






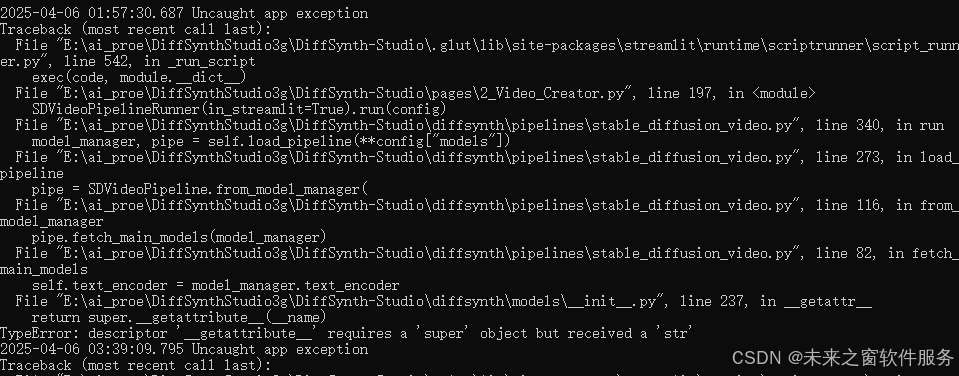
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\.glut\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 542, in _run_script
exec(code, module.__dict__)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\pages\2_Video_Creator.py", line 197, in <module>
SDVideoPipelineRunner(in_streamlit=True).run(config)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 340, in run
model_manager, pipe = self.load_pipeline(**config["models"])
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 273, in load_pipeline
pipe = SDVideoPipeline.from_model_manager(
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 116, in from_model_manager
pipe.fetch_main_models(model_manager)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 82, in fetch_main_models
self.text_encoder = model_manager.text_encoder
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\models\__init__.py", line 237, in __getattr__
return super.__getattribute__(__name)
TypeError: descriptor '__getattribute__' requires a 'super' object but received a 'str'
2025-04-06 03:39:09.795 Uncaught app exception解释:需要一个模型,但是你没有
ypeError: descriptor '__getattribute__' requires a 'super' object but received a 'str'
开始下载模型
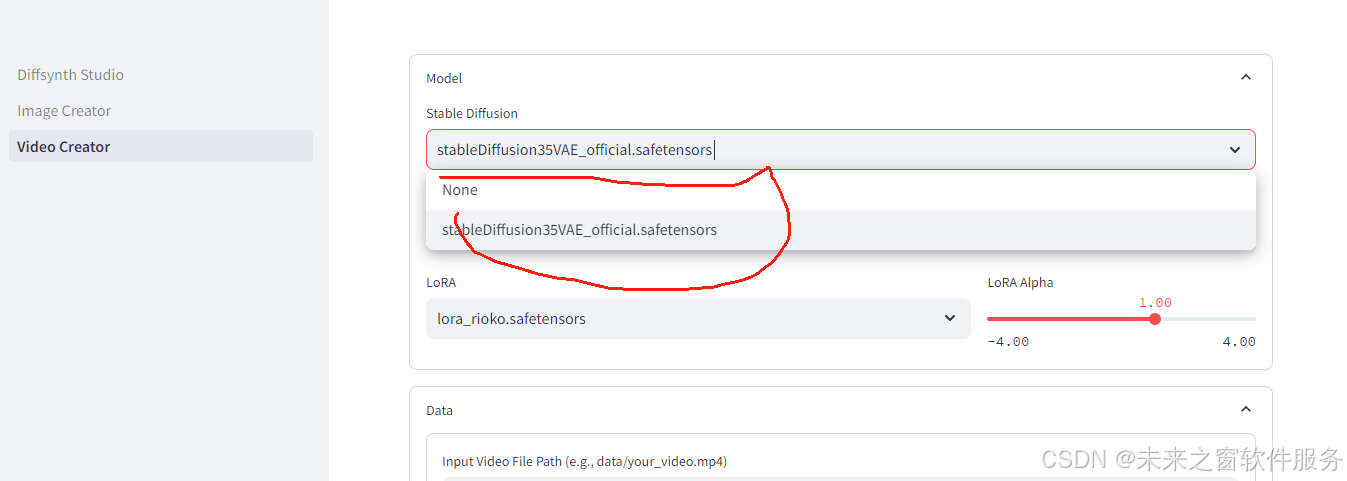
继续运行
aceback (most recent call last):
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\.glut\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 542, in _run_script
exec(code, module.__dict__)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\pages\2_Video_Creator.py", line 197, in <module>
SDVideoPipelineRunner(in_streamlit=True).run(config)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 340, in run
model_manager, pipe = self.load_pipeline(**config["models"])
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 272, in load_pipeline
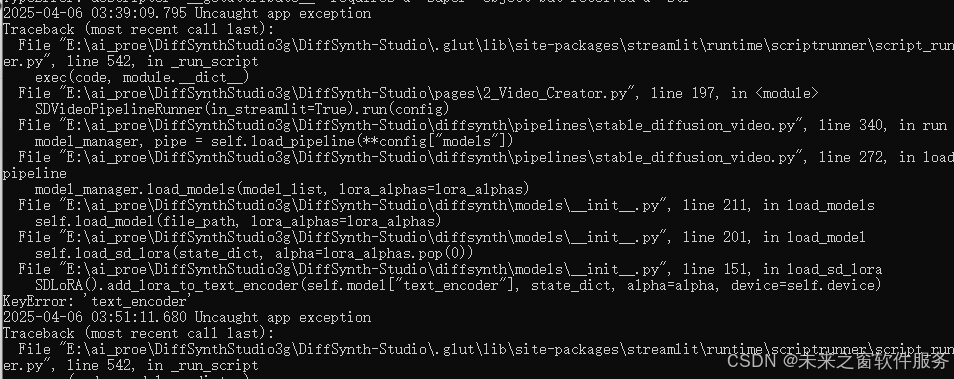
model_manager.load_models(model_list, lora_alphas=lora_alphas)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\models\__init__.py", line 211, in load_models
self.load_model(file_path, lora_alphas=lora_alphas)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\models\__init__.py", line 201, in load_model
self.load_sd_lora(state_dict, alpha=lora_alphas.pop(0))
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\models\__init__.py", line 151, in load_sd_lora
SDLoRA().add_lora_to_text_encoder(self.model["text_encoder"], state_dict, alpha=alpha, device=self.device)
KeyError: 'text_encoder'
解释历史lora错误
model_manager.load_models(model_list, lora_alphas=lora_alphas)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\models\__init__.py", line 211, in load_models
self.load_model(file_path, lora_alphas=lora_alphas)
修改源码显示加载模型,方便定位出问题模型
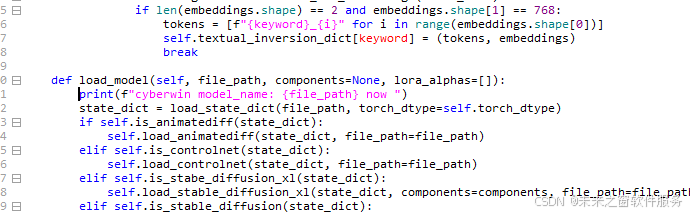
所在路径diffsynth\models\__init__.py 191行
def load_model(self, file_path, components=None, lora_alphas=[]):
print(f"未来之窗 cyberwin model_name: {file_path} now ")
state_dict = load_state_dict(file_path, torch_dtype=self.torch_dtype)
if self.is_animatediff(state_dict):再次运行视频制作
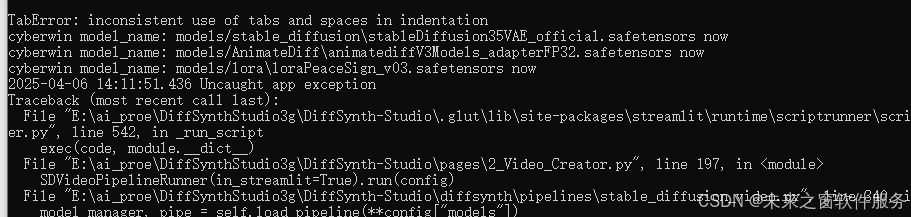
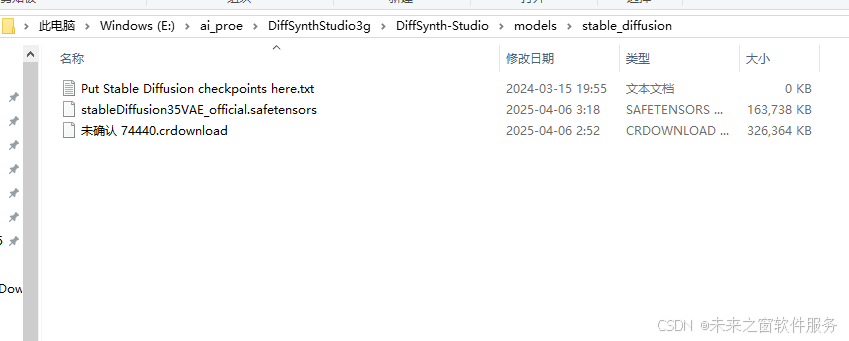
cyberwin model_name: models/stable_diffusion\stableDiffusion35VAE_official.safetensors now
cyberwin model_name: models/AnimateDiff\animatediffV3Models_adapterFP32.safetensors now
cyberwin model_name: models/lora\loraPeaceSign_v03.safetensors now
2025-04-06 14:11:51.436 Uncaught app exception
Traceback (most recent call last):解释模型 stableDiffusion35VAE_official 正常 animatediffV3Models_adapterFP32
loraPeaceSign_v03 但是lora错误了
立即更换lora模型
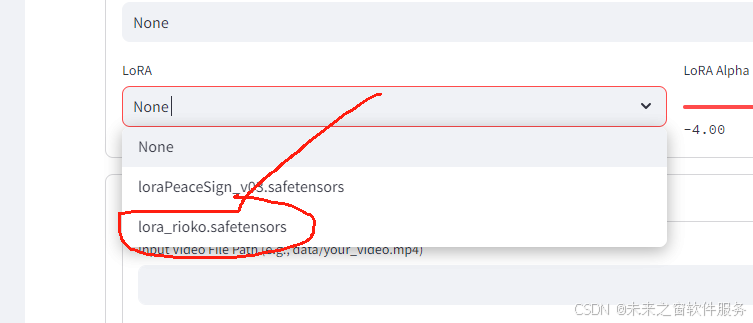
如何更换lora模型

搜索模型,并下载
lora模型运行监测-通过
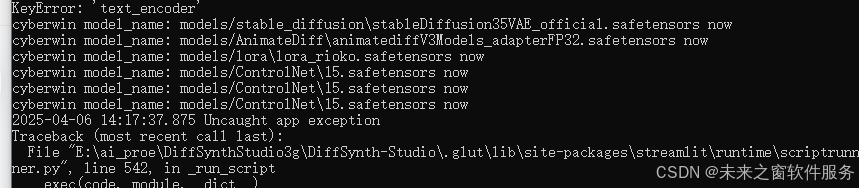
cyberwin model_name: models/stable_diffusion\stableDiffusion35VAE_official.safetensors now
cyberwin model_name: models/AnimateDiff\animatediffV3Models_adapterFP32.safetensors now
cyberwin model_name: models/lora\lora_rioko.safetensors now
cyberwin model_name: models/ControlNet\15.safetensors now
cyberwin model_name: models/ControlNet\15.safetensors now
cyberwin model_name: models/ControlNet\15.safetensors now
2025-04-06 14:17:37.875 Uncaught app exception
Traceback (most recent call last):
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\.glut\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 542, in _run_script
exec(code, module.__dict__)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\pages\2_Video_Creator.py", line 197, in <module>
SDVideoPipelineRunner(in_streamlit=True).run(config)
File "E:\ai_proe\DiffSynthStudio3g\DiffSynth-Studio\diffsynth\pipelines\stable_diffusion_video.py", line 340, in run
model_manager, pipe = self.load_pipeline(*controlnet 模型报错
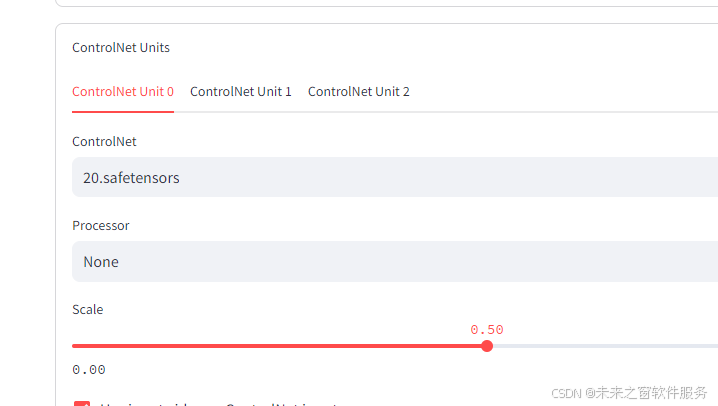
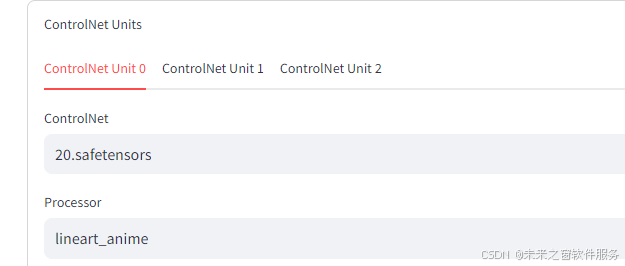
controlnet 模型报错 版本解释
softedge,软边
openpose 开放姿态
lineart 线性
lineart_anime 线性动漫
canny 精明
depth 深度
tile 瓦
| 术语 | 含义 | 在 ControlNet 中的作用 | 应用场景举例 |
|---|---|---|---|
| Softedge(软边) | 提取图像边缘信息,边缘更柔和、连续,含更多细节和过渡 | 帮助模型捕捉物体形状和轮廓,使生成图像边缘自然流畅 | 风景图像生成,如勾勒山脉、河流边界 |
| OpenPose(开放姿态) | 人体姿态估计模型,检测人体关键点获取姿态信息 | 控制生成图像中人物姿态,确保肢体动作自然协调 | 动画制作、游戏角色设计中特定动作人物图像生成 |
| Lineart(线性) | 提取图像线条信息,简化为线条表示,突出物体轮廓和结构 | 为模型提供图像基本架构指导,用于生成以线条结构为主的插画 | 平面设计、漫画创作 |
| Lineart_anime(线性动漫) | 针对动漫风格图像生成的线性控制模式,线条更简洁、夸张,突出动漫风格特征 | 引导模型生成具有典型动漫风格线条的图像 | 动漫角色、场景图像创作 |
| Canny(Canny 边缘检测) | 经典边缘检测算法,明确图像中物体边缘位置 | 模型依据其检测出的边缘信息生成完整图像,保证物体边缘准确 | 建筑设计、机械制图等对边缘准确性要求高的图像生成 |
| Depth(深度) | 图像中物体与相机(或观察者)之间的距离关系,即深度信息 | 为模型提供图像三维空间结构线索,生成具有真实远近层次和空间感的图像 | 虚拟现实、3D 场景生成 |
| Tile(瓦片) | 将输入图像视为可重复的 “瓦片” 结构 | 生成具有连续、重复图案且拼接处自然过渡的图像 | 壁纸、织物纹理等需要重复图案的图像生成,如室内设计、纺织品设计 |
=====
下载链接和方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









