






6 个优秀的开源 OCR 光学字符识别工具
纸张在许多地方已日益失宠,无纸化办公谈论40多年,办公环境正限制纸山的生成。而过去几年,无纸化办公的概念发生了显着的转变。在计算机软件的帮助 下,包含大量重要管理数据和资讯的文档可以更方便的以电子形式储存。扫描文档的好处不纯粹是存档理由。为了访问基于纸张的信息和将信息整合进数字工作流, 光学字符识别(OCR)技术至关重要。选择正确的OCR工具要基于特定需求而定,例如在线OCR服务对某些人有用,但可能存在隐私问题和文件大小限制。 OCR软件非大众产品,因此开源替代相对于商业级重量级产品相对较少,再加上OCR软件需要先进的算法将扫描的图像正确翻译成实际的文字,而图像不仅仅含 有文字,它还包含布局、图形和表格,可能会跨越多页。
优秀的开源OCR软件包括:
原本由惠普开发的图像识别类库tesseract-ocr已经更新到2.04, 就是最近Google支持的那个OCR。原先是惠普写的,现在Open source了。
Ocropus的(TM)是一个先进的文件分析和OCR系统,采用可插入的布局分析,可插入的字符识别,自然语言统计建模和多语言支持功能。
Cuneiform 是一个 OCR 文字识别系统的商标,最开始是由Cognitive 技术所开发的运行在 Windows 下的软件。而这个项目是该软件在 Linux 系统下的移植版本。
GOCR 是一个开源的OCR光学识别程序。

OCRFeeder 是 GNOME 桌面下的一个开源 OCR 套件。可将纸质或者图形文档转成电子文档。

linux-intelligent-ocr-solution (Lios) 是Linux下一个开源的 OCR 解决方案,可将打印的文档转成可编辑的文本。

Tesseract-OCR引擎 入门
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。当前版本为3.01.
项目地址为:http://code.google.com/p/tesseract-ocr
Windows 命令行使用Tesseract-OCR引擎识别验证码:
1、下载安装Tesseract-OCR引擎(3.0版本+才支持中文识别)
tesseract-ocr-setup-3.01-1.exe
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:
附录:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
如果想能识别中文,可以到http://code.google.com/p/tesseract-ocr/downloads/list下载对应的语言的字库文件.
简体中文字库文件下载地址为:http://tesseract-ocr.googlecode.com/files/chi_sim.traineddata.gz 下载完成后解压,然后将该文件剪切到tessdata目录下去就可以了。
2、使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:
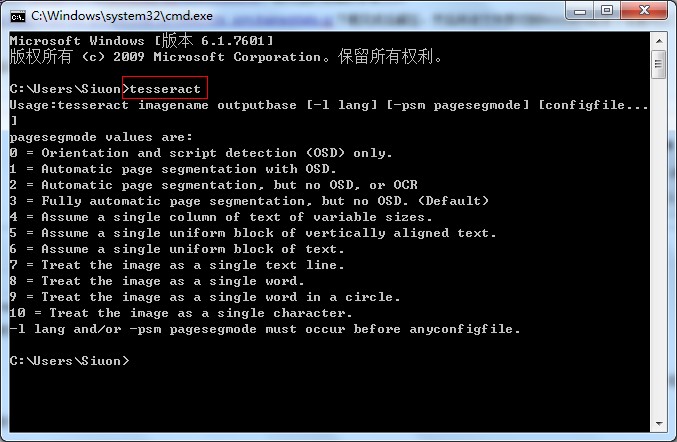
如果出现如上输出,表示安装正常。
我准备了一张验证码code.jpg放在D盘根目录下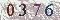 ,上图:
,上图:
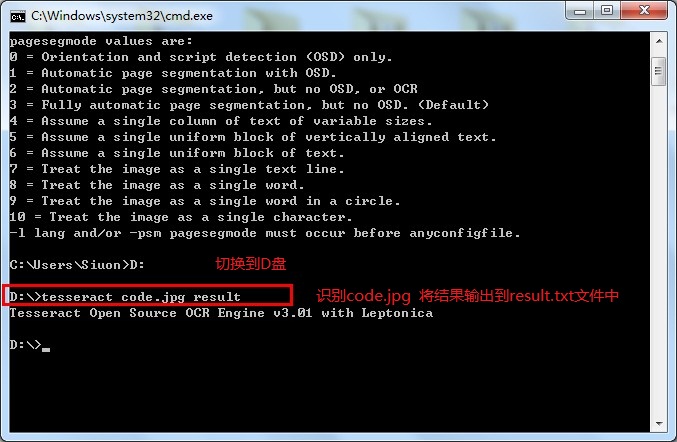
结果为:
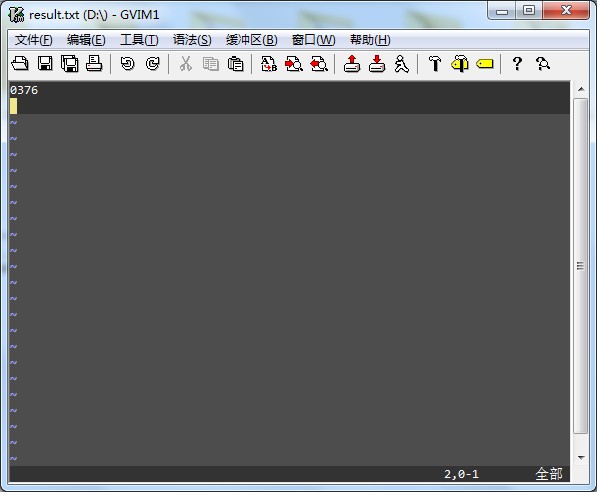
附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
=========================================
http://leadtools.gcpowertools.com.cn/products/ocr/?utm_source=baidu&utm_medium=cpc&utm_term=OCR&utm_content=OCR&utm_campaign=LeadTools
==========================
http://baike.baidu.com/link?url=XB5sh1UCsLn__HNvGtOD-_UG6WZ9obLLKeEfduC8xWIms4ZvZ0eRZUKS3_BC29p309toupxo64w5yMAPy85GIa
http://alice.pandorabots.com/















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









