







在开发模块过程中,遇到一个问题:在NF_INET_LOCAL_IN钩子处截获数据包后,如果操作失败,还要把这些截获的数据包重新传递到TCP层处理。但是这个操作是在内核线程中完成,不知道会不会对正常的数据包接收过程产生影响?因此,需要知道数据包在从网络层传递到传输层时的上下文环境(指的是是否禁止内核抢占、是否需要获取锁等)。为了解决这个问题,决定将数据包的接收过程从驱动程序到TCP层的处理流程梳理了一遍。
在文中的叙述过程中,将网卡驱动和网络层之间的部分,称之为网络核心层,如下图所示:

一、驱动程序
为了找到skb包传递到传输层的上下文,肯定要从数据包接收的下半部,也就是数据接收的软中断中去找,但是既然要梳理,就要梳理的彻底一点,确保没有遗漏,因此从网卡的驱动程序开始。每个网卡都会有一个中断号,驱动程序中会有一个对应的中断处理函数。当数据包到达时,网卡会向CPU发送一个中断,然后会调用特定于网络的驱动程序,来接收数据包。选择的驱动程序是3c501网卡的驱动,该驱动比较简单,便于看出从驱动程序传递到网络核心层传输的过程。3c501网卡对应的中断处理函数el_interrupt(),源码如下(只列出关键的部分):
static irqreturn_t el_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
struct net_local *lp;
int ioaddr;
int axsr; /* Aux. status reg. */
ioaddr = dev->base_addr;
lp = netdev_priv(dev);
spin_lock(&lp->lock);
......
if (lp->txing) {
......
} else {
/*
* In receive mode.
*/
int rxsr = inb(RX_STATUS);
.......
if (rxsr & RX_MISSED)
dev->stats.rx_missed_errors++;
else if (rxsr & RX_RUNT) {
/* Handled to avoid board lock-up. */
dev->stats.rx_length_errors++;
if (el_debug > 5)
pr_debug("%s: runt.\n", dev->name);
} else if (rxsr & RX_GOOD) {
/*
* Receive worked.
*/
el_receive(dev);
} else {
/*
* Nothing? Something is broken!
*/
if (el_debug > 2)
pr_debug("%s: No packet seen, rxsr=%02x **resetting 3c501***\n",
dev->name, rxsr);
el_reset(dev);
}
}
/*
* Move into receive mode
*/
outb(AX_RX, AX_CMD);
outw(0x00, RX_BUF_CLR);
inb(RX_STATUS); /* Be certain that interrupts are cleared. */
inb(TX_STATUS);
spin_unlock(&lp->lock);
out:
return IRQ_HANDLED;
}中断处理中调用inb()来获取当前中断的结果,如果是RX_GOOD,则调用el_receive()(3c501的接收函数)来处理接收数据的工作。从el_interrupt()中可以看出el_receive()返回后,驱动程序中对中断的处理已经基本完成。因此,要继续从el_receive()函数中去找前面提出的问题的答案。
el_receive()中的关键代码及分析如下:
static void el_receive(struct net_device *dev)
{
......
outb(AX_SYS, AX_CMD);
skb = dev_alloc_skb(pkt_len+2);
/*
* Start of frame
*/
outw(0x00, GP_LOW);
if (skb == NULL) {
pr_info("%s: Memory squeeze, dropping packet.\n", dev->name);
dev->stats.rx_dropped++;
return;
} else {
skb_reserve(skb, 2); /* Force 16 byte alignment */
/*
* The read increments through the bytes. The interrupt
* handler will fix the pointer when it returns to
* receive mode.
*/
insb(DATAPORT, skb_put(skb, pkt_len), pkt_len);
/*
* 调用eth_type_trans()函数来获取数据帧承载的
* 报文类型,并且将skb包中的数据起始位置
* 移到数据帧中报文的起始位置。如果
* 承载的是IP报文,则此时data指向的是IP首部的
* 地址。
*/
skb->protocol = eth_type_trans(skb, dev);
/*
* 调用netif_rx()将接收的数据包传递到
* 网络核心层。
*/
netif_rx(skb);
dev->stats.rx_packets++;
dev->stats.rx_bytes += pkt_len;
}
return;
}el_receive()首先分配一个sk_buff缓冲区,然后从网卡中拷贝数据,之后调用netif_rx()将skb包传递到网络核心层,至此网卡驱动中所做的工作已经完成了。也就是说,当netif_rx()返回后,数据包接收的上半部,也就完成了。从这里开始我们就要开始进入网络核心层中的处理了。
小结:在网卡驱动的中断处理函数中,也就是数据接收的上半部中,不可能存在和向传输层传递数据包相关的上下文。但是既然要梳理整个流程,就要彻底一些,以免漏掉什么东西。通过对驱动程序的研究,可以知道三层、四层中的skb是怎么来的,数据包是怎么从驱动程序传递到内核的协议栈中。当然还有skb中一些成员是如何设置的。
二、网络核心层
从这里开始,将更多的注意力放在处理过程中锁的获取、中断的处理、以及内核抢占等同步手段的处理上,找出向传输层传递数据包时的上下文环境,也就是调用tcp_v4_rcv()开始传输层处理时的上下文环境。
在3c501的网卡驱动程序中,看到将skb包传递到上层是通过netif_rx()函数来完成,每个网卡驱动程序在接收到一个包后,都会调用该接口来传递到上层。接下来看看这个接口的实现,源码及分析如下:
/**
* netif_rx - post buffer to the network code
* @skb: buffer to post
*
* This function receives a packet from a device driver and queues it for
* the upper (protocol) levels to process. It always succeeds. The buffer
* may be dropped during processing for congestion control or by the
* protocol layers.
*
* return values:
* NET_RX_SUCCESS (no congestion)
* NET_RX_DROP (packet was dropped)
*
*/
/*
* 数据到来时,会产生中断,首先执行特定网卡的中断
* 处理程序,然后再执行接收函数分配新的套接字缓冲
* 区,然后通过调用netif_rx来讲数据传到上层
* 调用该函数标志着控制由特定于网卡的代码转移到了
* 网络层的通用接口部分。该函数的作用是,将接收到
* 的分组放置到一个特定于CPU的等待队列上,并退出中
* 断上下文,使得CPU可以执行其他任务
*/
int netif_rx(struct sk_buff *skb)
{
struct softnet_data *queue;
unsigned long flags;
/* if netpoll wants it, pretend we never saw it */
if (netpoll_rx(skb))
return NET_RX_DROP;
/*
* 如果没有设置数据包到达的时间,
* 则获取当前的时钟时间设置到tstamp上
*/
if (!skb->tstamp.tv64)
net_timestamp(skb);
/*
* The code is rearranged so that the path is the most
* short when CPU is congested, but is still operating.
*/
local_irq_save(flags);
/*
* 每个CPU都有一个softnet_data类型变量,
* 用来管理进出分组的等待队列
*/
queue = &__get_cpu_var(softnet_data);
/*
* 记录当前CPU上接收的数据包的个数
*/
__get_cpu_var(netdev_rx_stat).total++;
if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
/*
* 如果接受队列不为空,说明当前正在处理数据包,
* 则不需要触发
* 软中断操作,直接将数据包放到接收
* 队列中,待前面的数据包处理之后,会立即处理
* 当前的数据包。
*/
if (queue->input_pkt_queue.qlen) {
enqueue:
__skb_queue_tail(&queue->input_pkt_queue, skb);
local_irq_restore(flags);
/*
* 至此,中断处理,也就是数据包接收的上半部已经
* 已经基本处理完成,剩下的工作交给软中断来处理。
*/
return NET_RX_SUCCESS;
}
/*
* 如果NAPI程序尚未运行,则重新调度使其开始
* 轮询,并触发NET_RX_SOFTIRQ软中断。
*/
napi_schedule(&queue->backlog);
goto enqueue;
}
/*
* 如果当前CPU的接受队列已满,则丢弃数据包。
* 并记录当前CPU上丢弃的数据包个数
*/
__get_cpu_var(netdev_rx_stat).dropped++;
local_irq_restore(flags);
kfree_skb(skb);
return NET_RX_DROP;
}每个CPU都有一个管理进出分组的softnet_data结构的实例,netif_rx()将skb包放在当前CPU的接收队列中,然后调用napi_schedule()来将设备放置在NAPI的轮询队列中,并触发NET_RX_SOFTIRQ软中断来进行数据包接收的下半部的处理,也就是在这个过程中找到在向传输层传递数据包时的上下文。
NET_RX_SOFTIRQ软中断对应的处理函数是net_rx_action(),参见net_dev_init()。在解决开始时提到的问题之前,需要先找到软中断的处理函数被调用时的上下文。
有几种方法可开启软中断处理,但这些都归结为调用do_softirq()函数。其中一种方式就是在软中断守护进程(每个CPU都会有一个守护进程)中调用,就以此种方式为切入点来探究。软中断守护进程的处理函数时ksoftirqd(),其关键的代码如下:
static int ksoftirqd(void * __bind_cpu)
{
......
while (!kthread_should_stop()) {
preempt_disable();
......
while (local_softirq_pending()) {
......
do_softirq();
preempt_enable_no_resched();
cond_resched();
preempt_disable();
......
}
preempt_enable();
......
}
......
}static int ksoftirqd(void * __bind_cpu)
{
......
while (!kthread_should_stop()) {
preempt_disable();
......
while (local_softirq_pending()) {
......
do_softirq();
preempt_enable_no_resched();
cond_resched();
preempt_disable();
......
}
preempt_enable();
......
}
......
}从这里可以看出,在开始处理软中断之前,要先调用preempt_disable()来禁止内核抢占,这是我们找到的一个需要关注的上下文环境,也就是在协议层中接收数据时,首先要作的就是禁止内核抢占(当然是不是这样,还要看后面的处理,这里姑且这么认为吧)。
接下来看do_softirq()中的处理,源码如下:
asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags;
/*
* 确认当前不处于中断上下文中(当然,即不涉及
* 硬件中断)。如果处于中断上下文,则立即结束。
* 因为软中断用于执行ISR中非时间关键部分,所以
* 其代码本身一定不能在中断处理程序内调用。
*/
if (in_interrupt())
return;
local_irq_save(flags);
/*
* 确定当前CPU软中断位图中所有置位的比特位。
*/
pending = local_softirq_pending();
/*
* 如果有软中断等待处理,则调用__do_softirq()。
*/
if (pending)
__do_softirq();
local_irq_restore(flags);
}在开始调用__do_softirq()作进一步的处理之前,要先调用local_irq_save()屏蔽所有中断,并且保存当前的中断状态,这是第二个我们需要关注的上下文环境。接下来看__do_softirq(),关键代码如下:
asmlinkage void __do_softirq(void)
{
......
__local_bh_disable((unsigned long)__builtin_return_address(0));
......
local_irq_enable();
h = softirq_vec;
do {
if (pending & 1) {
......
h->action(h);
......
}
h++;
pending >>= 1;
} while (pending);
local_irq_disable();
......
_local_bh_enable();
}__do_softirq()在调用软中断对应的action之前,会先调用__local_bh_disable()来和其他下半部操作互斥,然后调用local_irq_enable()来启用中断(注意这个操作和local_irq_restore()不一样),这是第三个我们需要关注的上文环境。在__do_softirq()中会调用到NET_RX_SOFTIRQ软中断对应的
处理函数net_rx_action()。接下来看net_rx_action()函数的处理
static void net_rx_action(struct softirq_action *h)
{
......
local_irq_disable();
while (!list_empty(list)) {
......
local_irq_enable();
......
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
......
local_irq_disable();
......
}
out:
local_irq_enable();
......
}net_rx_action()中进入循环前调用local_irq_disable()来关闭软中断,但是在调用NAPI轮询队列上设备的poll函数前又调用local_irq_enable()来开启中断,因此在net_rx_action()中poll函数的执行上下文(指锁、中断等同步手段的环境)中和__do_softirq()中保持一致,没有发生变化。接下来要关注的是net_rx_action()中调用poll接口,默认情况下调用的函数是process_backlog(),源码如下:
static int process_backlog(struct napi_struct *napi, int quota)
{
int work = 0;
struct softnet_data *queue = &__get_cpu_var(softnet_data);
unsigned long start_time = jiffies;
napi->weight = weight_p;
do {
struct sk_buff *skb;
local_irq_disable();
/*
* 从当前CPU的接收队列中取出一个SKB包。
*/
skb = __skb_dequeue(&queue->input_pkt_queue);
/*
* 如果所有的数据已处理完成,则调用
* __napi_complete()来将当前设备移除轮询队列。
*/
if (!skb) {
__napi_complete(napi);
local_irq_enable();
break;
}
local_irq_enable();
netif_receive_skb(skb);
/*
* 如果当前的处理次数小于设备的权重,并且
* 处理时间不超过1个jiffies时间(如果HZ为1000,则
* 相当于是1毫秒),则处理下一个SKB包。
*/
} while (++work < quota && jiffies == start_time);
return work;
}process_backlog()中首先从CPU的接收队列上,然后调用netif_receive_skb()将SKB包传递到网络层,所以netif_receive_skb()函数就是skb包在网络核心层的最后一次处理。 netif_receive_skb()的关键代码如下:
int netif_receive_skb(struct sk_buff *skb)
{
......
rcu_read_lock();
......
type = skb->protocol;
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_orig || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
} else {
......
}
out:
rcu_read_unlock();
return ret;
}netif_receive_skb()中在调用三层的接收函数之前,需要调用rcu_read_lock()进入读临界区,这是第四个我们需要关注的上文环境。如果skb的三层协议类型是IP协议,则pt_prev->func()调用的就是ip_rcv()。
小结:经过上面的分析,有必要总结一下从软中断守护进程的处理函数ksoftirqd()到netif_receive_skb()中调用ip_rcv()将skb包传递到IP层时,ip_rcv()函数所处的上下文环境,下面的图列出了所处理的环境(图中只包含获取锁或禁止中断等进入保护区的操作,释放的操作相应地一一对应,不在图中列出):
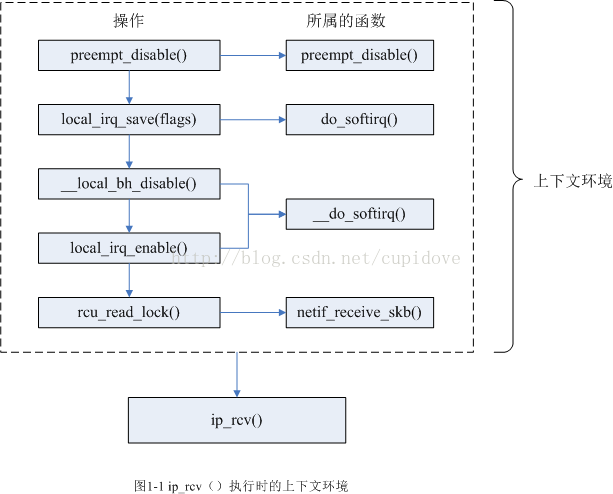
网络层中主要关注IPv4协议,其接收函数时ip_rcv()。ip_rcv()中首先判断skb包是否是发送给本机,如果是发送给其他机器,则直接丢弃,然后检查IP数据包是否是正常的IP包,如果是正常的数据包,则调用ip_rcv_finish()继续处理(忽略钩子的处理),如下所示:
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
......
<span style="white-space:pre"> </span>return NF_HOOK(PF_INET, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
......
}ip_rcv_finish()中首先判断skb包中是否设置路由缓存,如果没有设置,调用ip_route_input()来查找路由项,然后调用dst_input()来处理skb包。在 ip_rcv_finish()函数中也没有类似获取锁或中断相关的同步操作,继续看dst_input()函数。
dst_input()源码如下:
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}其中skb_dst(skb)是获取skb的路由缓存项,如果数据包是发送到本地,input接口会设置为ip_local_deliver();如果需要转发,则设置的是ip_forward()。因为要研究的是传送到传输层时的上下文,因此假设这里设置的ip_local_deliver()。
ip_local_deliver()首先检查是否需要组装分片,如果需要组装分片,则调用ip_defrag()来重新组合各个分片,最后经过钩子处理后,调用ip_local_deliver_finish()来将skb包传递到传输层,如下所示:
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
if (ip_hdr(skb)->frag_off & htons(IP_MF | IP_OFFSET)) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(PF_INET, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}ip_local_deliver()中同样没有使用内核中的同步手段,也就是没有我们关心的上下文环境(获取锁、开启或禁止中断等),接下来就剩下ip_local_deliver_finish()函数了。
ip_local_deliver_finish()中关键代码如下所示:
static int ip_local_deliver_finish(struct sk_buff *skb)
{
......
rcu_read_lock();
{
......
resubmit:
raw = raw_local_deliver(skb, protocol);
hash = protocol & (MAX_INET_PROTOS - 1);
ipprot = rcu_dereference(inet_protos[hash]);
if (ipprot != NULL) {
.......
ret = ipprot->handler(skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
} else {
......
}
}
out:
rcu_read_unlock();
return 0;
}ip_local_deliver_finish()首先根据IP包承载的报文协议类型找到对应的net_protocol实例,然后调用其handler接口。ip_local_deliver_finish()中有我们关心的上下文操作,也就是对rcu_read_lock()的调用。如果是TCP协议,则handler为tcp_v4_rcv()。tcp_v4_rcv()是TCP协议的接收函数,该函数被调用时的上下文就是我们一直在探究的向TCP层传送数据包时的上下文。至此,我们完成了从网络驱动到向TCP传输数据包的过程的梳理,及tcp_v4_rcv()执行时的上下文。
四、总结
tcp_v4_rcv()执行时的上下文,就是在图1-1中所示的ip_rcv()的执行上下文中再添加上rcu_read_lock()(ip_local_deliver_finish()中调用)的处理,上面已经说得很清楚了,就不再画图了。
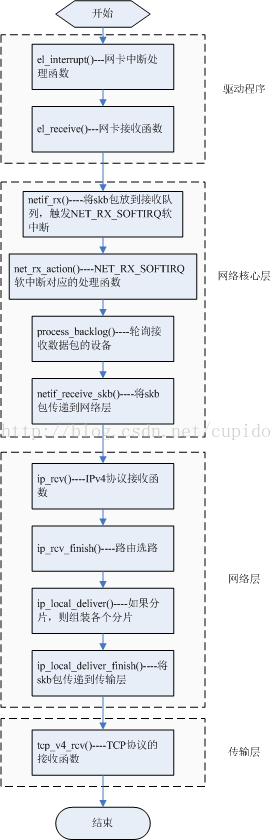
最后把从网卡驱动到TCP层的接收处理的流程列出来,如下图所示:















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









