








CVPR2016
Multi-Cue Zero-Shot Learning with Strong Supervision
zero-shot learning for visual recognition aims at equipping computer vision systems to recognize novel classes without a single training example
这里科普一下什么叫 zero-shot learning ,就是以前训练样本中没见过一个类别的物体,现在希望能够识别出该类别物体。
The required “knowledge” for the recognition task is transferred via auxiliary information of different types. The most successful techniques utilize human annotations of attributes for each class.
这就需要我们使用各种辅助信息迁移到完成该识别问题所需要的“知识”。目前比较成功的策略就是使用人工标记的属性。但是这需要大量的人工来标记,我们坚信最终的zero-shot learning 是可以通过书本和在线文献中的信息来完成的。这些信息已经大量存在。
Our goal is to compensate the loss in performance by using weaker –but more broadly available – auxiliary language information with a stronger visual supervision for classes that we are transferring from.
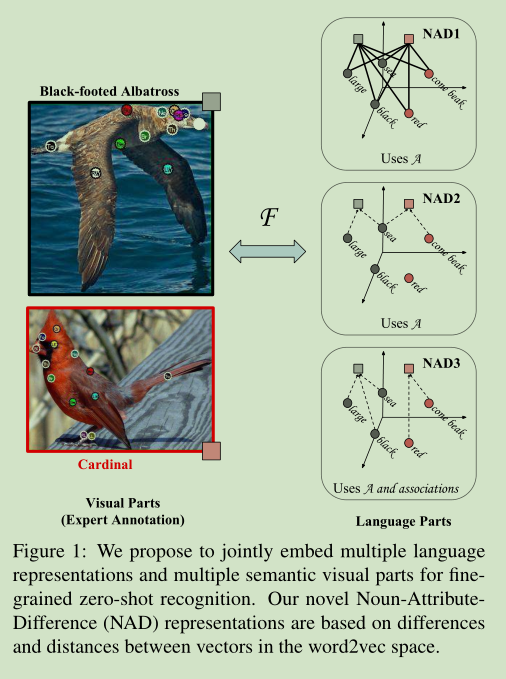
这里我们使用语义辅助信息外加一个较强的 visual supervision (Semantic Visual Parts 图像中显著区域)
3 Zero-Shot Multi-Cue Embeddings
这里主要定义了 目标函数
主要包括两个部分信息,一个是语义信息,一个是图像信息
4 Semantic Visual Parts
这里使用Semantic Visual Parts 图像中显著区域 来作为一个visual supervision 辅助语义信息提高识别率。使用 CNN来提取显著区域。
5 Language Parts
这里可选择的比较多。
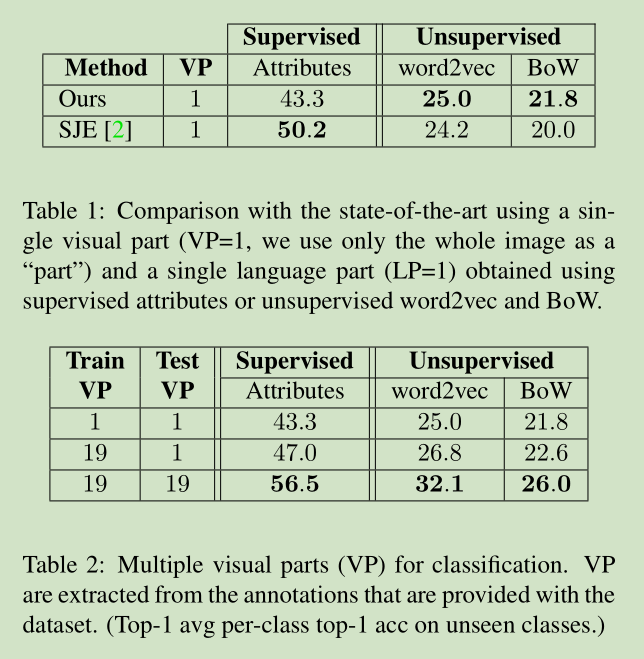
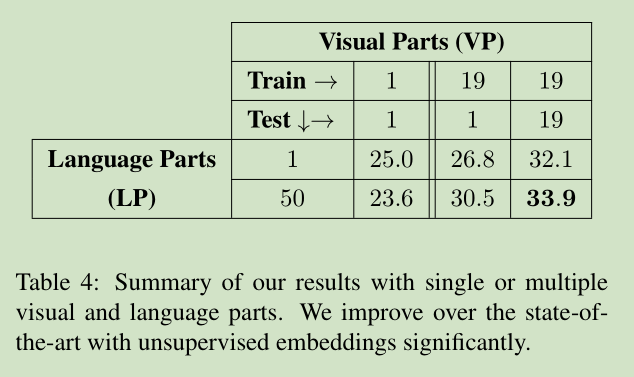
结果就是使用更多的语义信息和更多的显著区域,可以提高准确率。














 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









