 获得接口,解析评论接口
for hotComments in comments_list:
print("==============================================")
user_icon = hotComments.get('user').get('avatarUrl')
print("user_icon: ", user_icon)
userId = hotComments.get('user').get('userId')
print("userId: ", userId)
user_nickname = hotComments.get('user').get('nickname')
print("user_nickname: ", user_nickname)
comment_time = hotComments.get('time')
print("comment_time: ", comment_time)
comment_time = time.strftime(
"%Y-%m-%d %H:%M:%S", time.gmtime(float(comment_time) / 1000))
print(comment_time)
comment_content = hotComments.get('content')
print("comment_content: ", comment_content)
zan_count = hotComments.get('likedCount')
print("zan_count: ", zan_count)
try:
# 读写文件
with open(path, 'a+', encoding='utf-8') as f:
f.write(comment_content + "\n") # 记录全部评论
# f.write("\n user_icon: " + user_icon + "\n userId: " + str(userId) + "\n user_nickname: " + user_nickname + "\n comment_time: " +
# comment_time + "\n comment_content: " + comment_content + "\n
# zan_count: " + str(zan_count) + "\n")
except Exception as e:
pass
def get_wangyiyun_hotcomments(url, path): # 获取热评
data = {'params': 'D33zyir4L/58v1qGPcIPjSee79KCzxBIBy507IYDB8EL7jEnp41aDIqpHBhowfQ6iT1Xoka8jD+0p44nRKNKUA0dv+n5RWPOO57dZLVrd+T1J/sNrTdzUhdHhoKRIgegVcXYjYu+CshdtCBe6WEJozBRlaHyLeJtGrABfMOEb4PqgI3h/uELC82S05NtewlbLZ3TOR/TIIhNV6hVTtqHDVHjkekrvEmJzT5pk1UY6r0=',
'encSecKey': '45c8bcb07e69c6b545d3045559bd300db897509b8720ee2b45a72bf2d3b216ddc77fb10daec4ca54b466f2da1ffac1e67e245fea9d842589dc402b92b262d3495b12165a721aed880bf09a0a99ff94c959d04e49085dc21c78bbbe8e3331827c0ef0035519e89f097511065643120cbc478f9c0af96400ba4649265781fc9079'}
resp = requests.post(url, data=data, headers=headers)
comments_dict = json.loads(resp.text)
hotComments_list = comments_dict.get('hotComments')
print(hotComments_list)
parse_comments_json(hotComments_list, path)
def get_wangyiyu_comments(url, path): # 获取全部评论
header = {
'Accept': "*/*",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "music.163.com",
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"
}
n = 1
for i in range(0, 1024, 20): # 只打印0到1024中能被20整除的数(不一定有这么多)
param = {
'limit': str(i),
'offset': str(n * 20 - 1)
}
n += 1
response = requests.post(url, headers=header, params=param)
comments_dict = json.loads(response.text)
comments_list = comments_dict.get('comments')
print(comments_list)
parse_comments_json(comments_list, path=path)
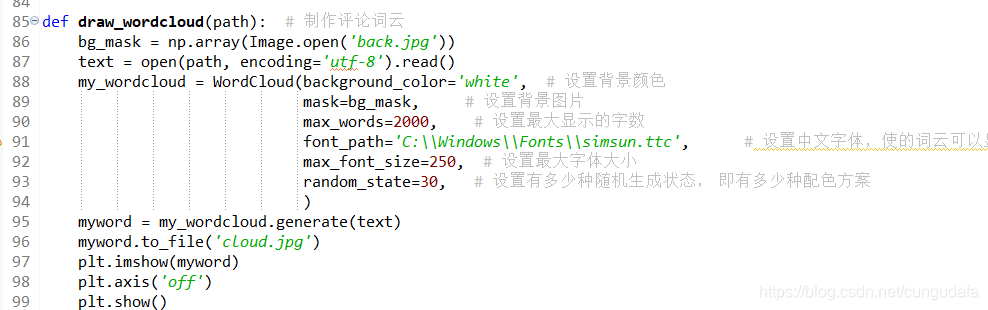
def draw_wordcloud(path): # 制作评论词云
bg_mask = np.array(Image.open('back.jpg'))
text = open(path, encoding='utf-8').read()
my_wordcloud = WordCloud(background_color='white', # 设置背景颜色
mask=bg_mask, # 设置背景图片
max_words=2000, # 设置最大显示的字数
font_path='C:\\Windows\\Fonts\\simsun.ttc', # 设置中文字体,使的词云可以显示
max_font_size=250, # 设置最大字体大小
random_state=30, # 设置有多少种随机生成状态, 即有多少种配色方案
)
myword = my_wordcloud.generate(text)
myword.to_file('cloud.jpg')
plt.imshow(myword)
plt.axis('off')
plt.show()
if __name__ == '__main__':
url = "https://music.163.com/weapi/v1/resource/comments/R_AL_3_36957040?csrf_token="
comments_url = "http://music.163.com/api/v1/resource/comments/R_AL_3_36957040"
path = 'comment.txt'
get_wangyiyun_hotcomments(comments_url, path) # 热评
start_time = time.time()
# get_wangyiyu_comments(comments_url, path) # 全部评论
end_time = time.time()
print("程序耗时%f秒." % (end_time - start_time))
draw_wordcloud(path)














 3913
3913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









