










ECCV 2016
The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition
当前 fine-grained recognition的主流方法分两步:1)训练数据的收集和标定,2)模型的训练。本文提出的使用从网络上搜索的含有噪声的数据进行训练,得到很好的效果。
3 Noisy Fine-Grained Data
3.1 Categories
这里我们主要关注四个类别的 fine-grained 识别问题:birds, aircraft, Lepidoptera, and dogs。对于birds 和 Lepidoptera,我们直接从Wikipedia 上获得子类别,10,982类birds 和 14,553 类 Lepidoptera,分别使用 L-Bird 和 L-Butterfly 表示。 对于 aircraft,我们手动建立 409 子类。对于dogs,我们一共建立了 515 子类。我们的测试数据是:CUB-
200-2011 and Birdsnap,分别包含200类和500类鸟, FGVC 100 子类aircraft, Stanford Dogs 有120子类 dogs。
3.2 Images from the Web
我们使用 Google 图像搜索的所有结果图像,对于L-Bird 和L-Butterfly 我们直接使用子类学术名字进行搜索,对于 L-Aircraft and L-Dog 直接使用子类名,例如:“Boeing 737-200” or “Pembroke Welsh Corgi”
Quantifying the Data:有多少子类数据可以获得了?我们绘制了下图
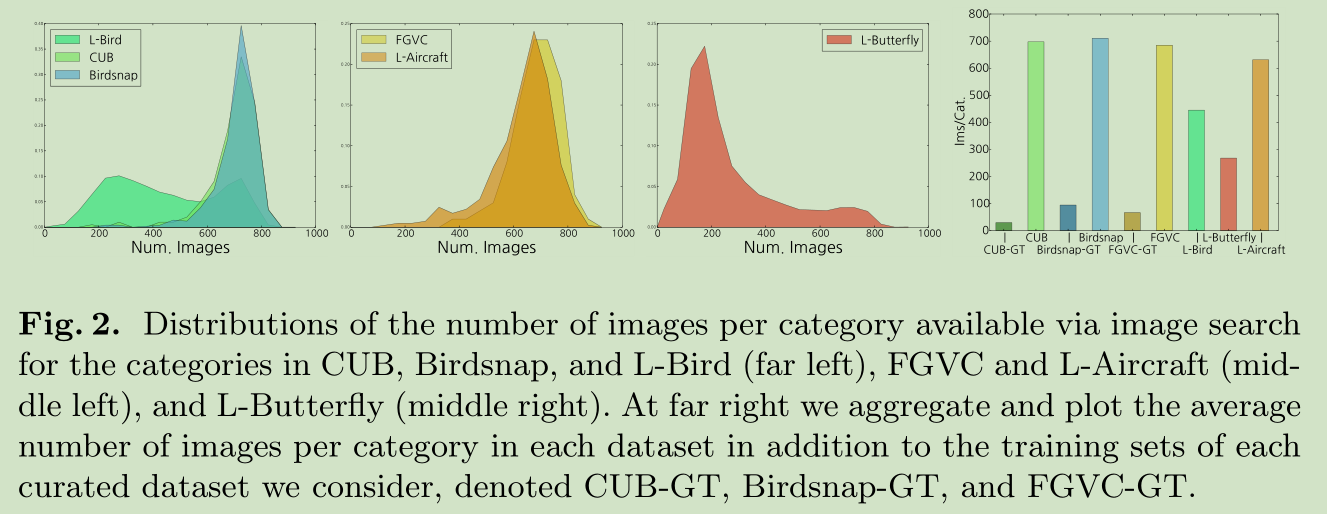
从上图中我们主要以下几点:
1)在现有的数据库中子类的图像数要多于L-Bird, L-Aircraft, or L-Butterfly 中的 long-tail 子类。尤其体现在 L-Bird and L-Butterfly。
2)不同类别的图像数量不一样,L-Bird and L-Aircraft 要明显多于L-Butterfly。更多的人偏好L-Bird and L-Aircraft。
3)图像搜索引擎对于每类之提供 800张图像,即使对于最常见的子类别,这应该是程序限制了数量。
4)当前数据库里的图像和从网上搜索的图像最大的不同是每类图像数目的不同,现存数据库单个类的图像数大约为94.8,大约是 网络搜索数的13%,当然网上搜索的图像含有噪声。
最后,对于四类新建数据库,我们获得 9千8百万张图像,26458类,151.8G硬盘空间。这些数据可以下载: https://github.com/google/goldfinch
Noise:网上搜索得到大量数据,但是这些数据还有噪声,这是个关键性问题。这里我们主要考虑两类噪声: cross-domain noise and cross-category noise
cross-domain noise 它并不含有大类的物体,例如对于 birds类,图像实际上不含有真正的鸟。如下图所示

cross-category noise 对应子类别划分错误,大的类别没问题
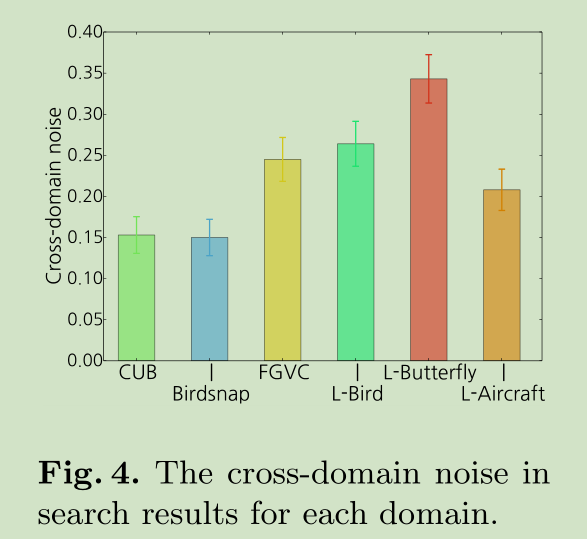
相对于 cross-domain noise,cross-category noise 更加难以量化,因为这需要正确分类。为了简单的分析一下 cross-category noise ,我们给出了一个分类器对 CUB 中30子类中的图像及对应网络搜索的图像 类别预测的 confusion matrix,该分类器我们使用 CUB training set 训练得到。

在这些 confusion matrices中, cross-category noise 主要体现在a strong off-diagonal pattern,而 cross-domain noise 则表现为 diffuse pattern of noise,因为 cross-domain noise 对所有子类都有影响。
这里我们提出了一个简单有效的过滤 cross-category noise 的方法:exclude images that appear in search results for more than one category,即去除那些出现在多个子类中的图像。这一步我们称之为 filtering

经过filtering,我们的数据库变化如下
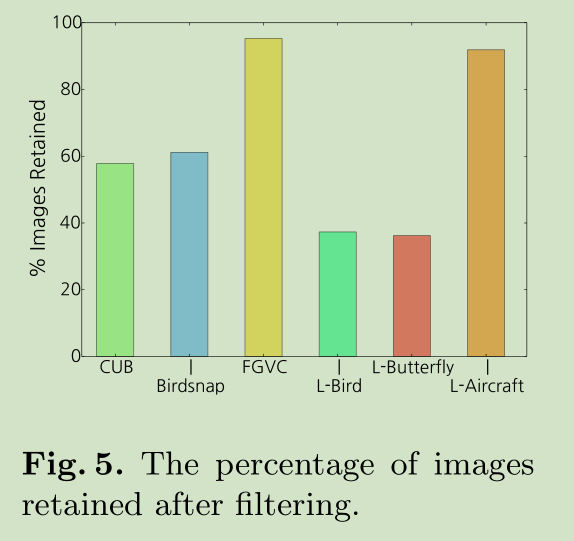
对于cross-domain noise 我们也尝试了一些方法去降低,但是对最后的测试效果影响不明显。可能是测试数据没有 out-of-domain 类
4 Data via Active Learning
这里我们主要简要讨论一下基于Active Learning来收集 大量 fine-grained 数据。Active learning 和其他人在闭环的系统 都被用于建立训练数据库,主要是节约成本。我们这里的主要目的是和直接使用网络收集的噪声数据做个对比,特别是在fine-grained recognition 方面。本文使用 active learning 在 Stanford Dogs 的120子类。
我们 active learning 系统首先在 Stanford Dogs 训练数据上进行训练,然后再人工标定一些数据,再重新训练分类器。我们使用一个卷积网络作为分类器。这里我们主要说说 sample selection and human annotation。
Sample Selection:我们有很多关于 Sample Selection的准则,这里我们采用基于confidence的采样。对于每个类别 c ,我们选择 bP^(c)张图像(按模型识别分数排序),其中P^(c)是先验概率。

Human Annotation:

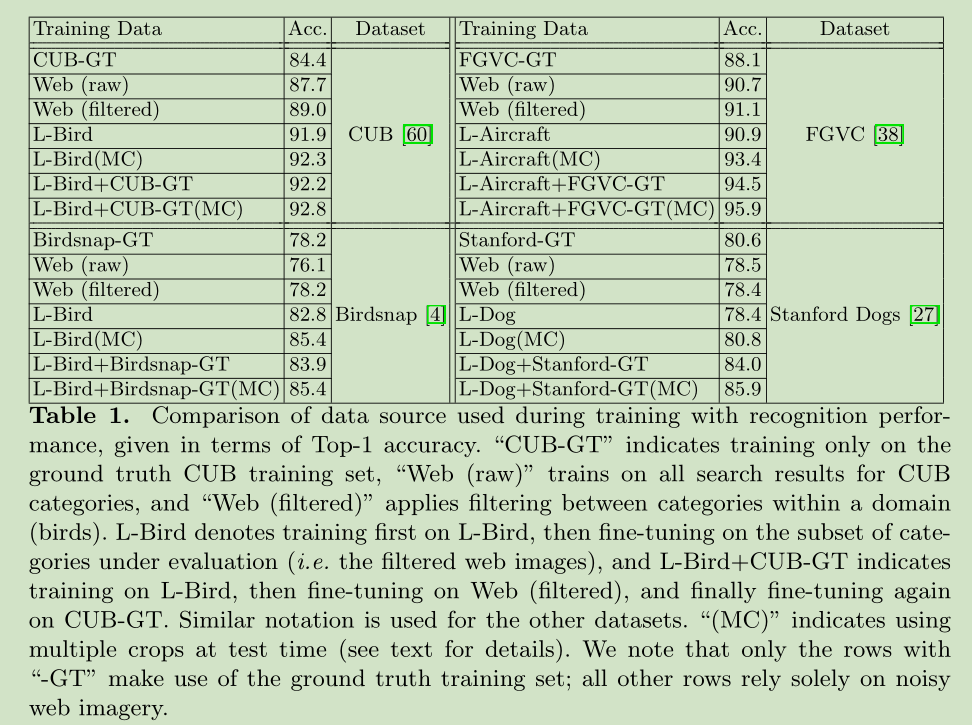
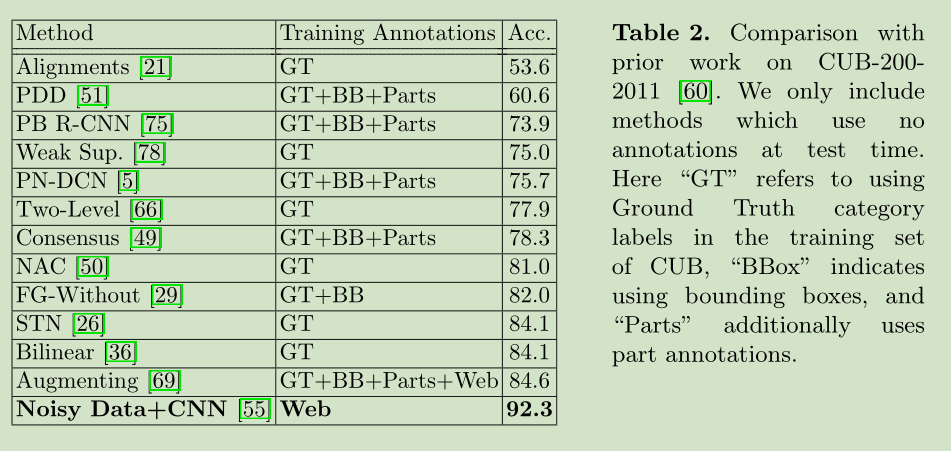
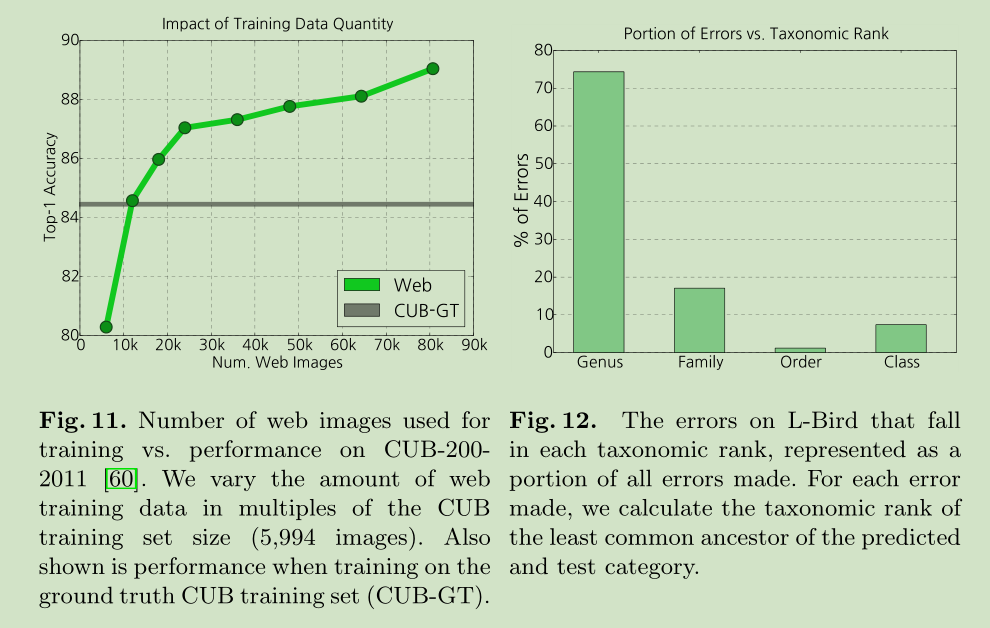
5 Experiments















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









