






概要
本文将懂车帝的选车页面数据进行爬取,包括:车型,价格范围,评分等信息。
一、使用模块
import csv
import json
from typing import Dict, List, Optional
import requests
二、反爬技术
1.字体反爬
反爬虫工程师利用自定义字体,隐藏真实数据
2.js压缩和混淆
对代码进行压缩(去除空格,换行符)和混淆(无意义变量)降低可读性,格式化使得无法定位到数据的真实位置。
3.动态网页
动态网站通过JavaScript异步加载数据,需要查找数据接口,并且请求参数通常被加密参数保护。
三、分析过程
1.判断网站类型
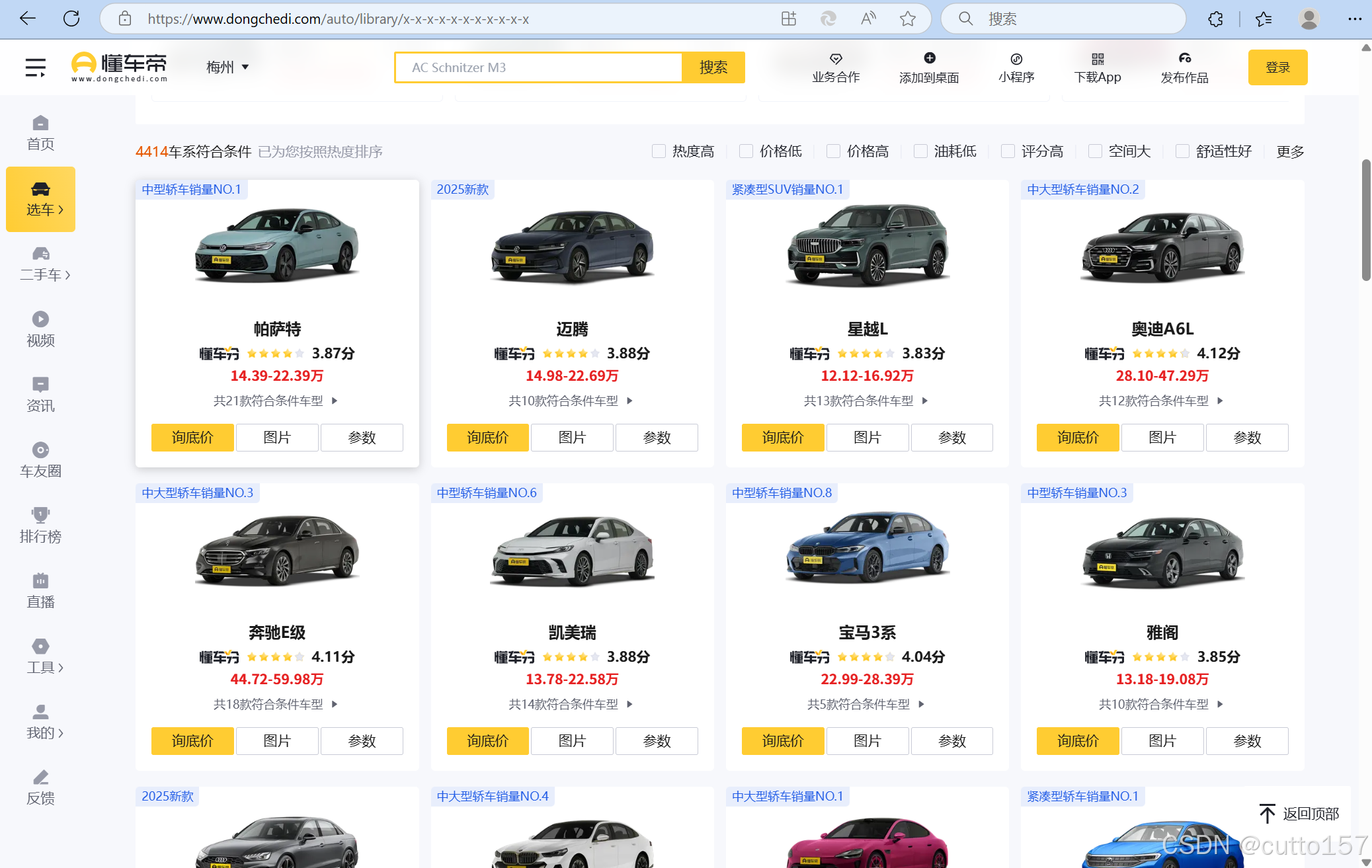
滚动鼠标查看更多汽车的信息,发现刷新新数据,可以判断网站是动态网站,所以猜测数据是json格式
2.监听数据
空白处右键,打开检查面板,选择网络选项卡,查看更多车辆信息,以新车辆信息作为关键词搜索,成功发现车辆数据。
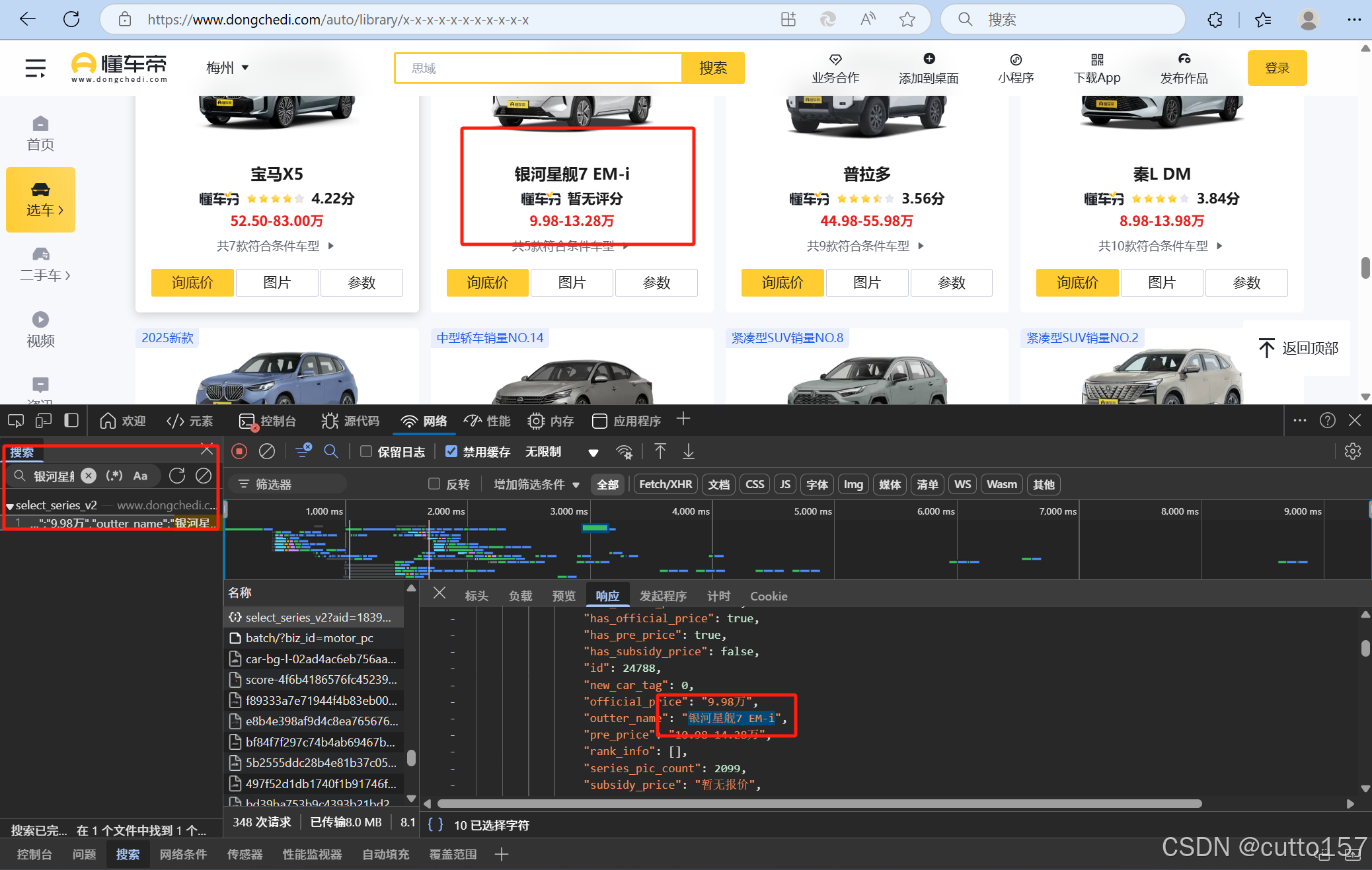
3.请求URL的规律
查看标头,发现发起的post请求
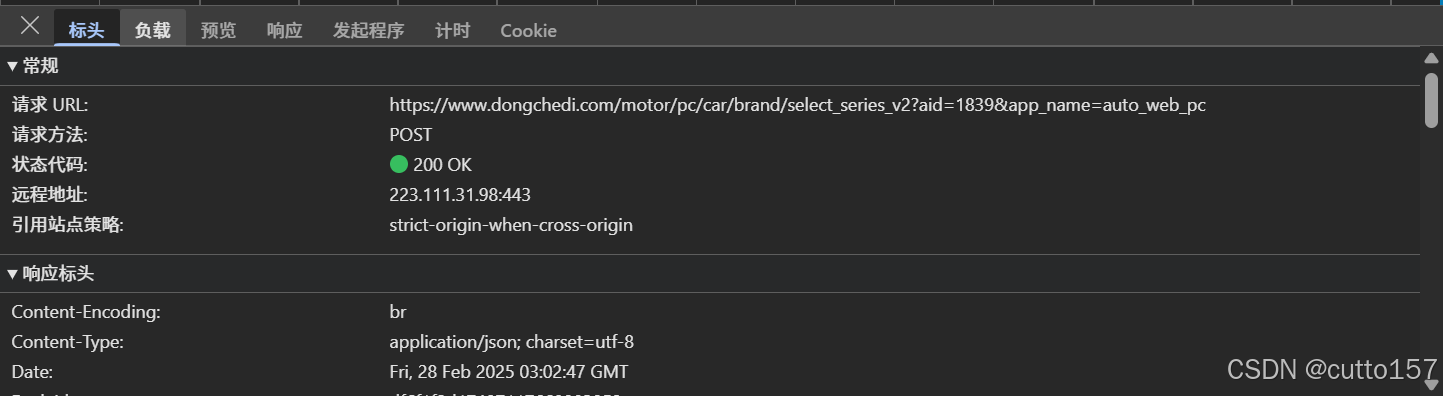
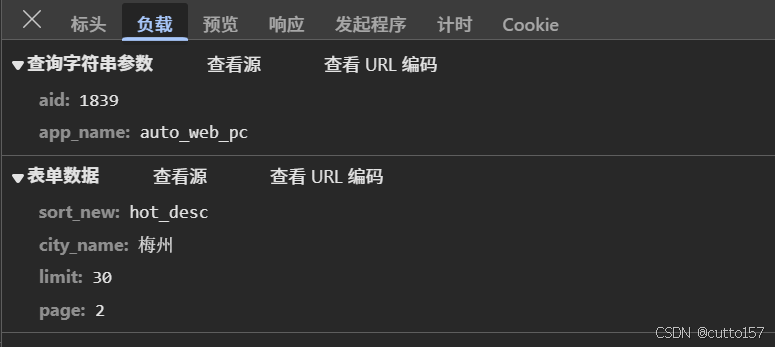
然后查看提交的格式为表单

通过提交表单的内容就可以推导,sort_new是排序方式,city_name是城市位置,limit是限制返回的条数量,page是第n页
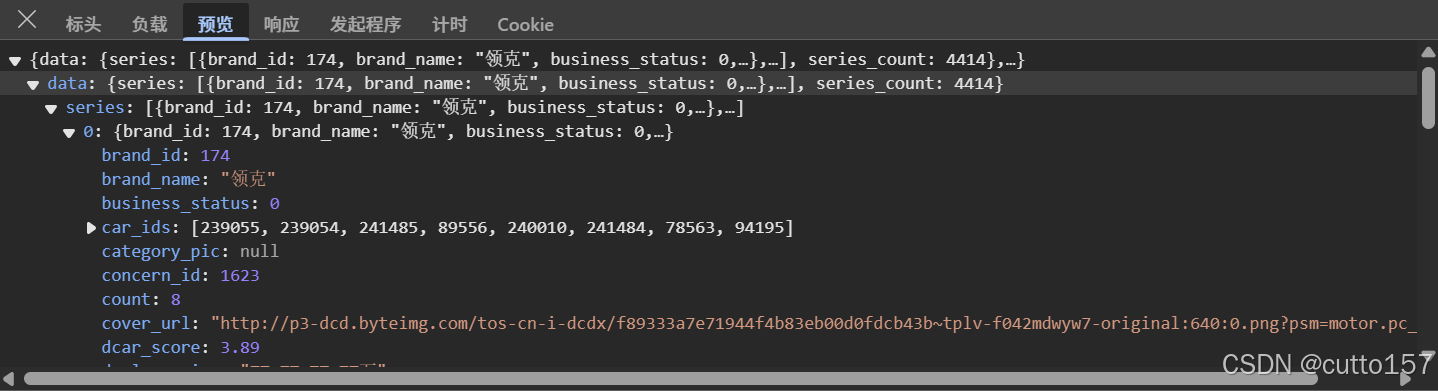
4.查看数据结构
“数据以JSON格式返回,可在开发者工具的‘预览’或‘响应’中查看结构,例如:{\"cars\": [{\"id\": 1, \"name\": \"Toyota\", \"price\": 20000}]}。JSON由键值对组成,通常包含列表或嵌套对象。爬虫中可用Python的json.loads()解析为字典或列表,进一步处理。”
四、完整代码
import csv
import json
from typing import Dict, List, Optional
import requests
# 常量定义
URL = 'https://www.dongchedi.com/motor/pc/car/brand/select_series_v2'
PARAMS = {
'aid': 1839,
'app_name': 'auto_web_pc'
}
FONT_MAP = {
'\\ue420': '0',
'\\ue40d': '1',
'\\ue423': '2',
'\\ue409': '3',
'\\ue41d': '4',
'\\ue427': '5',
'\\ue419': '6',
'\\ue3fd': '7',
'\\ue428': '8',
'\\ue413': '9'
}
def fetch_car_data(page: int) -> Optional[Dict]:
"""获取汽车数据"""
data = {
'sort_new': 'hot_desc',
'city_name': '梅州',
'limit': 30,
'page': page
}
try:
response = requests.post(URL, params=PARAMS, data=data, timeout=10)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"请求第{page}页失败: {e}")
return None
def transform_text(text: Dict) -> Dict:
"""转换加密字体"""
text_str = json.dumps(text)
for key, value in FONT_MAP.items():
text_str = text_str.replace(key, value)
return json.loads(text_str)
def parse_car_data(car_data: Dict) -> List[Dict]:
"""解析汽车数据"""
return [
{
'车型': item.get('outter_name', '未知车型'),
'价格范围': item.get('dealer_price', '价格未知'),
'评分': item.get('dcar_score', '暂无评分')
}
for item in car_data.get('data', {}).get('series', [])
]
def save_to_csv(datas: List[Dict], filename: str = 'car_data.csv') -> None:
"""保存数据到CSV文件"""
if not datas:
return
with open(filename, 'a', encoding='utf-8', newline='') as fp:
writer = csv.DictWriter(fp, fieldnames=['车型', '价格范围', '评分'])
# 如果文件为空,写入表头
if fp.tell() == 0:
writer.writeheader()
writer.writerows(datas)
def main():
"""主函数"""
max_pages = 10
for page in range(1, max_pages + 1):
print(f'正在爬取第{page}页...')
car_data = fetch_car_data(page)
if not car_data:
print('无新数据或请求失败,停止爬取')
break
transformed_data = transform_text(car_data)
car_info_list = parse_car_data(transformed_data)
if car_info_list:
save_to_csv(car_info_list)
print(f'第{page}页保存成功,共{len(car_info_list)}条数据')
else:
print(f'第{page}页无有效数据')
if __name__ == '__main__':
main()
小结
有任何问题,欢迎评论。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









