






阻塞队列
1.简介
想象一下,我们有一个需要访问外部Web服务的应用程序,以便收集有关客户端的信息,然后对其进行处理。 更具体地说,我们无法在一次调用中获得所有这些信息。 如果我们要查找不同的客户端,则需要多次调用。
如下图所示,示例应用程序将检索有关几个客户的信息,将它们分组在一个列表中,然后对其进行处理以计算其购买总额:
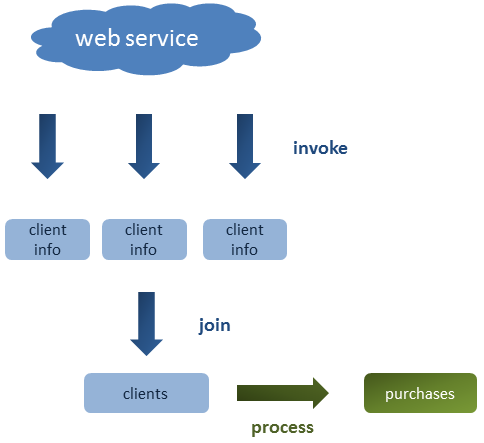

在这篇文章中,我们将看到收集信息的不同方式,并且从性能方面来看,哪一种是最好的。
这是与Java相关的文章。 但是,我们将使用Spring框架来调用RESTful Web服务。
栏目:
- 介绍
- 解释例子
- 首次尝试:顺序流
- 提高性能:并行流
- 具有CompletableFuture的非阻塞处理
- 结论
可以在Java 8 GitHub存储库中找到源代码。
此外,您可以访问 此存储库中公开RESTful Web服务的Web应用程序的源代码。
2.解释示例
在我们的应用程序中,我们有20个ID的列表,这些ID表示我们要从Web服务检索的客户端。 检索完所有客户之后,我们将查看每个客户购买了什么,并对它们进行汇总以计算出所有客户花费的总金额。
但是,有一个问题,该Web服务每次调用仅允许检索一个客户端,因此我们将需要调用该服务20次。 此外,Web服务有点慢,至少需要两秒钟才能响应请求。
如果我们看一下实现Web服务的应用程序,我们可以看到调用是由ClientController类处理的:
@RestController
@RequestMapping(value="/clients")
public class ClientController {
@Autowired
private ClientService service;
@RequestMapping(value="/{clientId}", method = RequestMethod.GET)
public @ResponseBody Client getClientWithDelay(@PathVariable String clientId) throws InterruptedException {
Thread.sleep(2000);
Client client = service.getClient(clientId);
System.out.println("Returning client " + client.getId());
return client;
}
}Thread.sleep用于模拟响应速度慢。
域类(客户)包含我们需要的信息; 客户花了多少钱:
public class Client implements Serializable {
private static final long serialVersionUID = -6358742378177948329L;
private String id;
private double purchases;
public Client() {}
public Client(String id, double purchases) {
this.id = id;
this.purchases = purchases;
}
//Getters and setters
}3.首次尝试:顺序流
在第一个示例中,我们将顺序调用服务以获取所有二十个客户端的信息:
public class SequentialStreamProcessing {
private final ServiceInvoker serviceInvoker;
public SequentialStreamProcessing() {
this.serviceInvoker = new ServiceInvoker();
}
public static void main(String[] args) {
new SequentialStreamProcessing().start();
}
private void start() {
List<String> ids = Arrays.asList(
"C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10",
"C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20");
long startTime = System.nanoTime();
double totalPurchases = ids.stream()
.map(id -> serviceInvoker.invoke(id))
.collect(summingDouble(Client::getPurchases));
long endTime = (System.nanoTime() - startTime) / 1_000_000;
System.out.println("Sequential | Total time: " + endTime + " ms");
System.out.println("Total purchases: " + totalPurchases);
}
}输出:
Sequential | Total time: 42284 ms
Total purchases: 20.0该程序的执行大约需要42秒。 这是太多时间。 让我们看看是否可以改善其性能。
4.提高性能:并行流
Java 8允许我们将流分成多个块,并在单独的线程中处理每个流。 我们需要做的就是简单地在前面的示例中将流创建为并行流。
您应考虑到每个块将在其线程中异步执行,因此处理这些块的顺序一定无关紧要。 在我们的案例中,我们正在对采购进行汇总,因此我们可以做到。
让我们尝试一下:
private void start() {
List<String> ids = Arrays.asList(
"C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10",
"C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20");
long startTime = System.nanoTime();
double totalPurchases = ids.parallelStream()
.map(id -> serviceInvoker.invoke(id))
.collect(summingDouble(Client::getPurchases));
long endTime = (System.nanoTime() - startTime) / 1_000_000;
System.out.println("Parallel | Total time: " + endTime + " ms");
System.out.println("Total purchases: " + totalPurchases);
}输出:
Parallel | Total time: 6336 ms
Total purchases: 20.0哇,这是一个很大的进步! 但是这个数字是什么来的呢?
并行流在内部使用ForkJoinPool,它是Java 7中引入的ForkJoin框架所使用的池。默认情况下,该池使用与计算机处理器可以处理的线程数相同的线程。 我的笔记本电脑是可以处理8个线程的四核(您可以通过调用Runtime.getRuntime.availableProcessors进行检查),因此它可以并行地对Web服务进行8次调用。 由于我们需要20次调用,因此至少需要3次“回合”:
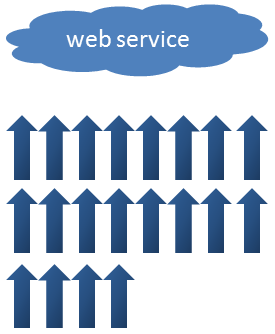

好的,所以从40秒到6秒是一个不错的改进,但是,我们还能进一步改进吗? 答案是肯定的。
5.使用CompletableFuture进行非阻塞处理
让我们分析先前的解决方案。
我们发送8个线程来调用每个Web服务,但是当该服务正在处理请求(整整两秒钟)时,我们的处理器除了等待外什么都不做(这是IO操作)。 在这些请求不回来之前,我们将无法发送更多请求。
问题是,如果我们可以异步发送所有20个请求,释放处理器并在可用时处理每个响应,该怎么办? 这是CompletableFuture抢救的地方:
public class AsyncStreamExecutorProcessing {
private final ServiceInvoker serviceInvoker;
private final ExecutorService executorService = Executors.newFixedThreadPool(100);
public AsyncStreamExecutorProcessing() {
this.serviceInvoker = new ServiceInvoker();
}
public static void main(String[] args) {
new AsyncStreamExecutorProcessing().start();
}
private void start() {
List<String> ids = Arrays.asList(
"C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10",
"C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20");
long startTime = System.nanoTime();
List<CompletableFuture<Client>> futureRequests = ids.stream()
.map(id -> CompletableFuture.supplyAsync(() -> serviceInvoker.invoke(id), executorService))
.collect(toList());
double totalPurchases = futureRequests.stream()
.map(CompletableFuture::join)
.collect(summingDouble(Client::getPurchases));
long endTime = (System.nanoTime() - startTime) / 1_000_000;
System.out.println("Async with executor | Total time: " + endTime + " ms");
System.out.println("Total purchases: " + totalPurchases);
executorService.shutdown();
}
}输出:
Async with executor | Total time: 2192 ms
Total purchases: 20.0在上一个示例中花费了三分之一的时间。
我们同时发送了所有20个请求,因此在IO操作上花费的时间仅花费了一次。 收到回复后,我们会Swift对其进行处理。
使用执行程序服务很重要,它被设置为supplyAsync方法的可选第二个参数。 我们指定了一个包含一百个线程的池,因此我们可以同时发送100个请求。 如果不指定执行程序,则默认使用ForkJoin池。
您可以尝试删除执行程序,您将看到与并行示例相同的性能。
六,结论
我们已经看到,当执行不涉及计算的操作(例如IO操作)时,我们可以使用CompletableFuture类来利用我们的处理器并提高应用程序的性能。
翻译自: https://www.javacodegeeks.com/2015/03/improving-performance-non-blocking-processing-of-streams.html
阻塞队列















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









