





 本教程介绍了如何使用Xcode和Core ML创建一个简单的iOS应用,该应用能识别和标记图像。从创建新项目开始,逐步讲解如何设置调试环境、设计用户界面、集成模型并处理实时图像输入。通过这个过程,读者将了解到如何利用预先训练好的模型实现图像分类功能。
本教程介绍了如何使用Xcode和Core ML创建一个简单的iOS应用,该应用能识别和标记图像。从创建新项目开始,逐步讲解如何设置调试环境、设计用户界面、集成模型并处理实时图像输入。通过这个过程,读者将了解到如何利用预先训练好的模型实现图像分类功能。
随着技术的进步,我们正处于设备可以使用内置摄像机通过预先训练的数据集准确识别和标记图像的地步。 您也可以训练自己的模型,但是在本教程中,我们将使用开源模型来创建图像分类应用程序。
我将向您展示如何创建可以识别图像的应用。 我们将从一个空的Xcode项目开始,并一次一步地实现机器学习支持的图像识别。
入门
Xcode版本
在开始之前,请确保您的Mac上安装了最新版本的Xcode。 这一点非常重要,因为Core ML仅在Xcode 9或更高版本上可用。 您可以通过打开Xcode并转到上方工具栏中的Xcode > 关于Xcode来检查您的版本。
如果您的Xcode版本早于Xcode 9,则可以转到Mac App Store进行更新,或者如果没有,则免费下载。
样例项目
新项目
确定具有正确版本的Xcode之后,您需要创建一个新的Xcode项目。
继续并打开Xcode,然后单击“ 创建新的Xcode项目”。

接下来,您需要为新的Xcode项目选择模板。 使用Single View应用程序是很常见的,因此请继续进行选择,然后单击“ 下一步”。
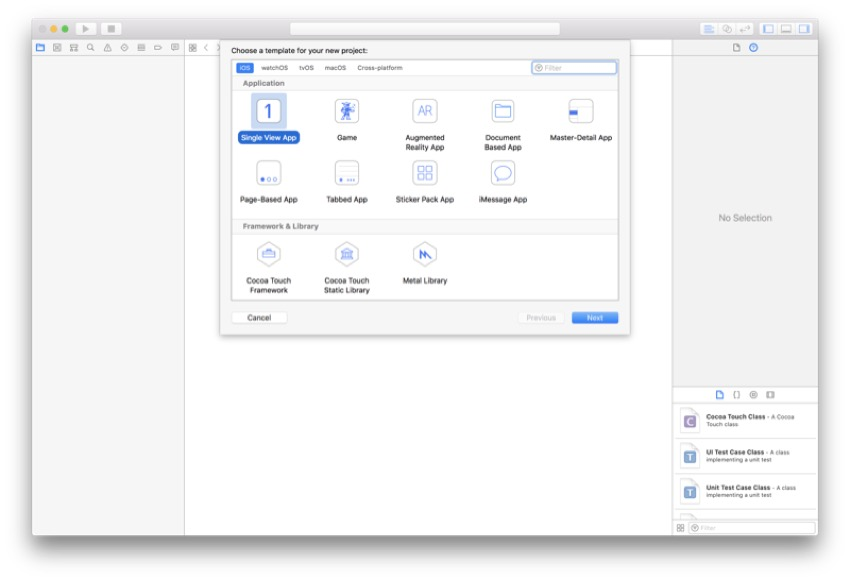
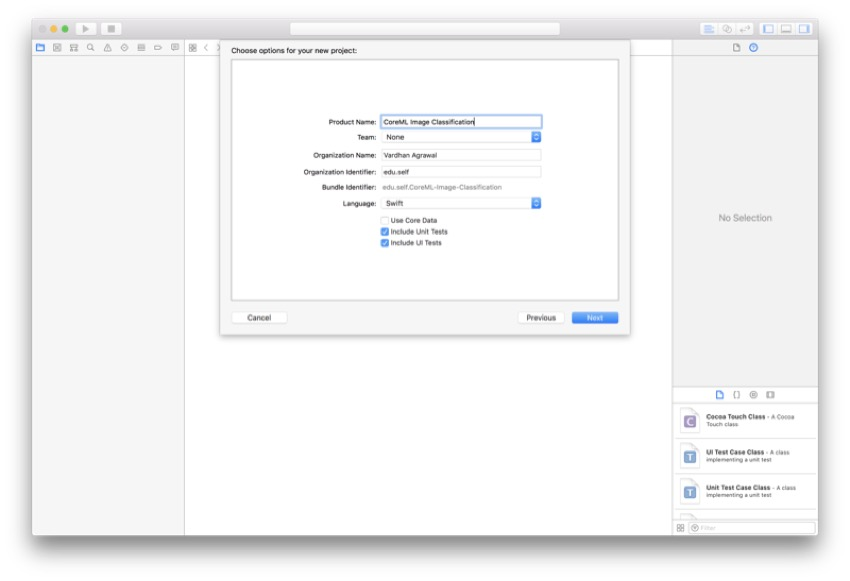
您可以根据自己的喜好为项目命名,但是我将命名为CoreML Image分类。 对于此项目,我们将使用Swift,因此请确保在Language(语言)下拉列表中将其选中。
准备调试
连接iPhone
由于Xcode Simulator没有相机,因此您需要插入iPhone。 不幸的是,如果您没有iPhone,则需要借用一本才能随本教程一起使用(以及与其他任何与相机相关的应用程序)。 如果您已经将iPhone连接到Xcode,则可以跳到下一步。
Xcode 9中的一个令人讨厌的新功能是您可以在设备上无线调试应用程序,因此让我们花点时间现在进行设置:
在顶部菜单栏中,选择“ 窗口” >“ 设备和模拟器” 。 在出现的窗口中,确保在顶部选择了设备 。
现在,使用避雷线插入设备。 这应该使您的设备出现在“ 设备和模拟器”窗口的左窗格中。 只需单击您的设备,然后选中通过网络连接框。
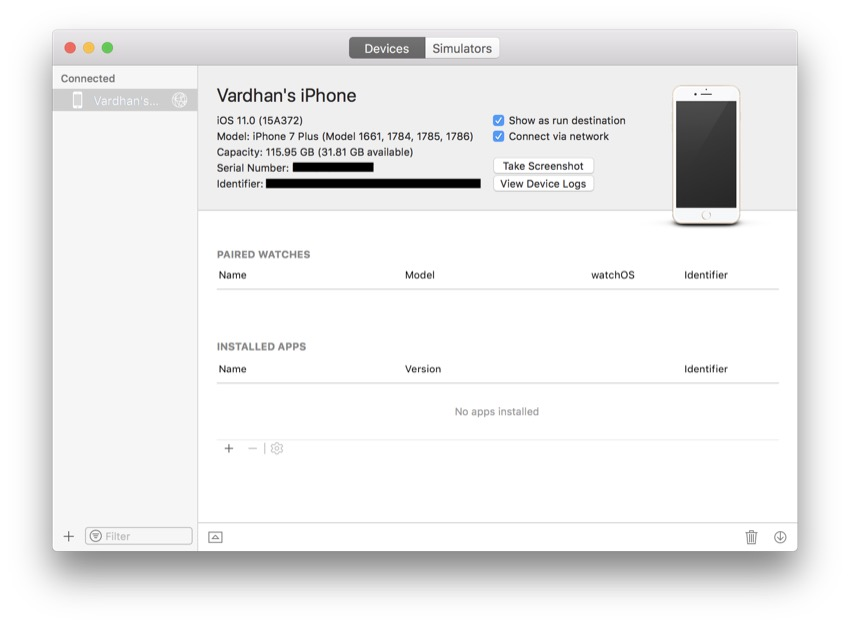
现在,您将可以在所有未来的应用程序的iPhone上进行无线调试。 要添加其他设备,您可以遵循类似的过程。
模拟器选择
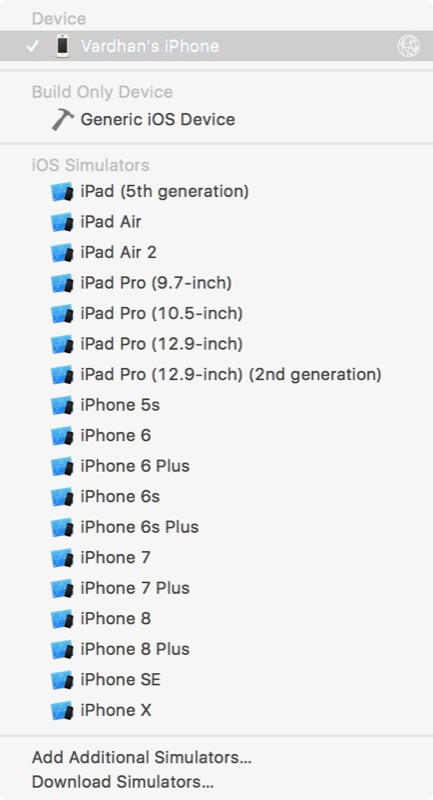
如果您想最终使用iPhone进行调试,只需从“ 运行”按钮旁边的下拉列表中选择它即可。 您应该在其旁边看到一个网络图标,显示该网络已连接以进行无线调试。 我已经选择了Vardhan的iPhone,但是您需要选择特定的设备。
深潜
现在,您已经创建了项目并将您的iPhone设置为模拟器,我们将更深入地研究并开始对实时图像分类应用程序进行编程。
准备项目
获取模型
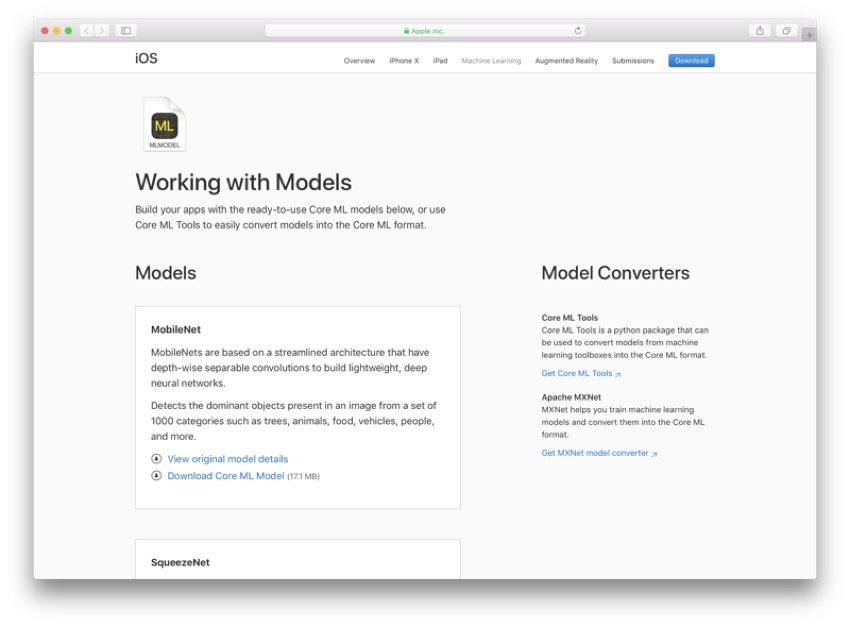
为了能够开始制作Core ML图像分类应用程序,您首先需要从Apple的网站上获取Core ML模型。 如前所述,您也可以训练自己的模型,但这需要一个单独的过程。 如果滚动到Apple 机器学习网站的底部,则可以选择和下载模型。
在本教程中,我将使用MobileNet.mlmodel模型,但是您可以使用任何模型,只要您知道它的名称并可以确保它以.mlmodel结尾即可 。
导入库
您需要导入几个框架以及通常的框架 UIKit 。 在文件顶部,确保存在以下导入语句:
import UIKit
import AVKit
import Vision 我们将需要AVKit因为我们将创建一个AVCaptureSession来显示实时提要,同时对图像进行实时分类。 另外,由于这是使用计算机视觉,因此我们需要导入Vision框架。
设计用户界面
该应用程序的重要部分是显示图像分类数据标签以及来自设备相机的实时视频。 要开始设计用户界面,请转到Main.storyboard文件。
添加图像视图
转到对象库并搜索图像视图 。 只需将其拖到View Controller上即可添加。如果需要,您还可以添加一个占位符图像,以便您大致了解该应用在使用时的外观。
如果您确实选择使用占位符图像,请确保将“ 内容模式”设置为“ 宽高比适合” ,并选中“ 裁剪到边界 ”框。 这样,图像将不会出现拉伸,也不会出现在UIImageView框之外。
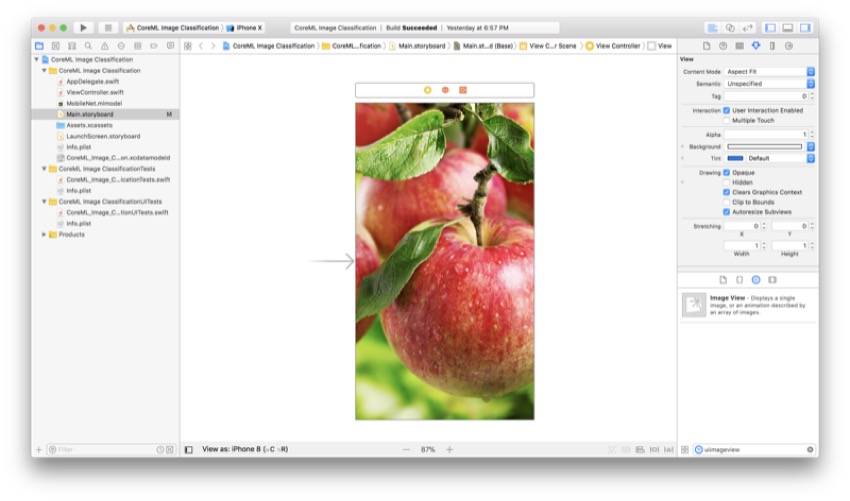
这是您的情节提要现在应该是什么样的:
添加视图
返回对象库 ,搜索一个View并将其拖到您的View Controller中。 这将为我们的标签提供一个很好的背景,这样它们就不会隐藏在所显示的图像中。 我们将使该视图变为半透明,以便某些预览层仍然可见(这对于应用程序的用户界面来说是一种很好的感觉)。
将其拖到屏幕底部,使其在三个侧面接触容器。 所选的高度无关紧要,因为我们将在这里设置约束。
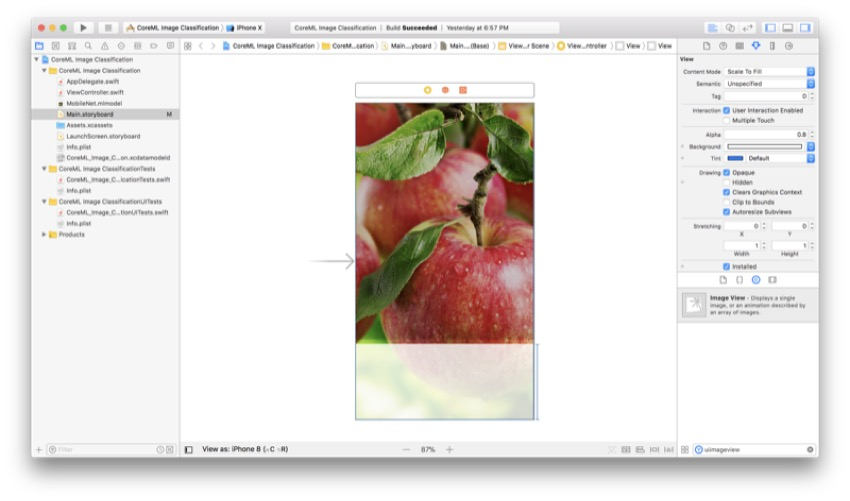
添加标签
这也许是我们用户界面中最重要的部分。 我们需要显示我们的应用程序认为对象是什么,以及它的确定程度(置信度)。 正如你可能已经猜到,你需要拖动两个Label(一个或多个) 从对象库到我们刚刚创建的视图。 将这些标签拖到中心附近的某个位置,彼此堆叠。
对于顶部标签,转到Attributes Inspector ,然后单击字体样式和大小旁边的T按钮,然后在弹出窗口中选择System作为字体 。 要将其与置信度标签区分开,请选择“ 黑色”作为样式。 最后,将大小更改为24 。
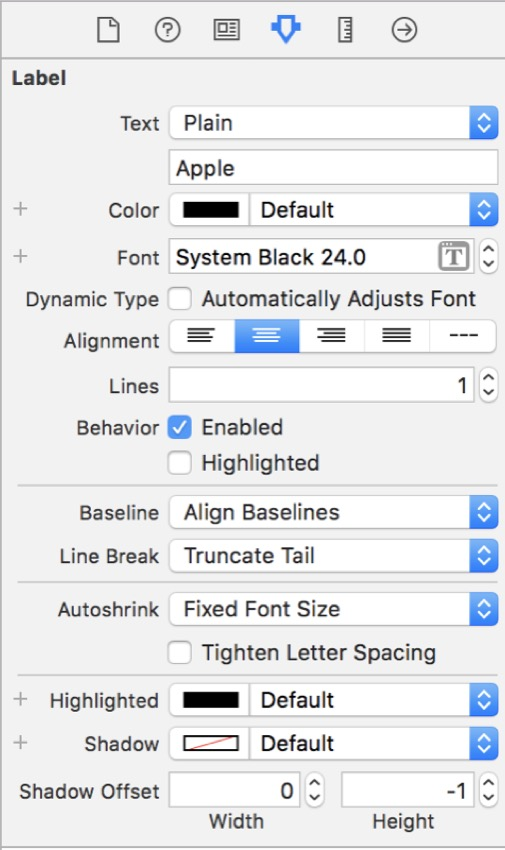
对于底部标签,请执行相同的步骤,但请选择“ 常规”,而不是选择“ 黑色”作为样式 ,并选择“ 17”作为大小 。
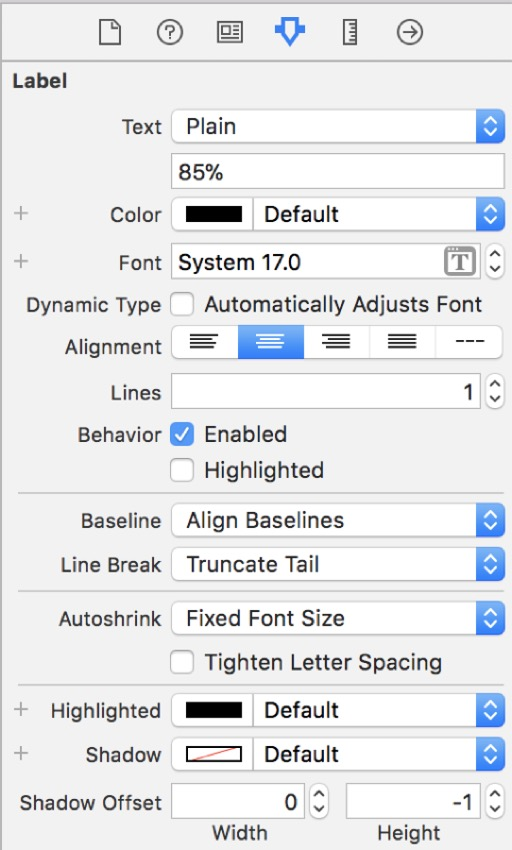
下图显示了您的 添加了所有这些视图和标签后,情节提要板便会出现。 如果它们与您的不完全相同,请不要担心。 我们将在下一步中向它们添加约束。
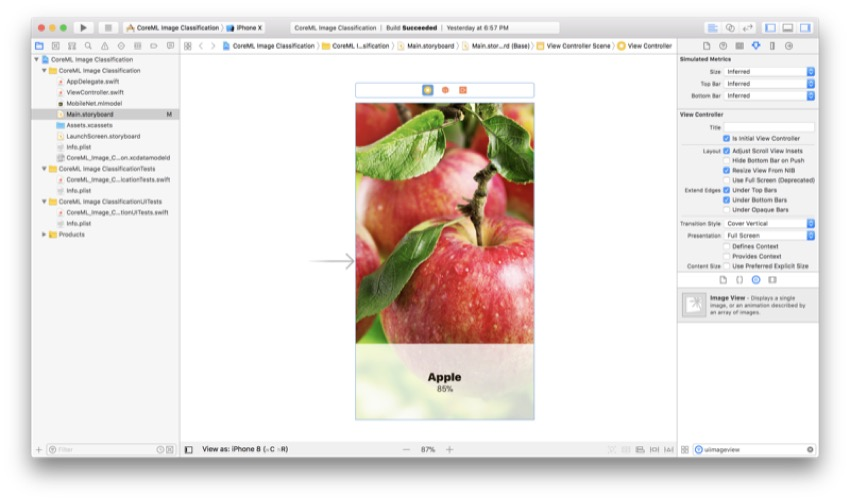
添加约束
为了使该应用程序可以在不同的屏幕尺寸上工作,添加约束很重要。 此步骤对应用程序的其余部分并不重要,但强烈建议您在所有iOS应用程序中执行此步骤。
影像检视限制
要约束的第一件事是我们的UIImageView 。 为此,选择您的图像视图,然后打开底部工具栏中的“ 固定菜单 ”(这看起来像是带有约束的正方形,是右边的第二个)。 然后,您需要添加以下值:
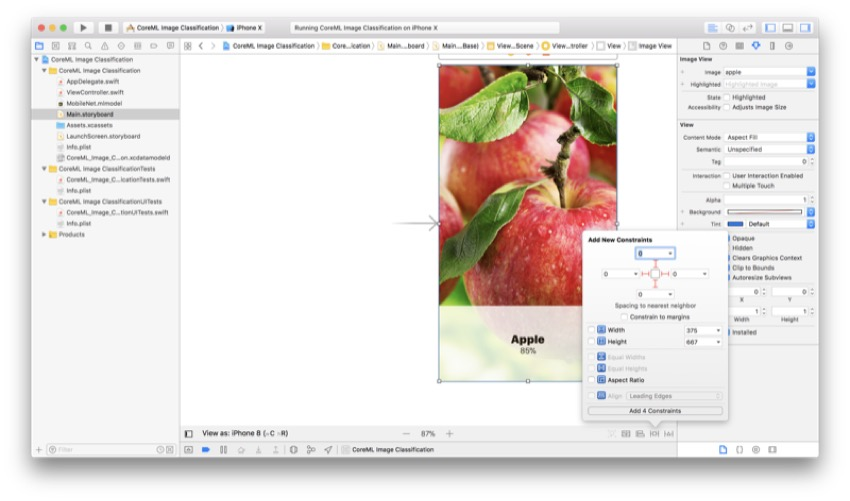
在继续之前,请确保未选中“ 限制到边距”框,因为这将在屏幕和实际图像视图之间形成间隙。 然后, 按Enter 。 现在,您的UIImageView位于屏幕UIImageView ,并且在所有设备尺寸上都应正确显示。
查看约束
现在,下一步是约束显示标签的视图。 选择视图,然后再次进入“ 固定菜单” 。 添加以下值:
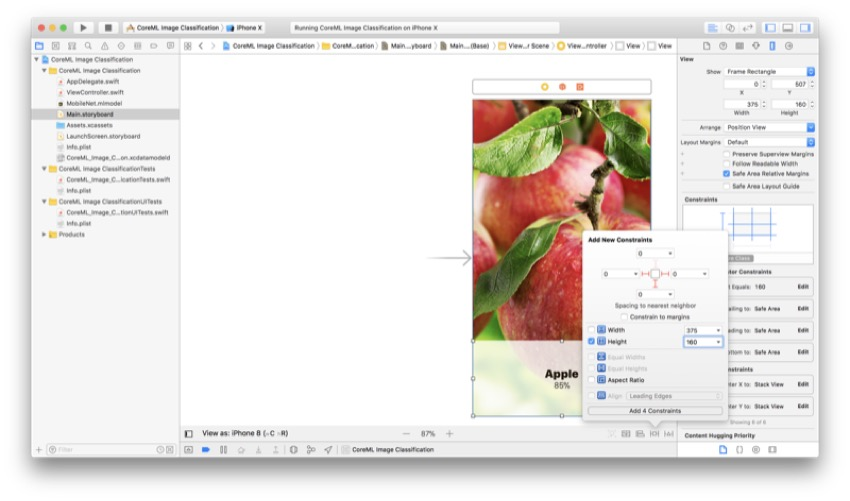
现在,只需按Enter键即可保存值。 现在,您的视图已限制在屏幕底部。
标签约束
由于现在已限制视图,因此可以相对于视图而不是屏幕向标签添加约束。 如果您以后决定更改标签或视图的位置,这将很有帮助。
选择两个标签,然后将它们放在堆栈视图中。 如果您不知道如何执行此操作,只需按一下看起来像一a书和向下箭头的按钮(从左数第二个)。 然后,您将看到按钮成为一个可选对象。
单击您的堆栈视图,然后单击“ 对齐菜单” (左第三),并确保选中以下框:
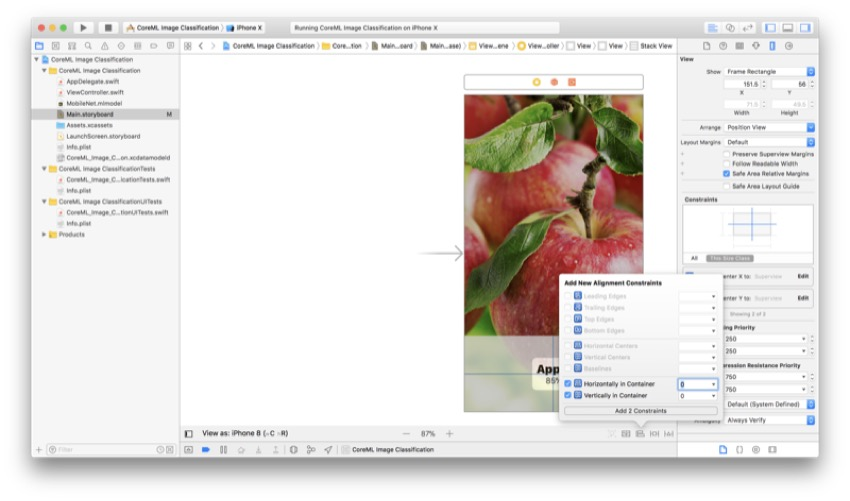
现在, 按Enter。 您的标签应该在上一步中的视图中居中,并且它们现在在所有屏幕尺寸上都将显示为相同。
接口生成器插座
用户界面中的最后一步是将元素连接到ViewController()类。 只需打开助理编辑 ,然后右击并每个元素拖到里面ViewController.swift类的顶部。 在本教程中,我将为它们命名:
-
UILabel:objectLabel -
UILabel:confidenceLabelUILabel -
UIImageView:imageView
当然,您可以随意命名,但是这些都是您可以在我的代码中找到的名称。
准备捕获会话
实时视频供稿将需要一个AVCaptureSession ,因此让我们现在创建一个。 我们还将实时向用户显示摄像机输入。 进行捕获会话是一个相当长的过程,并且您必须了解如何进行捕获,这一点很重要,因为在使用任何Apple设备上的机载摄像头进行的任何其他开发中,它都将非常有用。
类扩展和功能
首先,我们可以创建一个类扩展,然后使其符合AVCaptureVideoDataOutputSampleBufferDelegate协议。 您可以在实际的ViewController类中轻松地执行此操作,但是我们在此处使用了最佳实践,以使代码井井有条(这对于生产应用程序是这样的)。
为了能够在viewDidLoad()内部调用此函数,我们需要创建一个名为setupSession()的函数,该函数不包含任何参数。 您可以根据需要命名任何名称,但是稍后我们调用此方法时请注意命名。
完成后,您的代码应如下所示:
// MARK: - AVCaptureSession
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
func setupSession() {
// Your code goes here
}
}设备输入和捕获会话
创建捕获会话的第一步是检查设备是否具有摄像头。 换句话说,如果没有相机,请勿尝试使用相机。 然后,我们需要创建实际的捕获会话。
将以下代码添加到setupSession()方法中:
guard let device = AVCaptureDevice.default(for: .video) else { return }
guard let input = try? AVCaptureDeviceInput(device: device) else { return }
let session = AVCaptureSession()
session.sessionPreset = .hd4K3840x2160 在这里,我们使用guard let语句来检查设备( AVCaptureDevice )是否具有摄像机。 尝试获取设备的摄像机时,还必须指定mediaType ,在这种情况下,该类型为.video 。
然后,我们创建一个AVCaptureDeviceInput ,它是一个输入,它将媒体从设备带到捕获会话。
最后,我们仅创建AVCaptureSession类的实例,然后将其分配给名为session的变量。 我们已将会话比特率和质量自定义为 3840 x 2160像素的超高清(UHD)。 您可以尝试此设置,以查看最适合您的设置。
预览图层和输出
进行AVCaptureSession设置的下一步是创建预览层,用户可以在其中查看来自摄像机的输入。 我们将其添加到我们之前在Storyboard中创建的UIImageView 。 不过,最重要的部分实际上是为Core ML模型创建我们的输出,以在本教程的后面部分处理,我们还将在此步骤中进行处理。
将以下代码直接添加到上一步的代码下方:
et previewLayer = AVCaptureVideoPreviewLayer(session: session)
previewLayer.frame = view.frame
imageView.layer.addSublayer(previewLayer)
let output = AVCaptureVideoDataOutput()
output.setSampleBufferDelegate(self, queue: DispatchQueue(label: "videoQueue"))
session.addOutput(output) 我们首先创建AVCaptureVideoPreviewLayer类的实例,然后使用在上一步中创建的会话对其进行初始化。 完成之后,我们将其分配给名为previewLayer的变量。 该层用于实际显示来自摄像机的输入。
接下来,通过将框架尺寸设置为视图的尺寸,使预览层填充整个屏幕。 这样,所需的外观将在所有屏幕尺寸下均保持不变。 为了实际显示预览层,我们将其添加为创建用户界面时创建的UIImageView的子层。
现在,对于重要部分:我们创建AVCaptureDataOutput类的实例,并将其分配给名为output的变量。
输入和开始会话
最后,我们完成了捕获会话。 在实际的Core ML代码之前,剩下要做的就是添加输入并开始捕获会话。
直接在上一步下面添加以下两行代码:
// Sets the input of the AVCaptureSession to the device's camera input
session.addInput(input)
// Starts the capture session
session.startRunning() 这会将我们之前创建的输入添加到AVCaptureSession ,因为在此之前,我们仅创建了输入,而未添加它。 最后,这一行代码开始了我们花了很长时间创建的会话。
集成核心ML模型
我们已经下载了模型,因此下一步是在我们的应用程序中实际使用它。 因此,让我们开始使用它来对图像进行分类。
委托方法
首先,您需要将以下委托方法添加到您的应用中:
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// Your code goes here
}写入新的视频帧时将触发此委托方法。 在我们的应用程序中,每当通过我们的实时视频供稿录制一帧时就会发生这种情况(其速度仅取决于应用程序运行的硬件)。
像素缓冲区和模型
现在,我们将图像(实时供稿一帧)转换为像素缓冲区,模型可以识别该缓冲区。 这样,我们以后就可以创建VNCoreMLRequest 。
在先前创建的委托方法中添加以下两行代码:
guard let pixelBuffer: CVPixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return }
guard let model = try? VNCoreMLModel(for: MobileNet().model) else { return } 首先,我们通过委托方法传入的参数创建一个像素缓冲区(Core ML接受的格式),然后将其分配给名为pixelBuffer的变量。 然后,将MobileNet模型分配给一个称为model的常量。
请注意,这两个都是使用guard let语句创建的,并且如果这两个均为nil值,则函数将返回。
创建一个请求
在执行了前两行代码后,我们肯定知道我们有一个像素缓冲区和一个模型。 下一步将是使用它们两者来创建VNCoreMLRequest 。
在上一步的下面,将以下代码行粘贴到委托方法中:
let request = VNCoreMLRequest(model: model) { (data, error) in {
// Your code goes here
} 在这里,我们正在创建一个名为request的常量,并在将模型传递给它时VNCoreMLRequest分配方法VNCoreMLRequest的返回值。
获取和排序结果
我们快完成了! 现在我们要做的就是获取结果(模型认为我们的图像是什么),然后将其显示给用户。
将以下两行代码添加到请求的完成处理程序中:
// Checks if the data is in the correct format and assigns it to results
guard let results = data.results as? [VNClassificationObservation] else { return }
// Assigns the first result (if it exists) to firstObject
guard let firstObject = results.first else { return } 如果数据的结果(来自请求的完成处理程序的结果)可用作VNClassificationObservations数组,则此行代码将从我们先前创建的数组中获取第一个对象。 然后将其分配给名为firstObject的常量。 该数组中的第一个对象是图像识别引擎最有信心的对象。
显示数据和图像处理
还记得我们创建两个标签(信心和对象)的时候吗? 现在,我们将使用它们来显示模型认为图像的内容。
在上一步之后添加以下代码行:
if firstObject.confidence * 100 >= 50 {
self.objectLabel.text = firstObject.identifier.capitalized
self.confidenceLabel.text = String(firstObject.confidence * 100) + "%"
} if语句可确保算法对其对象的标识至少有50%的确定性。 然后,我们只需将firstObject设置为objectLabel的文本,因为我们知道置信度足够高。 我们只使用confidenceLabel的text属性显示确定性百分比。 由于firstObject.confidence用小数表示,因此我们需要乘以100以获得百分比。
最后要做的是通过我们刚刚创建的算法处理图像。 为此,您需要在退出captureOutput(_:didOutput:from:)委托方法之前直接输入以下代码:
try? VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:]).perform([request])结论
您在本教程中学到的概念可以应用于多种应用程序。 希望您喜欢使用手机对图像进行分类学习。 尽管它可能还不是完美的,但是您将来可以训练自己的模型以使其更加准确。
完成后,应用程序应如下所示:

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









