






本篇文章给大家介绍的是Python爬虫之lxml-etree和xpath的结合使用(附案例),内容很详细,希望可以帮助到大家。
lxml:python 的HTML/XML的解析器
官网文档:https://lxml.de/
使用前,需要安装安 lxml 包
功能:
1.解析HTML:使用 etree.HTML(text) 将字符串格式的 html 片段解析成 html 文档
2.读取xml文件
3.etree和XPath 配合使用
lxml 的安装
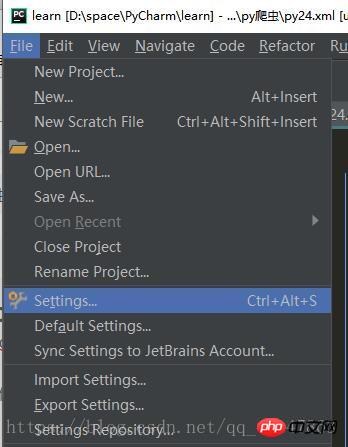
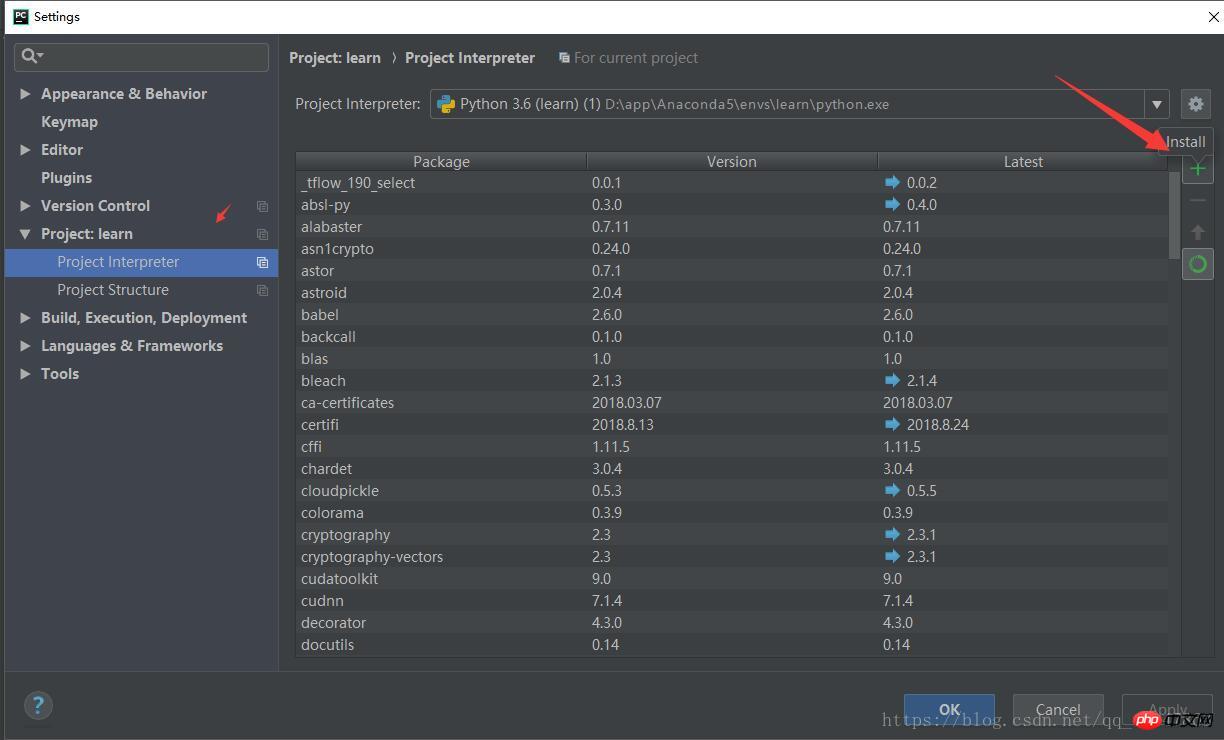
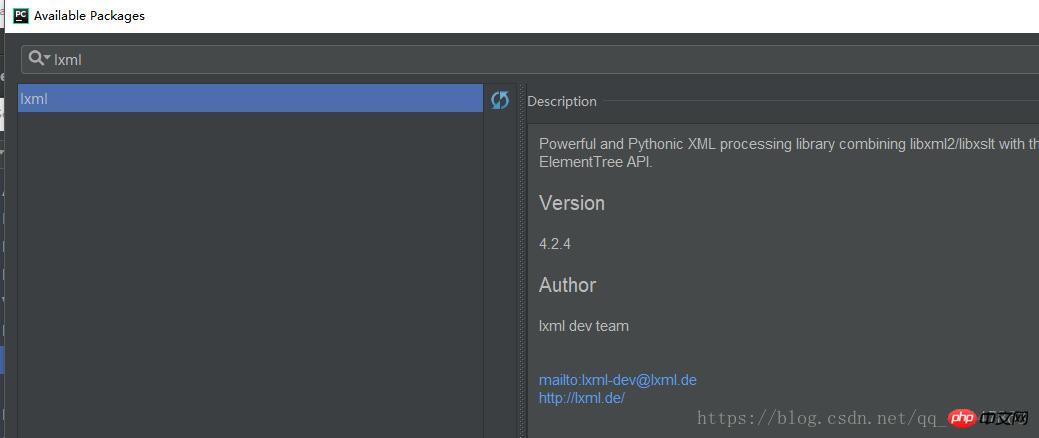
【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【lxml】>【install】
具体操作截图:
lxml-etree 的使用
-
案例v25文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py25etree.py
-
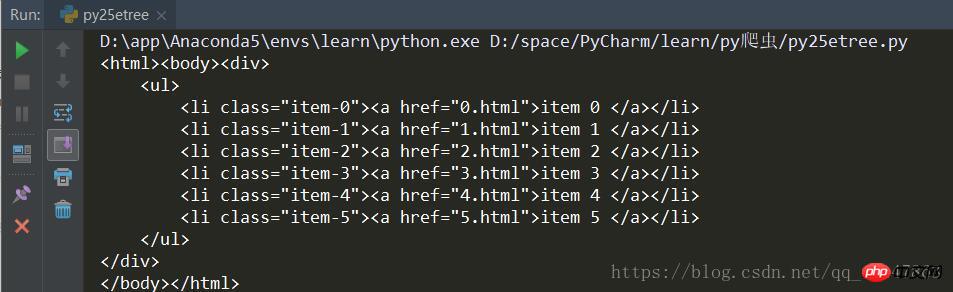
用 lxml 来解析HTML代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
运行结果
lxml-etree 的使用
-
案例v26etree2文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py26etree2.py
-
读取xml文件:
| 1 2 3 4 5 6 |
|
运行结果

etree和XPath 配合使用
-
案例v26expath.文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py26expath.py
-
etree和XPath 配合使用:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
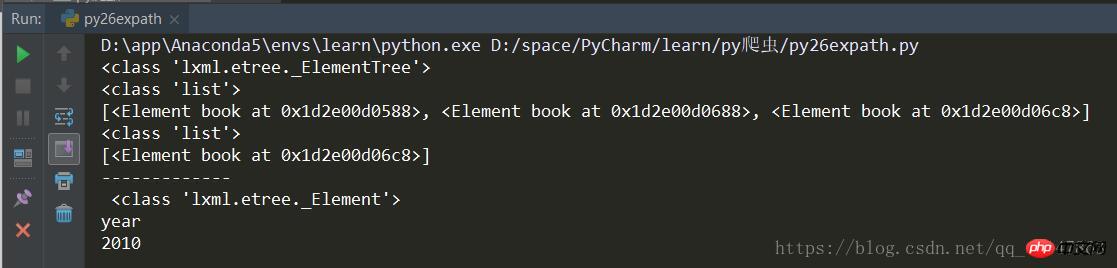
运行结果
etree和XPath 配合使用结果
相关推荐:
以上就是Python爬虫之lxml-etree和xpath的结合使用(附案例)的详细内容,更多请关注php中文网其它相关文章!















 2431
2431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









