





mysql计算逐月累加值
如果您需要计算变化(例如上个月对上个月或上个月对一年前的同月),R是一个不错的选择。 进行这些计算很容易-而且您不必担心是否正确单击并拖动了电子表格公式以覆盖所有必要的单元格。
像R中的许多事情一样,有多种方法可以做到这一点。 我将介绍其中的两个。
首先,我将导入有关Bluebikes每日骑车旅行的一些数据, Bluebikes是波士顿,剑桥和附近三个其他城市的自行车共享系统。 如果要继续学习,请下载此CSV数据压缩文件并解压缩。
在下面的代码中,我加载了两个程序包,然后使用读取程序包的read_csv()函数从daily_cycling_trips.csv文件中读取数据。
library(readr)
library(dplyr)
daily_trips <- readr::read_csv("daily_cycling_trips.csv") 在下一个代码块中,我将使用基础R的format()函数向数据添加一个名为YearMonth的新列,以为每个旅程开始日期创建yyyy-mm格式。 接下来是典型的dplyr group_by()和summary summarize()操作。 在这种情况下,我将按YearMonth分组,然后在每个组中创建一个名为MonthlyTrips的列,其中包含该月所有行程的总和。 最后,我确保数据按YearMonth排列。
daily_trips <- daily_trips %>%
mutate(
YearMonth = format(TripStartDate, "%Y-%m")
)
# Usual dplyr group_by() and summarize() by month.
monthly_trips <- daily_trips %>%
group_by(YearMonth) %>%
summarize(
MonthlyTrips = sum(Trips)
) %>%
arrange(YearMonth)计算每月和每年的变化
现在,我已经有了每月的小计,现在可以使用dplyr的lag()函数来计算逐月变化和逐年变化。 lag()默认为数据帧列中的前一个值,因为当前顺序是这样。 您可以更改滞后项的数量,使其超过一个。 与上个月进行比较,默认为1是可以的。 与上一年相比,我希望滞后时间为12,退回12个项目。 请注意,这仅在没有缺失月份的情况下有效。 如果不确定数据的完整性,则可能需要添加一些代码来检查丢失的数据。
使用lag() ,可以设置要排序的列,如果数据框未按所需的方式排序,则可以进行延迟。 (在这种情况下,我不需要,因为YearMonth已经对我的数据进行了排序。)
monthly_report <- monthly_trips %>%
mutate(
MoM = (MonthlyTrips - lag(MonthlyTrips)) / lag(MonthlyTrips),
YoY = (MonthlyTrips - lag(MonthlyTrips, 12)) / lag(MonthlyTrips, 12)
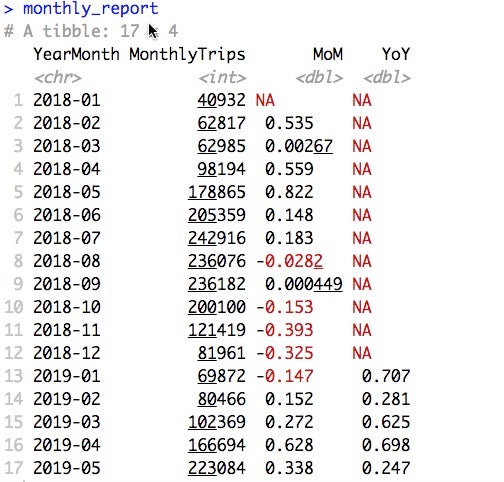
)如果您查看monthly_report对象,那么数据就在那里,尽管格式可能会更好。
 沙龙·马克斯(IDG)
沙龙·马克斯(IDG)
每月报告数据框架,其中包含逐月比较和逐年比较。
下面的代码将分数乘以100以创建百分比格式,然后四舍五入到小数点后一位。
monthly_report <- monthly_report %>%
mutate(
MoM = round(MoM * 100, 1),
YoY = round(YoY * 100, 1)
) 这是每月报告的最简单示例-每月只有一个数据点。 不过,有时候,您每个月都有多个要跟踪的类别,例如按城市,年龄段或网站进行的比较。 对此代码进行调整很容易:您只需在运行dplyr summary summarize()之前按月份对类别进行分组即可。 这是一个例子:
# Read in second data file
daily_trips_by_usertype <- readr::read_csv("daily_cycling_trips_by_usertype.csv")
# Add YearMonth column and get totals by month
monthly_trips_by_usertype <- daily_trips_by_usertype %>%
mutate(
YearMonth = format(TripStartDate, "%Y-%m")
) %>%
group_by(YearMonth, usertype) %>%
summarize(
MonthlyTrips = sum(Trips)
) %>%
arrange(YearMonth, usertype)
# Calculate MoM and YoY
monthly_report_by_usertype <- monthly_trips_by_usertype %>%
group_by(usertype) %>%
mutate(
MoM = (MonthlyTrips - lag(MonthlyTrips)) / lag(MonthlyTrips),
YoY = (MonthlyTrips - lag(MonthlyTrips, 12)) / lag(MonthlyTrips, 12)
)
在上面的代码块中,我正在做与以前相同的事情,只是我按月和用户类型比较行程。 此数据集中有两种类型的用户:客户和订户。 如果运行代码,然后查看monthly_report_by_user_type,您将看到按订阅者和客户用户类型进行的按月比较和按年比较。
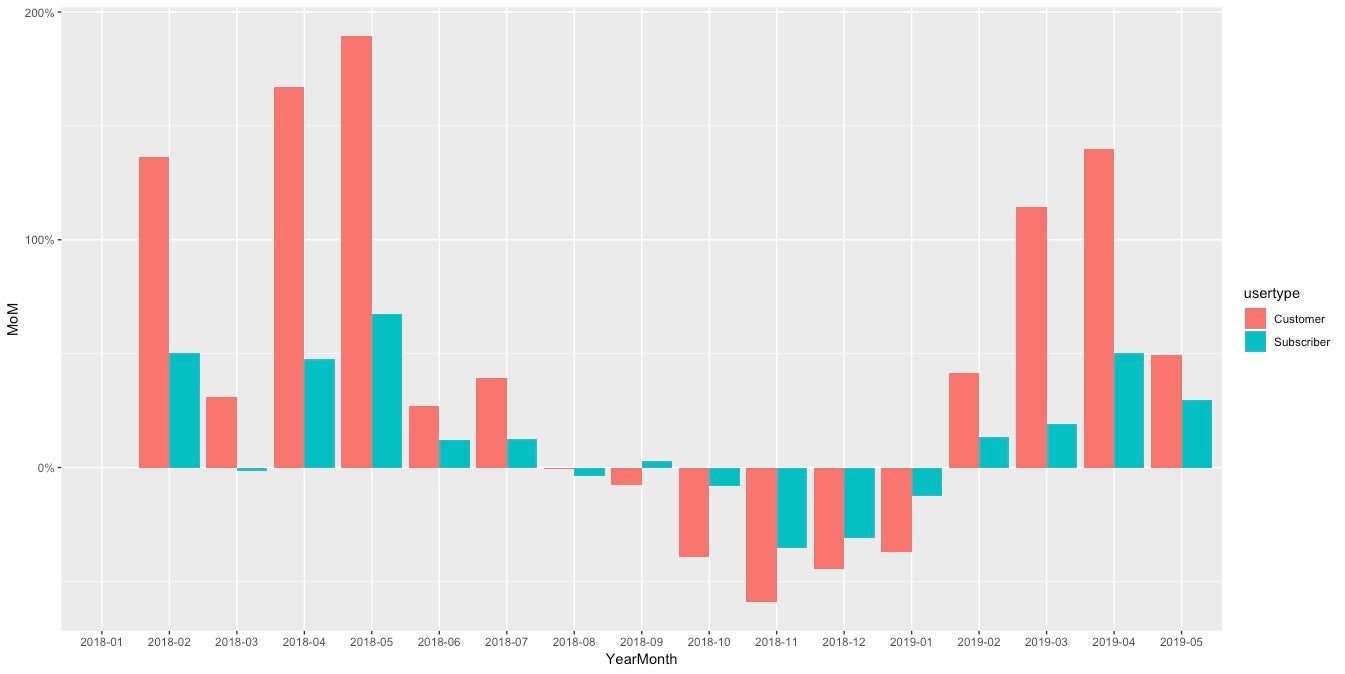
此数据还使使用ggplot2绘制每月百分比变化的图表变得容易。
 沙龙·马克斯(IDG)
沙龙·马克斯(IDG)
bluepike上按客户类型划分的旅行的逐月变化的ggplot2图表。
我没有通过乘以100并舍入来更改数据,而是在下面的ggplot2图形代码中使用了scales包和scale_y_continuous()为我做到了:
library(ggplot2)
library(scales)
ggplot(monthly_report_by_usertype, aes(x=YearMonth, y=MoM, fill=usertype)) +
geom_col(position="dodge") +
scale_y_continuous(labels = scales::percent) 注意:如果只需要特定报告的“上个月”,而不需要每个月的比较,请在报告数据帧上使用dplyr的filter()函数,并将YearMonth列设置为等于该数据的最大值。 例如:
filter(monthly_report_by_usertype, YearMonth == max(YearMonth))每周计算
每周与每月略有不同。 对于每周,我通常使用每周的开始日期,而不是像yyyy-ww这样的格式。 这是因为在一年的开始和结束时只有几周的时间,使用数周的数字会变得很复杂。
在下面的代码中,我使用lubridate包及其floor_date()函数。 您可以改用基R的cut.Date()函数,但这要复杂一些,因为它返回的是因子而不是日期。 (使用cut.Date()我通常最终会运行一些额外的代码以将这些因素转换为日期floor_date()是我想要的第一步。)
接下来是通常的计算,这一次是一周中的一周,也是一年中的一年。 请注意,与去年同期相比,滞后是52,而不是12。在这里重要的是要确保我每周也有行。
# install.packages("lubridate")
library(lubridate)
weekly_trips <- daily_trips %>%
mutate(
WeekStarting = floor_date(TripStartDate, unit = "weeks")
) %>%
group_by(WeekStarting) %>%
summarize(
WeeklyTrips = sum(Trips)
) %>%
arrange(WeekStarting)
weekly_report <- weekly_trips %>%
mutate(
WoW = (WeeklyTrips - lag(WeeklyTrips)) / lag(WeeklyTrips),
YoY = (WeeklyTrips - lag(WeeklyTrips, 52)) / lag(WeeklyTrips, 52)
)现在,您可能在想:好的,很简单,但是要输入简单的每周或每月报告,需要进行很多输入。 要简化此过程,请制作一个RStudio代码段! 如果您不知道它们是如何工作的,请查看代码段中的“用R做更多”插曲 。
这是我制作月度报告的摘要。 请记住,每条缩进的行都需要用制表符缩进,而不仅仅是空格,并且该代码段需要存在于您的RStudio代码段文件中,您可以使用usethis::edit_rstudio_snippets()进行访问。
snippet my_monthly_reports
monthly_report <- ${1:mydf} %>%
mutate(
YearMonth = format(${2:MyDateColumn}, "%Y-%m")
) %>%
group_by(YearMonth, ${3:MyCategory}) %>%
summarize(
MonthlyTotal = sum(${4:MyValueColumn})
) %>%
arrange(YearMonth, ${3:MyCategory}) %>%
ungroup() %>%
group_by(${3:MyCategory}) %>%
mutate(
MoM = (MonthlyTotal - lag(MonthlyTotal)) / lag(MonthlyTotal),
YoY = (MonthlyTotal - lag(MonthlyTotal, 12)) / lag(MonthlyTotal, 12)
)您可以在本文顶部的嵌入式视频中查看该片段的工作方式。
设置代码段后,在R中进行逐月比较甚至比在Excel中更快。
有关R的更多技巧,请访问InfoWorld上的“用R做更多 ”页面或YouTube上的“用R做更多”播放列表 。
翻译自: https://www.infoworld.com/article/3404276/how-to-calculate-month-over-month-changes-in-r.html
mysql计算逐月累加值















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









