





机器学习是我们未来最重要的技术之一。 无人驾驶汽车,语音控制扬声器和面部检测软件均基于机器学习技术和框架构建。 作为软件开发人员,您可能想知道这将如何影响您的日常工作,包括您应该学习的工具和框架。 如果您正在阅读本文,我想您已经决定学习有关机器学习的更多信息。
在我的上一篇文章“ Java开发人员的机器学习 ”中,我介绍了Java开发人员如何设置机器学习算法并使用Java开发简单的预测功能。 尽管Java的生态系统包括许多用于机器学习的工具和框架,但Python已成为该领域最受欢迎的语言。 图1显示了最近的Google趋势查询的结果,该查询将搜索词“机器学习”与“ Python”,“ Java”和“ R”组合在一起。 尽管从统计的角度来看,该图并不可靠,但它确实使我们能够直观地了解Python在机器学习中的普及程度。
 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图1.机器学习语言的流行度(2019年1月)
在本文中,您将了解为什么Python在机器学习和涉及数据科学的其他用途方面特别成功 。 我将简要介绍数据科学家和软件工程师用于机器学习的一些基于Python的工具,并提出几种将Python集成到您的机器学习开发过程中的方法-从利用Java后端的混合环境到基于Python的解决方案在云,容器等中。
获取代码
获取此Python机器学习入门的源代码 ,包括本文中未找到的示例。
机器学习的用例
首先,让我们回顾一下我先前对机器学习的介绍中的用例。 假设您正在为大型跨国房地产公司Better Home Inc.工作。为了支持其代理商,该公司使用了第三方软件系统以及定制开发的核心系统。 该系统建立在海量数据库的顶部,该数据库包含有关已售房屋,售价和可用房屋描述的历史数据。 该数据库由内部和外部资源不断更新,并用于管理销售以及估计待售物业的市场价值。
代理可以输入诸如房屋大小,建造年份,位置等特征,以接收估计的销售价格。 在内部,此函数使用机器学习模型(本质上是模型参数的数学表达式)来计算预测。 (有关机器学习算法以及如何在Java中进行开发和使用的详细说明,请参阅我的前一篇文章。)
清单1.基于线性回归的机器学习模型
double predictPrice(double[] houseFeatures) {
// mathematical expression (here linear regression)
double price = this.modelParams[0] * 1 +
this.modelParams[1] * houseFeatures[0] +
this.modelParams[2] * houseFeatures[1] +
...;
return price;
}
在清单1中,使用线性回归算法实现了机器学习模型,该算法在机器学习中非常流行。 该算法将模型参数与给定属性的特征参数相乘,然后求和。 如机器学习中的典型操作,训练过程确定要用于模型的参数值。 这种方法称为监督学习 。
监督学习包括提供一个带有示例记录的系统,然后对其进行分析以进行相关性分析。 在这种情况下,系统会收到已用销售价格标记的房屋历史记录特征。 该模型寻找对销售价格有一定影响的要素之间的相关性以及这些关系的权重。 然后基于识别出的相关性和权重调整模型参数。 这就是机器学习模型如何“学习”估计给定房屋的价格的方式。
清单2.训练模型参数
void train(double[] houseFeatures, double[] pricesOfSale) {
// .. find hidden structures and determine the
// proper model parameters
this.modelParams = ...
}
机器学习的挑战
尽管代码示例看起来很简单,但挑战在于找到并训练适当的算法。 与相对简单的线性回归相反,大多数用于机器学习的算法更为复杂。 许多机器学习算法都需要其他(超级)参数,这需要对算法背后的数学有更深入的了解。
另一个挑战是寻找和选择合适的训练数据。 必须收集和理解数据记录,并且收集记录并不总是那么容易。 为了构建和训练价格预测模型,必须首先找到大量已售房屋记录。 为了有用,您不仅需要售价,还需要其他有助于定义每座房屋价值的功能。 在许多情况下,这意味着从外部和内部数据源进行导入和合并。 例如,您可以从存储销售交易记录的内部数据库中获取房屋特征以及销售价格。 对于其他特征,您可以调用外部合作伙伴API,这些API提供有关给定社区的交通基础设施或收入水平的信息。
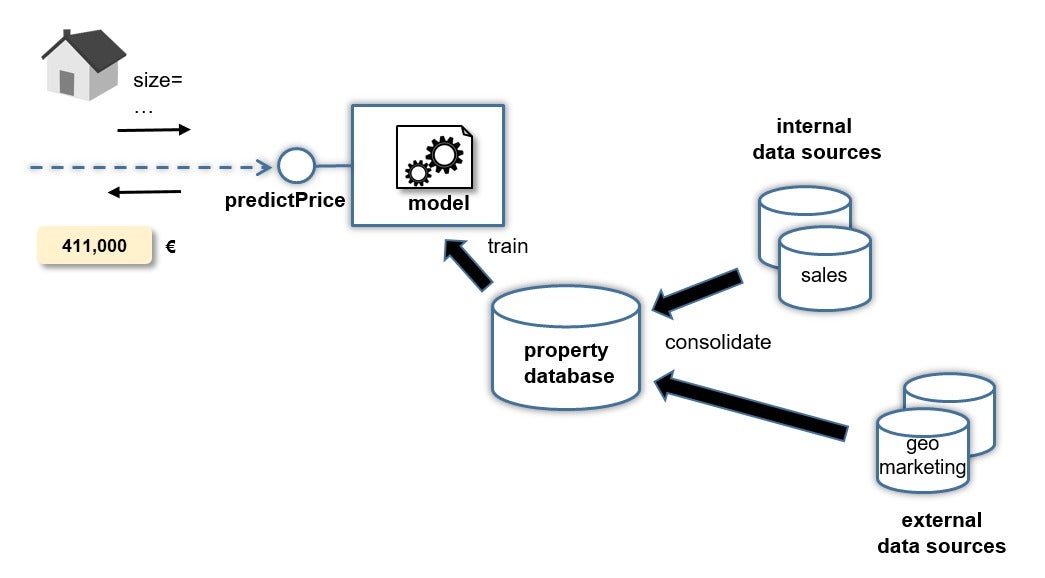 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图2.获取和合并数据
机器学习是一个科学过程
开发机器学习模型更类似于科学过程,而不是传统计算机编程。 科学过程始于问题或观察。 例如,您可能会观察到Better Home Inc.的高级房地产经纪人非常擅长估算房屋的市场价格。 通过采访这些代理商,您会发现他们能够快速枚举确定房屋市场价值的功能。 此外,他们非常了解不同城市和地区的市场状况。 根据此观察结果,您可以得出结论,任何人都可以通过将历史销售数据与该物业的主要特征相结合来确定房屋的市场价格。 使用此数据,您可以开发一个能够估计房屋售价的机器学习模型。 此功能对公司来说很有价值,因为它将使经验不足的代理商能够确定新报价的预期销售价格。
为了测试您的论文,您将需要获取并浏览所选的数据集。 此时,您正在寻求数据结构的概述 。 为了获得此概述,您可能会使用Tableau , KNIME和Weka之类的工具 ,甚至使用Python Data Analysis Library(pandas)或matplotlib之类的简单库。 在尝试构建机器学习模型之前,您还需要通过处理无效或缺失的值来准备数据记录。 建立模型后,您将需要测试和验证它们,以便知道您的假设是对还是错。 例如,您可能会验证Better Home Inc.的机器学习模型是否能够估算房屋的适当售价。 通常,数据探索,分析,清理和验证是机器学习中最耗时的活动。
数据科学家的作用
数据科学家经常负责机器学习过程的主要任务。 大多数数据科学家都有数学和统计学的背景,但他们通常也精通编程和数据建模技能。 数据科学家通常对数据挖掘技术有深刻的了解,这有助于他们理解和选择数据源,并从数据中获取见识。 仔细的数据分析可帮助团队为给定用例选择适当的机器学习算法。
与包括企业Java开发人员在内的传统软件工程师相比,数据科学家更加专注于数据和数据中的隐藏模式。 数据科学家通常使用由传统软件工程师实现的计算环境和数据平台来开发,训练和处理机器学习模型。
基于Python的数据分析工具
了解数据科学家在机器学习中的作用有助于我们理解为什么Python是该领域的首选语言。 与传统软件工程师不同,大多数数据科学家更喜欢使用Python作为编程语言。 这是因为数据科学家通常更靠近广泛使用R和Python的科研社区。 此外,这些社区已经开发了基于Python的科学库,这些库使开发机器学习模型变得更加容易。 现在,有一个不断增长的基于Python的工具生态系统专门用于机器学习。 这个生态系统包括Jupyter Notebook ,它是一个基于Web的交互式Python外壳,它是数据科学领域中的当前事实上的标准。
Jupyter Notebook:用于可视化数据分析的Web界面
Jupyter Notebook通过基于Web的用户界面和一些增强的可视化功能扩展了命令行Python解释器。 它将代码和输出集成到单个Web文档中,该Web文档将代码,说明性文本和可视化效果结合在一起。 输出的内联绘图可以立即进行数据可视化以及迭代开发和分析。 笔记本用于浏览数据以及开发,训练和测试机器学习模型。 例如,为Better Home Inc.工作的数据科学家可能会使用笔记本来加载和浏览可用的房屋数据集,如图3所示。
 格里戈尔·罗斯(Gregor Roth)
格里戈尔·罗斯(Gregor Roth)
图3.使用Jupyter Notebook探索数据
Jupyter中的笔记本由输入单元格和输出单元格组成。 可编辑的输入单元格包含通用的Python代码,可通过按组合键Ctrl + Enter来执行。 在图3所示的笔记本中,第二个输入单元用于将houses.csv文件加载到pandas数据houses.csv 。 数据框提供实用程序,以直观的方式处理和可视化数据。 笔记本的第三个单元格包含一个数据框,用于绘制房屋价格随时间的直方图。
数据科学家使用直方图以及其他图表和可视化效果来理解数据,并识别数据中的异常值和不一致之处。 识别不一致和异常值很重要,因为它使您可以在数据准备过程中进行分类和解决。 此过程最终会产生干净的数据集,您可以使用这些数据集来开发可靠的机器学习模型。 您可以使用数据集来确定与最终售价最相关的功能或房屋属性。 这些功能将定义您的机器学习模型。 大多数算法不够智能,无法自动从整个数据集中提取有意义的特征,而且如果要分析的特征太多,大多数算法将无法正常工作。
Scikit-learn:先进的机器学习算法库
我在基于Java的机器学习简介中解释了逻辑回归算法需要数值。 对于这种机器学习模型,必须将所有字符串或类别值都转换为数字值。 转换过程是在特征提取期间完成的。 提取特征的一种方法是开发一种专用功能,该功能将房屋记录的原始输入转换为算法可以理解的矢量化表示形式。
下面是用Python编写的简化的extract_core_features()方法。 如果您不熟悉Python,请不要对self参数感到困惑。 在Python中,每个非静态方法定义的第一个参数始终是对该类当前实例的引用。 在调用方,此参数将通过执行方法自动传递。
科学家编写的机器学习代码的很大一部分用于特征提取。 例如,在自然语言处理领域,需要几个非平凡的转换步骤才能将人类文本转换为矢量化形式。
翻译自: https://www.infoworld.com/article/3322898/machine-learning-with-python-an-introduction.html















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









